在 IDEA中运行 WordCount
一、新建一个maven项目
二、pom.xml 中内容
- <?xml version="1.0" encoding="UTF-8"?>
- <project xmlns="http://maven.apache.org/POM/4.0.0"
- xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
- xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
- <modelVersion>4.0.0</modelVersion>
- <groupId>1</groupId>
- <artifactId>1</artifactId>
- <version>1.0-SNAPSHOT</version>
- <repositories>
- <repository>
- <id>apache</id>
- <url>http://maven.apache.org</url>
- </repository>
- </repositories>
- <dependencies>
- <!--<dependency>-->
- <!--<groupId>org.apache.hadoop</groupId>-->
- <!--<artifactId>hadoop-core</artifactId>-->
- <!--<version>2.7.2</version>-->
- <!--</dependency>-->
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-common</artifactId>
- <version>2.7.2</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-hdfs</artifactId>
- <version>2.7.2</version>
- </dependency>
- <dependency>
- <groupId>org.apache.hadoop</groupId>
- <artifactId>hadoop-client</artifactId>
- <version>2.7.2</version>
- </dependency>
- <dependency>
- <groupId>junit</groupId>
- <artifactId>junit</artifactId>
- <version>3.8.1</version>
- <scope>test</scope>
- </dependency>
- </dependencies>
- <build>
- <plugins>
- <plugin>
- <artifactId>maven-dependency-plugin</artifactId>
- <configuration>
- <excludeTransitive>false</excludeTransitive>
- <stripVersion>true</stripVersion>
- <outputDirectory>./lib</outputDirectory>
- </configuration>
- </plugin>
- </plugins>
- </build>
- </project>
三、准备数据文件
注意点:因为Windows当前用户是 Administrator ,所以需要在 hdfs://master:8020/user/ 目录下创建文件夹 Administrator ,以后进行本地测试都使用此文件夹。
文件夹创建好之后,还需要给与写的权限。此处直接给最大权限。
- su hdfs
- hdfs dfs -mkdir -p /user/Administrator/input
- hdfs dfs -chmod -R 777 /user/Administrator
hdfs dfs -put ./wordCountData.txt /user/Administrator/input
exit
四、创建 WordCount.java 文件
注意点: 因为是在 Windows 上提交 mapreduce 任务,需要在 conf 中设置下面内容。
conf.set("mapreduce.app-submission.cross-platform", "true"); // 跨平台,保证在 Windows 下可以提交 mr job
否则报错:/bin/bash: line 0: fg: no job control
- package com.zjc.mr;
- import java.io.IOException;
import java.util.StringTokenizer;- import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;- public class WordCount {
- public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
- // 下面的IntWritable 跟 Text 类是hadoop内部类,相当于 java 中的 int 与 String
// MapReduce 程序中互相传递的是这种类型的参数
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();- public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());//java 自带的字符串分割函数
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
/*
*eg map output:
* hello 1
* word 1
* hello 1
* hadoop 1
*/
}
}
}- /*
* Reduce 输入:
* key: hello
* value: [1,1]
*
* Hadoop负责将Map产生的<key,value>处理成{具有相同key的value集合},传给Reducer
输入:<key,(listof values)>
输出:<key,value>
reduce函数(必须是这个名字)的参数,(输入key,输入具有相同key的value集合,Context)其中,
输入的key,value必须类型与map的输出<key,value>相同,这一点适用于map,reduce类及函数
*
*/
public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();- public void reduce(Text key, Iterable<IntWritable> values, Context context)
throws IOException, InterruptedException {
int sum = 0;
System.out.println("-----------------------------------------");
System.out.println("key: "+key);
for (IntWritable val : values) {
System.out.println("val: "+val);
sum += val.get();
}
result.set(sum);
System.out.println("result: "+result.toString());
context.write(key, result);
}
}- public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
conf.set("mapreduce.app-submission.cross-platform", "true"); // 跨平台,保证在 Windows 下可以提交 mr job
Job job = Job.getInstance(conf, "word count"); // 任务名
job.setJarByClass(WordCount.class); // 指定Class
job.setMapperClass(TokenizerMapper.class); // 指定 Mapper Class
job.setCombinerClass(IntSumReducer.class); // 指定 Combiner Class,与 reduce 计算逻辑一样
job.setReducerClass(IntSumReducer.class); // 指定Reucer Class
job.setOutputKeyClass(Text.class); // 指定输出的KEY的格式
job.setOutputValueClass(IntWritable.class); // 指定输出的VALUE的格式
job.setNumReduceTasks(1); //设置Reducer 个数默认1
// Mapper<Object, Text, Text, IntWritable> 输出格式必须与继承类的后两个输出类型一致
String args_0 = "hdfs://master:8020/user/Administrator/input";
String args_1 = "hdfs://master:8020/user/Administrator/output";
FileInputFormat.addInputPath(job, new Path(args_0)); // 输入路径
FileOutputFormat.setOutputPath(job, new Path(args_1)); // 输出路径
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
// 每次运行都需要先删除hdfs中,上一次执行生成的 output 文件夹。 hdfs dfs -rm -R /user/Administrator/output
五、查看结果
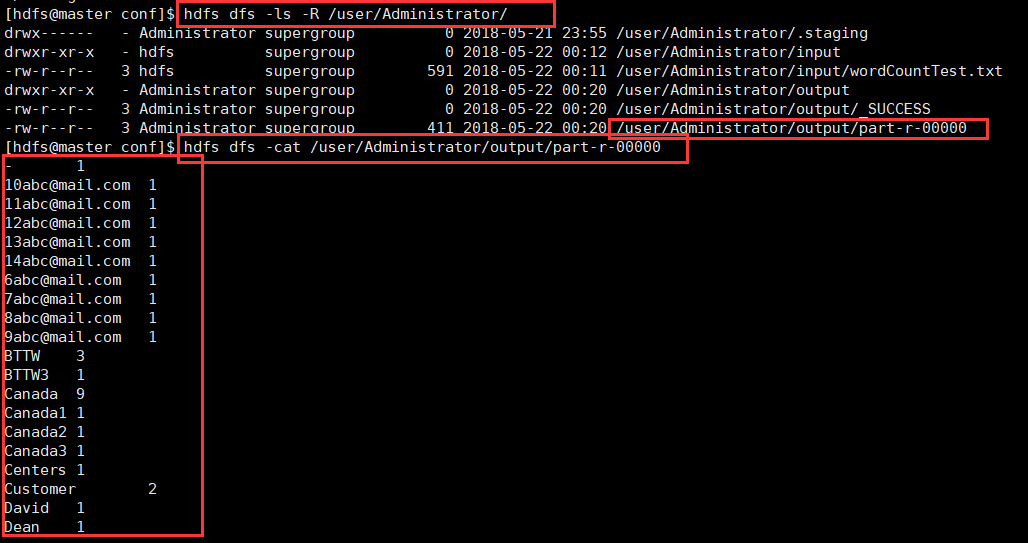
在 IDEA中运行 WordCount的更多相关文章
- Spark学习笔记——在远程机器中运行WordCount
1.通过realy机器登录relay-shell ssh XXX@XXX 2.登录了跳板机之后,连接可以用的机器 XXXX.bj 3.在本地的idea生成好程序的jar包(word-count_2.1 ...
- CDH quick start VM 中运行wordcount例子
需要注意的事情: 1. 对于wordcount1.0 ,按照http://www.cloudera.com/content/cloudera/en/documentation/HadoopTutori ...
- 在eclipse中运行wordcount,控制台打印log4j警告
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).log4j:WARN Please i ...
- Hadoop3 在eclipse中访问hadoop并运行WordCount实例
前言: 毕业两年了,之前的工作一直没有接触过大数据的东西,对hadoop等比较陌生,所以最近开始学习了.对于我这样第一次学的人,过程还是充满了很多疑惑和不解的,不过我采取的策略是还是先让环 ...
- (二)Hadoop例子——运行example中的wordCount例子
Hadoop例子——运行example中的wordCount例子 一. 需求说明 单词计数是最简单也是最能体现MapReduce思想的程序之一,可以称为 MapReduce版"Hello ...
- 021_在Eclipse Indigo中安装插件hadoop-eclipse-plugin-1.2.1.jar,直接运行wordcount程序
1.工具介绍 Eclipse Idigo.JDK1.7-32bit.hadoop1.2.1.hadoop-eclipse-plugin-1.2.1.jar(自己网上下载) 2.插件安装步骤 1)将ha ...
- Spark源码编译并在YARN上运行WordCount实例
在学习一门新语言时,想必我们都是"Hello World"程序开始,类似地,分布式计算框架的一个典型实例就是WordCount程序,接触过Hadoop的人肯定都知道用MapRedu ...
- eclipse运行WordCount
1) 可以完全参考http://www.cnblogs.com/archimedes/p/4539751.html在eclipse下创建MapReduce工程,创建了MR工程,并完成WordCount ...
- 解决在windows的eclipse上面运行WordCount程序出现的一系列问题详解
一.简介 要在Windows下的 Eclipse上调试Hadoop2代码,所以我们在windows下的Eclipse配置hadoop-eclipse-plugin- 2.6.0.jar插件,并在运行H ...
随机推荐
- Numpy库的学习(四)
我们今天继续学习一下Numpy库 接着前面几次讲的,Numpy中还有一些标准运算 a = np.arange(3) print(a) print(np.exp(a)) print(np.sqrt(a) ...
- DataPipeline创始人&CEO 陈诚:沃森与AI
引言:本文来自infoQ架构师电子月刊对DataPipeline创始人&CEO陈诚的约稿.陈诚,毕业于上海交大,留学于美国密西根大学,前Yelp大数据研发工程师,曾就职于美国Google.Ye ...
- python之list和tuple
https://www.cnblogs.com/evablogs/p/6691743.html list和tuple区别: 相同:均为有序集合 异同:list可变,tuple一旦初始化则不可变 lis ...
- 数据加密算法--详解DES加密算法原理与实现
DES算法简介 DES(Data Encryption Standard)是目前最为流行的加密算法之一.DES是对称的,也就是说它使用同一个密钥来加密和解密数据. DES还是一种分组加密算法,该算法每 ...
- IOS开发证书常见问题
1.本地Provisioning Profiles存放路径 ~/Library/MobileDevice/Provisioning Profiles 2.this action could not b ...
- RocketMQ知识整理与总结
1.架构 RocketMQ的master broker与master broker没有任何消息通讯,nameserver之间也同样没有消息通信 MQ历史 由数据结构队列发展而来 MQ使用场景 异 ...
- Node.js在指定的图片模板上生成二维码图片并附带底部文字说明
在Node.js中,我们可以通过qr-image包直接在后台生成二维码图片,使用方法很简单: var qr = require('qr-image'); exports.createQRImage = ...
- iOS中Safari浏览器select下拉列表文字太长被截断的处理方法
网页中的select下拉列表,文字太长的话在iOS的Safari浏览器里会被自动截断,显示成下面这种: 安卓版的浏览器则没有这个问题. 如何让下拉列表中的文字在iOS的Safari浏览器里显示完整呢? ...
- Java基础系列--04_数组
一维数组: (1)数组:存储同一种数据类型的多个元素的容器. (2)特点:每一个元素都有编号,从0开始,最大编号是数组的长度-1. 编号的专业叫法:索引 (3)定义格式 A:数据类型[] 数组名;(一 ...
- RIPng(第三组)
一.实验拓扑 2.地址规划 3.实验配置 1)配置各个路由器的端口地址,PC端地址采用自动配置 如本处的PC0,自动获取IPV6地址 2)配置RIP a.现在路由器开启RIP:ipv6 router ...