influxdb集群部署
环境准备
influxdb enterprise运行条件最低需要三个meta nodes节点以及两个data nodes
Meta nodes之间使用TCP和Raft一致性协议通信,默认端口为8089
Meta nodes对外暴露8091,用于influxd-ctl命令进行交互
Data nodes通过8088进行数据同步,8086对于用户进行读写服务
在集群中,所有meta nodes节点必须要与data nodes节点保持通信。

mata nodes主要保存以下所有的元数据信息
- 集群中所有的节点以及角色
- 集群中所有存在的数据库和保留策略(retention policy)
- 保存所有分片和分片组信息
- 保存集群用户权限
data node保存所有原始时序数据以及元数据,包括
- measurement(数据表)
- tag key和value
- field key和value;

#wget https://dl.influxdata.com/enterprise/releases/influxdb-meta_1.7.8-c1.7.8_amd64.deb
# dpkg -i influxdb-meta_1.7.8-c1.7.8_amd64.deb
influxdb-meda01
# egrep -v "#|^$" /etc/influxdb/influxdb-meta.conf
hostname = "enterprise-meta-01"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
internal-shared-secret = "123.com"
influxdb-meda02
# egrep -v "#|^$" /etc/influxdb/influxdb-meta.conf
hostname = "enterprise-meta-02"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
internal-shared-secret = "123.com"
influxdb-meda03
# egrep -v "#|^$" /etc/influxdb/influxdb-meta.conf
hostname = "enterprise-meta-03"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
internal-shared-secret = "123.com"
# systemctl start influxdb-meta
# systemctl enable influxdb-meta
将meta node节点加入集群
#influxd-ctl add-meta enterprise-meta-02:8091
#influxd-ctl add-meta enterprise-meta-03:8091
【部署influxdb-node节点】
#wget https://dl.influxdata.com/enterprise/releases/influxdb-data-1.8.2_c1.8.2.x86_64.rpm
#dpkg -i influxdb-data_1.8.2-c1.8.2_amd64.deb
#egrep -v "#|^$" /etc/influxdb/influxdb.conf
bind-address = "192.168.60.0:8088"
hostname = "enterprise-data-01"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
meta-internal-shared-secret = "123.com"
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"
cache-max-memory-size = "1g"
cache-snapshot-memory-size = "25m"
cache-snapshot-write-cold-duration = "10m"
max-series-per-database = 0
max-values-per-tag = 0
max-index-log-file-size = "128k"
[cluster]
[hinted-handoff]
dir = "/var/lib/influxdb/hh"
[anti-entropy]
[retention]
[shard-precreation]
[monitor]
store-enabled = false
[http]
log-enabled = true [logging]
[subscriber]
[[graphite]]
[[collectd]]
[[opentsdb]]
[[udp]]
[continuous_queries]
[tls]
# egrep -v "#|^$" /etc/influxdb/influxdb.conf
bind-address = "192.168.60.0:8088"
hostname = "enterprise-data-02"
[enterprise]
license-key = "224bca5e-514d-441e-b2c2-31b29dd79811"
[meta]
dir = "/var/lib/influxdb/meta"
meta-internal-shared-secret = "123.com"
[data]
dir = "/var/lib/influxdb/data"
wal-dir = "/var/lib/influxdb/wal"
cache-max-memory-size = "1g"
cache-snapshot-memory-size = "25m"
cache-snapshot-write-cold-duration = "10m"
max-series-per-database = 0
max-values-per-tag = 0
max-index-log-file-size = "128k"
[cluster]
[hinted-handoff]
dir = "/var/lib/influxdb/hh"
[anti-entropy]
[retention]
[shard-precreation]
[monitor]
store-enabled = true
[http] [logging]
[subscriber]
[[graphite]]
[[collectd]]
[[opentsdb]]
[[udp]]
[continuous_queries]
log-enabled = true
[tls]
#systemctl start influxd
#systemctl enable influxd
#将date node加入集群
#influxd-ctl add-data enterprise-data-01:8088
#influxd-ctl add-data enterprise-data-02:8088
最后我们在influxdb-meta节点上执行 influxd-ctl show查看集群节点状态
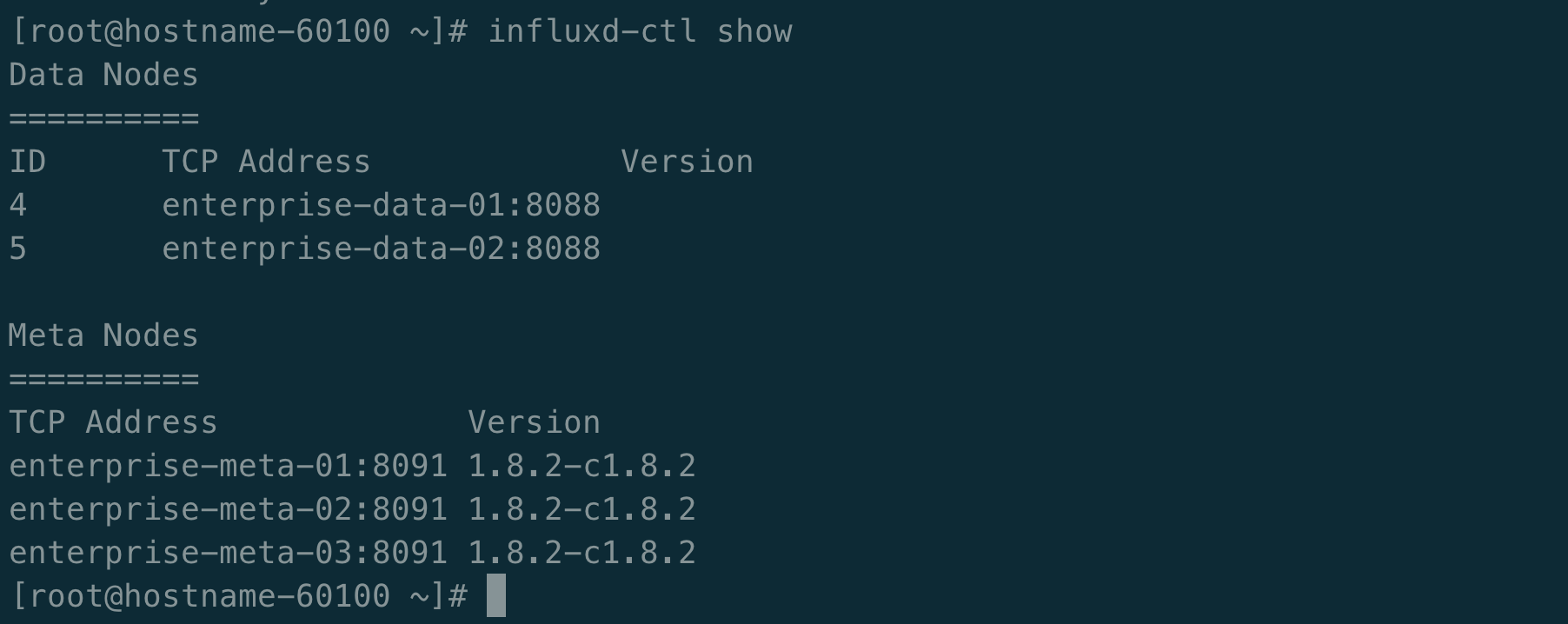
截止目前influxdb集群部署完毕!END
influxdb集群部署的更多相关文章
- Kubernetes集群部署关键知识总结
Kubernetes集群部署需要安装的组件东西很多,过程复杂,对服务器环境要求很苛刻,最好是能连外网的环境下安装,有些组件还需要连google服务器下载,这一点一般很难满足,因此最好是能提前下载好准备 ...
- Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列目录
0.目录 整体架构目录:ASP.NET Core分布式项目实战-目录 k8s架构目录:Kubernetes(k8s)集群部署(k8s企业级Docker容器集群管理)系列目录 一.感谢 在此感谢.net ...
- linux运维、架构之路-Kubernetes离线集群部署-无坑
一.部署环境介绍 1.服务器规划 系统 IP地址 主机名 CPU 内存 CentOS 7.5 192.168.56.11 k8s-node1 2C 2G CentOS 7.5 192.168.56 ...
- k8s集群部署(2)
一.利用ansible部署kubernetes准备阶段 1.集群介绍 基于二进制方式部署k8s集群和利用ansible-playbook实现自动化:二进制方式部署有助于理解系统各组件的交互原理和熟悉组 ...
- Quartz.net持久化与集群部署开发详解
序言 我前边有几篇文章有介绍过quartz的基本使用语法与类库.但是他的执行计划都是被写在本地的xml文件中.无法做集群部署,我让它看起来脆弱不堪,那是我的罪过. 但是quart.net是经过许多大项 ...
- Openfire 集群部署和负载均衡方案
Openfire 集群部署和负载均衡方案 一. 概述 Openfire是在即时通讯中广泛使用的XMPP协议通讯服务器,本方案采用Openfire的Hazelcast插件进行集群部署,采用Hapro ...
- 基于Tomcat的Solr3.5集群部署
基于Tomcat的Solr3.5集群部署 一.准备工作 1.1 保证SOLR库文件版本相同 保证SOLR的lib文件版本,slf4j-log4j12-1.6.1.jar slf4j-jdk14-1.6 ...
- jstorm集群部署
jstorm集群部署下载 Install JStorm Take jstorm-0.9.6.zip as an example unzip jstorm-0.9.6.1.zip vi ~/.bashr ...
- CAS 集群部署session共享配置
背景 前段时间,项目计划搞独立的登录鉴权中心,由于单独开发一套稳定的登录.鉴权代码,工作量大,最终的方案是对开源鉴权中心CAS(Central Authentication Service)作适配修改 ...
随机推荐
- [程序员代码面试指南]最长递增子序列(二分,DP)
题目 例:arr=[2,1,5,3,6,4,8,9,7] ,最长递增子序列为1,3,4,8,9 题解 step1:找最长连续子序列长度 dp[]存以arr[i]结尾的情况下,arr[0..i]中的最长 ...
- Kubernetes中的存储(六)
一.ConfigMap 1,介绍 ConfigMap 功能在 Kuberbetes 1.2 版本中引入,许多应用程序会从配置文件.命令行参数或环境变量中读取配置信息.ConfigMap API 给我们 ...
- Element-UI:级联选择器:Cannot read property 'level' of null"
当级联选择时如果其选择内容需要动态变化时,如果没有选择就不会报错的:而当做出选择后又要动态变化级联选择器内容时,就会报错/ 错误:这个错误的原因是当选择后,再更新内容时,选择器仍会关联原来的数据,导致 ...
- 我把公司 10 年老系统改造 Maven,真香!!
公司有几个老古董项目,应该是 10 年前开发的了,有一个是 JSP + Servlet,有一个还用的 SSH 框架,打包用的 Ant,是有多老啊,我想在座的各位很多都没听过吧. 为了持续集成.持续部署 ...
- GitLab集成kubernetes
创建GitLab源码项目并上传示例代码 1. 创建GitLab源码项目 本示例中创建的GitLab源码项目地址为:https://gitee.com/SunHarvey/helloworld_java ...
- .netcore+vue 实现压缩文件下载
一.前言 目前接触的项目中,给定的需求是将系统内所有用户的数据整理好,并保存到文件夹内,目的主要是防止用户在实施人员已配置好的基础上由于不熟悉系统,导致的误删或者误操作.减少实施人员的配置工作.我首先 ...
- 趣图:调试bug进行时
扩展阅读 趣图:大神写实,左脚程序继续运行,右脚程序调试 趣图:Bug 多了,总有一个会把你坑了 趣图:领导在旁,只求代码无Bug
- System Verilog随笔(1)
测试文件该怎么写? 首先看一个简单代码案例: `timescale 1ns/10ps //1 module test; //2 intput wire[15:0] a; output reg[15 ...
- Python-对字典进行排序
案例: 某班英语成绩以字典的形式存储为: {'lili':78, 'jin':50, 'liming': 30, ......} 依据成绩高低,进行学生成绩排名 如何对字典排序? 方法1: #!/us ...
- unity inspector 自动装载Commont和Prefab属性
在使用unity的过程中,经常遇到这样的问题:每次都需要手动为序列化属性拖拽赋值.像这样: 试着找了找,真的找到了一份代码,但是缺少自动装载Prefab的功能.之后我花了点时间添加这个功能. 使用方法 ...