JDK源码分析(6)之 LinkedHashMap 相关
LinkedHashMap实质是HashMap+LinkedList,提供了顺序访问的功能;所以在看这篇博客之前最好先看一下我之前的两篇博客,HashMap 相关 和 LinkedList 相关;
一、整体结构
1. 定义
public class LinkedHashMap<K,V> extends HashMap<K,V> implements Map<K,V> {}
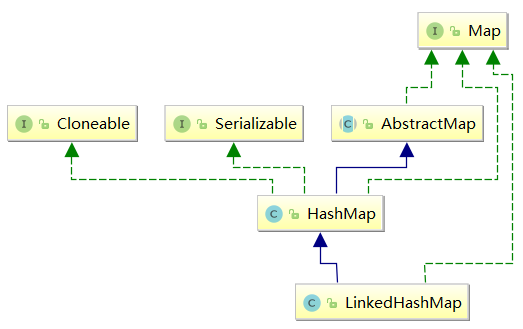
从上述定义中也能看到LinkedHashMap其实就是继承了HashMap,并加了双向链表记录顺序,代码和结构本身不难,但是其中结构的组织,代码复用这些地方十分值得我们学习;具体结构如图所示:
2. 构造函数和成员变量
public LinkedHashMap(int initialCapacity, float loadFactor) {}
public LinkedHashMap(int initialCapacity) {}
public LinkedHashMap() {}
public LinkedHashMap(Map<? extends K, ? extends V> m) {}
public LinkedHashMap(int initialCapacity, float loadFactor, boolean accessOrder) {}
/**
* The iteration ordering method for this linked hash map: <tt>true</tt>
* for access-order, <tt>false</tt> for insertion-order.
* @serial
*/
final boolean accessOrder;
可以看到LinkedHashMap的5个构造函数和HashMap的作用基本是一样的,都是初始化initialCapacity和loadFactor,但是多了一个accessOrder,这也是LinkedHashMap最重要的一个成员变量了;
- 当
accessOrder为true的时候,表示LinkedHashMap中记录的是访问顺序,也是就没放get一个元素的时候,这个元素就会被移到链表的尾部; - 当
accessOrder为false的时候,表示LinkedHashMap中记录的是插入顺序;
3. Entry关系

扎眼一看可能会觉得HashMap体系的节点继承关系比较混乱;一所以这样设计因为
LinkedHashMap继承至HashMap,其中的节点同样有普通节点和树节点两种;并且树节点很少使用;- 现在的设计中,树节点是可以完全复用的,但是
HashMap的树节点,会浪费双向链表的能力; - 如果不这样设计,则至少需要两条继承关系,并且需要抽出双向链表的能力,整个继承体系以及方法的复用会变得非常复杂,不利于扩展;
二、重要方法
上面我们已经讲了LinkedHashMap就是HashMap+链表,所以我们只需要在结构有可能改变的地方加上链表的修改就可以了,结构可能改变的地方只要有put/get/replace,这里需要注意扩容的时候虽然结构改变了,但是节点的顺序仍然保持不变,所以扩容可以完全复用;
1. put 方法
- 未找到key时,直接在最后添加一个节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p = new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
TreeNode<K,V> newTreeNode(int hash, K key, V value, Node<K,V> next) {
TreeNode<K,V> p = new TreeNode<K,V>(hash, key, value, next);
linkNodeLast(p);
return p;
}
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
上面代码很简单,但是很清晰的将添加节点到最后的逻辑抽离的出来;
- 找到key,则替换value,这部分需要联系 HashMap 相关 中的put方法部分;
// HashMap.putVal
...
// 如果找到key
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
// 如果没有找到key
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
...
在之前的HashMap源码分析当中可以看到有几个空的方法
void afterNodeAccess(Node<K,V> p) { }
void afterNodeInsertion(boolean evict) { }
void afterNodeRemoval(Node<K,V> p) { }
这三个就是用来调整链表位置的事件方法,可以看到HashMap.putVal中就使用了两个,
void afterNodeAccess(Node<K,V> e) { // move node to last
LinkedHashMap.Entry<K,V> last;
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p = (LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
afterNodeAccess可以算是LinkedHashMap比较核心的方法了,当访问了一个节点的时候,如果accessOrder = true则将节点放到最后,如果accessOrder = false则不变;
void afterNodeInsertion(boolean evict) { // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
protected boolean removeEldestEntry(Map.Entry<K,V> eldest) {
return false;
}
afterNodeInsertion方法是插入节点后是否需要移除最老的节点,这个方法和维护链表无关,但是对于LinkedHashMap的用途有很大作用,后天会举例说明;
2. get 方法
public V get(Object key) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return null;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
public V getOrDefault(Object key, V defaultValue) {
Node<K,V> e;
if ((e = getNode(hash(key), key)) == null)
return defaultValue;
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
get方法主要也是通过afterNodeAccess来维护链表位置关系;
以上就是LinkedHashMap链表位置关系调整的主要方法了;
3. containsValue 方法
public boolean containsValue(Object value) {
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
return true;
}
return false;
}
可以看到LinkedHashMap还重写了containsValue,在HashMap中寻找value的时候,需要遍历所有节点,他是遍历每个哈希桶,在依次遍历桶中的链表;而在LinkedHashMap里面要遍历所有节点的时候,就可以直接通过双向链表进行遍历了;
三、应用
public class Cache<K, V> {
private static final float DEFAULT_LOAD_FACTOR = 0.75f;
private final int MAX_CAPACITY;
private LinkedHashMap<K, V> map;
public Cache(int capacity, boolean accessOrder) {
capacity = (int) Math.ceil((MAX_CAPACITY = capacity) / DEFAULT_LOAD_FACTOR) + 1;
map = new LinkedHashMap(capacity, DEFAULT_LOAD_FACTOR, accessOrder) {
@Override
protected boolean removeEldestEntry(Map.Entry eldest) {
return size() > MAX_CAPACITY;
}
};
}
public synchronized void put(K key, V value) {
map.put(key, value);
}
public synchronized V get(K key) {
return map.get(key);
}
@Override
public String toString() {
StringBuilder sb = new StringBuilder();
for (Map.Entry entry : map.entrySet()) {
sb.append(String.format("%s:%s ", entry.getKey(), entry.getValue()));
}
return sb.toString();
}
}
以上是就是一个LinkedHashMap的简单应用,
- 当
accessOrder = true时,就是LRUCache, - 当
accessOrder = false时,就是FIFOCache;
// LRUCache
Cache<String, String> cache = new Cache<>(3, true);
cache.put("a", "1");
cache.put("b", "2");
cache.put("c", "3");
cache.put("d", "4");
cache.get("c");
System.out.println(cache);
// 打印:b:2 d:4 c:3
// FIFOCache
Cache<String, String> cache = new Cache<>(3, false);
cache.put("a", "1");
cache.put("b", "2");
cache.put("c", "3");
cache.put("d", "4");
cache.get("c");
System.out.println(cache);
// 打印:b:2 c:3 d:4
总结
- 总体而言
LinkedHashMap的代码比较简单,但是我觉得里面代码的组织,逻辑的提取等方面特别值得借鉴;
JDK源码分析(6)之 LinkedHashMap 相关的更多相关文章
- JDK 源码分析(4)—— HashMap/LinkedHashMap/Hashtable
JDK 源码分析(4)-- HashMap/LinkedHashMap/Hashtable HashMap HashMap采用的是哈希算法+链表冲突解决,table的大小永远为2次幂,因为在初始化的时 ...
- 【JDK】JDK源码分析-LinkedHashMap
概述 前文「JDK源码分析-HashMap(1)」分析了 HashMap 主要方法的实现原理(其他问题以后分析),本文分析下 LinkedHashMap. 先看一下 LinkedHashMap 的类继 ...
- 【JDK】JDK源码分析-HashMap(1)
概述 HashMap 是 Java 开发中最常用的容器类之一,也是面试的常客.它其实就是前文「数据结构与算法笔记(二)」中「散列表」的实现,处理散列冲突用的是“链表法”,并且在 JDK 1.8 做了优 ...
- JDK源码分析(三)—— LinkedList
参考文档 JDK源码分析(4)之 LinkedList 相关
- JDK源码分析(一)—— String
dir 参考文档 JDK源码分析(1)之 String 相关
- 【JDK】JDK源码分析-TreeMap(2)
前文「JDK源码分析-TreeMap(1)」分析了 TreeMap 的一些方法,本文分析其中的增删方法.这也是红黑树插入和删除节点的操作,由于相对复杂,因此单独进行分析. 插入操作 该操作其实就是红黑 ...
- 【JDK】JDK源码分析-Vector
概述 上文「JDK源码分析-ArrayList」主要分析了 ArrayList 的实现原理.本文分析 List 接口的另一个实现类:Vector. Vector 的内部实现与 ArrayList 类似 ...
- 【JDK】JDK源码分析-List, Iterator, ListIterator
List 是最常用的容器之一.之前提到过,分析源码时,优先分析接口的源码,因此这里先从 List 接口分析.List 方法列表如下: 由于上文「JDK源码分析-Collection」已对 Collec ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(2)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(1)」初步分析了 AQS,其中提到了 Node 节点的「独占模式」和「共享模式」,其实 AQS 也主要是围绕对这两种模 ...
- 【JDK】JDK源码分析-AbstractQueuedSynchronizer(3)
概述 前文「JDK源码分析-AbstractQueuedSynchronizer(2)」分析了 AQS 在独占模式下获取资源的流程,本文分析共享模式下的相关操作. 其实二者的操作大部分是类似的,理解了 ...
随机推荐
- C#封装的websocket协议类
关于VB版之前已经写了,有需要可以进传送门<VB封装的WebSocket模块,拿来即用>,两个使用都差不多,这里简单概述一下: 连接完成后,没有握手就用Handshake()先完成握手之后 ...
- 安装selenium
步骤: 1.下载setuptools2.点击安装setuptools.exe3.安装成功后,python的安装目录下会有Scripts的文件夹4.配置环境变量:python安装目录\Scripts5. ...
- Markdown基础语法笔记
# 一级标题## 二级标题### 三级标题###### #号之后记得加一个空格 仅支持1-6级标题 ### 列表 - 文本1 - 文本2 - 文本3+ 列表2* 列表2 ### 有序列表1. 有序文 ...
- C# yield return 和 yield break
yield关键字用于遍历循环中,yield return用于返回IEnumerable<T>,yield break用于终止循环遍历. 以下对比了使用yield return与不使用yie ...
- oracle的知识点总结
体系结构:数据库的体系结构是指数据库的组成.工作过程与原理,以及数据在数据库中的组织与管理机制.体系结构包括:实例(instence),数据库文件(database),用户进程(user proces ...
- Python tkinter 学习记录(一) --label 与 button
最简的形式 from tkinter import * root = Tk() # 创建一个Tk实例 root.wm_title("标题") # 修改标题 root.mainloo ...
- Android APK 瘦身 - JOOX Music项目实战
导语 JOOX Music是腾讯海外布局的一个音乐产品,2014年发布以来已经成为5个国家和地区排名第一的音乐App.东南亚是JOOX Music的主要发行地区,由于JOOX Music所面对的市场存 ...
- gps 经纬度 转换实际距离
<!doctype html> <html lang="zh-CN"> <head> <meta charset="utf-8& ...
- numpy.random 常用函数详解之简单随机数篇(Simple random data)
1.numpy.random.rand(d0,d1,d2,...,dn) 参数:d0,d1,d2,...,dn 须是正整数,用来描述生成随机数组的维度.如(3,2)代表生成3行2列的随机数组. 返回值 ...
- 什么是REST接口
转载自:http://baijiahao.baidu.com/s?id=1591007540303121112&wfr=spider&for=pc 从事web开发工作有一小段时间,RE ...