1.XGBOOST算法推导
最近因为实习的缘故,所以开始复习各种算法推导~~~就先拿这个xgboost练练手吧。
(参考原作者ppt
链接:https://pan.baidu.com/s/1MN2eR-4BMY-jA5SIm6WCGg
提取码:bt5s )
1.xgboost的原理
首先值得说明的是,xgboost是gbdt的升级版,有兴趣的话可以先看看gbdt的推导。xgboost同样是构造一棵棵树来拟合残差,但不同之处在于(1)gbdt使用一阶导,xgboost使用二阶导。(2)xgboost在loss中包括模型复杂度,gbdt没有。
首先我们来定义一下模型:
1.符号定义:
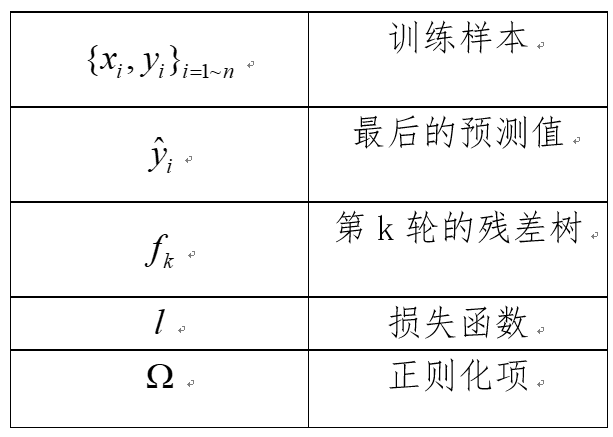
2.模型定义
假设我们迭代T轮,意味着我们要生成T棵残差树:

值得注意的几点:
1.其实一般来说,前面还要加上一个 ,但是作者在这里初始化的时候将
,但是作者在这里初始化的时候将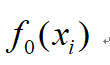 设置为0,所以不用加了。
设置为0,所以不用加了。
2.ft(xi)表示的是第t棵残差树对xi的第t轮残差的预测值。
3.每一轮残差)树的训练数据是什么呢?假如,yt表示t棵cart残差树的和,也就是最终预测值,y表示x的真实标签,那么第t+1棵树的训练数据就是(x,y-yt)
4.F是残差树的函数空间。
5.从函数的角度来说,每一个残差树类似一个分段函数。
2.损失函数定义

从公式的角度,xgboost的误差来源主要是:训练误差和模型复杂度。
3.如何训练残差树?
由于xgboost采取的是增量训练,也就是说只有前一棵树训练好了,才能开始训练下一棵树。这也就意味着,当我训练第t棵树的时候,1~t-1棵树的参数都是固定的了,与其相关的量都是常量。我们可以将目标函数简化一下:
上面的损失函数是没有具体到每一轮的训练,为了方便推导,我们把第t轮的loss表示如下:
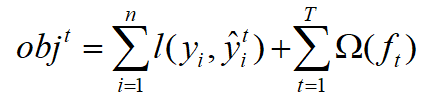
由于存在以下关系:
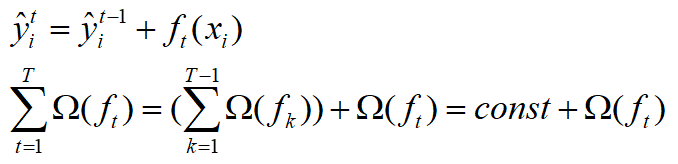
因此,第t轮的loss化简如下:
对于第一部分loss,由于泰勒展开式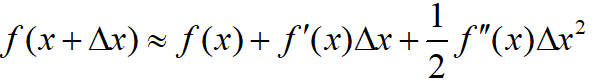 ,我们把
,我们把 当作
当作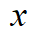 ,
,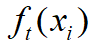 当作
当作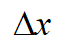 ,那么训练loss可以化简为:
,那么训练loss可以化简为:
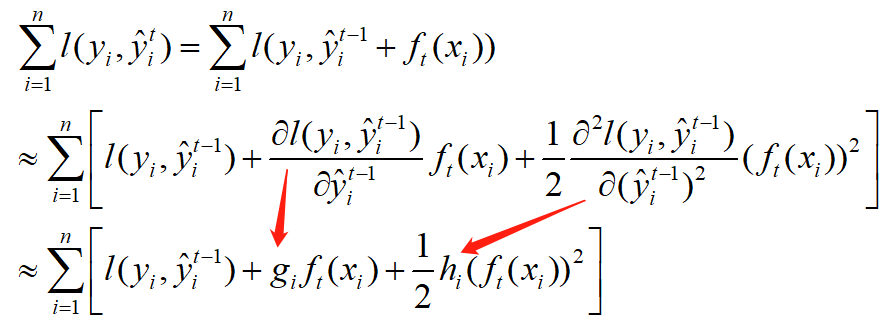
那么总loss变为:
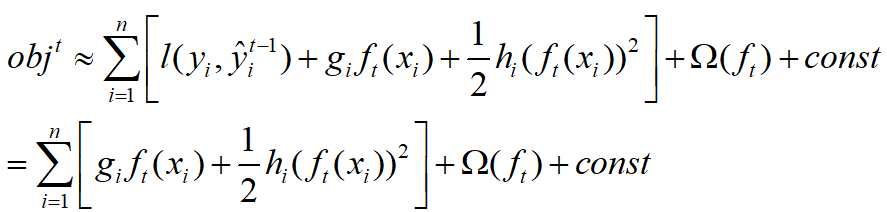
在这个目标函数中,我们需要求的就只有第t棵残差树的参数了。那么一棵树的参数又包括哪些呢?或者说我们要怎样去表示这棵树呢?在xgboost的原作者ppt中是这样定义的:

其中,q(x)就表示x属于哪一个叶子节点,比如说是第三个叶子节点,那么wq(x)就表示第三个叶子节点的权值了,也可以理解为ft对x第t轮残差的的预测值。另外K表示叶子节点的个数(我用的符号和原PPT不太一样,原PPT用的符号是T,感觉和残差树的个数搞重了,所以就换了一个符号)。
下面说一下,模型复杂度的定义:
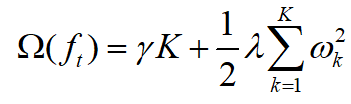
K是叶子节点的个数,K值越小,树的结构就越简单,从而不容易过拟合,这个很好理解,但是为什么还要限制w呢,从某种意义上来说,w是ft对x第t轮残差的的预测值,这个有必要限制嘛?我的思考是这样的:xgboost不希望一次性就把数据拟合得很好,而是每次拟合一个大概就可以了,反正还可以继续学的,也就是说每个残差树都是一个弱分类器,这样也可以防止过拟合。其实这也是boosting一个比较重要的思想。那么如何限制分类器拟合得太好呢,直接限制w的取值就可以了,试想如果某一个w很大,那么当前这棵棵残差树在所有残差树就占很大的权重,这样就容易导致过拟合了。(自己的理解,有错请指正)。
接下来,我们我们用具体的预测值来代替函数,在下面的变换中,loss的计算由以样本为单位求和变味了以叶子节点为单位求和。
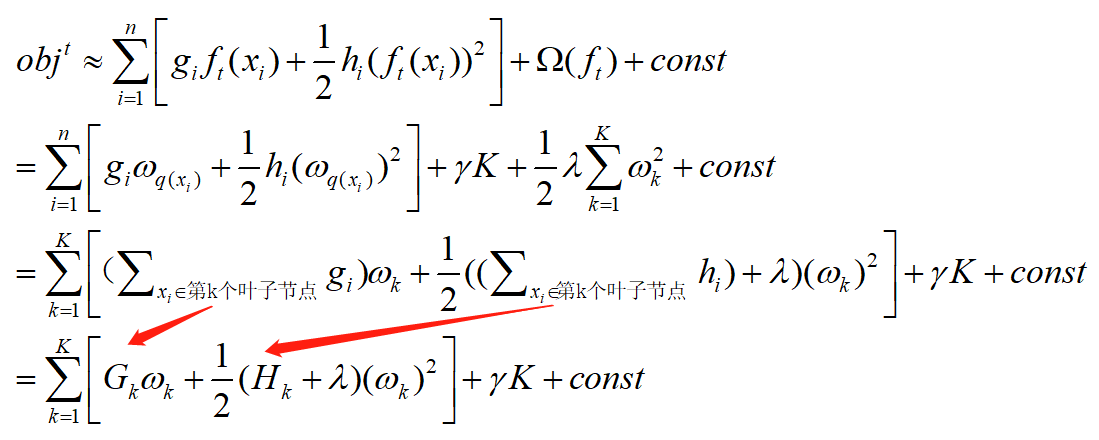
因为G和H都是常数,那么这个问题就变成了一个二次问题了,求解最小值的方法就不多说了,直接给出结果(这个二次问题应该是开口向下的,我没有主动算过,主要是看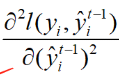 的大小,但是常见的损失函数二次导应该是正的,大家可以去验证一下)
的大小,但是常见的损失函数二次导应该是正的,大家可以去验证一下)
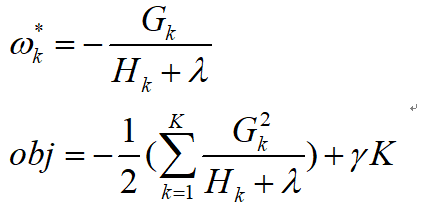
我们说,目前我们得到的最优结果是基于这棵树的结构已经确定的情况下得到的,但是树的结构有很多种,那么该如何确定这棵树的结构呢?
原论文中采取贪婪算法来生成这棵树:
1.从根节点开始;
2.遍历所有特征
3.对于每一个特征,如果是连续型特征,则将其按照从小到大排列,我们样本数量假设有n个,那么这个连续型的特征的切分点就有n-1个,我们就在每一个切分点都计算出一个“分裂增益值”,这个分裂增益值是什么意思呢?它是用来判断当前节点要不要进行分裂,如果分裂那么选择哪个特征的哪个切分点最好。那么分裂增益值要怎么算呢?原论文给出的算法如下:
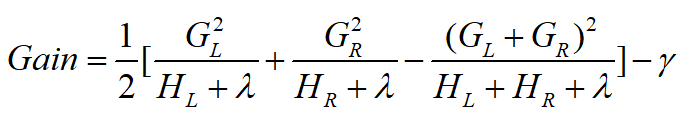
GL是指左节点中所有样本的g和,GR,HL,HR同理(这里对g不知道是什么的东西的同学,我把下面的公式再贴一次)
要知道,分裂后的改变就是叶子节点数多了一个,然后样本被划分到不同的叶子节点。这个Gain公式的原理用白话讲就是,用左节点增益加右节点增益减去未进行分裂前的那个节点的增益减去因为多增加了一个节点而产生的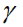 ,那么为什么
,那么为什么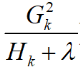 可以表示一个节点的收益呢?由于
可以表示一个节点的收益呢?由于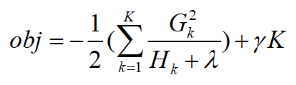 (刚刚计算出的当树结构确定时的最优总loss),仔细观察其结构,就是叶子节点总数乘以一个系数减去所有叶子节点的和乘以一个系数,为了使得loss减小,那么越大越好,因此我们可以将当作是第k个叶子节点的增益。
(刚刚计算出的当树结构确定时的最优总loss),仔细观察其结构,就是叶子节点总数乘以一个系数减去所有叶子节点的和乘以一个系数,为了使得loss减小,那么越大越好,因此我们可以将当作是第k个叶子节点的增益。
4.关于树的剪枝
作者提出了两种剪枝的方法pre-stopping和Post-Prunning,其实就是预剪枝和后减枝:
pre-stopping:我们在计算分裂增益值时,有可能得到负数,这个时候可以直接停止分裂了,这就是pre-stopping的思想,但是这种方法有缺陷:可能这次分裂虽然得到了负增益,但是可能会为后面的节点分裂带来更好的收益。
Post-Prunning:这种方法是先按照上面的算法,不管深度,直接生成能够达到的最大深度的树,然后再根据负增益递归从下往上减枝。
5.一些其他问题
1.如果样本带有权重该怎么办?
假设样本xi的权重为a,那么将gi和hi分别变成a*gi,a*hi
2.还有什么防止过拟合的方法?
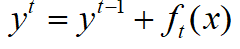 变成
变成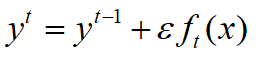 ,
,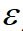 一般取0.1,这个意思和之前关于loss的构成解释差不多,还是希望,前面的残差树不要学得太好,把细节末枝留给后面的树学。(其实感觉这个是所有boosting方法防止过拟合的做法)
一般取0.1,这个意思和之前关于loss的构成解释差不多,还是希望,前面的残差树不要学得太好,把细节末枝留给后面的树学。(其实感觉这个是所有boosting方法防止过拟合的做法)
1.XGBOOST算法推导的更多相关文章
- 机器学习总结(一) Adaboost,GBDT和XGboost算法
一: 提升方法概述 提升方法是一种常用的统计学习方法,其实就是将多个弱学习器提升(boost)为一个强学习器的算法.其工作机制是通过一个弱学习算法,从初始训练集中训练出一个弱学习器,再根据弱学习器的表 ...
- 04-09 XgBoost算法
目录 XgBoost算法 一.XgBoost算法学习目标 二.XgBoost算法详解 2.1 XgBoost算法参数 2.2 XgBoost算法目标函数 2.3 XgBoost算法正则化项 2.4 X ...
- xgboost 算法总结
xgboost有一篇博客写的很清楚,但是现在网址已经失效了,之前转载过,可以搜索XGBoost 与 Boosted Tree. 现在参照这篇,自己对它进行一个总结. xgboost是GBDT的后继算法 ...
- BP神经网络模型及算法推导
一,什么是BP "BP(Back Propagation)网络是1986年由Rumelhart和McCelland为首的科学家小组提出,是一种按误差逆传播算法训练的多层前馈网络,是目前应用最 ...
- XGBoost算法--学习笔记
学习背景 最近想要学习和实现一下XGBoost算法,原因是最近对项目有些想法,准备做个回归预测.作为当下比较火的回归预测算法,准备直接套用试试效果. 一.基础知识 (1)泰勒公式 泰勒公式是一个用函数 ...
- 带你找到五一最省的旅游路线【dijkstra算法推导详解】
前言 五一快到了,小张准备去旅游了! 查了查到各地的机票 因为今年被扣工资扣得很惨,小张手头不是很宽裕,必须精打细算.他想弄清去各个城市的最低开销. [嗯,不用考虑回来的开销.小张准备找警察叔叔说自己 ...
- BP神经网络算法推导及代码实现笔记zz
一. 前言: 作为AI入门小白,参考了一些文章,想记点笔记加深印象,发出来是给有需求的童鞋学习共勉,大神轻拍! [毒鸡汤]:算法这东西,读完之后的状态多半是 --> “我是谁,我在哪?” 没事的 ...
- Python机器学习笔记:XgBoost算法
前言 1,Xgboost简介 Xgboost是Boosting算法的其中一种,Boosting算法的思想是将许多弱分类器集成在一起,形成一个强分类器.因为Xgboost是一种提升树模型,所以它是将许多 ...
- 说说xgboost算法
xgboost算法最近真是越来越火,趁着这个浪头,我们在最近一次的精准营销活动中,也使用了xgboost算法对某产品签约行为进行预测和营销,取得了不错的效果.说到xgboost,不得不说它的两大优势, ...
随机推荐
- HIS(LIS、PACS、RIS、EMR)系统简介
HIS(LIS.PACS.RIS.EMR)系统简介 HIS:医院信息系统(Hospital Information System, HIS),利用电子计算机和通讯设备,为医院所属各部 门提供病人诊疗信 ...
- CentOS7设置ssh服务以及端口修改
很多时候我们都是通过SSH 服务 来对 Linux 进行操作,而不是直接来操作Linux机器,包括对Linux服务器的操作,因此,设置SSH服务对于学习Linux来说属于必备技能(尤其是运维人员),关 ...
- Eclipse使用JDBC小案例
JDBC(Java Database Connectivity:Java访问数据库的解决方案)定义一套标准接口,即访问数据库的通用API,不同数据库厂商根据各自数据的特点去实现这些接口. JDBC是J ...
- python常用的内置函数
python常用的内置函数集合做一个归类用的时候可以查找- abs 返回数字x的绝对值或者x的摸 - all (iterable)对于可迭代的对象iterable中所有元素x都有bool(x)为tru ...
- 【ShaderToy】基本操作——旋转
*继续:ShaderToy基础学习中d(`・∀・)b 对每个像素点进行旋转,其实加个公式就ok了啊. 对网格进行旋转: 代码如下: #define TUTORIAL 2 #define PI 3.14 ...
- -source 1.5 中不支持泛型(请使用-source5或更高版本)
Idea中maven--compile时报错 -source 1.5 中不支持泛型(请使用-source5或更高版本) 解决办法 在项目的pom.xml中,添加 <build> & ...
- 415 DOM 查找列表框、下拉菜单控件、对表格元素/表单控件进行增删改操作、创建元素并且复制节点与删除、 对表格操作、通用性和标准的事件监听方法(点击后弹窗效果以及去掉效果)
DOM访问列表框.下拉菜单的常用属性: form.length.options.selectedindex.type 使用options[index]返回具体选项所对应的常用属性:defa ...
- 前后端分离--ajaxUpload异步上传文件成功,前端获取数据却失败的解决方案
转载:https://blog.csdn.net/baidu_32809053/article/details/78709951
- P5300 [GXOI/GZOI2019]与或和
题目地址:P5300 [GXOI/GZOI2019]与或和 考虑按位计算贡献 对于 AND 运算,只有全 \(1\) 子矩阵才会有贡献 对于 OR 运算,所以非全 \(0\) 子矩阵均有贡献 如果求一 ...
- Tomcat使用shutdown.bat关闭会将其他Tomcat关掉的问题
Tomcat使用shutdown.bat关闭会将其他Tomcat关掉的问题 shutdown.bat文件有一句if not "%CATALINA_HOME%" == "& ...