Redis持久化存储——>RDB & AOF
Redis中两种持久化存储机制RDB和AOF
redis是一个内存数据库,数据保存在内存中,但是我们都知道内存的数据变化是很快的,也容易发生丢失。幸好Redis还为我们提供了持久化的机制,分别是RDB(Redis DataBase)和AOF(Append Only File)。
在这里假设你已经了解了redis的基础语法,某字母网站都有很好的教程,可以去看。基本使用的文章就不写了,都是一些常用的命令。
下面针对这两种方式来介绍一下。由浅入深。
一、持久化流程
既然redis的数据可以保存在磁盘上,那么这个流程是什么样的呢?
会经过如下五个过程:
(1)客户端向服务端发送写操作(数据在客户端的内存中)。
(2)数据库服务端接收到写请求的数据(数据在服务端的内存中)。
(3)服务端调用write这个系统调用,将数据往磁盘上写(数据在系统内存的缓冲区中)。
(4)操作系统将缓冲区中的数据转移到磁盘控制器上(数据在磁盘缓存中)。
(5)磁盘控制器将数据写到磁盘的物理介质中(数据真正落到磁盘上)。
这5个过程是在理想条件下的一个正常保存流程,但是在大多数情况下,我们的机器等等都会有各种各样的故障,这里划分了两种情况:
(1)Redis数据库发生故障,只要在上面的第三步执行完毕,那么就可以持久化保存,剩下的两步由操作系统替我们完成。
(2)操作系统发生故障,必须上面5步都完成才可以。
在这里只考虑了保存的过程可能发生的故障,其实保存的数据也有可能发生损坏,需要一定的恢复机制,不过在这里就不再延伸了。现在主要考虑的是redis如何来实现上面5个保存磁盘的步骤。它提供了两种策略机制,也就是RDB和AOF。
二、RDB机制
RDB其实就是把数据以快照的形式保存在磁盘上。什么是快照呢,你可以理解成把当前时刻的数据拍成一张照片保存下来。
RDB持久化是指在指定的时间间隔内将内存中的数据集快照写入磁盘。也是默认的持久化方式,这种方式就是将内存中数据以快照的方式写入到二进制文件中,默认的文件名为dump.rdb。
在我们安装了redis之后,所有的配置都是在redis.conf文件中,里面保存了RDB和AOF两种持久化机制的各种配置。
既然RDB机制是通过把某个时刻的所有数据生成一个快照来保存,那么就应该有一种触发机制,l来实现这个过程。对于RDB来说,提供了三种机制:save、bgsave、自动化。我们分别来看一下:
1、save命令触发方式
该命令会阻塞当前Redis服务器,执行save命令期间,Redis不能处理其他命令,直到RDB过程完成为止。具体流程如下:
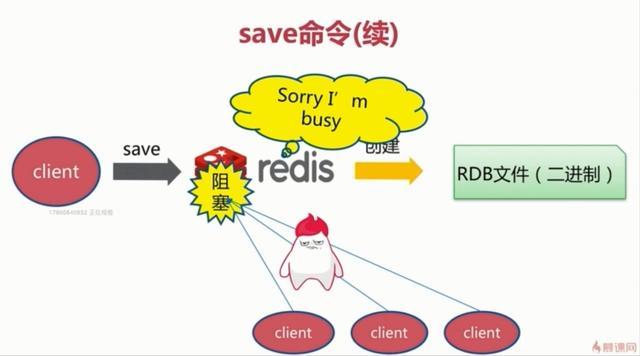
执行完成时如果存在旧的RDB文件,就把新的替代掉旧的。我们的客户端可能有几万或者是几十万,故这种方式显然不可取。
2、bgsave触发方式
执行该命令时,Redis会在后台异步进行快照操作,快照同时还可以响应客户端请求。具体流程如下:
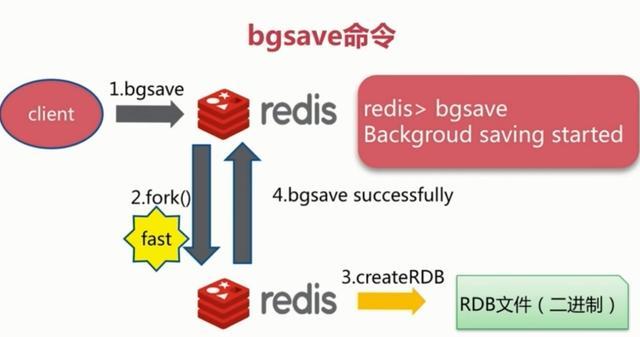
具体操作是Redis进程执行fork操作创建子进程,RDB持久化过程由子进程负责,完成后自动结束。阻塞只发生在fork阶段,一般时间很短。基本上 Redis 内部所有的RDB操作都是采用 bgsave 命令。
3、二者比较
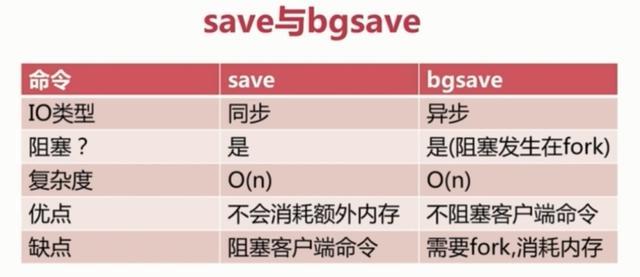
4、自动化触发
自动触发是由修改配置文件来完成的。在redis.conf配置文件中,里面有如下配置,我们可以去设置:
1、save:这里是用来配置触发 Redis的 RDB 持久化条件,也就是什么时候将内存中的数据保存到硬盘。比如“save m n”。表示m秒内数据集存在n次修改时,自动触发bgsave。
默认如下配置:
'#' 表示900 秒内如果至少有1个key的值发生变化,则保存save 900
'1#' 表示300 秒内如果至少有10个key的值变化,则保存save 300
'10#' 表示60 秒内如果至少有10000个key的值变化,则保存save 60 10000
不需要持久化,那么你可以注释掉所有的 save 行来停用保存功能。
2、'stop-writes-on-bgsave-error':默认值为yes。当启用了RDB且最后一次后台保存数据失败时,Redis是否停止接收数据,这会让用户意识到数据没有正确持久化到磁盘上,否则没有人会注意到灾难(disaster)发生了。如果Redis重启了,那么又可以重新开始接收数据了
3、'rdbcompression':默认值是yes。对于存储到磁盘中的快照,可以设置是否进行压缩存储。
4、'rdbchecksum':默认值是yes。在存储快照后,我们还可以让redis使用CRC64算法来进行数据校验,但是这样做会增加大约10%的性能消耗,如果希望获取到最大的性能提升,可以关闭此功能。
5、'dbfilename':设置快照的文件名,默认是 dump.rdb
6、'dir':设置快照文件的存放路径,这个配置项一定是个目录,而不能是文件名。
我们可以修改这些配置来实现我们想要的效果。
4、RDB 的优势和劣势
优势:
(1)RDB文件紧凑,全量备份,非常适合用于进行备份和灾难恢复。
(2)生成RDB文件的时候,redis主进程会fork()一个子进程来处理所有保存工作,主进程不需要进行任何磁盘IO操作。
(3)RDB 在恢复大数据集时的速度比 AOF 的恢复速度要快。
劣势:
RDB快照是一次全量备份,存储的是内存数据的二进制序列化形式,存储上非常紧凑。当进行快照持久化时,会开启一个子进程专门负责快照持久化,子进程会拥有父进程的内存数据,父进程修改内存子进程不会反应出来,所以在快照持久化期间修改的数据不会被保存,可能丢失数据。
三、AOF机制
全量备份总是耗时的,有时候我们提供一种更加高效的存储方式——>AOF,工作机制很简单,redis会将每一个收到的写命令都通过write函数追加到文件中。通俗的理解就是日志记录。
1、持久化原理
如图所示:
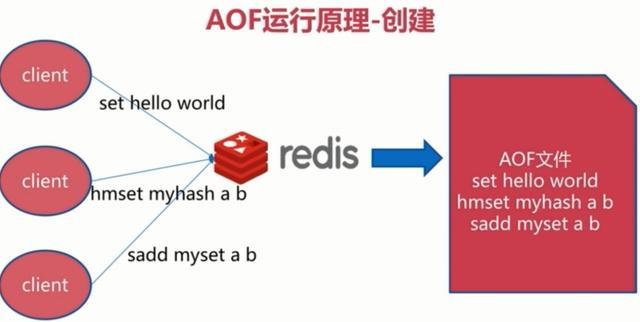
每当有一个写命令过来时,就直接保存在我们的AOF文件中。
2、文件重写原理
AOF的方式也同时带来了另一个问题。持久化文件会变的越来越大。为了压缩aof的持久化文件。redis提供了bgrewriteaof命令。将内存中的数据以命令的方式保存到临时文件中,同时会fork出一条新进程来将文件重写。
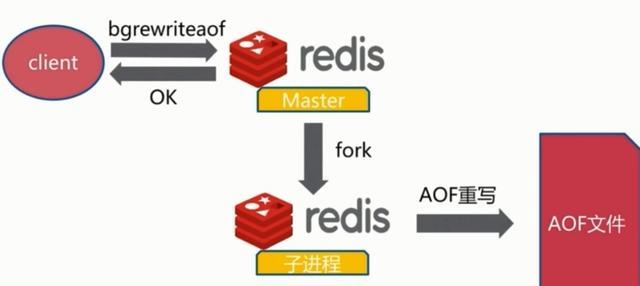
重写aof文件的操作,并没有读取旧的aof文件,而是将整个内存中的数据库内容用命令的方式重写了一个新的aof文件,这点和快照有点类似。
3、AOF也有三种触发机制
(1)每修改同步always:同步持久化 每次发生数据变更会被立即记录到磁盘 性能较差但数据完整性比较好
(2)每秒同步everysec:异步操作,每秒记录 如果一秒内宕机,有数据丢失
(3)不同no:从不同步

4、优点
(1)AOF可以更好的保护数据不丢失,一般AOF会每隔1秒,通过一个后台线程执行一次fsync操作,最多丢失1秒钟的数据。(2)AOF日志文件没有任何磁盘寻址的开销,写入性能非常高,文件不容易破损。
(3)AOF日志文件即使过大的时候,出现后台重写操作,也不会影响客户端的读写。
(4)AOF日志文件的命令通过非常可读的方式进行记录,这个特性非常适合做灾难性的误删除的紧急恢复。比如某人不小心用flushall命令清空了所有数据,只要这个时候后台rewrite还没有发生,那么就可以立即拷贝AOF文件,将最后一条flushall命令给删了,然后再将该AOF文件放回去,就可以通过恢复机制,自动恢复所有数据
5、缺点
(1)对于同一份数据来说,AOF日志文件通常比RDB数据快照文件更大
(2)AOF开启后,支持的写QPS会比RDB支持的写QPS低,因为AOF一般会配置成每秒fsync一次日志文件,当然,每秒一次fsync,性能也还是很高的
(3)以前AOF发生过bug,就是通过AOF记录的日志,进行数据恢复的时候,没有恢复一模一样的数据出来。
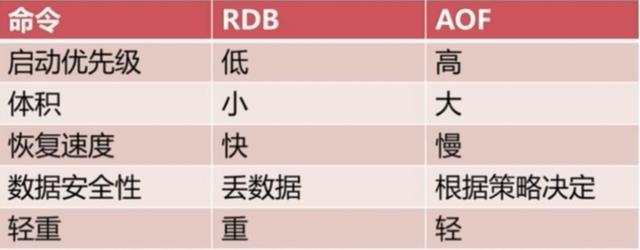
四、RDB和AOF到底该如何选择
选择的话,两者加一起才更好。因为两个持久化机制你明白了,剩下的就是看自己的需求了,需求不同选择的也不一定,但是通常都是结合使用。有一张图可供总结:
Redis持久化存储——>RDB & AOF的更多相关文章
- Redis持久化之rdb&aof
Redis有两种持久化的方式:快照(RDB文件)和追加式文件(AOF文件) RDB持久化方式是在一个特定的间隔保存某个时间点的一个数据快照. AOF(Append only file)持久化方式则会记 ...
- redis 持久化之 RDB & AOF
Redis 持久化实现方式 快照对数据某一时间点的完整备份.例如Linux 快照备份.Redis RDB.MySQL Dump. 日志将数据的所有操作都记录到日志中,需要恢复时,将日志重新执行一次.M ...
- 11/6笔记 补充(Redis持久化,RDB&&AOF)
11/6补充笔记 修改redis-6379.conf里面的save10秒2个数据发生改变 (save 10 2) 修改一次数据不发生改变,修改2次数据才发生改变 继续修改数据,发现还是一样的规律 增删 ...
- Redis持久化之RDB&&AOF的区别
在说Redis持久化之前,需要搞明白什么是数据库状态这个概念,因为持久化的就是将内存中的数据库状态保存到磁盘上.那么什么是数据库状态呢?Redis是一个key-value数据库服务器,一般默认是有16 ...
- Redis持久化存储(RDB和AOF)
参考了: https://blog.csdn.net/canot/article/details/52886923 和 https://www.cnblogs.com/zhangchao-letv/ ...
- Redis持久化存储(AOF与RDB两种模式)
Redis中数据存储模式有2种:cache-only,persistence; cache-only即只做为“缓存”服务,不持久数据,数据在服务终止后将消失,此模式下也将不存在“数据恢复”的手段,是一 ...
- Redis 持久化之RDB和AOF
Redis 持久化之RDB和AOF Redis 有两种持久化方案,RDB (Redis DataBase)和 AOF (Append Only File).如果你想快速了解和使用RDB和AOF,可以直 ...
- Redis持久化(RDB和AOF)
什么是Redis持久化 什么是Redis持久化,就是将内存数据保存到硬盘. Redis 持久化存储 (AOF 与 RDB 两种模式) RDB持久化 RDB 是以二进制文件,是在某个时间 点将数据写入一 ...
- 详解Redis持久化(RDB和AOF)
详解Redis持久化(RDB和AOF) 什么是Redis持久化? Redis读写速度快.性能优越是因为它将所有数据存在了内存中,然而,当Redis进程退出或重启后,所有数据就会丢失.所以我们希望Red ...
随机推荐
- STL源码剖析:序列式容器
前言 容器,置物之所也.就是存放数据的地方. array(数组).list(串行).tree(树).stack(堆栈).queue(队列).hash table(杂凑表).set(集合).map(映像 ...
- Shell基本语法---shell数组
shell数组 arr=( ) #定义数组 echo ${#arr[*]} #打印数组长度 echo ${arr[]} #打印数组的第一个成员 echo ${arr[]} #打印数组的二个成员 ech ...
- Python3基础语法快速入门
01 Python 简介 Python 是一种高层次的结合了解释性.编译性.互动性和面向对象的脚本语言.Python 由 Guido van Rossum 于 1989 年底在荷兰国家数学和计算机科学 ...
- 使用faker生成测试数据
需要先安装faker模块,pip install faker 导入模块中的Faker类:from faker import Faker 实例化faker = Faker() print('姓名相关') ...
- 关于调用三方平台接口与推送接口的总结<二>(2020.7.27)
前言:本篇博客是接着上篇总结写的,想了解怎么对接第三方平台接口的同学可以看我上一篇博客,地址是 https://www.cnblogs.com/alanturingson/p/13377500.ht ...
- python学习笔记1 -- 面向对象编程高级编程1
说起高级其实也就是些基础的东西,但是活用和熟用肯定会大幅度提升代码质量 首先要记录的是面向对象的灵活性,及如何去控制其灵活性,她允许你在实例中新增属性和方法,允许你给类新增属性和方法,也支持在定义类时 ...
- 让内层浮动的Div将外层Div撑开 -----清浮动
清浮动的好处写多了都能体会到,解决高度塌陷, 一般情况下是要清除浮动的,不然会影响下面标签的排版. <div class="parent" style="width ...
- C#怎么统计网站当前在线人数
1.问题背景 c#网站怎么合理的统计在线人数?我想通过全局变量来统计软件的使用情况,当启动软件时向服务器的用户表写开始使用时间,正常退出时写一个结束使用时间,来统计用户的在线使用情况. 但是有一个问题 ...
- timeit_list操作测试
''' timeit库Timer函数 ''' from timeit import Timer def test1(): l = list(range(1000)) def test2(): l = ...
- 牛客练习赛63 牛牛的树行棋 差分 树上博弈 sg函数
LINK:牛牛的树行棋 本来是不打算写题解的. 不过具体思考 还是有一段时间的. 看完题 一直想转换到阶梯NIM的模型上 转换失败. 考虑SG函数. 容易发现 SG函数\(sg_x=max{sg_{t ...