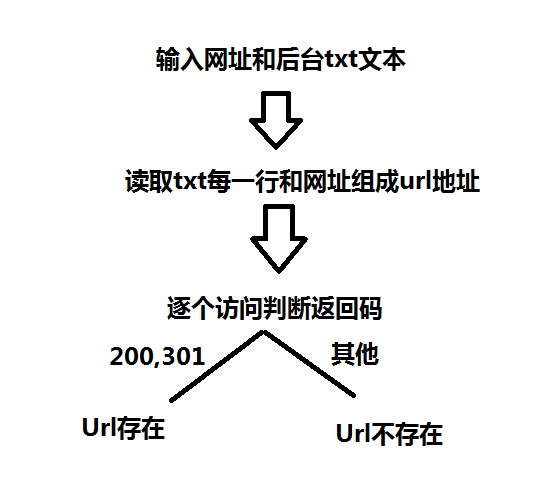
Python 网站后台扫描脚本
Python 网站后台扫描脚本
#!/usr/bin/python
#coding=utf-8
import sys
import urllib
import time
url = "http://123.207.123.228/"
txt = open(r"C:\Users\ww\Desktop\houtaiphp.txt","r")
open_url = []
all_url = []
def search_url(url,txt):
with open(r"C:\Users\ww\Desktop\houtaiphp.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = url+each
all_url.append(urllist)
print("查找:"+urllist+'\n')
try:
req = urllib.urlopen(urllist)
if req.getcode() == 200:
open_url.append(urllist)
if req.getcode() == 301:
open_url.append(urllist)
except:
pass
def main():
search_url(url,txt)
if open_url:
print("后台地址:")
for each in open_url:
print("[+]"+each)
else:
print("没有找到网站后台")
if __name__ == "__main__":
main()
#!/usr/bin/python
#coding=utf-8
import sys
import urllib
import time
url = "http://123.207.123.228/"
txt = open(r"C:\Users\ww\Desktop\houtaiphp.txt","r")
open_url = []
all_url = []
def search_url(url,txt):
with open(r"C:\Users\ww\Desktop\houtaiphp.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = url+each
all_url.append(urllist)
handle_url(urllist) def handle_url(urllist):
print("查找:"+urllist+'\n')
try:
req = urllib.urlopen(urllist)
if req.getcode() == 200:
open_url.append(urllist)
if req.getcode() == 301:
open_url.append(urllist)
except:
pass def main():
search_url(url,txt)
if open_url:
print("后台地址:")
for each in open_url:
print("[+]"+each)
else:
print("没有找到网站后台")
if __name__ == "__main__":
main()

师傅让我多看看-->多线程
这里就加个多线程吧。
#!/usr/bin/python
#coding=utf-8
import sys
import urllib
import time
import threading
url = "http://123.207.123.228/"
txt = open(r"C:\Users\ww\Desktop\houtaiphp.txt","r")
open_url = []
all_url = []
threads = []
def search_url(url,txt):
with open(r"C:\Users\ww\Desktop\houtaiphp.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = url+each
all_url.append(urllist)
def handle_url(urllist):
print("查找:"+urllist+'\n')
try:
req = urllib.urlopen(urllist)
if req.getcode() == 200:
open_url.append(urllist)
if req.getcode() == 301:
open_url.append(urllist)
except:
pass def main():
search_url(url,txt)
for each in all_url:
t = threading.Thread(target = handle_url,args=(each,))
threads.append(t)
t.start()
for t in threads:
t.join()
if open_url:
print("后台地址:")
for each in open_url:
print("[+]"+each)
else:
print("没有找到网站后台")
if __name__ == "__main__":
start = time.clock()
main()
end = time.clock()
print("spend time is:%.3f seconds" %(end-start))
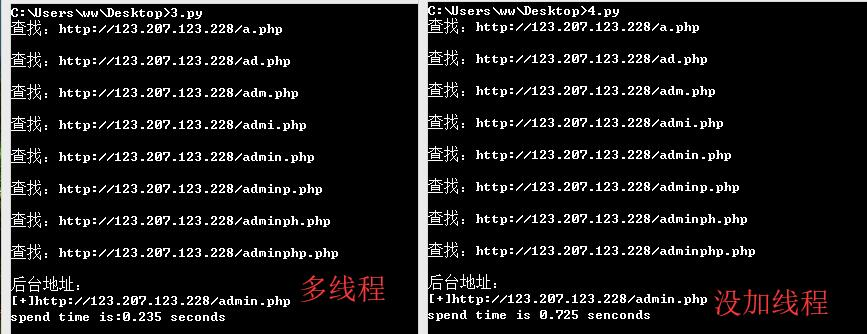
多线程和没加线程的时间对比
--------------------------------------------------------------------------------------------------------------------------------------------------
利用zoomeye搜索
调用ZoomEye API获取信息
主要涉及模块urllib,json,os模块。
# coding: utf-8
import os
import requests
import json access_token = ''
ip_list = [] def login():
"""
输入用户米密码 进行登录操作
:return: 访问口令 access_token
"""
user = raw_input('[-] input : username :')
passwd = raw_input('[-] input : password :')
data = {
'username' : user,
'password' : passwd
}
data_encoded = json.dumps(data) # dumps 将 python 对象转换成 json 字符串
try:
r = requests.post(url = 'https://api.zoomeye.org/user/login',data = data_encoded)
r_decoded = json.loads(r.text) # loads() 将 json 字符串转换成 python 对象
global access_token
access_token = r_decoded['access_token']
except Exception,e:
print '[-] info : username or password is wrong, please try again '
exit() def saveStrToFile(file,str):
"""
将字符串写如文件中
:return:
"""
with open(file,'w') as output:
output.write(str) def saveListToFile(file,list):
"""
将列表逐行写如文件中
:return:
"""
s = '\n'.join(list)
with open(file,'w') as output:
output.write(s) def apiTest():
"""
进行 api 使用测试
:return:
"""
page = 1
global access_token
with open('access_token.txt','r') as input:
access_token = input.read()
# 将 token 格式化并添加到 HTTP Header 中
headers = {
'Authorization' : 'JWT ' + access_token,
}
# print headers
while(True):
try: r = requests.get(url = 'https://api.zoomeye.org/host/search?query="phpmyadmin"&facet=app,os&page=' + str(page),
headers = headers)
r_decoded = json.loads(r.text)
# print r_decoded
# print r_decoded['total']
for x in r_decoded['matches']:
print x['ip']
ip_list.append(x['ip'])
print '[-] info : count ' + str(page * 10) except Exception,e:
# 若搜索请求超过 API 允许的最大条目限制 或者 全部搜索结束,则终止请求
if str(e.message) == 'matches':
print '[-] info : account was break, excceeding the max limitations'
break
else:
print '[-] info : ' + str(e.message)
else:
if page == 10:
break
page += 1 def main():
# 访问口令文件不存在则进行登录操作
if not os.path.isfile('access_token.txt'):
print '[-] info : access_token file is not exist, please login'
login()
saveStrToFile('access_token.txt',access_token) apiTest()
saveListToFile('ip_list.txt',ip_list) if __name__ == '__main__':
main()
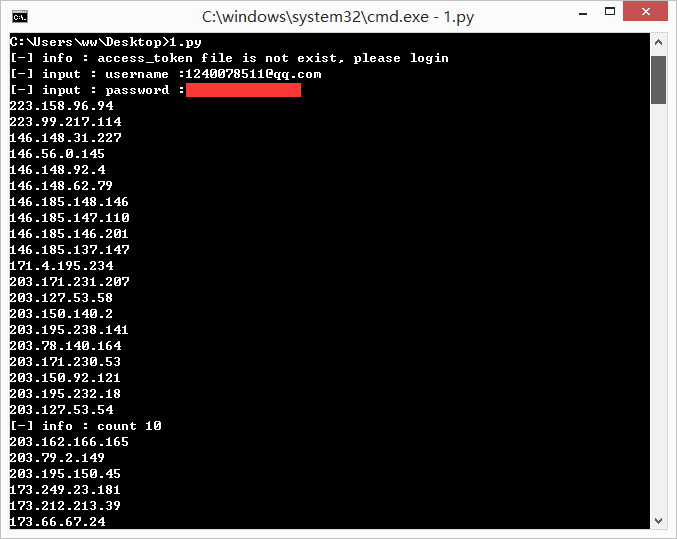
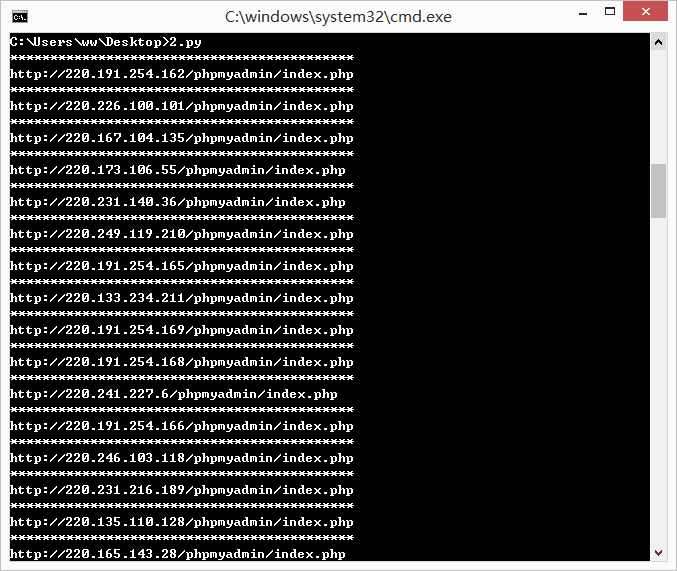
上面的脚本是搜索 phpmyadmin 的。搜索得到的 IP 会保存在同路径下的 ip_list.txt 文件。
但是搜索到的 ip 并不是都能够访问的,所以这里写个了识别 phpmyadmin 的脚本,判断是否存在,是则输出。
#!/usr/bin/python
#coding=utf-8
import sys
import time
import requests
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}##浏览器请求头
open_url = []
all_url = []
payloa = 'http://'
payload = '/phpmyadmin/index.php'
def search_url():
with open(r"C:\Users\ww\Desktop\ip_list.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = payloa+each+payload
all_url.append(urllist)
handle_url(urllist)
def handle_url(urllist):
#print('\n'+urllist)
#print '----------------------------'
try:
start_htm = requests.get(urllist,headers=headers)
#print start_htm
if start_htm.status_code == 200:
print '*******************************************'
print urllist
except:
pass
if __name__ == "__main__":
search_url()
加个多线程,毕竟工作量很大。
#!/usr/bin/python
#coding=utf-8
import sys
import time
import requests
import threading
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 6.3; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0"}##浏览器请求头
open_url = []
all_url = []
threads = []
payloa = 'http://'
payload = '/phpmyadmin/index.php'
def search_url():
with open(r"C:\Users\ww\Desktop\ip_list.txt","r") as f :
for each in f:
each = each.replace('\n','')
urllist = payloa+each+payload
all_url.append(urllist)
#handle_url(urllist)
def handle_url(urllist):
#print('\n'+urllist)
#print '----------------------------'
try:
start_htm = requests.get(urllist,headers=headers)
#print start_htm
if start_htm.status_code == 200:
print '*******************************************'
print urllist
except:
pass
def main():
search_url()
for each in all_url:
t = threading.Thread(target=handle_url,args=(each,))
threads.append(t)
t.start()
for t in threads:
t.join()
if __name__ == "__main__":
start = time.clock()
main()
end = time.clock()
print("spend time is %.3f seconds" %(end-start))
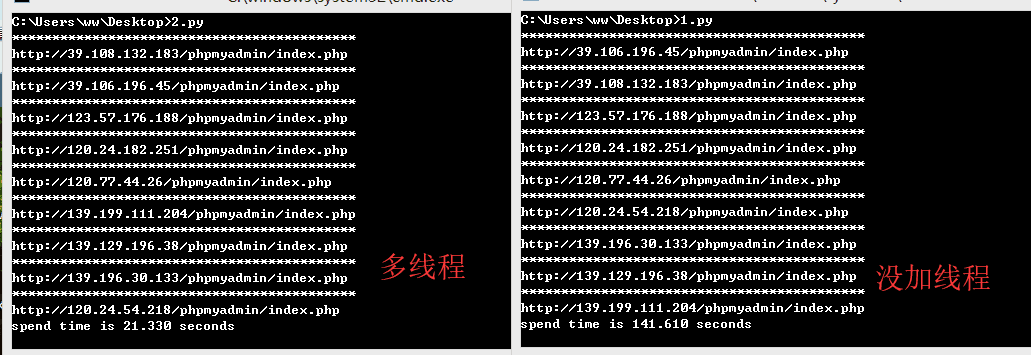
这下就方便了许多。
任重而道远!
Python 网站后台扫描脚本的更多相关文章
- Python 网站后台扫描
title date layout tags Python 网站后台扫描 2018-05-08 post Python #!/usr/bin/python # This was written for ...
- 网站后台扫描工具dirbuster、御剑的用法
dirbuster DirBuster是Owasp(Open Web Application Security Project )开发的一款专门用于探测网站目录和文件(包括隐藏文件)的工具.由于使用J ...
- 【Python】端口扫描脚本
0x00 使用模块简介 1.optparse模块 选项分析器,可用来生成脚本使用说明文档,基本使用如下: import optparse #程序使用说明 usage="%prog -H ...
- [python]MS17-010自动化扫描脚本
一种是3gstudent分享的调用Nsa泄露的smbtouch-1.1.1.exe实现验证,另一种是参考巡风的poc.这里整合学习了下两种不同的方法. import os import fileinp ...
- 转战网站后台与python
这么长时间了,迷茫的大雾也逐渐散去,正如标题所写的一样,转战网站后台开发.这段时间没怎么写博客,主要还是太忙,忙着期末考试的预习,以及服务器的搭建,python的学习,还有各种各样杂七杂八的小事,就像 ...
- python模块之sys和subprocess以及编写简单的主机扫描脚本
python模块之sys和subprocess以及编写简单的主机扫描脚本 1.sys模块 sys.exit(n) 作用:执行到主程序末尾,解释器自动退出,但是如果需要中途退出程序,可以调用sys.e ...
- BBScan — 一个信息泄漏批量扫描脚本
github:https://github.com/lijiejie/BBScan 有些朋友手上有几十万甚至上百万个域名,比如,乌云所有厂商的子域名. 如果把这30万个域名全部扔给wvs,APPsca ...
- 通过SQL注入获得网站后台用户密码
通过 SQL 注入攻击,掌握网站的工作机制,认识到 SQL 注入攻击的防范措施,加强对 Web 攻击的防范. 一.实验环境 下载所需代码及软件:获取链接:链接:https://pan.baidu.co ...
- 通过COOKIE欺骗登录网站后台
1.今天闲着没事看了看关于XSS(跨站脚本攻击)和CSRF(跨站请求伪造)的知识,xss表示Cross Site Scripting(跨站脚本攻击),它与SQL注入攻击类似,SQL注入攻击中以SQL语 ...
随机推荐
- redis命令Sortedset 类型(八)
Sortedset又叫zset Sortedset是有序集合,可排序的,但是唯一. Sortedset和set的不同之处, 是会给set中的元素添加一个分数,然后通过这个分数进行排序. 命令 1> ...
- DatePickerAndroid用法
一.代码/** * Sample React Native App * https://github.com/facebook/react-native */ 'use strict'; import ...
- Java前后端依赖
有时候我们的一个类需要依赖另外一个类,这种就是依赖关系,创建对象的工作一般由spring容器来完成然后注入给调用者,这种就是依赖注入. 代码可参考1227210565朋友空间 DispatcherSe ...
- Linux命令基础2-ls命令
本文介绍的是linux中的ls命令,ls的单词是list files的缩写,意思的列出目录文件. 首先我们在admin用户的当前路径,新建一个test的文件夹,为了方便本文操作和介绍,创建了不同文件类 ...
- Linux恢复误删除的文件或者目录(转)
linux不像windows有个回收站,使用rm -rf *基本上文件是找不回来的. 那么问题来了: 对于linux下误删的文件,我们是否真的无法通过软件进行恢复呢? 答案当然是否定的,对于误删的文件 ...
- Lua实现Map
通过Lua中自带的table来实现一个Map,可以根据键值来插入移除取值 map = {} local this = map function this:new() o = {} setmetatab ...
- 转 深入理解net core中的依赖注入、Singleton、Scoped、Transient
出处:http://www.mamicode.com/info-detail-2200461.html 一.什么是依赖注入(Denpendency Injection) 这也是个老身常谈的问题,到底依 ...
- java方法 throws exception 事务回滚机制
使用spring难免要用到spring的事务管理,要用事务管理又会很自然的选择声明式的事务管理,在spring的文档中说道,spring声明式事务管理默认对非检查型异常和运行时异常进行事务回滚,而对检 ...
- SpringBoot 部署到linux环境
第一部分:Springboot项目部署 说明:工具使用的是IEDA 第一:项目打包 1.在pom文件中添加插件 <build> <plugins> <plugin> ...
- jquery Ajax 实现图片上传的功能。
$('#image').on('change', function () { var url = ""; var form = new FormDa ...