Vue、Node全栈项目~面向小白的博客系统~
个人博客系统
前言
❝
代码质量问题轻点喷(去年才学的前端),有啥建议欢迎联系我,联系方式见最下方,感谢!
页面有啥bug也可以反馈给我,感谢! 这是一套包含前后端代码的个人博客系统,欢迎各位提出建议,本来打算用nuxt来书写,但是想学了react之后用next来写,后面会用reactSSR来重构!
❞
博客该有的功能都有,可以写文章,可以评论,可以留言,甚至可以玩游戏(虽然还没完善),等等让你来发现。
这是一个小型的全栈项目,主要是检验并记录一下自己的学习成果
运用的技术Vue、Vue-Cli、Element-Ui、后端NodeJs、数据库MySql等各种技术
看到这里了,请你们不要白嫖,点个star(O(∩_∩)O)
前台页面
- 页面设计 借鉴开源项目「白茶」
「支持PC端和移动端,响应式页面,更多页面戏节让你去发掘」
1. 主页
2. 文章列表
3. 听雨
4. Demo
5. 关于我
6. 留言板
页面详情看这里
后台页面
- 主页
- 发布文章
- 关于我
- 评论列表
- 设置
其他的例如文章列表等我后面会别补上,「主要是想让你们研究透代码,自己去写,因为真的很简单(手动狗头)」
页面详情看这里
后端相关
「sequelize」和「koa」在此项目中的使用有机会我会写成对应的文章出来
❝
数据库表结构
❞
「这个博客里本来打算实现文章分类功能,后面感觉不需要,就没用到这个表了」
- 用户表 ID 用户名 用户账号 用户密码 生日 头像 创建时间
- 文章表 ID 用户ID 文章标题 文章图片 文章music 文章内容 分类ID(外键) 文章摘要 发布时间 浏览人数 喜欢人数 评论数(通过文章留言板去查) 分类ID
- 文章留言表 ID 留言文章ID 留言用户ID 留言内容 留言时间
- 分类表 ID 分类名称
- 留言表 ID 留言用户ID 留言内容
- 用户是否喜欢文章表 ID 用户ID 文章ID (通过多对多关系生产)
❝
表关系
❞
- 一个分类有多个文章(一对多)
- 一篇文章可以有多个评论(一对多)
- 一个用户可以评论多篇文章(一对多)
- 一个用户可以留言多次(一对多)
- 一篇文章可以被多个用户喜欢,一个用户可以喜欢多个文章(多对多)
代码目录介绍及运行介绍
后端代码采用三层架构模式
❝
models 是表现层
services 是业务逻辑层
routes 是数据访问层
❞
- 「backstage」 是后台管理系统
- 「client」 是前端
「拉取代码后先在根目录和client文件夹里面和backstage都执行 npm install安装依赖」
「之后首先要在跟目录创建public和encrypt文件夹」
「public文件夹里面要创建upload文件夹,上传文件需要,打包前端代码也是打包到这个目录」
「encrypt里面要创建dbEncrypt.js和ossEncrypt.js」
可随时在models/tables/db.js里面切换
本地开发就用localDbInfo里面的,注意要在db.js切换
——————————数据库请自行安装————————————
dbEncrypt.js
module.exports = {
localDbInfo: {
dbName: 'XXX', // 数据库名称
userName: 'XXX', // 数据库用户名
password: 'XXX', // 数据库密码
host: {
host: 'localhost',
dialect: 'mysql'
}
},
aliDbInfo: { // 服务器上的数据库信息,同上
dbName: 'XXX',
userName: 'XXX',
password: 'XXX',
host: {
host: 'XXX',
dialect: 'mysql'
}
}
}
如果没有服务器,本地开发的话就不需要这个了
我写了两个上传文件的接口,/upload和/ossUpload,没有服务器就切换成/upload就行了
ossEncrypt.js
module.exports = {
region: 'XXX', // OSS region
accessKeyId: 'XXXXXX', OSS accessKeyId
accessKeySecret: 'XXXXXX', OSS accessKeySecret
bucket: 'XXXX', // OSS bucket名
}
接下来就可以愉快的玩耍了
「确保数据库信息填写正确之后 在根目录输入在 npm sync 同步数据库,提示同步完成即可」 「然后输入npm start 开启服务,这样本地服务就跑起来了」 「接下来就跟平时开发一样跑前端就行了,进入client或者backstage 输入 npm run dev 进入开发模式」
部署
首先你得有一个自己的服务器,我用的是阿里云
这里推荐一个我用的服务器工具 xShell和xFtp
然后点击右边的「免费授权页面」填写相应资料即可下载
首先需要安装「nodeJs」,百度安装方式很多,请自选其一,安装完成后node -v,能打印出版本代表安装完成, 安装完成后设置为淘宝镜像:「npm config set registry https://registry.npm.taobao.org」
❝
选装[「nvm」(node管理工具), 「git」]
❞
「nginx」 安装可以看这里,或者百度教程很多
「mysql」 百度一下,你就知道~~
「navicat」(数据库操作工具), 可以使用「navicat注册机」破解,教程点此
「打开navicat连接上服务器的数据库,连接成功即可」
「pm2」(PM2是node进程管理工具,可以利用它来简化很多node应用管理的繁琐任务,如性能监控、自动重启、负载均衡等,而且使用非常简单)
❝
安装命令:npm install pm2@latest -g
❞
❝
pm2 -v打印版本即安装成功
❞
打开服务器和阿里云上相应的端口(3306,5008,80)
「nginx配置」
为什么是5008,因为我koa监听的是5008端口
❝
这里给出我的nginx配置
❞
user root root;
worker_processes auto;
error_log /www/logs/nginx_error.log crit;
pid /www/server/nginx/logs/nginx.pid;
worker_rlimit_nofile 51200;
events
{
use epoll;
worker_connections 51200;
multi_accept on;
}
http
{
include mime.types;
#include luawaf.conf;
# 设置缓存路径并且使用一块最大100M的共享内存,用于硬盘上的文件索引,包括文件名和请求次数,每个文件在1天内若不活跃(无请求)则从硬盘上淘汰,硬盘缓存最大10G,满了则根据LRU算法自动清除缓存。
proxy_cache_path /var/cache/nginx/cache levels=1:2 keys_zone=imgcache:100m inactive=1d max_size=10g;
include proxy.conf;
default_type application/octet-stream;
server_names_hash_bucket_size 512;
client_header_buffer_size 32k;
large_client_header_buffers 4 32k;
client_max_body_size 100m;
sendfile on;
tcp_nopush on;
keepalive_timeout 60;
tcp_nodelay on;
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
fastcgi_buffer_size 64k;
fastcgi_buffers 4 64k;
fastcgi_busy_buffers_size 128k;
fastcgi_temp_file_write_size 256k;
fastcgi_intercept_errors on;
#开启和关闭gzip模式
gzip on;
#gizp压缩起点,文件大于1k才进行压缩
gzip_min_length 1k;
# 设置压缩所需要的缓冲区大小,以4k为单位,如果文件为7k则申请2*4k的缓冲区
gzip_buffers 4 16k;
#nginx对于静态文件的处理模块,开启后会寻找以.gz结尾的文件,直接返回,不会占用cpu进行压缩,如果找不到则不进行压缩
gzip_static on;
# 识别http协议的版本,早起浏览器可能不支持gzip自解压,用户会看到乱码
gzip_http_version 1.1;
# gzip 压缩级别,1-9,数字越大压缩的越好,也越占用CPU时间
gzip_comp_level 1;
# 进行压缩的文件类型。
gzip_types text/plain application/json application/javascript application/x-javascript text/javascript text/css application/xml image/jpeg image/gif image/png video/mpeg audio/x-pn-realaudio audio/x-midi audio/basic audio/mpeg audio/ogg audio/* video/mp4;
# 启用应答头"Vary: Accept-Encoding"
gzip_vary on;
# nginx做为反向代理时启用,off(关闭所有代理结果的数据的压缩),expired(启用压缩,如果header头中包括"Expires"头信息),no-cache(启用压缩,header头中包含"Cache-Control:no-cache"),no-store(启用压缩,header头中包含"Cache-Control:no-store"),private(启用压缩,header头中包含"Cache-Control:private"),no_last_modefied(启用压缩,header头中不包含"Last-Modified"),no_etag(启用压缩,如果header头中不包含"Etag"头信息),auth(启用压缩,如果header头中包含"Authorization"头信息)
gzip_proxied expired no-cache no-store private auth;
# (IE5.5和IE6 SP1使用msie6参数来禁止gzip压缩 )指定哪些不需要gzip压缩的浏览器(将和User-Agents进行匹配),依赖于PCRE库
gzip_disable "MSIE [1-6]\.";
limit_conn_zone $binary_remote_addr zone=perip:10m;
limit_conn_zone $server_name zone=perserver:10m;
server_tokens off;
access_log off;
# 是否启用在on-the-fly方式压缩文件,启用后,将会在响应时对文件进行压缩并返回。
brotli on;
# 启用后将会检查是否存在带有br扩展的预先压缩过的文件。如果值为always,则总是使用压缩过的文件,而不判断浏览器是否支持。
brotli_static always;
# 设置压缩质量等级。取值范围是0到11.
brotli_comp_level 6;
# 设置缓冲的数量和大小。大小默认为一个内存页的大小,也就是4k或者8k。
brotli_buffers 16 8k;
# 设置需要进行压缩的最小响应大小。
brotli_min_length 20;
# 指定对哪些内容编码类型进行压缩。text/html内容总是会被进行压缩
brotli_types text/plain application/json application/javascript application/x-javascript text/javascript text/css application/xml image/jpeg image/gif image/png video/mpeg audio/x-pn-realaudio audio/x-midi audio/basic audio/mpeg audio/ogg audio/* video/mp4;
server {
listen 80;
# 您的域名
server_name xxxxxx.xxx;
location ^~ / {
proxy_cache imgcache;
proxy_cache_key $scheme$proxy_host$uri$is_args$args;
proxy_cache_valid 200 304 302 24h;
proxy_pass http://www.域名:5008;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_set_header Host $http_host;
proxy_set_header X-Nginx-Proxy true;
proxy_redirect off;
rewrite ^.+(?<!js|css|png|map)$ /index.html break;
autoindex on;
index index.htm index.html;
set $fallback_uri /index.html;
if ($http_accept !~ text/html) {
set $fallback_uri /null;
}
try_files $uri $uri/ $fallback_uri = 404;
}
location ^~ /pc {
proxy_pass http://www.域名:5008/back;
index index.htm index.html;
}
}
include /www/server/panel/vhost/nginx/*.conf;
}
一切准备工作已就绪,可以把项目部署到服务器上了
「执行 npm run build 命令分别打包前台和后台」 执行打包后的结构是这样的
接下来把项目(除client和backstage和node_modules以外)放置到服务器的dist文件夹中(然后打该目录执行「npm i」下载依赖)
由于对nginx不熟悉,所以我这里public文件放置得做一些改动,熟悉的可以自行配置(顺便教下我。。)
就是把pc文件夹里面的放置放到同级
皆大欢喜,做到这里就完成了。接下使用 域名就能访问啦
日志记录
放置到服务器后,出了问题,肯定不像本地开发调试一样方便,所以我们需要「日志记录」,来定位问题
我采用的库是 log4js打不开就得翻墙,我只记录了接口调用记录,需要sql调用记录的可以自行加上 npm i koa-log4
const log4js = require('koa-log4')
const path = require('path')
log4js.configure({
appenders: {
api: {
type: 'dateFile',
filename: path.resolve(__dirname, 'logs', 'api', 'logging.log'),
maxLogSize: 1024 * 1024, // 配置文件的最大字节数
keepFileExt: 3, // 最多保存3天
layout: {
type: 'pattern',
pattern: '%c [%d{yyyy-MM-dd hh:mm:ss}] [%p]:%m%n'
}
},
default: {
type: 'stdout'
}
},
categories: {
api: {
appenders: ['api'],
level: 'all'
},
default: {
appenders: ['default'],
level: 'all'
}
}
})
process.on("exit", () => {
log4js.shutdown()
})
const apiLogger = log4js.getLogger("api")
exports.apiLogger = apiLogger
然后创建一个中间件
// apiLoggerMiddleware.js
const { apiLogger } = require('../logger')
// 处理错误的中间件
module.exports = async (ctx, next) => {
try {
await next();
}
finally {
apiLogger.debug(`${ctx.method} ${ctx.path} ${JSON.stringify(ctx.body)}`)
}
};
//init.js
app.use(require('./apiLoggerMiddleware')) // API请求日志
首页加载速度优化
用vue-cli正常打包后,会生成「多个chunk-hash.js 和 chunk-hash.css」,些许增加访问速度,所以我们需要把对应和合为一个
合并chunk-hash.js
在所有异步组件前增加以下代码,目的是把打包的chunk统一
合并chunk-hash.css
vue.config.js
module.exports = {
configureWebpack: config => {
// 公共代码抽离
config.optimization.splitChunks.cacheGroups = {
vendor: {
chunks: 'all',
test: /node_modules/,
name: 'vendor',
minChunks: 1,
maxInitialRequests: 5,
minSize: 0,
priority: 100
},
common: {
chunks: 'all',
test: /[\\/]src[\\/]js[\\/]/,
name: 'common',
minChunks: 2,
maxInitialRequests: 5,
minSize: 0,
priority: 60
},
styles: {
name: 'styles',
test: /\.(le|sa|sc|c)ss$/,
chunks: 'all',
reuseExistingChunk: true,
minChunks: 1,
enforce: true
}
}
}
}
index.html
「XXX是我的名字」
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<meta http-equiv="X-UA-Compatible" content="IE=edge">
<meta name="description" content="XXX,一名前端工程师,这是我的个人博客,网站文章随便写,想写啥写啥">
<meta name="keywords" content="个人博客,XXX,前端,技术,WEB,blog,BLOG,搭建博客,前端技术,VUE博客,XXX的博客">
<meta name="anthor" content="XXX,123456789@qq.com">
<meta name="robots" content="博客, 前端, blog, 个人博客, XXX, Yong,XXX的博客,web,VUE,React">
<meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, minimum-scale=1, user-scalable=no">
<link rel="icon" href="https://qiheizhiya.oss-cn-shenzhen.aliyuncs.com/image/favicon.ico">
<!-- 使用CDN的CSS文件 -->
<% for (var i in htmlWebpackPlugin.options.cdn &&
htmlWebpackPlugin.options.cdn.css) { %>
<link
href="<%= htmlWebpackPlugin.options.cdn.css[i] %>"
rel="stylesheet"
/>
<% } %>
<title>漆黑之牙</title>
</head>
<body>
<noscript>
<strong>We're sorry but <%= htmlWebpackPlugin.options.title %> doesn't work properly without JavaScript enabled. Please enable it to continue.</strong>
</noscript>
<div id="app"></div>
<!-- built files will be auto injected -->
<!-- 使用CDN的JS文件 -->
<% for (var i in htmlWebpackPlugin.options.cdn &&
htmlWebpackPlugin.options.cdn.js) { %>
<script src="<%= htmlWebpackPlugin.options.cdn.js[i] %>"></script>
<% } %>
<!-- 使用CDN的JS文件 -->
</body>
</html>
cdn
vue.config.js
const isProduction = process.env.NODE_ENV === 'production';
const cdn = {
externals: {
'vue': 'Vue',
'vuex': 'Vuex',
'vue-router': 'VueRouter',
'axios': 'axios',
"element-ui": "ELEMENT",
},
css: [
'https://lib.baomitu.com/element-ui/2.13.2/theme-chalk/index.css'
],
js: [
'https://cdn.bootcss.com/vue/2.6.10/vue.min.js',
'https://cdn.bootcss.com/vue-router/3.1.3/vue-router.min.js',
'https://cdn.bootcss.com/vuex/3.1.2/vuex.min.js',
'https://lib.baomitu.com/element-ui/2.13.2/index.js',
'https://cdn.bootcss.com/axios/0.19.2/axios.min.js'
]
}
module.exports = {
chainWebpack: config => {
// 注入cdn
config.plugin('html').tap(args => {
// 生产环境或本地需要cdn时,才注入cdn
if (isProduction) { args[0].cdn = cdn }
return args
})
},
configureWebpack: config => {
config.externals = cdn.externals
}
}
前端gzip
npm i -d compression-webpack-plugin
vue.config.js
//也是在configureWebpack中
//gzip压缩
config.plugins.push(new CompressionPlugin({
filename: '[path].gz[query]',
//压缩算法
algorithm: 'gzip',
//匹配文件
test: /\.js$|\.css$|\.html$|\.woff$|\.ttf$|\.eot$|/,
//压缩超过此大小的文件,以字节为单位
threshold: 1024,
minRatio: 0.8,
//删除原始文件只保留压缩后的文件
deleteOriginalAssets: isProduction
}))
「完整配置请自行看client中的vue.config.js」
优化前:1M带宽才首屏加载「10多秒」
优化后:正常情况下首屏加载「1,2秒」
最后
不知不觉写的太多了
项目无模板,纯手写
分享自己的一个全栈简单项目给大家,有什么建议/bug/优化可以提一下,感谢!!。
如果看到这里,就请帮忙点个star吧!!
喜欢技术的也可以加我,一起进步。
邮箱: 953136447@qq.com
微信号:qwer880620
# <center>个人博客系统</center>
## 前言> 代码质量问题轻点喷(去年才学的前端),有啥建议欢迎联系我,联系方式见最下方,感谢!>> 页面有啥bug也可以反馈给我,感谢!这是一套包含前后端代码的个人博客系统,欢迎各位提出建议,本来打算用nuxt来书写,但是想学了react之后用next来写,后面会用reactSSR来重构!
博客该有的功能都有,可以写文章,可以评论,可以留言,甚至可以玩游戏(虽然还没完善),等等让你来发现。
这是一个小型的全栈项目,主要是检验并记录一下自己的学习成果
运用的技术Vue、Vue-Cli、Element-Ui、后端NodeJs、数据库MySql等各种技术
看到这里了,请你们不要白嫖,点个[star(O(∩_∩)O)](https://github.com/qiheizhiya/myBlog)
### 前台页面- 页面设计 借鉴开源项目**白茶** **支持PC端和移动端,响应式页面,更多页面戏节让你去发掘**
1. 主页
2. 文章列表
3. 听雨
4. Demo
5. 关于我
6. 留言板
页面详情看[这里](http://www.llongjie.top)### 后台页面1. 主页2. 发布文章3. 关于我4. 评论列表5. 设置 其他的例如文章列表等我后面会别补上,**主要是想让你们研究透代码,自己去写,因为真的很简单(手动狗头)**
页面详情看[这里](http://www.llongjie.top/pc)### 后端相关1. 数据库操作使用 [sequelize](https://github.com/demopark/sequelize-docs-Zh-CN)2. 后端框架使用 [koa](https://www.w3cways.com/doc/koa/)
**sequelize**和**koa**在此项目中的使用有机会我会写成对应的文章出来
> 数据库表结构>**这个博客里本来打算实现文章分类功能,后面感觉不需要,就没用到这个表了**1. 用户表 ID 用户名 用户账号 用户密码 生日 头像 创建时间 2. 文章表 ID 用户ID 文章标题 文章图片 文章music 文章内容 分类ID(外键) 文章摘要 发布时间 浏览人数 喜欢人数 评论数(通过文章留言板去查) 分类ID 3. 文章留言表 ID 留言文章ID 留言用户ID 留言内容 留言时间4. 分类表 ID 分类名称 5. 留言表 ID 留言用户ID 留言内容6. 用户是否喜欢文章表 ID 用户ID 文章ID (通过多对多关系生产)
> 表关系1. 一个分类有多个文章(一对多)2. 一篇文章可以有多个评论(一对多)3. 一个用户可以评论多篇文章(一对多)4. 一个用户可以留言多次(一对多)5. 一篇文章可以被多个用户喜欢,一个用户可以喜欢多个文章(多对多) ### 代码目录介绍及运行介绍后端代码采用三层架构模式> models 是表现层> > services 是业务逻辑层> > routes 是数据访问层>1. **backstage** 是后台管理系统2. **client** 是前端
**拉取代码后先在根目录和client文件夹里面和backstage都执行 npm install安装依赖**
**之后首先要在跟目录创建public和encrypt文件夹**
**public文件夹里面要创建upload文件夹,上传文件需要,打包前端代码也是打包到这个目录**
**encrypt里面要创建dbEncrypt.js和ossEncrypt.js**
``` 可随时在models/tables/db.js里面切换本地开发就用localDbInfo里面的,注意要在db.js切换
——————————数据库请自行安装————————————
dbEncrypt.js module.exports = { localDbInfo: { dbName: 'XXX', // 数据库名称 userName: 'XXX', // 数据库用户名 password: 'XXX', // 数据库密码 host: { host: 'localhost', dialect: 'mysql' } }, aliDbInfo: { // 服务器上的数据库信息,同上 dbName: 'XXX', userName: 'XXX', password: 'XXX', host: { host: 'XXX', dialect: 'mysql' } }}``````如果没有服务器,本地开发的话就不需要这个了我写了两个上传文件的接口,/upload和/ossUpload,没有服务器就切换成/upload就行了ossEncrypt.js module.exports = { region: 'XXX', // OSS region accessKeyId: 'XXXXXX', OSS accessKeyId accessKeySecret: 'XXXXXX', OSS accessKeySecret bucket: 'XXXX', // OSS bucket名 }```
接下来就可以愉快的玩耍了
**确保数据库信息填写正确之后 在根目录输入在 npm sync 同步数据库,提示同步完成即可****然后输入npm start 开启服务,这样本地服务就跑起来了****接下来就跟平时开发一样跑前端就行了,进入client或者backstage 输入 npm run dev 进入开发模式**
### 部署首先你得有一个自己的服务器,我用的是阿里云
这里推荐一个我用的服务器工具[xShell和xFtp](https://www.netsarang.com/zh/xshell-download/)
然后点击右边的**免费授权页面**填写相应资料即可下载
1. 首先需要安装**nodeJs**,百度安装方式很多,请自选其一,安装完成后node -v,能打印出版本代表安装完成, 安装完成后设置为淘宝镜像:**npm config set registry https://registry.npm.taobao.org**> 选装[**nvm**(node管理工具), **git**]2. **[nginx](http://www.llongjie.top/detail/55)** 安装可以看这里,或者百度教程很多 3. **mysql** 百度一下,你就知道~~4. **[navicat](http://www.navicat.com.cn/)**(数据库操作工具), 可以使用**navicat注册机**破解,教程点此5. **打开navicat连接上服务器的数据库,连接成功即可**6. **pm2**(PM2是node进程管理工具,可以利用它来简化很多node应用管理的繁琐任务,如性能监控、自动重启、负载均衡等,而且使用非常简单)> 安装命令:npm install pm2@latest -g > pm2 -v打印版本即安装成功7. 打开服务器和阿里云上相应的端口(3306,5008,80)8. **nginx配置**
为什么是5008,因为我koa监听的是5008端口 > 这里给出我的nginx配置``` user root root; worker_processes auto; error_log /www/logs/nginx_error.log crit; pid /www/server/nginx/logs/nginx.pid; worker_rlimit_nofile 51200; events { use epoll; worker_connections 51200; multi_accept on; }
http { include mime.types; #include luawaf.conf;
# 设置缓存路径并且使用一块最大100M的共享内存,用于硬盘上的文件索引,包括文件名和请求次数,每个文件在1天内若不活跃(无请求)则从硬盘上淘汰,硬盘缓存最大10G,满了则根据LRU算法自动清除缓存。 proxy_cache_path /var/cache/nginx/cache levels=1:2 keys_zone=imgcache:100m inactive=1d max_size=10g;
include proxy.conf;
default_type application/octet-stream; server_names_hash_bucket_size 512; client_header_buffer_size 32k; large_client_header_buffers 4 32k; client_max_body_size 100m;
sendfile on; tcp_nopush on;
keepalive_timeout 60;
tcp_nodelay on;
fastcgi_connect_timeout 300; fastcgi_send_timeout 300; fastcgi_read_timeout 300; fastcgi_buffer_size 64k; fastcgi_buffers 4 64k; fastcgi_busy_buffers_size 128k; fastcgi_temp_file_write_size 256k;fastcgi_intercept_errors on; #开启和关闭gzip模式 gzip on; #gizp压缩起点,文件大于1k才进行压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小,以4k为单位,如果文件为7k则申请2*4k的缓冲区 gzip_buffers 4 16k; #nginx对于静态文件的处理模块,开启后会寻找以.gz结尾的文件,直接返回,不会占用cpu进行压缩,如果找不到则不进行压缩 gzip_static on; # 识别http协议的版本,早起浏览器可能不支持gzip自解压,用户会看到乱码 gzip_http_version 1.1; # gzip 压缩级别,1-9,数字越大压缩的越好,也越占用CPU时间 gzip_comp_level 1; # 进行压缩的文件类型。 gzip_types text/plain application/json application/javascript application/x-javascript text/javascript text/css application/xml image/jpeg image/gif image/png video/mpeg audio/x-pn-realaudio audio/x-midi audio/basic audio/mpeg audio/ogg audio/* video/mp4; # 启用应答头"Vary: Accept-Encoding" gzip_vary on; # nginx做为反向代理时启用,off(关闭所有代理结果的数据的压缩),expired(启用压缩,如果header头中包括"Expires"头信息),no-cache(启用压缩,header头中包含"Cache-Control:no-cache"),no-store(启用压缩,header头中包含"Cache-Control:no-store"),private(启用压缩,header头中包含"Cache-Control:private"),no_last_modefied(启用压缩,header头中不包含"Last-Modified"),no_etag(启用压缩,如果header头中不包含"Etag"头信息),auth(启用压缩,如果header头中包含"Authorization"头信息) gzip_proxied expired no-cache no-store private auth; # (IE5.5和IE6 SP1使用msie6参数来禁止gzip压缩 )指定哪些不需要gzip压缩的浏览器(将和User-Agents进行匹配),依赖于PCRE库 gzip_disable "MSIE [1-6]\.";
limit_conn_zone $binary_remote_addr zone=perip:10m;limit_conn_zone $server_name zone=perserver:10m;
server_tokens off; access_log off;
# 是否启用在on-the-fly方式压缩文件,启用后,将会在响应时对文件进行压缩并返回。 brotli on; # 启用后将会检查是否存在带有br扩展的预先压缩过的文件。如果值为always,则总是使用压缩过的文件,而不判断浏览器是否支持。 brotli_static always; # 设置压缩质量等级。取值范围是0到11. brotli_comp_level 6; # 设置缓冲的数量和大小。大小默认为一个内存页的大小,也就是4k或者8k。 brotli_buffers 16 8k; # 设置需要进行压缩的最小响应大小。 brotli_min_length 20; # 指定对哪些内容编码类型进行压缩。text/html内容总是会被进行压缩 brotli_types text/plain application/json application/javascript application/x-javascript text/javascript text/css application/xml image/jpeg image/gif image/png video/mpeg audio/x-pn-realaudio audio/x-midi audio/basic audio/mpeg audio/ogg audio/* video/mp4; server { listen 80; # 您的域名 server_name xxxxxx.xxx; location ^~ / { proxy_cache imgcache; proxy_cache_key $scheme$proxy_host$uri$is_args$args; proxy_cache_valid 200 304 302 24h; proxy_pass http://www.域名:5008; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_set_header X-Nginx-Proxy true; proxy_redirect off; rewrite ^.+(?<!js|css|png|map)$ /index.html break; autoindex on; index index.htm index.html; set $fallback_uri /index.html; if ($http_accept !~ text/html) { set $fallback_uri /null; } try_files $uri $uri/ $fallback_uri = 404; } location ^~ /pc { proxy_pass http://www.域名:5008/back; index index.htm index.html; } } include /www/server/panel/vhost/nginx/*.conf; }
```一切准备工作已就绪,可以把项目部署到服务器上了
**执行 npm run build 命令分别打包前台和后台**执行打包后的结构是这样的

接下来把项目(除client和backstage和node_modules以外)放置到服务器的dist文件夹中(然后打该目录执行**npm i**下载依赖)

由于对nginx不熟悉,所以我这里public文件放置得做一些改动,熟悉的可以自行配置(顺便教下我。。)

就是把pc文件夹里面的放置放到同级
皆大欢喜,做到这里就完成了。接下使用 域名就能访问啦
[例如我的博客](http://www.llongjie.top)
### 日志记录放置到服务器后,出了问题,肯定不像本地开发调试一样方便,所以我们需要**日志记录**,来定位问题
我采用的库是 [log4js](https://log4js-node.github.io/log4js-node/)打不开就得翻墙,我只记录了接口调用记录,需要sql调用记录的可以自行加上npm i koa-log4
```const log4js = require('koa-log4')const path = require('path')
log4js.configure({ appenders: { api: { type: 'dateFile', filename: path.resolve(__dirname, 'logs', 'api', 'logging.log'), maxLogSize: 1024 * 1024, // 配置文件的最大字节数 keepFileExt: 3, // 最多保存3天 layout: { type: 'pattern', pattern: '%c [%d{yyyy-MM-dd hh:mm:ss}] [%p]:%m%n' } }, default: { type: 'stdout' } }, categories: { api: { appenders: ['api'], level: 'all' }, default: { appenders: ['default'], level: 'all' } }})
process.on("exit", () => { log4js.shutdown()})
const apiLogger = log4js.getLogger("api")
exports.apiLogger = apiLogger```
然后创建一个中间件
```// apiLoggerMiddleware.jsconst { apiLogger } = require('../logger')
// 处理错误的中间件module.exports = async (ctx, next) => { try { await next(); } finally { apiLogger.debug(`${ctx.method} ${ctx.path} ${JSON.stringify(ctx.body)}`) }
};
//init.jsapp.use(require('./apiLoggerMiddleware')) // API请求日志```
### 首页加载速度优化用vue-cli正常打包后,会生成**多个chunk-hash.js 和 chunk-hash.css**,些许增加访问速度,所以我们需要把对应和合为一个#### 合并chunk-hash.js在所有异步组件前增加以下代码,目的是把打包的chunk统一
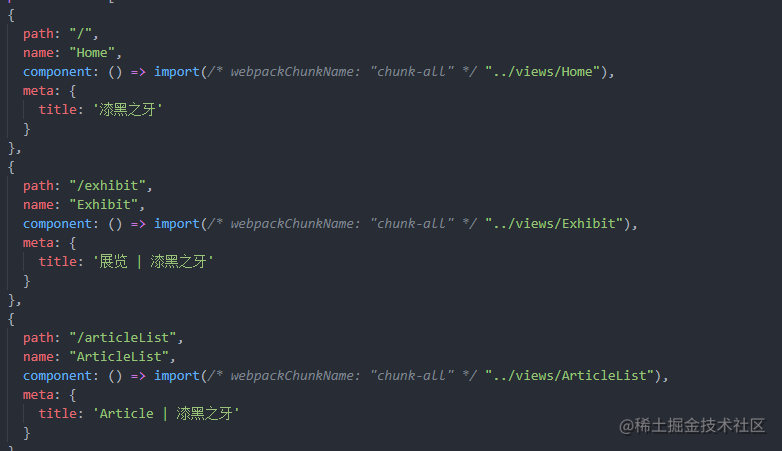#### 合并chunk-hash.cssvue.config.js```module.exports = {configureWebpack: config => { // 公共代码抽离 config.optimization.splitChunks.cacheGroups = { vendor: { chunks: 'all', test: /node_modules/, name: 'vendor', minChunks: 1, maxInitialRequests: 5, minSize: 0, priority: 100 }, common: { chunks: 'all', test: /[\\/]src[\\/]js[\\/]/, name: 'common', minChunks: 2, maxInitialRequests: 5, minSize: 0, priority: 60 }, styles: { name: 'styles', test: /\.(le|sa|sc|c)ss$/, chunks: 'all', reuseExistingChunk: true, minChunks: 1, enforce: true } } }}```index.html
**XXX是我的名字**```<!DOCTYPE html><html lang="en"> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="description" content="XXX,一名前端工程师,这是我的个人博客,网站文章随便写,想写啥写啥"> <meta name="keywords" content="个人博客,XXX,前端,技术,WEB,blog,BLOG,搭建博客,前端技术,VUE博客,XXX的博客"> <meta name="anthor" content="XXX,123456789@qq.com"> <meta name="robots" content="博客, 前端, blog, 个人博客, XXX, Yong,XXX的博客,web,VUE,React"> <meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, minimum-scale=1, user-scalable=no"> <link rel="icon" href="https://qiheizhiya.oss-cn-shenzhen.aliyuncs.com/image/favicon.ico"> <!-- 使用CDN的CSS文件 --> <% for (var i in htmlWebpackPlugin.options.cdn && htmlWebpackPlugin.options.cdn.css) { %> <link href="<%= htmlWebpackPlugin.options.cdn.css[i] %>" rel="stylesheet" /> <% } %> <title>漆黑之牙</title> </head> <body> <noscript> <strong>We're sorry but <%= htmlWebpackPlugin.options.title %> doesn't work properly without JavaScript enabled. Please enable it to continue.</strong> </noscript> <div id="app"></div> <!-- built files will be auto injected -->
<!-- 使用CDN的JS文件 --> <% for (var i in htmlWebpackPlugin.options.cdn && htmlWebpackPlugin.options.cdn.js) { %> <script src="<%= htmlWebpackPlugin.options.cdn.js[i] %>"></script> <% } %> <!-- 使用CDN的JS文件 --> </body></html>
```#### cdnvue.config.js``` const isProduction = process.env.NODE_ENV === 'production';const cdn = { externals: { 'vue': 'Vue', 'vuex': 'Vuex', 'vue-router': 'VueRouter', 'axios': 'axios', "element-ui": "ELEMENT", }, css: [ 'https://lib.baomitu.com/element-ui/2.13.2/theme-chalk/index.css' ], js: [ 'https://cdn.bootcss.com/vue/2.6.10/vue.min.js', 'https://cdn.bootcss.com/vue-router/3.1.3/vue-router.min.js', 'https://cdn.bootcss.com/vuex/3.1.2/vuex.min.js', 'https://lib.baomitu.com/element-ui/2.13.2/index.js', 'https://cdn.bootcss.com/axios/0.19.2/axios.min.js' ]}module.exports = {chainWebpack: config => { // 注入cdn config.plugin('html').tap(args => { // 生产环境或本地需要cdn时,才注入cdn if (isProduction) { args[0].cdn = cdn } return args }) }, configureWebpack: config => { config.externals = cdn.externals }}```#### 前端gzipnpm i -d compression-webpack-plugin
vue.config.js```//也是在configureWebpack中//gzip压缩 config.plugins.push(new CompressionPlugin({ filename: '[path].gz[query]', //压缩算法 algorithm: 'gzip', //匹配文件 test: /\.js$|\.css$|\.html$|\.woff$|\.ttf$|\.eot$|/, //压缩超过此大小的文件,以字节为单位 threshold: 1024, minRatio: 0.8, //删除原始文件只保留压缩后的文件 deleteOriginalAssets: isProduction }))```
**完整配置请自行看client中的vue.config.js**
优化前:1M带宽才首屏加载**10多秒**
优化后:正常情况下首屏加载**1,2秒**
### 最后
不知不觉写的太多了
项目无模板,纯手写
分享自己的一个全栈简单项目给大家,有什么建议/bug/优化可以提一下,感谢!!。
如果看到这里,就请帮忙点个[star](https://github.com/qiheizhiya/myBlog)吧!!
喜欢技术的也可以加我,一起进步。
邮箱: 953136447@qq.com
微信号:qwer880620
Vue、Node全栈项目~面向小白的博客系统~的更多相关文章
- Vue+node.js实现一个简洁的个人博客系统
本项目是一个用vue和node以及mysql实现的一个简单的个人博客系统,整体逻辑比较简单.但是可以我们完整的了解一个项目从数据库到后端到前端的实现过程,适合不太懂这一块的朋友们拿来练手. 本项目所用 ...
- vue3+node全栈项目部署到云服务器
一.前言 最近在B站学习了一下全栈开发,使用到的技术栈是Vue+Element+Express+MongoDB,为了让自己学的第一个全栈项目落地,于是想着把该项目部署到阿里云服务器.经过网上一番搜索和 ...
- Vue、Nuxt服务端渲染,NodeJS全栈项目,面试小白的博客系统~~
Holle,大家好,我是李白!! 一时兴起的开源项目,到这儿就告一段落了. 这是一个入门全栈之路的小项目,从设计.前端.后端.服务端,一路狂飙的学习,发量正在欣喜若狂~~ 接触过WordPress,H ...
- 全栈一路坑(4)——创建博客的API
上一篇博客:全站之路一路坑(3)——使用百度站长工具提交站点地图 这一篇要搭建一个API平台,一是为了给博客补充一些功能,二是为以后做APP提供数据接口. 首先需要安装Django REST Fram ...
- 一个关于vue+mysql+express的全栈项目(一)
最近学了mysql数据库,寻思着能不能构思一个小的全栈项目,思来想去,于是就有了下面的项目: 先上几张效果图吧 目前暂时前端只有这几个页面,后端开发方面,有登录,注册,完善用户信息,获取用 ...
- spring boot + vue + element-ui全栈开发入门——基于Electron桌面应用开发
前言 Electron是由Github开发,用HTML,CSS和JavaScript来构建跨平台桌面应用程序的一个开源库. Electron通过将Chromium和Node.js合并到同一个运行时环 ...
- 《从零开始做一个MEAN全栈项目》(3)
欢迎关注本人的微信公众号"前端小填填",专注前端技术的基础和项目开发的学习. 上一篇文章给大家讲了一下本项目的开发计划,这一章将会开始着手搭建一个MEAN项目.千里之行,始于足下, ...
- 《从零开始做一个MEAN全栈项目》(2)
欢迎关注本人的微信公众号"前端小填填",专注前端技术的基础和项目开发的学习. 上一节简单介绍了什么是MEAN全栈项目,这一节将简要介绍三个内容:(1)一个通用的MEAN项目的技 ...
- 《从零开始做一个MEAN全栈项目》(1)
欢迎关注本人的微信公众号"前端小填填",专注前端技术的基础和项目开发的学习. 在本系列的开篇,我打算讲一下全栈项目开发的优势,以及MEAN项目各个模块的概览. 为什么选择全栈开发? ...
随机推荐
- day63:Linux:nginx基础知识&nginx基础模块
目录 1.nginx基础知识 1.1 什么是nginx 1.2 nginx应用场景 1.3 nginx组成结构 1.4 nginx安装部署 1.5 nginx目录结构 1.6 nginx配置文件 1. ...
- SpringBoot-06-模板引擎Thymeleaf
6. 模板引擎 Thymeleaf Thyme leaf 英译为 百里香的叶子. 模板引擎 以前开发中使用的jsp就是一个模板引擎,但是springboot 以jar的方式,并且使用嵌入式的tom ...
- 对ACE和ATL积分
下载source code - 39.66 KB 介绍 这篇文章展示了一种结合ACE和ATL的方法.它不打算作为功能演示,而是作为一个小型的"入门"解决方案,展示实现此目标的可行方 ...
- 执行新增和修改操作报错connection is read-only. Queries leading to data modification are not allowed
出现这个问题的原因是默认事务只有只读权限,因此要添加下面的每一个add*,del*,update*等等. 分别给予访问数据库的权限. 方法名的前缀有该关键字设置了read-only=true,将其改为 ...
- fastjson配置序列化过滤转换
@Configuration@EnableWebMvcpublic class WebConfig implements WebMvcConfigurer { @Override public voi ...
- VBScript 教程
VBScript 教程 VB 不区分大小写 变量 普通变量 关键词声明 Dim.Public.Private 赋值动态创建 name = "hello" Option Explic ...
- 多测师讲解rf _基本使用002_高级讲师肖sir
在你安装好RF-ride之后,桌面就会生成一个RIDE图标.双击启动,界面如下:
- canal 整合RabbitMQ
环境如下: canal: 1.15-alpha-1 mysql 5.6.49 rabbitmq 3.7.14 Erlang 21.3 canal 安装和启动 见上篇文章 canal快速安装启动 但是 ...
- mysql锁 转
参考文章:https://blog.csdn.net/puhaiyang/article/details/72284702 一.mysql锁的结构图 如上图所示,针对mysql的innodb存储引擎, ...
- spring boot:实现图片文件上传并生成缩略图(spring boot 2.3.1)
一,为什么要给图片生成缩略图? 1, 用户上传的原始图片如果太大,不能直接展示在网站页面上, 因为不但流费server的流量,而且用户打开时非常费时间, 所以要生成缩略图. 2,服务端管理图片要注意的 ...