Python正则表达式初识(四)
今天继续给大家分享Python正则表达式基础知识,主要给大家介绍一下特殊字符“{}”的用法,具体的教程如下。

特殊字符“{}”实质上也是一个限定词的用法,其限定前面字符所出现的次数,其常用的模式有三种,分别是“{数字}”、“{数字,}”和“{数字1, 数字2}”。举个例子,如“{1}”、“{1,}”和“{1, 3}”。到这里可能大家还不是很清楚,下面依次通过实例来演示一下,加深对特殊字符“{}”的理解。
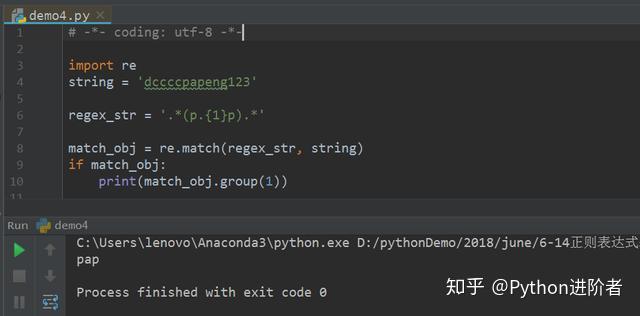
1、如下图所示,限定字符p前面的字符出现1次,则根据贪婪匹配模式,pap成功匹配到。
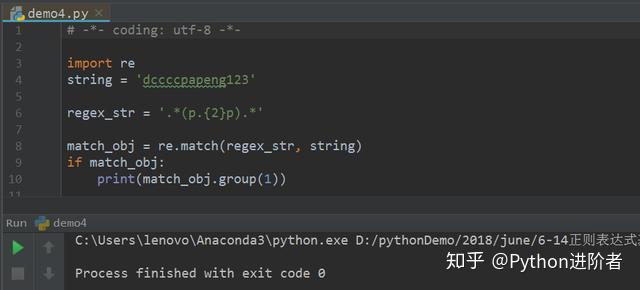
2、如果将匹配模式更改为“.*(p.{2}p).*”,则无任何的输出,如下图所示,因为此时并没有任何的字字符串符合匹配条件。
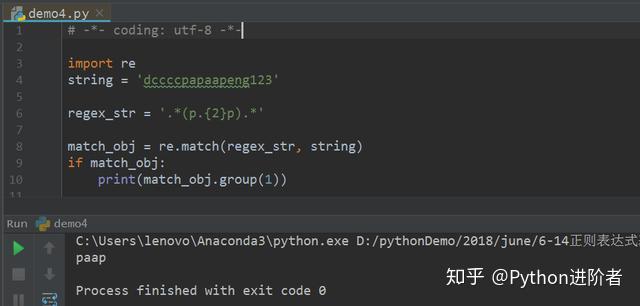
3、相应的,我们将原始字符串做一下更改,如下图所示,此时“.*(p.{2}p).*”匹配模式有对应的结果,如下图所示。
4、特殊字符“{1,}”代表的是前面的字符出现1次及以上;特殊字符“{2,}”代表的是前面的字符出现2次及以上;特殊字符“{3,}”代表的是前面的字符出现3次及以上;以此类推。举个栗子,如下图所示。
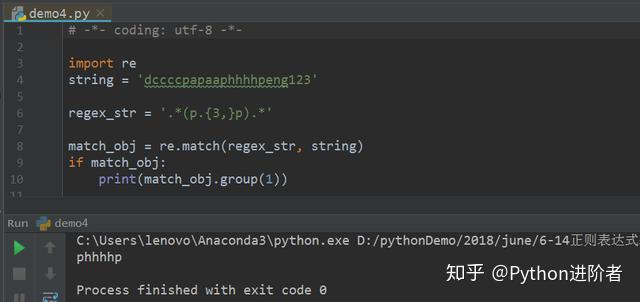
我们要匹配出现p字符前面出现3次及以上的次数,此时子字符串phhhhp被提取出来,但是pap和paap都没有提取到,因为其不满足匹配条件。
5、特殊字符“{1, 3}” 代表的是前面的字符至少出现1次,最多出现3次;特殊字符“{2, 5}” 代表的是前面的字符至少出现2次,最多出现5次;以此类推。举个栗子,如下图所示。
当使用特殊字符“{1, 3}”的时候,如下图所示:
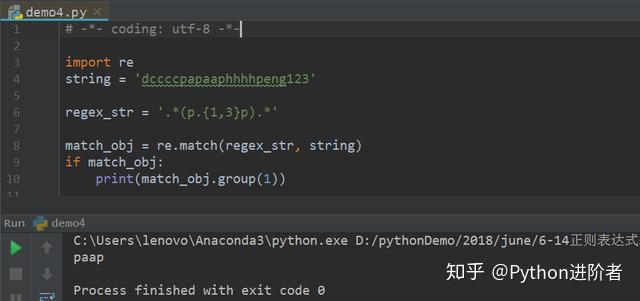
贪婪模式下,字符串从右边开始往左取,首先遇到相对满足条件的子字符串是phhhhp,但是并不符合规则,因为该子字符串出现的次数为4次,而限定条件为1次到3次,所以这个子字符串不符合匹配条件,尔后继续往前匹配,得到匹配结果paap,满足匹配条件。
6、同理,当使用特殊字符“{3, 5}”的时候,如下图所示:
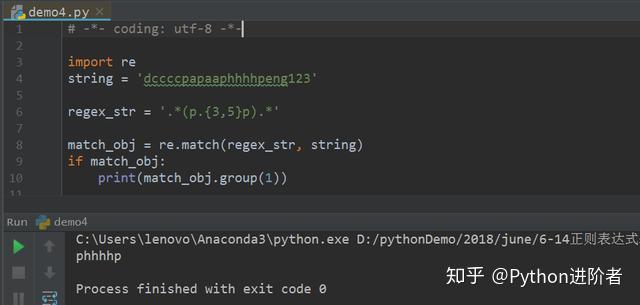
根据上一步的分析可以得知,该匹配结果为phhhhp。
小伙伴们,关于正则表达式特殊字符“{}”的用法,你们get到了吗?
Python正则表达式初识(四)的更多相关文章
- Python正则表达式初识(十)附正则表达式总结
今天分享正则表达式最后一个特殊字符“\d”,具体的教程如下. 1.特殊字符“\d”十分常用,其代表的意思是数字.代码演示如下图所示. 其中“+”的意思是表示连续,在这里代表的意思是连续的数字.但是输出 ...
- Python正则表达式初识(二)
前几天给大家分享了Python正则表达式初识(一),介绍了正则表达式中的三个特殊字符“^”.“.”和“*”,感兴趣的伙伴可以戳进去看看,今天小编继续给大家分享Python正则表达式相关特殊字符知识点. ...
- Python正则表达式初识(六)
继续分享Python正则表达式基础,今天给大家分享的正则表达式特殊符号是“[]”.中括号十分实用,其有特殊含义,其代表的意思是中括号中的字符只要满足其中任意一个就可以.其用法一共有三种,分别对其进行具 ...
- Python正则表达式初识(九)
继续分享Python正则表达式的基础知识,今天给大家分享的特殊字符是[\u4E00-\u9FA5],这个特殊字符最好能够记下来,如果记不得的话通过百度也是可以一下子查到的. 该特殊字符是固定的写法,其 ...
- Python正则表达式初识(八)
继续分享Python正则表达式的基础知识,今天给大家分享的特殊字符是“\w”和“\W”,具体的教程如下. 1.“\w”代表的意思是该字符为任意字符,但是和特殊字符“.”的意思不同.“\w”代表的字符主 ...
- Python正则表达式初识(七)
继续分享Python正则表达式的基础知识,今天给大家分享的特殊字符是“\s”.“\S”,具体的教程如下. 1.“\s”代表的意思是匹配空格,匹配模式“加\s油”代表的是字符“加”和“油”之间有空格的意 ...
- Python正则表达式初识(五)
正则表达式的内容很丰富,今天小编继续给大家分享Python正则表达式的基础知识.今天要给大家的讲的特殊字符是竖线“|”.竖线“|”实质上是一个或的关系. 1.直接上代码演示,比方说我们需要匹配一个字符 ...
- Python正则表达式初识(三)
前几天给大家分享了Python正则表达式基础(一)和Python正则表达式基础(二),感兴趣的小伙伴可以点击进去学习,今天继续给大家分享Python正则表达式基础. 1.正则表达式特殊字符“+”,其代 ...
- python正则表达式(四)
re模块的高级用法 search 需求:匹配出文章阅读的次数 #coding=utf-8 import re ret = re.search(r"\d+", "阅读次数为 ...
随机推荐
- 【codeforces 257D】Sum
[题目链接]:http://codeforces.com/problemset/problem/257/D [题意] 给你n个数字; 这n个数字组成的数组满足: a[i-1]<=a[i]< ...
- Redis Java调用
Redis Java调用 package com.stono.redis; import redis.clients.jedis.Jedis; public class RedisJava { pub ...
- MooseFS源代码分析(二)
watermark/2/text/aHR0cDovL2Jsb2cuY3Nkbi5uZXQv/font/5a6L5L2T/fontsize/400/fill/I0JBQkFCMA==/dissolve/ ...
- so near yet so far
Dear little yang So beautiful boy as you, the most beautiful boy is you who i ever saw, like a sun , ...
- VS2013+PTVS,python编码问题
1.调试,input('中文'),乱码2.调试,print('中文'),正常3.不调试,input('中文'),正常4.不调试,print('中文'),正常 页面编码方式已经加了"# -- ...
- RMAN备份脚本
单机环境全备 export ORACLE_BASE=/oracle export ORACLE_HOME=$ORACLE_BASE/product/10.2.0/db_1 export ORA ...
- Chromium Graphics: Graphics and Skia
Graphics and Skia Chrome uses Skia for nearly all graphics operations, including text rendering. GDI ...
- ML words
samples:样本 multi-dimensional entry / multivariate data:多属性记录 features:特征,属性 supervised learning:监督学习 ...
- asp.net.core网站重启后登陆无效问题(部署在IIS)
一.问题 在使用asp.net.core时,把网站发布到IIS后,在后续更新中需要停止网站,然后重启网站,发现已经登陆的用户会退出登陆.过程如下 1.登陆代码(测试) [AllowAnonymous] ...
- main()函数的形参
main函数中的第一个参数argc代表的是向main函数传递的参数个数,第二个参数argv数组代表执行的程序名称和执行程序时输入的参数 #include <stdio.h> int mai ...