关于操作HDFS的一个问题
一、问题起源及详细异常
近日写程序定时任务调Hadoop MR程序,然后生成报表,发送邮件,当时起了两个任务A和B,调MR程序之前,会操作hdfs(读写都有),任务A每天一点跑,任务B每十分钟跑一次,B任务不会调用MR程序,纯粹采集数据。结果第一天就发现任务A没有发送邮件,于是乎查日志,异常信息如下
java.io.IOException: Failed on local exception: java.io.InterruptedIOException: Interrupted while waiting for IO on channel java.nio.channels.SocketChannel[connected local=/10.1.23.249:52305 remote=/10.1.23.249:9000]. 60000 millis timeout left.; Host Details : local host is: "hadoop-alone-test/10.1.23.249"; destination host is: "hadoop-alone-test":9000;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:776)
at org.apache.hadoop.ipc.Client.call(Client.java:1479)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy109.getListing(Unknown Source)
........
当时有点懵,不知道为什么出现这种IO被中断。于是乎,我在job控制台再调一下,并没有出现错误。本来想看看源码,但是领导安排了个比较紧急的任务。忙了几天,期间没有仔细去管,我只是注意了下每天的邮件,发现还是有的时候会成功的。忙完了任务,赶紧来排查,再看日志,发现报的错不止这一种,下面列出其他错误
java.io.IOException: Failed on local exception: java.io.IOException; Host Details : local host is: "hadoop-alone-test/10.1.23.249"; destination host is: "hadoop-alone-test":9000;
at org.apache.hadoop.net.NetUtils.wrapException(NetUtils.java:776)
at org.apache.hadoop.ipc.Client.call(Client.java:1479)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy109.getFileInfo(Unknown Source)
...........
java.io.IOException: Filesystem closed
at org.apache.hadoop.hdfs.DFSClient.checkOpen(DFSClient.java:808)
at org.apache.hadoop.hdfs.DFSClient.listPaths(DFSClient.java:2083)
at org.apache.hadoop.hdfs.DistributedFileSystem$DirListingIterator.<init>(DistributedFileSystem.java:944)
at org.apache.hadoop.hdfs.DistributedFileSystem$DirListingIterator.<init>(DistributedFileSystem.java:927)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:872)
at org.apache.hadoop.hdfs.DistributedFileSystem$19.doCall(DistributedFileSystem.java:868)
at org.apache.hadoop.fs.FileSystemLinkResolver.resolve(FileSystemLinkResolver.java:81)
................
java.io.IOException: The client is stopped
at org.apache.hadoop.ipc.Client.getConnection(Client.java:1507)
at org.apache.hadoop.ipc.Client.call(Client.java:1451)
at org.apache.hadoop.ipc.Client.call(Client.java:1412)
at org.apache.hadoop.ipc.ProtobufRpcEngine$Invoker.invoke(ProtobufRpcEngine.java:229)
at com.sun.proxy.$Proxy109.getFileInfo(Unknown Source)
at org.apache.hadoop.hdfs.protocolPB.ClientNamenodeProtocolTranslatorPB.getFileInfo(ClientNamenodeProtocolTranslatorPB.java:771)
at sun.reflect.GeneratedMethodAccessor69.invoke(Unknown Source)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
就是上述这四个错误,都是和io通信有关,然后都出现在操作Hadoop的FileSystem那段代码,且任务A和B都不等量的出现过,而且出现在凌晨一点,两个线程同时操作的时候,所以问题很明确,出在并发上面,联系到上面的FileSystem被关闭,我代码确实是调用了close方法
于是查看了一下源码,创建FileSystem的时候有如下代码
String disableCacheName = String.format("fs.%s.impl.disable.cache", scheme);
return conf.getBoolean(disableCacheName, false) ? createFileSystem(uri, conf) : CACHE.get(uri, conf);
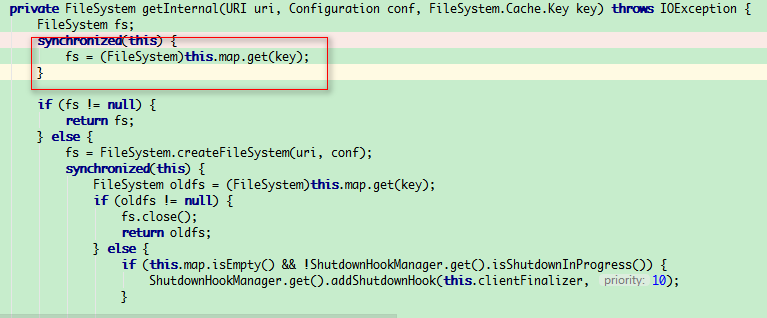
创建FileSystem的时候读取配置"fs.%s.impl.disable.cache",默认为false,所以第二次走了缓存, FileSystem的URI相同的话,一定只创建一个FileSystem
涉及到多线程访问,而线程B已经调用了filesystem.close()方法,这个时候线程A还在操作filesystem,所以报错上面种种异常
二、解决办法
1、代码同步(这里就不贴代码,用synchronized、lock这些都行)
2、禁用FileSystem缓存
代码里
Configuration conf = new Configuration();
conf.set("fs.hdfs.impl.disable.cache", "true");
core-site.xml文件里面配置(二者选其一)
<property>
<name>fs.hdfs.impl.disable.cache</name>
<value>true</value>
</property>
关于操作HDFS的一个问题的更多相关文章
- java操作hdfs实例
环境:window7+eclipse+vmware虚拟机+搭建好的hadoop环境(master.slave01.slave02) 内容:主要是在windows环境下,利用eclipse如何来操作hd ...
- Hadoop操作hdfs的命令【转载】
本文系转载,原文地址被黑了,故无法贴出原始链接. Hadoop操作HDFS命令如下所示: hadoop fs 查看Hadoop HDFS支持的所有命令 hadoop fs –ls 列出目录及文件信息 ...
- 使用javaAPI操作hdfs
欢迎到https://github.com/huabingood/everyDayLanguagePractise查看源码. 一.构建环境 在hadoop的安装包中的share目录中有hadoop所有 ...
- 使用Java API操作HDFS文件系统
使用Junit封装HFDS import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.fs.*; import org ...
- 使用Eclipse来操作HDFS的文件
一.常用类 1.Configuration Hadoop配置文件的管理类,该类的对象封装了客户端或者服务器的配置(配置集群时,所有的xml文件根节点都是configuration) 创建一个Confi ...
- Hadoop Java API操作HDFS文件系统(Mac)
1.下载Hadoop的压缩包 tar.gz https://mirrors.tuna.tsinghua.edu.cn/apache/hadoop/common/stable/ 2.关联jar包 在 ...
- Hadoop基础-通过IO流操作HDFS
Hadoop基础-通过IO流操作HDFS 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.上传文件 /* @author :yinzhengjie Blog:http://www ...
- 使用Java Api 操作HDFS
如题 我就是一个标题党 就是使用JavaApi操作HDFS,使用的是MAVEN,操作的环境是Linux 首先要配置好Maven环境,我使用的是已经有的仓库,如果你下载的jar包 速度慢,可以改变Ma ...
- Java代码操作HDFS测试类
1.Java代码操作HDFS需要用到Jar包和Java类 Jar包: hadoop-common-2.6.0.jar和hadoop-hdfs-2.6.0.jar Java类: java.net.URL ...
随机推荐
- 是时候理解下HTTPS的原理及流程了
1.什么是HTTP协议? HTTP协议是Hyper Text Transfer Protocol(超文本传输协议),位于TCP/IP模型当中的应用层.HTTP协议通过请求/响应的方式,在客户端和服务端 ...
- MVC 全局过滤器
1. 新创建一个类 CheckLogin2. 在类中加入以下代码 public class CheckLogin : ActionFilterAttribute { public override v ...
- 工具(1): 极简Word排版示例(Example by Word2013)
文档标题 第一行写下文档的名字,居中,微软雅黑字体,三号 章节标题 每一章的标题单独一行,光标选中这行,设置为标题1 每一节的标题单独一行,光标选中这行,设置为标题2 全部章节标题设置完毕后,下一步 ...
- 微信网页分享 jssdk config:invalid signature 签名错误
invalid signature签名错误.建议按如下顺序检查: 确认签名算法正确,可用 http://mp.weixin.qq.com/debug/cgi-bin/sandbox?t=jsapisi ...
- 查看电脑系统参数(Windows)
发现工作的电脑开了很多任务,都运行的很好,所以记录下来(以后买电脑可以参考一下) 一.硬件详情(i5第七代?) 硬盘信息(分有固态和机械硬盘): 固态硬盘直接给了系统使用: 二.体验指数(基本都达到了 ...
- 如何在django视图中使用asyncio(协程)和ThreadPoolExecutor(多线程)
Django视图函数执行,不在主线程中,直接 loop = asyncio.new_event_loop() # 更不能loop = asyncio.get_event_loop() 会触发 Runt ...
- Python基础:搭建开发环境(1)
1.Python语言简介 2.Python环境 Python环境产品存在多个. 2.1 CPython CPython是Python官方提供的.一般情况下提到的Python就是指CPython,CPy ...
- Leetcode 4.28 string
1. 38. Count and Say 就是对于前一个数,找出相同元素的个数,把个数和该元素存到新的string里.数量+字符 class Solution { public String coun ...
- iptables 限制ip访问3306端口
*filter:INPUT DROP [0:0] #全部关闭:FORWARD ACCEPT [0:0]:OUTPUT ACCEPT [0:0]-A INPUT -s 172.4.4.14 -p tc ...
- UOJ 7 NOI2014 购票
题意:给一棵树计算一下各个点在距离限制下以一定的费用公式通过不停地到祖先最后到达一号点的最小花费. 第一种做法:线段树维护带修凸壳.显然的,这个公式计算是p*x+q 所以肯定和斜率有关系.然后这题的d ...