Oracle学习笔记二
多表查询:
笛卡尔积: 实际上是两张表的乘积,但是在实际开发中没有太大意义
格式: select * from 表1,表2
select * from emp;
select * from dept;
select * from emp, dept;
select * from emp e1, dept d1 where e1.deptno = d1.deptno;
连接类型分类
内联接
隐式内联接
等值内联接: where e1.deptno = d1.deptno;
不等值内联接: where e1.deptno <> d1.deptno;
自联接: 自己连接自己
显示内联接
select * from 表1 inner join 表2 on 连接条件 --inner 关键字可以省略
select * from emp e1, dept d1 where e1.deptno <> d1.deptno;
--查询员工编号,员工姓名,经理的编号,经理的姓名
select e1.empno,e1.ename,e1.mgr,m1.ename
from emp e1, emp m1 where e1.mgr= m1.empno;
--查询员工编号,员工姓名,员工的部门名称,经理的编号,经理的姓名
select e1.empno,e1.ename,d1.dname,e1.mgr,m1.ename
from emp e1, emp m1,dept d1 where e1.mgr= m1.empno and e1.deptno = d1.deptno;
--查询员工编号,员工姓名,员工的部门名称,经理的编号,经理的姓名,经理的部门名称
select e1.empno,e1.ename,d1.dname,e1.mgr,m1.ename,d2.dname
from emp e1, emp m1,dept d1,dept d2
where
e1.mgr= m1.empno
and e1.deptno = d1.deptno
and m1.deptno = d2.deptno
;
--查询员工编号,员工姓名,员工的部门名称,员工的工资等级,经理的编号,经理的姓名,经理的部门名称
select e1.empno,e1.ename,d1.dname,s1.grade,e1.mgr,m1.ename,d2.dname
from emp e1, emp m1,dept d1,dept d2,salgrade s1
where
e1.mgr= m1.empno
and e1.deptno = d1.deptno
and m1.deptno = d2.deptno
and e1.sal between s1.losal and s1.hisal
;
--查询员工编号,员工姓名,员工的部门名称,员工的工资等级,经理的编号,经理的姓名,经理的部门名称,经理的工资等级
select e1.empno,e1.ename,d1.dname,s1.grade,e1.mgr,m1.ename,d2.dname,s2.grade
from emp e1, emp m1,dept d1,dept d2,salgrade s1,salgrade s2
where
e1.mgr= m1.empno
and e1.deptno = d1.deptno
and m1.deptno = d2.deptno
and e1.sal between s1.losal and s1.hisal
and m1.sal between s2.losal and s2.hisal
;
--查询员工编号,员工姓名,员工的部门名称,员工的工资等级,经理的编号,经理的姓名,经理的部门名称,经理的工资等级,将工资等级 1,2,3,4 显示成 中文的 一级 二级 三级...
select e1.empno,
e1.ename,
d1.dname,
case s1.grade
when 1 then '一级'
when 2 then '二级'
when 3 then '三级'
when 4 then '四级'
else
'五级'
end "等级",
e1.mgr,
m1.ename,
d2.dname,
decode(s2.grade,1,'一级',2,'二级',3,'三级',4,'四级','五级') "等级"
from emp e1, emp m1,dept d1,dept d2,salgrade s1,salgrade s2
where
e1.mgr= m1.empno
and e1.deptno = d1.deptno
and m1.deptno = d2.deptno
and e1.sal between s1.losal and s1.hisal
and m1.sal between s2.losal and s2.hisal
;
--查询员工姓名和员工部门所处的位置
select e1.ename,d1.loc from emp e1,dept d1 where e1.deptno = d1.deptno;
select * from emp e1 inner join dept d1 on e1.deptno = d1.deptno;
外链接:(标准,通用写法)
左外连接: left outer join 左表中所有的记录,如果右表没有对应记录,就显示空
右外连接: right outer join 右表中的所有记录,如果左表没有对应记录,就显示空
outer 关键字可以省略
注:Oracle中的外连接: (+) 实际上是如果没有对应的记录就加上空值
select * from emp e1,dept d1 where e1.deptno = d1.deptno(+);
select * from emp e1 left outer join dept d1 on e1.deptno = d1.deptno;
insert into emp(empno,ename) values(9527,'HUAAN');
select * from emp e1,dept d1 where e1.deptno = d1.deptno(+);
select * from emp e1 right outer join dept d1 on e1.deptno = d1.deptno;
select * from emp e1,dept d1 where e1.deptno(+) = d1.deptno;
子查询: 查询语句中嵌套查询语句; 用来解决复杂的查询语句
查询最高工资的员工信息
单行子查询: > >= = < <= <> !=
多行子查询: in not in >any >all exists not exists
--查询最高工资的员工信息
--1.查询出最高工资 --5000
select max(sal) from emp;
--2. 工资等于最高工资
select * from emp where sal = (select max(sal) from emp);
--查询出比雇员7654的工资高,同时和7788从事相同工作的员工信息
--1.雇员7654的工资 1250
select sal from emp where empno = 7654;
--2.7788从事的工作 ANALYST
select job from emp where empno = 7788;
--3.两个条件合并
select * from emp where sal > 1250 and job = 'ANALYST';
select * from emp where sal > (select sal from emp where empno = 7654) and job = (select job from emp where empno = 7788);
--查询每个部门最低工资的员工信息和他所在的部门信息
--1.查询每个部门的最低工资,分组统计
select deptno,min(sal) minsal from emp group by deptno;
--2.员工工资等于他所处部门的最低工资
select *
from emp e1,
(select deptno,min(sal) minsal from emp group by deptno) t1
where e1.deptno = t1.deptno and e1.sal = t1.minsal;
--3.查询部门相关信息
select *
from emp e1,
(select deptno,min(sal) minsal from emp group by deptno) t1,
dept d1
where e1.deptno = t1.deptno and e1.sal = t1.minsal and e1.deptno = d1.deptno;
内连接:(单行子查询,多行子查询)
in
not in
any
all
exists
通常情况下, 数据库中不要出现null 最好的做法加上Not null,null值并不代表不占空间, char(100) null 100个字符
--查询领导信息
--1.查询所有经理的编号
select mgr from emp;
select distinct mgr from emp;
--2.结果
select * from emp where empno in (select mgr from emp);
--查询不是领导的信息
select * from emp where empno not in (select mgr from emp);
select * from emp where empno <>all(select mgr from emp);
--正确的写法
select * from emp where empno not in (select mgr from emp where mgr is not null);
--查询出比10号部门任意一个员工薪资高的员工信息 10 20 30
select * from emp where sal >any (select sal from emp where deptno = 10);
--查询出比20号部门所有员工薪资高的员工信息 10 20 30
--1.20号最高工资 5000
select max(sal) from emp where deptno =20;
--2.员工信息
select * from emp where sal > (select max(sal) from emp where deptno =20);
--使用多行子查询完成上面这题
--20号部门所有员工薪资 (800 2975 ...)
select sal from emp where deptno = 20;
--大于集合所有的
select * from emp where sal >all(select sal from emp where deptno = 20);
exists(查询语句) : 存在的意思,判断一张表里面的记录是否存在与另外一张表中
当作布尔值来处理:当查询语句有结果的时候, 就是返回true,否则返回的是false,数据量比较大的时候是非常高效的
select * from emp where exists(select * from emp where deptno = 1234567);
select * from emp where 3=4;
select * from emp where exists(select * from emp where deptno = 20);
--查询有员工的部门的信息
select * from dept d1 where exists(select * from emp e1 where e1.deptno = d1.deptno );
--找到员工表中工资最高的前三名(降序排序)
select * from emp order by sal desc;
rownum : 伪列, 系统自动生成的一列, 用来表示行号
rownum是Oracle中特有的用来表示行号的, 默认值/起始值是 1 ,在每查询出结果之后,再添加1
rownum最好不能做大于号判断,可以做小于号判断
SQL执行顺序:from .. where ..group by..having .. select..rownum..order by
--查询rownum大于2的所有记录
select rownum,e1.* from emp e1 where rownum > 2; --没有任何记录
--查询rownum大于等于1的所有记录
select rownum,e1.* from emp e1 where rownum >=1;
--查询rownum < 6 的所有记录
select rownum,e1.* from emp e1 where rownum < 6;
--rownum 排序
Select rownum,e1.* from emp e1 order by sal;
--找到员工表中工资最高的前三名
select e1.* from emp e1 order by sal desc;
--将上面的结果当作一张表处理,再查询
select rownum, t1.* from (select e1.* from emp e1 order by sal desc) t1;
--只要显示前三条记录
select rownum, t1.* from (select e1.* from emp e1 order by sal desc) t1 where rownum < 4;
--找到员工表中薪水大于本部门平均薪水的员工
--1.分组统计部门平均薪水
select deptno,avg(sal) avgsal from emp group by deptno;
--2.员工工资 > 本部门平均工资
select * from emp e1,(select deptno,avg(sal) avgsal from emp group by deptno) t1
where e1.deptno = t1.deptno and e1.sal > t1.avgsal;
关联子查询 || 非关联子查询
select * from emp e where sal > (select avg(sal) from emp e2 group by deptno having e.deptno=e2.deptno);
--统计每年入职的员工个数
select hiredate from emp;
--只显示年份
select to_char(hiredate,'yyyy') from emp;
--分组统计
select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy');
select yy
from
(select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt;
select case yy when '1987' then cc end
from
(select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt;
select case yy when '1987' then cc end "1987"
from
(select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt;
--去除行记录中的空值
select sum(case yy when '1987' then cc end) "1987"
from
(select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt;
--统计员工的总数
select sum(cc) "TOTAL"
from
(select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt;
--将1987 和TOTAL 合并在一起
select
sum(cc) "TOTAL",
sum(case yy when '1987' then cc end) "1987"
from
(select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt;
--显示所有年份的结果
select
sum(cc) "TOTAL",
sum(case yy when '1980' then cc end) "1980",
sum(case yy when '1981' then cc end) "1981",
sum(case yy when '1982' then cc end) "1982",
sum(case yy when '1987' then cc end) "1987"
from
(select to_char(hiredate,'yyyy') yy,count(1) cc from emp group by to_char(hiredate,'yyyy')) tt;
rowid : 伪列 每行记录所存放的真实物理地址
rownum : 行号 , 每查询出记录之后,就会添加一个行号
select rowid,e.* from emp e;
--去除表中重复记录
create table p(
name varchar2(10)
);
insert into p values('黄伟福');
insert into p values('赵洪');
insert into p values('杨华');
delete from p where
select rowid,p.* from p;
select distinct * from p;
delete from p p1 where rowid > (select min(rowid) from p p2 where p1.name = p2.name);
分页查询:在oracle中只能使用子查询来做分页查询
--查询第6 - 第10 记录
select rownum, emp.* from emp;
select rownum hanghao, emp.* from emp;
select * from (select rownum hanghao, emp.* from emp) tt where tt.hanghao between 6 and 10;
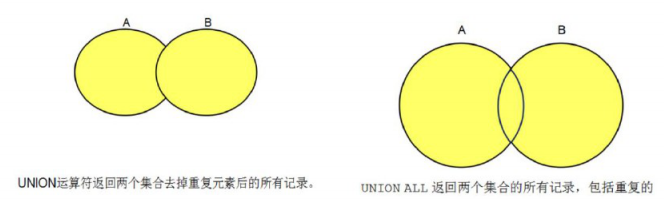
集合运算
并集: 将两个查询结果进行合并
交集:
差集:
--工资大于1500,或者20号部门下的员工
select * from emp where sal > 1500 or deptno = 20;
--工资大于1500
select * from emp where sal > 1500;
--20号部门下的员工
select * from emp where deptno = 20;
并集运算: union union all
union : 去除重复的,并且排序
union all : 不会去除重复的
select * from emp where sal > 1500
union
select * from emp where deptno = 20;
select * from emp where sal > 1500
union all
select * from emp where deptno = 20;
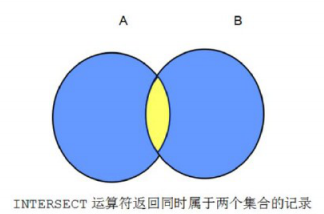
交集运算: intersect
--工资大于1500,并且20号部门下的员工
select * from emp where sal > 1500;
select * from emp where deptno = 20;
select * from emp where sal > 1500
intersect
select * from emp where deptno = 20;
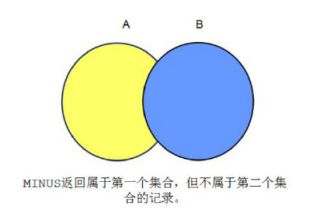
差集运算: 两个结果相减
--1981年入职员工(不包括总裁和经理)
--1981年入职员工
select * from emp where to_char(hiredate,'yyyy')='1981';
--总裁和经理
select * from emp where job = 'PRESIDENT' or job = 'MANAGER';
select * from emp where to_char(hiredate,'yyyy')='1981'
minus
select * from emp where job = 'PRESIDENT' or job = 'MANAGER';
集合运算中的注意事项:
1.列的类型要一致
2.按照顺序写
3.列的数量要一致,如果不足,用空值填充
select ename,sal from emp where sal > 1500
union
select ename,sal from emp where deptno = 20;
--列的类型不匹配
select ename,sal from emp where sal > 1500
union
select sal,ename from emp where deptno = 20;
--列的数量不匹配
select ename,sal,deptno from emp where sal > 1500
union
select ename,sal from emp where deptno = 20;
select ename,sal,deptno from emp where sal > 1500
union
select ename,sal,null from emp where deptno = 20;
select ename,sal,deptno from emp where sal > 1500
union
select ename,sal,66 from emp where deptno = 20;
Oracle学习笔记二的更多相关文章
- Oracle 学习笔记(二)
一.索引 表的数据是无序的,所以叫堆表(heap table),意思为随机存储数据.因为数据是随机存储的,所以在查询的时候需要全表扫描.索引就是将无序的数据有序化,这样就可以在查询数据的时候 减少数据 ...
- Oracle 学习笔记二
一.oracle通用函数vnl(a,b) 用于任何类型,如果a的值不为null返回a的值否则返回b的值 条件判断oracle中可以使用 case 字段 when 条件1 then 表达式1 when ...
- Oracle学习笔记二 初识Oracle(二)
Windows 中的 Oracle 服务 Oracle 9i的每个实例在Windows中都作为一项服务启动 服务是在 Windows 注册表中注册的可执行进程,由 Windows 操作系统管理 “服务 ...
- oracle学习笔记(二)
1. Oracle字符串操作 1.1. 字符串类型 1.1.1. CHAR和VARCHAR2类型 CHAR和VARCHAR2类型都是用来表示字符串数据类型,用来在表中存放字符串信息, 比如姓名.职业. ...
- Oracle学习笔记三 SQL命令
SQL简介 SQL 支持下列类别的命令: 1.数据定义语言(DDL) 2.数据操纵语言(DML) 3.事务控制语言(TCL) 4.数据控制语言(DCL)
- oracle学习笔记第一天
oracle学习笔记第一天 --oracle学习的第一天 --一.几个基础的关键字 1.select select (挑选) 挑选出显示的--列--(可以多列,用“,”隔开,*表示所有列),为一条 ...
- Oracle学习笔记—数据字典和常用命令(转载)
转载自: oracle常用数据字典和SQL语句总结 Oracle常用命令大全(很有用,做笔记) 一.Oracle数据字典 数据字典是Oracle存放有关数据库信息的地方,其用途是用来描述数据的.比如一 ...
- WPF的Binding学习笔记(二)
原文: http://www.cnblogs.com/pasoraku/archive/2012/10/25/2738428.htmlWPF的Binding学习笔记(二) 上次学了点点Binding的 ...
- AJax 学习笔记二(onreadystatechange的作用)
AJax 学习笔记二(onreadystatechange的作用) 当发送一个请求后,客户端无法确定什么时候会完成这个请求,所以需要用事件机制来捕获请求的状态XMLHttpRequest对象提供了on ...
随机推荐
- Win10 安装Oracle11g2、配置PL/SQL Developer11环境
Oracle11g2的下载地址(下载以下两个压缩包,解压后得到两个oracle目录,放到一起就得到完整的安装文件了): 1.Oracle11g2: oracle-part-1 oracle-part- ...
- [POJ1193][NOI1999]内存分配(链表+模拟)
题意 时 刻 T 内存占用情况 进程事件 0 1 2 3 4 5 6 7 8 9 进程A申请空间(M=3, P=10)<成功> 1 A 2 A B 进程B申请空间(M=4, P=3)< ...
- [jzoj]3506.【NOIP2013模拟11.4A组】善良的精灵(fairy)(深度优先生成树)
Link https://jzoj.net/senior/#main/show/3506 Description 从前有一个善良的精灵. 一天,一个年轻人B找到她并请他预言他的未来.这个精灵透过他的水 ...
- String.matches()的用法
https://blog.csdn.net/victoryckl/article/details/6930409
- 实现简单的promise
只考虑成功时的调用,方便理解一下promise的原理promise的例子: 1. 接下来一步步实现一个简单的promise step1:promise 接受一个函数作为构造函数的参数,是立即执行的,并 ...
- 上传插件webupload之调用拍照兼容问题
在项目中,移动端用到了webupload插件来实现上传功能(我觉得这个插件挺好用的,所以无论pc还是移动端我都使用了这个插件来做上传功能) 在移动端要调起拍照功能,实现上传,须得在webuploade ...
- 多路分支----switch语句
switch-case与if-else有相似的作用,都是表达分支的方式. 语法形式: switch(type){ case 常量1: do something; break; case 常量2: do ...
- Go语言基础之结构体
Go语言基础之结构体 Go语言中没有“类”的概念,也不支持“类”的继承等面向对象的概念.Go语言中通过结构体的内嵌再配合接口比面向对象具有更高的扩展性和灵活性. 类型别名和自定义类型 自定义类型 在G ...
- 4.28Linux(6)
2019-4-28 21:27:41 明天回家.回家继续学Linux还好有个服务器!!!感觉有个属于自己的服务器感觉好爽啊!! 越努力越幸运!永远不要高估自己!!! Nginx安装 服务器的请求原理 ...
- 玩转vue前进刷新,后退不刷新and按需刷新
大白萝卜小课堂开讲了!带你玩转vue前进后退按需刷新! 用vue做后台管理项目,特别是有列表页.列表数据详情页.列表数据修改页功能的码友们,几乎都被vue前进后退都刷新的逻辑坑过,本萝卜更是! 萝卜的 ...