jieba库的使用与词频统计
1、词频统计
(1)词频分析是对文章中重要词汇出现的次数进行统计与分析,是文本
挖掘的重要手段。它是文献计量学中传统的和具有代表性的一种内容分析方法,基本原理是通过词出现频次多少的变化,来确定热点及其变化趋势。
(2)安装jieba库
安装说明
代码对 Python 2/3 均兼容
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
半自动安装:先下载 http://pypi.python.org/pypi/jieba/ ,解压后运行 python setup.py install
手动安装:将 jieba 目录放置于当前目录或者 site-packages 目录
通过 import jieba 来引用
示例、全自动安装
在命令行下输入指令:
pip install jieba
(2) 安装进程:

2、调用库函数
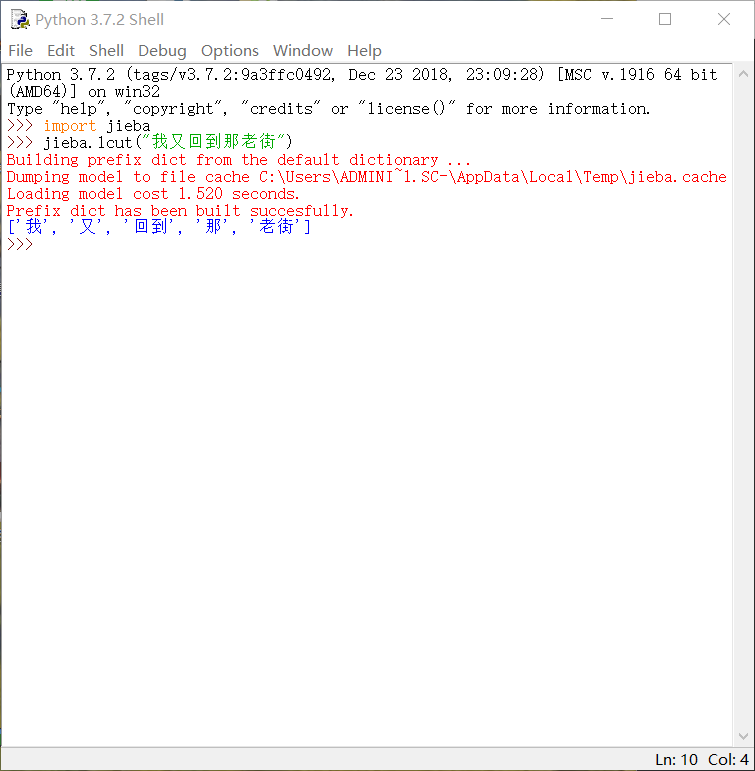
1、输入import jieba与使用其中函数
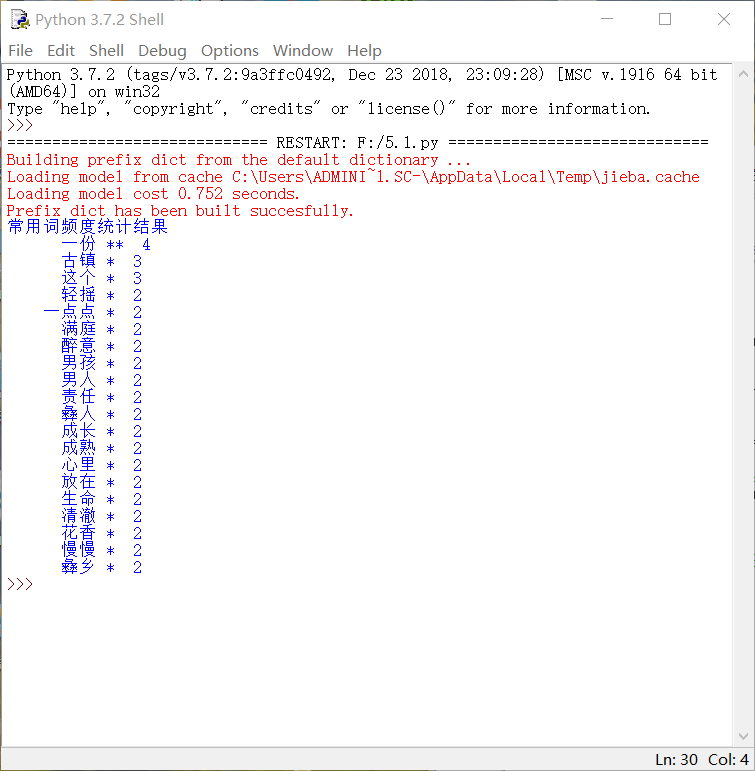
3、python代码
#! python3
# -*- coding: utf- -*-
import os, codecs
import jieba
from collections import Counter def get_words(txt):
seg_list = jieba.cut(txt) #对文本进行分词
c = Counter()
for x in seg_list: #进行词频统计
if len(x)> and x != '\r\n':
c[x] +=
print('常用词频度统计结果')
for (k,v) in c.most_common(): #遍历输出高频词
print('%s%s %s %d' % (' '*(-len(k)), k, '*'*int(v/2), v)) if __name__ == '__main__':
with codecs.open('梦里花落知多少.txt', 'r', 'utf8') as f:
txt = f.read()
get_words(txt)
• •显示效果
4、词云
import jieba
import wordcloud
f = open("梦里花落知多少.txt","r",encoding = "utf-8") #打开文件
t = f.read() #读取文件,并存好
f.close()
ls = jieba.lcut(t) #对文本分词
txt = " ".join(ls) #对文本进行标点空格化
w = wordcloud.WordCloud(font_path = "msyh.ttc",width = ,height = ,background_color = "white") #设置词云背景,找到字体路径(否则会乱码)
w.generate(txt) #生成词云
w.to_file("govermentwordcloud.png") #保存词云图
• 词云显示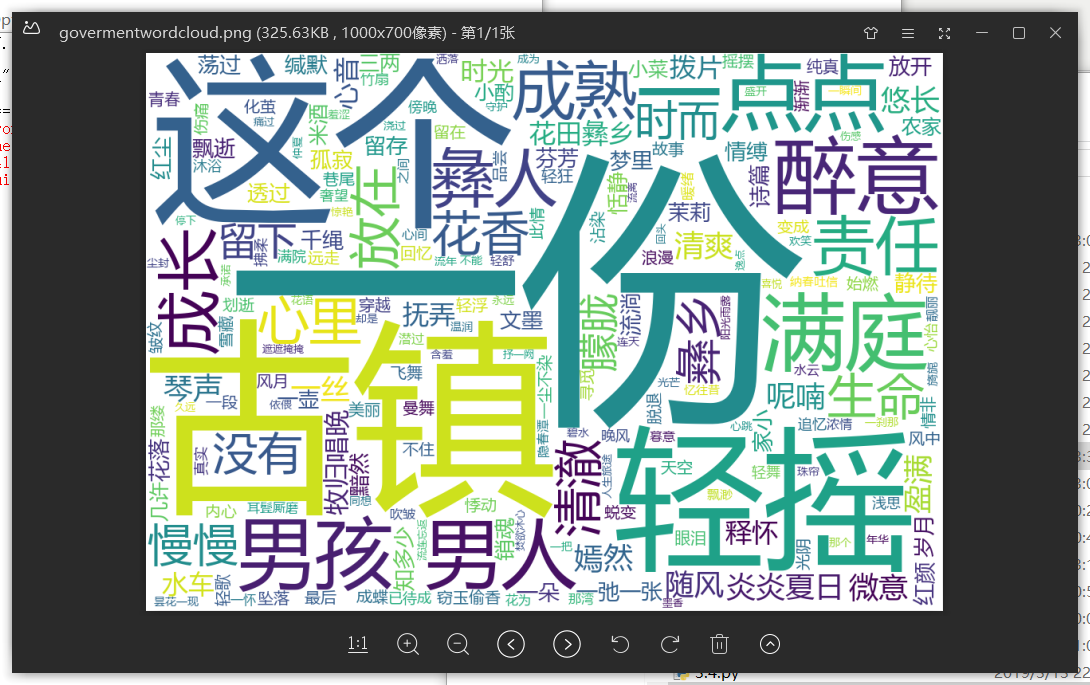
jieba库的使用与词频统计的更多相关文章
- jieba库及wordcloud库的使用
知识内容: 1.jieba库的使用 2.wordcloud库的使用 参考资料: https://github.com/fxsjy/jieba https://blog.csdn.net/fontthr ...
- 用jieba库统计文本词频及云词图的生成
一.安装jieba库 :\>pip install jieba #或者 pip3 install jieba 二.jieba库解析 jieba库主要提供提供分词功能,可以辅助自定义分词词典. j ...
- jieba库词频统计
一.jieba 库简介 (1) jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最大概率的词组:除此之外,jieba 库还提供了增加自定义中文 ...
- py库: jieba (中文词频统计) 、collections (字频统计)、WordCloud (词云)
先来个最简单的: # 查找列表中出现次数最多的值 ls = [1, 2, 3, 4, 5, 6, 1, 2, 1, 2, 1, 1] ls = ["呵呵", "呵呵&qu ...
- 利用python jieba库统计政府工作报告词频
1.安装jieba库 舍友帮装的,我也不会( ╯□╰ ) 2.上网寻找政府工作报告 3.参照课本三国演义词频统计代码编写 import jieba txt = open("D:\政府工作报告 ...
- Python之利用jieba库做词频统计且制作词云图
一.环境以及注意事项 1.windows10家庭版 python 3.7.1 2.需要使用到的库 wordcloud(词云),jieba(中文分词库),安装过程不展示 3.注意事项:由于wordclo ...
- jieba库词频统计练习
在sypder上运行jieba库的代码: import matplotlib.pyplot as pltfracs = [2,2,1,1,1]labels = 'houqin', 'jiemian', ...
- jieba库分词词频统计
代码已发至github上的python文件 词频统计结果如下(词频为1的词组数量已省略): {'是': 5, '风格': 4, '擅长': 4, '的': 4, '兴趣': 4, '宣言': 4, ' ...
- 使用jieba库与wordcloud库第三方库进行词频统计
一.jieba库与wordcloud库的使用 1.jieba库与wordcloud库的介绍 jieba 库的分词原理是利用一个中文词库,将待分词的内容与分词词库进行比对,通过图结构和动态规划方法找到最 ...
随机推荐
- Node 环境变量 process.env.NODE_ENV 之webpack应用
转载来源:https://github.com/wfzong/NODE_ENV_TEST,这里还有源码可以学习,谢谢原作者的分享! 对于process.env.NODE_ENV困惑起因为在配置webp ...
- shiro 错误登陆次数限制
第一步:在spring-shiro.xml 中配置缓存管理器和认证匹配器 <!-- 缓存管理器 使用Ehcache实现 --><bean id="cacheManager& ...
- 用Mysql进行emp、dept、salgrade表的相关查询操作
初学者都会接触到三种表:emp.dept.salgrade表,进行练习各种语句操作再合适不过 但是,网上大多数的操作语句都是用oracle进行操作的,小编在学习mysql的时候,参考网上的书写遇到了不 ...
- VMware对虚拟机快照进行克隆
1.在关机状态下做一个快照 2.把快照管理器打开 3.右键快照,选择“克隆此快照” 4.选择要克隆的快照 5.选择克隆的方式 6.设置名称及保存的位置 注:虚拟机的快照是开机状态,不能对快照进行克隆
- unity中调试模型时unity崩溃问题
这个问题是在我调试3D模型资源时出现的,每当在Scene场景中调试模型时unity崩溃,出现Unity Bug Reporter页面,反复出现这个问题,很烧脑 对于这个问题我表示很无语,但是经过不断查 ...
- Linux Centos7.5中的RocketMQ集群部署
系统环境 Docker > centos7.5 此镜像已经安装了jdk1.8和maven3.6.0 如果你想知道这个基础镜像的具体情况, 参考此文: https://www.cnblogs.co ...
- datatable拆分多个
/// <summary> /// 分解数据表 /// </summary> /// <param name="originalTab">需要分 ...
- python 判断连个 Path 是否是相同的文件夹
python 判断连个 Path 是否是相同的文件夹 import os os.path.normcase(p1) == os.path.normcase(p2) normcase() 在 windo ...
- php的运行机制
php的解析过程是 apache -> httpd -> php5_module -> sapi -> php cgi (外部应用程序)只是用来解析php代码的 sapi中的其 ...
- HTML5通讯协议——WebSocket
1.导入maven依赖 <!-- websocket --> <dependency> <groupId>org.springframework</group ...