DeconvNet 论文阅读理解
学习语义分割反卷积网络DeconvNet
一点想法:反卷积网络就是基于FCN改进了上采样层,用到了反池化和反卷积操作,参数量2亿多,非常大,segnet把两个全连接层去掉,效果也能很好,显著减少了参数,只有290万,提升了性能
摘要
提出了一个创新的语义分割算法,反卷积网络。网络前几层用VGG16的结构。反卷积网络由反卷积层和反池化层组成,他们来实现像素级别的语义分割。我们把网络应用于输入图像得到每个结果,再将所有结果组合起来构成最终的语义分割图。这个方法可以降低现有的基于组合深度卷积网络和类别预测的全卷积网络的限制。我们的分割方法很好的识别了细节,也能应对不同尺度大小的物体。我们的网络在PASCAL VOC 2012数据集上取得了很好的成绩,同时在所有没有用额外数据的全卷积网络中取得了最高精度72.5%
1、介绍(introduction)
卷积神经网络在许多视觉识别问题上取得了惊人的表现,如图像分类[15,22,23],目标检测[7,9],语义分割[6,18],动作识别[12,21]。CNN强有力的表现取得了巨大的成功,用CNN提取特征再和一个简单的现成的分类器组合在实际操作中表现很好。由于CNN在分类问题上的成功,研究者们开始将其用于预测问题,如语义分割[17,1]和人体姿态估计[16]。
最近的语义分割通常是通过构建CNN来解决每个像素的标签问题[1,17]。他们把一个现有的分类CNN结构转化为全卷积网络,通过对图像每个局部区域的分类获得一个粗糙的标签图,再用简单的双线性插值反卷积得到像素级别的标签。有时会用条件随机场对输出图片进行处理得到精细的分割结果[14]。FCN最大的优势在于它接受一整个图片,然后快速又精确的得到结果。
基于FCN的语义分割[1,17]有一些明显的局限。首先,网络只能处理单一尺度的图片,因为网络的感受野是确定的。因此比感受野更大或者更小的物体可能会被分裂或是误标。换句话说,标签预测对大物体只用了局部信息,使原本属于同一物体的东西会有不连续的标签。同时小物体通常会被忽略识别成背景。尽管[17]尝试用跳跃连接结构来回避这一局限,但这不是一个根本性的解决,而表现也没有取得很显著的提升。第二,物体的细节结构通常会丢失或是被平滑,因为反卷积操作太简单了,输入到反卷积层的标签图太粗糙。在原始FCN中[17],标签图是16*16大小的,然后通过线性插值反卷积到原始图片大小。没有用真正的反卷积使其无法达到一个好效果。不过用CRF可以改善这一问题[14].
为了突破这些限制,我们提出了一个完全不同的策略,主要是以下几点:
1、设计了多层反卷积网络,由反卷积层,反池化层,relu层组成。反卷积层的学习是有意义的,但目前没有人尝试过
2、训练好的网络被应用于单独物体的实例分割,最后组合起来形成最后的语义分割结果,它不受到规模尺度的影响同时有更好的细节
3、通过结合FCN和我们的方法[17],反卷积网络在PASCAL VOC 2012上取得了杰出的表现
我们相信是这三点帮助我们达到了最高标准的表现
论文以下的结构是这样组织的。首先在第二章里回顾了相关的工作,第三章描述了我们的网络结构,第四章里详细讨论了如何去学习一个有监督的反卷积网络。第五章展示了如何去利用学习好的反卷积网络。实验结果展示在第六章
2、相关工作
CNN在许多视觉识别任务中应用广泛,也已经被广泛用于语义分割。我们首先总结了现有的有监督的语义分割算法
基于分类的语义分割算法有几种。Mostajabi等【18】和Farabet等【6】把多尺度超像素分类到预定义的类中,再结合分类结果实现像素级别标注。一些算法【3,9,10】对建议区域进行分类,再对分割好的图片进行标注来获得最后的分割结果。
全卷积网络【17】带来了深度学习在语义分割上的突破。在FCN中,传统CNN的全连接层被一个具有大的感受野的卷积层替代,分割结果是通过在前向传播上得到的粗糙的分类分值图得到的。这个工作中有趣的想法是利用一个简单的插值实现反卷积,只有CNN部分在学习。令人惊讶的是这个网络的结果在PASCAL VOC上表现突出。Chen等【1】通过FCN网络获得逐像素标签,再用全连接CRF改善标签图。
除了基于监督学习的方法,一些弱监督技术也被提出。仅仅给出边界框标注【2,19】,再通过循环过程获得精确的分割结果。另一方面,【20】在一个多实例学习网络中仅仅基于图片级别的标注实现语义分割。
语义分割在理论上基于反卷积,但学习反卷积网络并不常见。反卷积网络在【25】中被提出用于重构输入图片。最大池化层的存在使得重构输入图片是不简单的,它提出反池化操作,通过记录池化位置。使用反卷积网络可以通过特征图来重构网络。这个方法也被应用于可视化CNN特征图【24】,来提升网络结构。可视化可以帮助我们更好理解一个训练好的CNN网络。
3、系统结构
这一部分讨论了我们反卷积网络的结构和算法。
3.1结构
图2展示了整个网络的细节配置。我们的网络由两部分组成,卷积和反卷积网络。卷积网络部分是一个特征提取器,将输入图片转换成多维特征表示。反卷积网络是一个形状生成器,它将卷积网络提取的特征生成目标分割结果。最后的输出是一个和输入图片相同大小的概率图,每个像素代表属于预先定义的类的概率。
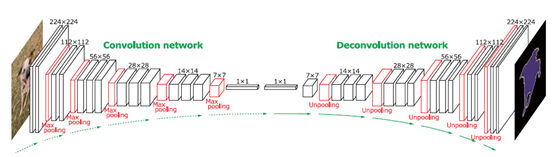
图2. 整个网络结构。卷积网络基于VGG16,再通过反卷积得到准确的分割图。给定一个特征,通过一系列反池化,反卷积和relu得到语义分割图。
卷积部分我们把VGG16的分类层移除了【22】,总共有13层卷积,中间夹杂着relu和池化层。两层全连接层在最后增强分类结果。反卷积网络是卷积网络的镜像,有多层反池化反卷积和relu层。相反于卷积网络减小激活尺寸,反卷积通过这反池化和反卷积扩大激活尺寸。更多的细节在下面讨论。
3.2反卷积网络用于分割
我们现在讨论两个反卷积网络主要操作细节,反池化和反卷积。
3.2.1反池化
卷积网络中的池化是设计用来过滤低层的噪声,通过提取一个感受野内一个单一激活值实现。尽管它通过保持高层的鲁棒激活来帮助分类,但同时也丢失了空间信息,这对语义分割是很重要的。
为了解决这个问题,我们在反卷积网络中利用反池化层,它是池化的反操作,重构了原始大小的激活。图3.实现反池化用了和【24,25】相似的方法。在池化时记录最大池化索引,反池化时可以把激活值放回原位。这个反池化策略在重构输入物体时很有用【24】。
3.2.2反卷积
反池化生成的扩大的输出时稀疏的激活图,反卷积层通过类似卷积层的操作将稀疏激活图变密。相反于卷积层将一个感受野内的多个输入变为1个输出,反卷积将一个输入变为多个输出。图3.反卷积层输出的是稠密的扩大的激活图,我们将超出边界的部分裁剪掉,使其和反池化后的图大小相同。
反卷积层学习到的滤波器对应于输入物体的重构大小。因此类似于卷积网络,继承的反卷积网络结构也可以获得不同尺度的形状信息。低层的滤波器倾向于捕获物体整体形状,而物体的细节分类特征在更高层捕捉。这样网络可以获得形状细节信息,这在别的只基于卷积网络的方法里是会被忽略的。【1,17】
3.2.3反卷积网络分析
在提出的算法中,反卷积网络是获得物体精细边界分割的主要组成部分。相对于【17】里对粗糙的激活图的简单反卷积,我们的算法实现了深度反卷积网络,通过连续的反池化反卷积和relu实现了稠密的像素分割概率图。
图4展示了网络一层层的输出,这对我们理解内部网络结构很有用。可以看到由粗到细的物体结构在反卷积层的传播中被重构。低层倾向于获得整体的粗糙外形(位置,形状,区域),更复杂的特征在高层被捕获。注意到反池化和反卷积在重构物体分割掩膜时是有不同作用的。反池化捕获结构特例(example-specific),通过追溯原图像最大激活的位置。结果就是有效的重构了物体细节结构。在另一方面,反卷积层倾向于捕获类别特定(class-specific)的形状。通过反卷积,和目标类别相关的激活被放大,无关的被压制。结合反池化和反卷积,我们的网络生成精确的分割图。
图5展示了FCN-8s的输出和我们的输出。我们的网络结构比FCN-8S的输出更稠密和精确。
3.3系统总览
我们的算法把语义分割看做实例分割问题。就是说网络接收一个可能包含物体的图片,后面题为实例,作为输入然后输出逐像素的类别预测。我们的网络把每一类的实例从图像里提取出来,然后聚合起来生成语义分割结果。
一个个实例的分割在图片级别的预测有几个好处。它可以有效处理不同尺度的物体,识别物体细节,这在固定尺寸的感受野是无法实现的。同时它通过降低预测的搜索空间和训练时需要的内存减轻了训练复杂度。
4、训练
前文所述的网络非常深(是【22】的两倍),同时有许多复杂的参数。另外用于语义分割的训练样本相较于网络非常小——PASCAL的训练和验证集加起来12031。训练一个深层网络用这么少有限的样本是不现实的,我们用以下几个方法顺利的训练了网络。
4.1 批归一化batch normalization
众所周知深层神经网络由于内部协变量移动(internal-covariate-shift)问题很难优化【11】,每层的变量输入分布在每次训练时都在改变,因为上一层更新了。分布的变化在层与层之间传播时会被放大导致很难优化。
用BN可以减轻内部协变量移动(internal-covariate-shift)通过把每一层的输入分布归一化到标准高斯分布。因此BN层在每个卷积和反卷积后面都加了。我们发现BN对优化我们的网络非常重要,如果不用网络会落在一个不好的局部最优
4.2 两级训练 two-stage training
尽管BN可以帮助我们逃离局部最优,网络相比于训练样本还是太大,反卷积网络带来的好处会消失。因此我们用了两级训练,首先用简单的例子训练网络,再用复杂的例子对网络进行微调。
第一个阶段的训练我们利用标注数据将物体裁剪至图像中间。通过限制物体位置和形状,显著降低了搜索空间和大小,同时成功的用少量样本训练了网络。在第二阶段,我们利用物体建议来构建更复杂的样本。特别是那些候选物体和真值时有重叠的。用这个方法构建训练数据在测试时有更好的鲁棒性,但它使训练难度增加了。
5、推断,实现(inference)
提出的网络是在单实例上训练的。给定一个图像,我们首先生成一定数量的候选提议,再用网络对每个单独物体进行提议,再将所有物体的提议组合起来形成最后的结果。此外我们也组合了我们的方法和FCN【17】来更进一步提升性能。细节在下面展示
5.1 聚合每个实例的分割结果
由于一些提议是不准确的由于物体的错位和背景的聚合,我们要在聚合时消除这些噪声。每个像素的分值图的最大值或是平均值是有效的。
gi∈R(W*H*C)是第i个提议的分值图,w,h,c是分值图像的大小和类别数。首先在gi周围补0到原图大小,后面记为Gi。然后将所有提议的分值图聚合起来通过最大或是平均。
每一类的原始大小的概率图再经过一个softmax激活函数。最后用全连接CRF【14】对输出图进行优化,用逐像素概率图得到一元可能性。
5.2 和FCN组合
我们的反卷积网络和FCN是互补的,我们提取精细边界,而FCN提取总体形状。另外,逐实例预测在处理多尺度目标时有用,而全卷积网络对捕获上下文特征有用。组合这两个特征可以获得更好的结果。
我们简单组合了两个方法,计算两个网络最后输出的平均值,再用CRF获得最后分割结果。
6、实验
这部分描述了我们事先细节和实验步骤。然后从各个方面分析和评估了网络
6.1 实现细节
网络配置
表2总结了网络的细节。网络以第二个全连接层为中心对称。输入和输出分别代表输入图像和类别条件概率图,整个网络共有约252M的参数
数据集
用的是PASCAL VOC 2012的训练和测试分割数据【5】。训练时我们用了【8】的扩增方法,对于训练和验证数据都扩增了。网络的表现在测试集上进行评估。注意我们只用了这个数据集,没有像【2,19】那样用额外的数据集才得到最高水平的结果
训练数据构建
我们用两级训练法,每个阶段用不同的训练数据。构建第一阶段训练数据时,我们对每个标注的物体画一个框框,再扩大1.2倍来包括物体的局部上下文信息。第二阶段,每个训练样本通过物体提议提取出来【26】,相关的类别标签用于标注。然后用和第一阶段相同的后处理方法来包括上下文信息。对两个数据集,通过添加重复的样本使样本不同类之间保持平衡。在扩增数据集方面,我们转换一个输入图像到250*250大小。再随机切割成224*224,同时随机添加水平翻转【22】。第一阶段和第二阶段的训练样本大小分别为0.2M和2.7M。
优化
我们在caffe框架下实现了网络,标准的随机梯度下降配合动量的方法用于优化,初始学习率0.01,momentum 0.9,权重下降0.0005。初始化卷积网络用在ILSVRC上预训练的VGG16层,反卷积网络用0均值的高斯分布。由于BN的存在移除了dropout层(为啥呢),学习率当验证集精度不再上升时按数量级下降(应该是每次除以10),尽管我们是在训练集和验证集上一起训练的,实验看来学习率调整还是很有用。网络的第一阶段和第二阶段分别在经过20K和40K的SGD迭代后收敛,batch-size为64。训练消耗了6天,第一阶段2天,第二阶段4天。用一块Nvidia GTX Titan X GPU,内存12G。
实现
我们用边框【26】来生成物体建议,对每个测试图像我们生成大约2000个物体建议,挑选前50个。我们发现50个对获得精确分割边界是足够的,最后用每个像素的最大提议来生成语义分割图(前文聚合部分的最大值公式)
6.2在PASCAL VOC上评估
PASCAL VOC 2012包含1456个测试图像,20个物体种类【5】。我们采用交并比IoU来评估。
和其余方法的定量比较结果在表1中。反卷积网络和最先进的模型不相上下。用CRF【14】做后处理提升了1%的准确度。我们通过结合FCN-8s更进一步提升了表现,对FCN-8s和反卷积网络分别提升了10.3%和3.1%。我们相信这是由于我们的方法和FCN的互补导致的,5.2中已经讨论过,这个特性使我们的方法和其余基于FCN的方法区分开来。两个方法的结合用EDeconvNet表示。
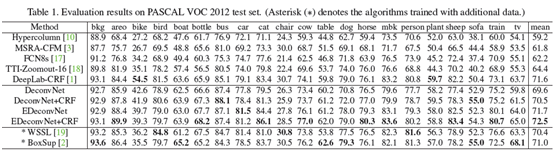
图6展示了逐实例预测的有效性。通过聚合以大小降序排列的提议,同时观察分割的过程,随着聚合过程的继续,算法识别到了物体的精细边界,这是通过小的提议捕获到的。
图7展示了一些DeconvNet,FCN和他们的组合的结果。总的来说,反卷积网络相比于FCN生成更精细的结果,同时可以处理不同尺度的物体。FCN由于固定感受野无法识别太大或是太小的物体(7a)。我们的网络当物体有移位或是处于背景中时也会生成有噪音的结果(7b)。两者的组合有一个更好的结果。注意到两者错误的预测可以被组合的网络纠正。加上CRF可以一生效果尽管提升不显著。
7、结论
我们提出了一个创新型的可学习的反卷积网络。反卷积网络可以生成精确的分割结果,是因为一个物体通过一系列的反卷积实现了粗糙到精细的重构。我们基于逐实例的预测对处理不同规模大小的物体很有用,不像全卷积网络固定了感受野。我们进一步提出了结合两个网络的方法,由于两个网络的互补性取得了更好的成绩。我们的网络在没有额外数据的情况下取得了最先进的表现
参考文献:
[1] L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with deep convolutional nets and fully connected CRFs. In ICLR, 2015. 1,2, 4, 7
[2] J. Dai, K. He, and J. Sun. Boxsup: Exploiting bounding boxes to supervise convolutional networks for semantic segmentation.arXiv preprint arXiv:1503.01640, 2015. 2, 6, 7
[3] J. Dai, K. He, and J. Sun. Convolutional feature masking for joint object and stuff segmentation. In CVPR, 2015. 2, 7
[4] J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierarchical image database. In CVPR, 2009. 6
[5] M. Everingham, L. Van Gool, C. K. Williams, J. Winn, and A. Zisserman. The pascal visual object classes (voc) challenge.IJCV, 88(2):303–338, 2010. 6, 7
[6] C. Farabet, C. Couprie, L. Najman, and Y. LeCun. Learning hierarchical features for scene labeling. TPAMI, 35(8):1915–1929, 2013. 1, 2
[7] R. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014. 1
[8] B. Hariharan, P. Arbel´aez, L. Bourdev, S. Maji, and J. Malik. Semantic contours from inverse detectors. In ICCV, 2011. 6
[9] B. Hariharan, P. Arbel´aez, R. Girshick, and J. Malik. Simultaneous detection and segmentation. In ECCV, 2014. 1, 2
[10] B. Hariharan, P. Arbel´aez, R. Girshick, and J. Malik. Hypercolumns for object segmentation and fine-grained localization.In CVPR, 2015. 2, 7
[11] S. Ioffe and C. Szegedy. Batch normalization: Accelerating deep network training by reducing internal covariate shift. arXiv preprint arXiv:1502.03167, 2015. 5
[12] S. Ji, W. Xu, M. Yang, and K. Yu. 3D convolutional neural networks for human action recognition. TPAMI, 35(1):221–231, 2013. 1
[13] Y. Jia, E. Shelhamer, J. Donahue, S. Karayev, J. Long, R. Girshick, S. Guadarrama, and T. Darrell. Caffe: Convolutional architecture for fast feature embedding. arXiv preprint arXiv:1408.5093, 2014. 6
[14] P. Kr¨ahenb¨uhl and V. Koltun. Efficient inference in fully connected crfs with gaussian edge potentials. In NIPS, 2011.1, 2, 6, 7
[15] A. Krizhevsky, I. Sutskever, and G. E. Hinton. ImageNet classification with deep convolutional neural networks. In NIPS, 2012. 1
[16] S. Li and A. B. Chan. 3D human pose estimation from monocular images with deep convolutional neural network. In ACCV, 2014. 1
[17] J. Long, E. Shelhamer, and T. Darrell. Fully convolutional networks for semantic segmentation. In CVPR, 2015. 1, 2,4, 5, 7, 8
[18] M. Mostajabi, P. Yadollahpour, and G. Shakhnarovich. Feedforward semantic segmentation with zoom-out features. arXiv preprint arXiv:1412.0774, 2014. 1, 2, 7
[19] G. Papandreou, L.-C. Chen, K. Murphy, and A. L. Yuille. Weakly-and semi-supervised learning of a DCNN for semantic image segmentation. arXiv preprint arXiv:1502.02734,2015. 2, 6, 7
[20] P. O. Pinheiro and R. Collobert. Weakly supervised semantic segmentation with convolutional networks. In CVPR, 2015.2
[21] K. Simonyan and A. Zisserman. Two-stream convolutional networks for action recognition in videos. In NIPS, 2014. 1
[22] K. Simonyan and A. Zisserman. Very deep convolutional networks for large-scale image recognition. In ICLR, 2015.1, 3, 5, 6
[23] C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed, D. Anguelov, D. Erhan, V. Vanhoucke, and A. Rabinovich.Going deeper with convolutions. arXiv preprint arXiv:1409.4842, 2014. 1
[24] M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. In ECCV, 2014. 2, 3
[25] M. D. Zeiler, G. W. Taylor, and R. Fergus. Adaptive deconvolutional networks for mid and high level feature learning.In ICCV, 2011. 2, 3
[26] C. L. Zitnick and P. Doll´ar. Edge boxes: Locating object proposals from edges. In ECCV, 2014. 6
DeconvNet 论文阅读理解的更多相关文章
- 论文阅读理解 - Stacked Hourglass Networks for Human Pose Estimation
http://blog.csdn.net/zziahgf/article/details/72732220 keywords 人体姿态估计 Human Pose Estimation 给定单张RGB图 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
- 论文阅读笔记六:FCN:Fully Convolutional Networks for Semantic Segmentation(CVPR2015)
今天来看一看一个比较经典的语义分割网络,那就是FCN,全称如题,原英文论文网址:https://people.eecs.berkeley.edu/~jonlong/long_shelhamer_fcn ...
- 阅读关于DuReader:百度大规模的中文机器阅读理解数据集
很久之前就得到了百度机器阅读理解关于数据集的这篇文章,今天才进行总结!.... 论文地址:https://arxiv.org/abs/1711.05073 自然语言处理是人工智能皇冠上的明珠,而机器阅 ...
- Event StoryLine Corpus 论文阅读
Event StoryLine Corpus 论文阅读 本文是对 Caselli T, Vossen P. The event storyline corpus: A new benchmark fo ...
- 机器阅读理解(看各类QA模型与花式Attention)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Model 2: Attentive Sum Reader Model 3: S ...
- 机器阅读理解(看各类QA模型与花式Attention)(转载)
目录 简介 经典模型概述 Model 1: Attentive Reader and Impatient Reader Attentive Reader Impatient Reader Model ...
- YOLO 论文阅读
YOLO(You Only Look Once)是一个流行的目标检测方法,和Faster RCNN等state of the art方法比起来,主打检测速度快.截止到目前为止(2017年2月初),YO ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
随机推荐
- PC逆向之代码还原技术,第四讲汇编中减法的代码还原
目录 PC逆向之代码还原技术,第四讲汇编中减法的代码还原 一丶汇编简介 二丶高级代码对应汇编观看. 1.代码还原解析: 三丶根据高级代码IDA反汇编的完整代码 四丶知识总结 PC逆向之代码还原技术,第 ...
- 10年架构师告诉你,他眼中的Spring容器是什么样子的
相关文章 如何慢慢地快速成长起来? 成长的故事之Spring Core系列 你是如何看待Spring容器的,是这样子吗? Spring的启动过程,你有认真思考过吗?(待写) 面向切面编程,你指的是Sp ...
- Centos 7 Puppet之foreman介绍安装测试
一.简介 1.前言(引用一下网上的资料) 随着企业的 Linux 系统数量越来越多,管理问题便成为一个相对麻烦并需要急 迫解决的问题,这里有 2 个 Key Message:1)统一管控体系非常重要, ...
- 一统江湖的大前端(4)shell.js——穿上马甲我照样认识你
<一统江湖的大前端>系列是自己的前端学习笔记,旨在介绍javascript在非网页开发领域的应用案例和发现各类好玩的js库,不定期更新.如果你对前端的理解还是写写页面绑绑事件,那你真的是有 ...
- tomcat 大并发报错 Maximum number of threads (200) created for connector with address null and port 80
1.INFO: Maximum number of threads (200) created for connector with address null and port 80 说明:最大线程数 ...
- JSON字符串反序列化成对象_部分属性值反序列化失败
简介:本人在开发webapi接口时遇到了:一个复杂的Json字符串在反序列化为对象时报,无法发序列化其中的一个属性对象? 使用方法: InternalRecommendRequestFormModel ...
- unix时间转换为datetime\datetime转换为unixtime
/// <summary> /// unix时间转换为datetime /// </summary> /// <param name="timeStamp&qu ...
- 【开源】SpringBootNetty聊天室V1.2.0升级版本介绍
前言 SpringBoot!微服务微架构的基础,Netty通信框架的元老级别框架,即之前的SpringBoot与Netty的实现聊天室的功能后已经过了不到一周的时间啦,今天我们更新了项目版本从V1.0 ...
- asp.net引用System.Speech实现语音提示
using System; using System.Speech.Synthesis; namespace testvoice { class Program { static void Main( ...
- java框架之springboot
快速入门 一.helloworld示例 二.springboot单元测试 三.springboot热部署 web开发 整合redis thymeleaf使用 spring-data-jpa使用 整合m ...