LWJGL3的内存管理,第一篇,基础知识
LWJGL3的内存管理,第一篇,基础知识
为了讨论LWJGL在内存分配方面的设计,我将会分为数篇随笔分开介绍,本篇将主要介绍一些大方向的问题和一些必备的知识。
何为"绑定(binding)"
LWJGL3 是一个 OpenGL,Vulkan 等的绑定库,这怎么理解呢?
首先要知道, 以OpenGL为例,其本身已经是一个完备的图形库,你可以选择直接使用它的原生(C/C++)API,来进行项目的开发,事实上这也是当今主流的做法。Java则是一直被视为不胜任该领域,图形学相关的讨论几乎与Java无缘。而LWJGL3的出现改变了这一现状。LWJGL3 并非要建立一个新的受操作系统和显卡厂商支持的基本图形库,而是实现通过Java来进行基于OpenGL的开发。LWJGL提供的API,最后还是通过JNI调用native API来实现相关的功能。除了由于C和Java在语言特性上的不同,造成的一些差异外,实际上两者的API从函数名到函数签名,都是相同的,这是LWJGL的刻意为之,也是“绑定”一词的内涵。
以下将列举几个原生的API,和LWJGL的API,来直观体现这一点
| 序号 | native API(C语言) | LWJGL3的API(Java) |
|---|---|---|
| 1 | void glBindVertexArray(GLuint array); | glBindVertexArray(@NativeType("GLuint") int array) |
| 2 | void glBindTexture(GLenum target, GLuint texture); | void glBindTexture(@NativeType("GLenum") int target, @NativeType("GLuint") int texture) |
| 3 | void glGenBuffers(GLsizei n, GLuint * buffers); | int glGenBuffers() |
为何 LWJGL3 的 API 被设计为严格禁止堆内缓冲区(Heap buffers),只接受堆外缓冲区
堆外缓冲区指的是 DirectByteBuffer 或其子类的实例所引用的堆外内存,LWJGL3的API只接受这种引用对象。之所以要这样设计,是因为:
- 堆内缓冲区分配虽然快速,但传递给native代码时却需要拷贝
- 堆内缓冲区需要考虑GC问题。如果你对此有疑问,认为无论堆内堆外都会面临GC,那么LWJGL3的栈上分配方式会让你眼前一亮
- 调用路径变长,代码变得复杂
- Java的多态是基于C++的虚方法实现的,当虚函数的实现只有一个时,称之为单态(monomorphic)的情况,虚方法的调用可以通过缓存的虚函数表快速定位。Hotspot的实现中,只要不是单态,就会劣化为超态(megamorphic),缓存起来的虚函数表的命中率将会降低,会造成性能损失;因此当常用的ByteBuffer都指向堆外内存时,单态提高了性能
- 直接使用堆外缓冲区,可以在构造DirectByteBuffer引用对象时指定字节序为本地字节序(native byte order),CPU运算更快
什么是字节序
字节序是字节的顺序,分为大端序和小端序,之所以要关心字节的顺序,是因为CPU在运算时,先读低位字节则效率更高。
举个例子,让CPU计算 11110000 10110110 加 1,如果CPU从高位开始读,也就是从左往右读,则需要读完两个字节才能完成运算得出结果。而如果从低位开始读,则立刻可以得出结果,不需要读完两个字节。
但有些时候,比如在使用TCP协议传递XML报文这种情况,我们常常使用前面几个字节约定报文体长度,或者作为通讯用的标志位,这种情况下,服务端先接受和处理高位字节,能快速获取重要信息做出处理。
这两个简单的例子可以看出,大端序和小端序皆有自身存在的价值,历史上不同的CPU和平台也都未作统一。 因此在不同的平台上,将字节序根据平台进行调整,也是一种性能优化手段。如下所示,LWJGL3在分配每一块堆外内存时,都指定字节序为本地字节序。
/**
* Allocates a direct native-ordered {@code ByteBuffer} with the specified capacity.
*
* @param capacity the capacity, in bytes
*
* @return a {@code ByteBuffer}
*/
public static ByteBuffer createByteBuffer(int capacity) {
return ByteBuffer.allocateDirect(capacity).order(ByteOrder.nativeOrder());
}
Unsafe 类
sun.misc.Unsafe 是一个非公开的类,主要用于JDK内部,比如NIO以及线程和锁的操作。在LWJGL的内存管理里,也是需要该类来实现最为重要的栈上分配功能。
获取实例
我们可以通过反射的方式获取到该类的实例。
private static Unsafe getUnsafeInstance() throws NoSuchFieldException, IllegalAccessException {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe instance = (Unsafe) field.get(null); // 由于 theUnsafe 是 static 属性,因此参数为 null
return instance;
}
Unsafe类中的 public native long getLong(Object obj, long offset) 方法
该方法将返回 obj 这个对象的,在内存布局中,偏移量为 offset 的那个long类型字段的值。下面是一个小例子
class Account {
private long acctNumber;
private String acctName;
private long balance;
public Account(long acctNumber, String acctName, long balance) {
this.acctNumber = acctNumber;
this.acctName = acctName;
this.balance = balance;
}
}
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
Account account = new Account(6212990000000000001L, "张三", 20000000L);
Unsafe unsafe = getUnsafeInstance();
// 获取 acctNumber 在 Account 类中的偏移量
long offset = unsafe.objectFieldOffset(Account.class.getDeclaredField("acctNumber"));
// 获取 account 对象中,偏移量为 offset 的那个long类型字段的值
long accountNumber = unsafe.getLong(account, offset);
System.out.println(accountNumber);
}
这个例子将输出 6212990000000000001
内存地址空间
现代操作系统都做了内存虚拟化,跑在操作系统上的程序,访问到的地址,实际上是虚拟地址,虚拟地址被操作系统映射到物理地址上。每个进程都有互相独立的地址空间,比如同一个地址 0xDEADBEEF8BADF00DL,在不同的进程上对应的物理地址是不同的,因此不同的进程对这个虚拟地址进行读写也互不影响。
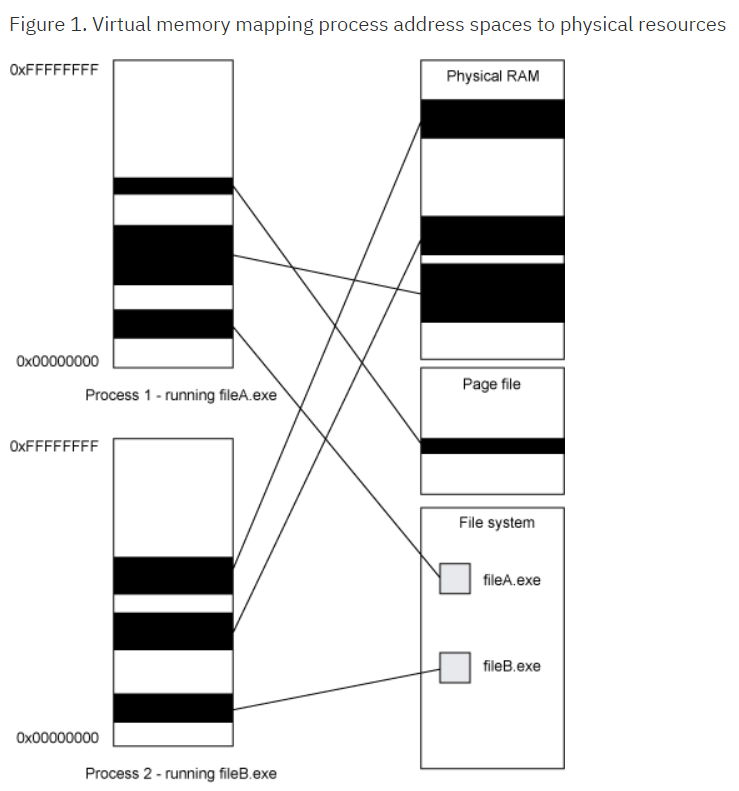
另外,每个进程的地址空间里,分为了用户空间和内核空间,内核空间用于支持系统调用。有一种称为 hugemem 的内核技术不在讨论范围之内。32位平台上,经典的Linux的内核空间与用户空间的比例为1:3,而Windows NT的这一比例为2:2。据此我们可以窥见为什么许多硬件规格较低的系统,有时候反而会比硬件更好的平台有更好的性能表现。
因此,对于本地库文件,比如 jemalloc.dll,首先需要将他加载到进程地址空间,才能进行调用。
其实这里还能延申出零拷贝相关的讨论,正是因为用户空间和内核空间的分开,导致像是nginx这种读取一个静态资源并返回给网络时,需要考虑性能问题,因为无论是读文件还是往网络写数据,都属于系统调用,nginx首先需要从内核态读数据到用户空间,然后再将数据拷贝到网络协议栈,而实际上nginx在这里只起了一个中转的作用,拷贝是白白浪费的。这也是为什么nginx要支持 sendfile 这种零拷贝技术的原因。 Kafka和RocketMQ的高性能也离不开零拷贝技术。
直接内存
直接内存是堆外内存,堆指的 Java 堆。在Java中,要获取堆外内存,有好几种方式:
- NIO 提供的 ByteBuffer::allocateDirect
- Unsafe::allocateMemory
- 通过 JNI 调用第三方包比如 jemalloc 来实现,或者调用标准c的malloc这样的方式
- 通过 JNI 自身提供的 NewDirectByteBuffer 方法来实现
- 通过 UNSAFE.allocateInstance 以反射的方式构造一个 ByteBuffer 对象,再将直接内存的地址等必要信息通过 UNSAFE::putLong, UNSAFE::putInt 等方法初始化。当然这里构造的是一个引用对象,并没有真正的堆外内存分配。
这5种方式,均在LWJGL3的内存管理中被合理地进行了使用。
由于ByteBuffer::allocateDirect 内部是借助于Unsafe::allocateMemory 来实现的;而 jemalloc 相比 malloc 效率更高且对内存碎片问题做了处理,本身是一个成熟的库,在LWJGL3中只是做API调用; 因此下面我们主要对另外3种方式进行一些介绍
NIO 提供的 ByteBuffer::allocateDirect
ByteBuffer bb = ByteBuffer.allocateDirect(16);
例如上面这段代码,产生了两个对象,bb 是位于栈上(如果发生逃逸则在堆上)的引用对象,它指向一块堆外内存。
allocateDirect 内部实际上是调用了 unsafe.allocateMemory(size) 来进行内存分配,之所以不直接使用unsafe.allocateMemory(size) 是因为 allocateDirect 提供了诸如异常处理,注册虚引用支持堆外内存自动回收等功能。
DirectByteBuffer(int cap) { // package-private
super(-1, 0, cap, cap);
boolean pa = VM.isDirectMemoryPageAligned();
int ps = Bits.pageSize();
long size = Math.max(1L, (long)cap + (pa ? ps : 0));
Bits.reserveMemory(size, cap);
long base = 0;
try {
base = unsafe.allocateMemory(size);
} catch (OutOfMemoryError x) {
Bits.unreserveMemory(size, cap);
throw x;
}
unsafe.setMemory(base, size, (byte) 0);
if (pa && (base % ps != 0)) {
// Round up to page boundary
address = base + ps - (base & (ps - 1));
} else {
address = base;
}
cleaner = Cleaner.create(this, new Deallocator(base, size, cap));
att = null;
}
上面是 DirectByteBuffer 的构造方法,Deallocator是一个 Runnable实例,用于释放内存,它的run方法内容如下
public void run() {
if (address == 0) {
// Paranoia
return;
}
unsafe.freeMemory(address);
address = 0;
Bits.unreserveMemory(size, capacity);
}
而 Cleaner::create方法用于创建一个虚引用,虚引用引用了该 DirectByteBuffer 实例和 Deallocator。
DirectByteBuffer 的内存回收,需要两轮GC才能完成,第一轮通过可达性分析扫描的结果对不可达的引用对象进行回收,第二轮才能完成堆外内存的回收。这在高负载情况下容易引起OOM,这也是LWJGL3 不推荐使用它的原因之一。
NewDirectByteBuffer
这是JDK提供的一个API,属于JNI的一部分,官方文档在 https://docs.oracle.com/javase/8/docs/technotes/guides/jni/spec/functions.html#NewDirectByteBuffer
而 Oracle 对于 JNI 的介绍参见:https://docs.oracle.com/javase/8/docs/technotes/guides/jni/spec/jniTOC.html
JNI = Java Native Interface ,是一个本地编程接口(a native programming interface),通俗理解就是用于Java和本地代码(比如C)互相调用的一种技术。由于涉及的内容比较多,这里只介绍一些LWJGL3 里用到的。
NewDirectByteBuffer 方法是由JDK提供的本地方法,需要由本地代码进行调用,该方法用于将一块堆外缓冲区包装为DirectByteBuffer,将该引用类型为 ByteBuffer 的实例返回给Java代码。
该方法的原型为
jobject NewDirectByteBuffer(JNIEnv* env, void* address, jlong capacity);
使用示例如下
#include "net_scaventz_test_mem_MyMemUtil.h"
JNIEXPORT jobject JNICALL Java_net_scaventz_test_mem_MyMemUtil_newDirectByteBuffer
(JNIEnv* __env, jclass clazz, jlong address, jlong capacity) {
void* addr = (void*)(intptr_t) address;
return (*__env)->NewDirectByteBuffer(__env, addr, capacity);
}
有一些细节在官方文档上没有明说,却需要注意:
- 该方法实际上是对堆外指定内存进行包装,wrap 成一个 DirectByteBuffer并返回
- 因而该方法的执行过程并不会对堆外内存做任何修改,实际上返回的DirectByteBuffer并不保证是可写的,只保证可读
- 因而无需考虑传入的 address 值是否已被占用
- capacity参数传0也是可以的,这种特殊情况也在LWJGL3中得到应用
下面这段代码将输出 20201028L
public static void main(String[] args) throws NoSuchFieldException {
ByteBuffer buffer = ByteBuffer.allocateDirect(8);
Field address = Buffer.class.getDeclaredField("address");
long addressOffset = UNSAFE.objectFieldOffset(address);
long addr = UNSAFE.getLong(buffer, addressOffset);
buffer.putLong(20201028L);
ByteBuffer bb = NewDirectByteBuffer(addr, Long.SIZE / 8);
long aLong = bb.getLong();
System.out.println("along: " + aLong);
}
@Nullable
@NativeType("jobject")
public static ByteBuffer NewDirectByteBuffer(@NativeType("void *") long address, @NativeType("jlong") long capacity) {
if (CHECKS) {
check(address);
}
return nNewDirectByteBuffer(address, capacity);
}
@Nullable
public static native ByteBuffer nNewDirectByteBuffer(long address, long capacity);
UNSAFE.allocateInstance
这个方法比较好理解,下面是一个使用它的例子。这段代码对地址为 address 的一块堆外内存进行了包装,可以返回一个具体类型的ByteBuffer,用于引用一块具体大小的堆外内存。这是实现LWJGL3 栈上内存分配策略的基础。
static <T extends Buffer> T wrap(Class<? extends T> clazz, long address, int capacity) {
T buffer;
try {
buffer = (T)UNSAFE.allocateInstance(clazz);
} catch (InstantiationException e) {
throw new UnsupportedOperationException(e);
}
UNSAFE.putLong(buffer, ADDRESS, address);
UNSAFE.putInt(buffer, MARK, -1);
UNSAFE.putInt(buffer, LIMIT, capacity);
UNSAFE.putInt(buffer, CAPACITY, capacity);
return buffer;
}
字节对齐
字节对齐并非Java特有的概念。现代CPU在读取对齐的数据结构时效率更高,很多编程语言都支持自动字节对齐,比如Java,以及一些C和C++的实现。之所以字节对齐能提高CPU读取效率,是因为CPU并非逐个字节读取。举个例子,将内存每个字节比为库房里的一瓶可乐,而每64瓶组成一箱,CPU不会一瓶一瓶去取,而是每次取一箱。假设字节不对齐,就好比64瓶可乐分散在两个箱子,则CPU要取两次才能取全。
Java 对象在堆中的起始地址是8字节对齐的(见https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html),Java 虚拟机还要求 long 字段、double 字段,以及非压缩指针状态下的引用字段地址为 8 的倍数。
因此可以知道,任何一个对象的long类型字段,在对象中的偏移量也将是8的倍数,我们可以写个程序验证一下。
class Person {
public int id = 213;
public char[] msg = {'h', 'e', 'l', 'l', 'o'};
public long age = 17L;
public short payment = 1000;
public boolean bool = true;
}
public class Temp {
private static Unsafe UNSAFE = getUnsafe();
public static void main(String[] args) throws NoSuchFieldException, IOException {
long idOffset = UNSAFE.objectFieldOffset(Person.class.getDeclaredField("id"));
long msgOffset = UNSAFE.objectFieldOffset(Person.class.getDeclaredField("msg"));
long ageOffset = UNSAFE.objectFieldOffset(Person.class.getDeclaredField("age"));
long paymentOffset = UNSAFE.objectFieldOffset(Person.class.getDeclaredField("payment"));
long boolOffset = UNSAFE.objectFieldOffset(Person.class.getDeclaredField("bool"));
System.out.println("idOffset: "+idOffset);
System.out.println("msgOffset: "+msgOffset);
System.out.println("ageOffset: "+ageOffset);
System.out.println("paymentOffset: "+paymentOffset);
System.out.println("boolOffset: "+boolOffset);
}
private static Unsafe getUnsafe() {
try {
Field field = Unsafe.class.getDeclaredField("theUnsafe");
field.setAccessible(true);
Unsafe unsafe = (Unsafe) field.get(null);
return unsafe;
} catch (Exception e) {
return null;
}
}
}
这段代码输出结果为
idOffset: 12
msgOffset: 28
ageOffset: 16
paymentOffset: 24
boolOffset: 26
long 类型的 age 字段在该对象布局的偏移量为 16,确实是8的倍数。
这个知识在 LWJGL3 中有极为重要的应用,可以说是整个栈上内存分配策略的基石。
我们可以利用这一点,对 Direct ByteBuffer 引用对象,以8字节偏移量为起点,8字节偏移量为步长,对整个对象进行扫描。LWJGL3 使用了该技术来寻找特定平台上Direct ByteBuffer 的 address 字段(不同平台该字段名字可能不同)的偏移量。
Java 对象的内存布局
为了更好的理解 Unsafe::getLong 等方法, 需要对Java对象的内存布局有所了解。
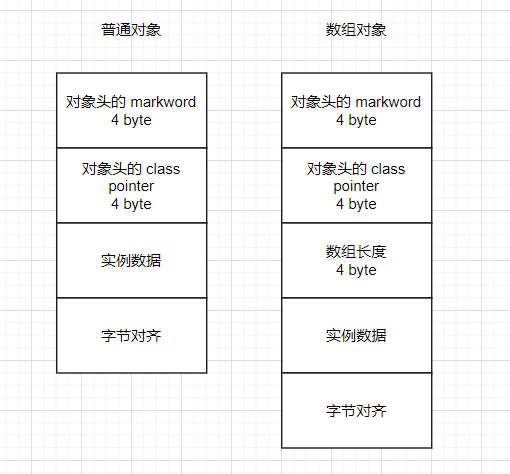
Java对象在内存中的布局主要四部分组成:对象头,类型指针,实例数据,对齐填充。因此对于Java对象内部字段的寻址,比C/C++要更复杂,比如Java对象的第一个字段的地址,和对象的地址是不同的;而C/C++结构体的第一个字段的地址,就是结构体本身的地址。
之所以要有对象头,是有理由的,比如锁信息和hashcode,就保存在对象头里。
借助于 openjdk 提供的 jol,可以直观看到一个对象的内存布局,下面我们实操一下
添加依赖
<dependency>
<groupId>org.openjdk.jol</groupId>
<artifactId>jol-core</artifactId>
<version>0.9</version>
</dependency>
编写代码
import org.openjdk.jol.info.ClassLayout;
/**
* @author scaventz
* @date 10/26/2020
*/
public class MyObject {
public static void main(String[] args) {
MyObject o = new MyObject();
System.out.println(ClassLayout.parseInstance(o).toPrintable());
}
}
输出结果如下:
temp.MyObject object internals:
OFFSET SIZE TYPE DESCRIPTION VALUE
0 4 (object header) 01 00 00 00 (00000001 00000000 00000000 00000000) (1)
4 4 (object header) 00 00 00 00 (00000000 00000000 00000000 00000000) (0)
8 4 (object header) 05 c1 00 f8 (00000101 11000001 00000000 11111000) (-134168315)
12 4 (loss due to the next object alignment)
Instance size: 16 bytes
Space losses: 0 bytes internal + 4 bytes external = 4 bytes total
前面8个字节是markword,由于默认启用指针压缩,接下来的4个字节,是Class Pointer,由于该对象没有成员变量,所以剩下的为补白对齐。所以一个对象占用了16个字节,其中前12个字节为对象头。
参考资料:
https://blog.lwjgl.org/memory-management-in-lwjgl-3/
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
https://blog.csdn.net/aha_jasper/article/details/105695481
https://www.ibm.com/developerworks/library/j-nativememory-linux/index.html
LWJGL3的内存管理,第一篇,基础知识的更多相关文章
- [Python笔记]第一篇:基础知识
本篇主要内容有:什么是python.如何安装python.py解释器解释过程.字符集转换知识.传参.流程控制 初识Python 一.什么是Python Python是一种面向对象.解释型计算机程序设计 ...
- 20151009 C# 第一篇 基础知识
20151009 C#:优点: 1. 语法简洁:不直接操作内存,去掉了指针操作 2. 面向对象:具有封装.继承.多态特性 3. 支持Web标准:支持HTML.XML.SOAP 4. 兼容性:遵循.Ne ...
- LWJGL3的内存管理,第二篇,栈上分配
LWJGL3的内存管理,第二篇,栈上分配 简介 为了讨论LWJGL在内存分配方面的设计,本文将作为该系列随笔中的第二篇,用来讨论在栈上进行内存分配的策略,该策略在 LWJGL3 中体现为以 Memor ...
- LWJGL3的内存管理,第三篇,剩下的两种策略
LWJGL3的内存管理,第三篇,剩下的两种策略 上一篇讨论的基于 MemoryStack 类的栈上分配方式,是效率最高的,但是有些情况下无法使用.比如需要分配的内存较大,又或许生命周期较长.这时候就可 ...
- LWJGL3的内存管理
LWJGL3的内存管理 LWJGL3 (Lightweight Java Game Library 3),是一个支持OpenGL,OpenAl,Opengl ES,Vulkan等的Java绑定库.&l ...
- [译]PrestaShop开发者指南 第一篇 基础
# 第一篇 基础 PS(PrestaShop简称)一开始就设定了能够在它的基础上很简单的构建第三方模块的机制,让它成为一款具有极高定制性的电子商务软件. PS的可以在三个方面进行定制: * 主题 * ...
- LWJGL3的内存管理,简介及目录
LWJGL3的内存管理,简介及目录 LWJGL3 (Lightweight Java Game Library 3),是一个支持OpenGL,OpenAl,Opengl ES,Vulkan等的Java ...
- JVM内存管理——总结篇
JVM内存管理--总结篇 自动内存管理--总结篇 内存划分及作用 常见问题 内存划分及作用 程序计数器 线程私有.字节码行号指示器. 执行Java方法,计数器记录的是字节码指令地址:执行本地(Nati ...
- 深入学习jQuery选择器系列第一篇——基础选择器和层级选择器
× 目录 [1]id选择器 [2]元素选择器 [3]类选择器[4]通配选择器[5]群组选择器[6]后代选择器[7]兄弟选择器 前面的话 选择器是jQuery的根基,在jQuery中,对事件处理.遍历D ...
随机推荐
- Jquery的一键上传组件OCUpload及POI解析Excel文件
第一步:将js文件引入页面 <script type="text/javascript" src="${pageContext.request.contextPat ...
- linux_基础调优
1. 配置授时服务,使用阿里云的授时服务 echo -e "# update time\n*/5 * * * * /usr/sbin/ntpdate time1.aliyun.com &am ...
- Leetcode-数组&链表
常见双指针技巧用法,只总结思路,具体边界判定想不清楚的时候稍微画个图就行了 1. 快慢指针判断链表是否含有环.环入口(快慢指针再次相遇即有环:再从头节点和快慢指针的相遇位置同速度向后,相遇点即为环入口 ...
- Python练习题 047:Project Euler 020:阶乘结果各数字之和
本题来自 Project Euler 第20题:https://projecteuler.net/problem=20 ''' Project Euler: Problem 20: Factorial ...
- xor 和 or 有什么区别
参考:https://zhidao.baidu.com/question/67532331.html 1.定义区别: ①OR是或运算,A OR B的结果:当A.B中只要有一个或者两个都为1时,结果为1 ...
- 文档生成工具——Doxygen
参考: 1.https://blog.csdn.net/liao20081228/article/details/77322584 2.https://blog.csdn.net/wang150619 ...
- 【题解】[USACO08MAR]Land Acquisition G
Link 题目大意:给定\(n\)个二元组,每次可以选择一组,花费是组内最大的长乘以最大的宽.问消掉所有二元组的最小代价. \(\text{Solution:}\) \(dp\)写的不够啊-- 先挖掘 ...
- postgreSQL与Kingbase 字符串裁剪区别
--postgreSQL postgres=# select substring('abcdefg',0,4); substring abc (1 行记录) postgres=# select sub ...
- Struts2 学习记录-第一天
Struts2 -01 struts2框架认识 struts2框架是web层框架.struts2框架=webwork+strut1框架发展过来的.struts2框架设计主要用到技术:通过过滤器进行请求 ...
- day50 Pyhton 前端01
文档结构: <!-- 定义文档类型 --> <!DOCTYPE html> <!-- 文档 --> <html lang='en'> <!-- 仅 ...