pycaffe 可视化常用
net.params['layername'].[0]/[1]
caffe的一个程序跑完之后会在snapshot所指定的目录下产生一个后缀名为caffemode的文件,这里存放的就是我们在训练网络的时候得到的每层参数的信息。
net.params['layername'][0].data #访问权重参数(num_filter,channel,weight,high
net.params['layername'][1].data #访问bias,格式是(biase,)
如下所示,这里的net.params使用的是字典的格式:
格式: layername (num_filter,channel,kernel_size,kernel_size) (biase_counts,)
net.blobs['layername'].data
保存着网络结构的字典类型,记录着图片数据。
net.blobs['layername'].data.shape #得到输入图片的大小
net.blobs['layername'].data.reshape(0,3,227,227) #改变图片大小(batch——number,channel,image_size,image_size) 只有最开始的时候第二位是channel,之后的图片数据第二位是feature_map的个数
#net.blobs['layername'].data[0,:36] 表示batch_size里的第一个图片卷积层后的featuresmap图像中的前36幅feature map图像
查看cnn各层的输出值(activations)的结构
#第i次循环体的内部
#layer_name提取的是net的第i层的名称
#blob提取的是第i层的输出数据(4d)
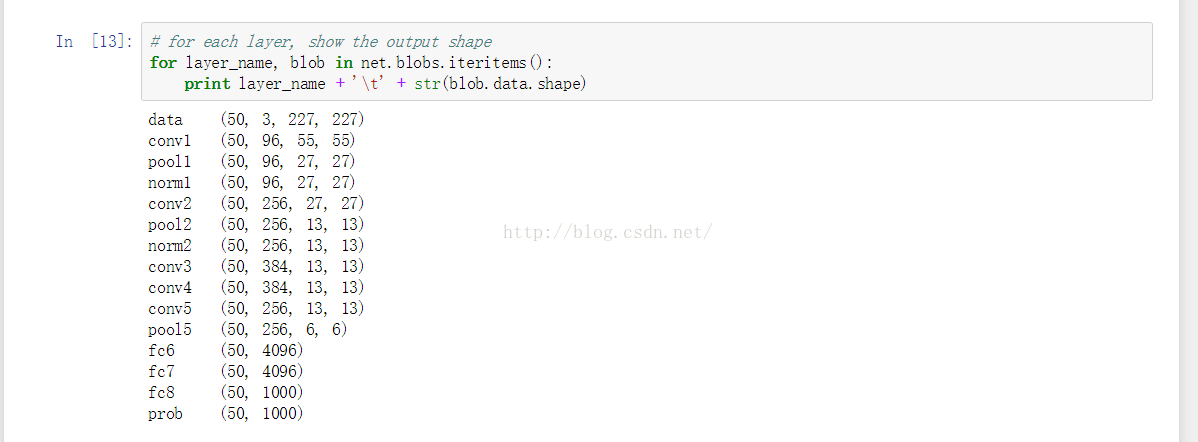
for layer_name, blob in net.blobs.iteritems():
print layer_name + '\t' + str(blob.data.shape)
结果是:
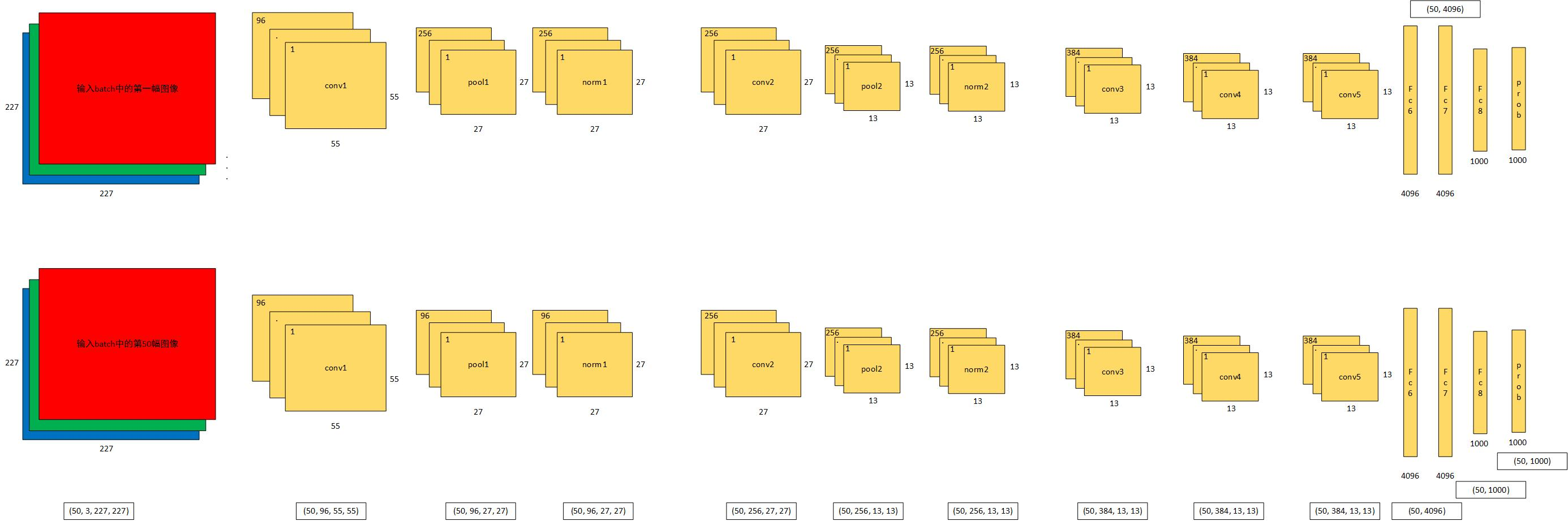
data (50, 3, 227, 227) 网络的输入,batch_number = 50,图像为227*227*3的RGB图像
conv1 (50, 96, 55, 55) 第一个conv层的输出图像大小为55*55,feature maps个数为96
pool1 (50, 96, 27, 27) 第一个pool层的图像尺寸为27*27,feature map个数为96
norm1 (50, 96, 27, 27) 第一个norm层的图像尺寸为27*27,feature map个数为96
conv2 (50, 256, 27, 27) 第二个conv层的图像尺寸为27*27,feature map个数为256
pool2 (50, 256, 13, 13) 第二个pool层的图像尺寸为13*13,feature map个数为256
norm2 (50, 256, 13, 13) 第二个norm层的图像尺寸为13*13,feature map个数为256
conv3 (50, 384, 13, 13) 第三个conv层的图像尺寸为13*13,feature map个数为384
conv4 (50, 384, 13, 13) 第四个conv层的图像尺寸为13*13,feature map个数为384
conv5 (50, 256, 13, 13) 第五个conv层的图像尺寸为13*13,feature map个数为256
pool5 (50, 256, 6, 6) 第五个pool层的图像尺寸为13*13,feature map个数为256
fc6 (50, 4096)
第六个fc层的图像尺寸为4096
fc7 (50, 4096)
第七个fc层的图像尺寸为4096
fc8 (50, 1000)
第八个fc层的图像尺寸为1000
prob (50, 1000)
probablies层的尺寸为1000
查看每一层的参数结构
#第i次循环体的内部
#layer_name提取的是第i层的名字
#params提取的是第i层的参数
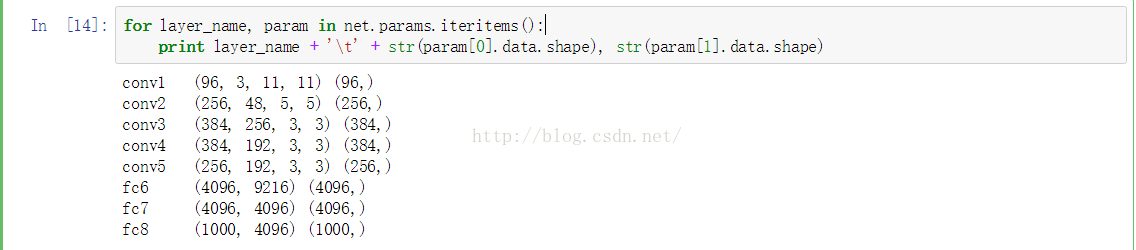
for layer_name, param in net.params.iteritems():
print layer_name + '\t' + str(param[0].data.shape, str(param[1].data.shape)
结果是:
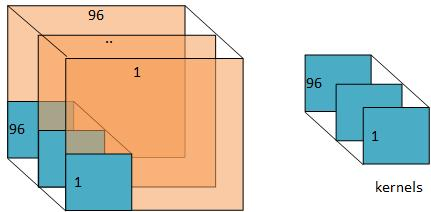
conv1 (96, 3, 11, 11) (96,) 第一个conv层的filters的尺寸,这里的3是因为输入层的data为rgb,可以看做三个feature maps
conv2 (256, 48, 5, 5) (256,) 第二个conv层的filters尺寸
conv3 (384, 256, 3, 3) (384,)第三个conv层的filters尺寸
conv4 (384, 192, 3, 3) (384,)第四个conv层的filters尺寸
conv5 (256, 192, 3, 3) (256,)第五个conv层的filters尺寸
fc6 (4096, 9216) (4096,)第一个fc层的权值尺寸
fc7 (4096, 4096) (4096,)第二个fc层的权值尺寸
fc8 (1000, 4096) (1000,)第三个fc层的权值尺寸
应该注意到,由于pool层和norm层并没有需要优化的参数,所以参数中并没有关于pool层和norm层的信息
下面给出filters如何对输入数据进行filter的一幅形象化的图:
可视化4D数据的函数
def func(data):
#输入数据为一个ndarray,尺寸可以为(batch_size,height,width)或(batch_size,height,width,channel)
#前者是batch_size个灰度图像的数据,后者是batch_size个rgb图像的数据
#在一个sqrt(n) by sqrt(n) 的格子中,显示没一幅图像
#对图像进行normlization
data = (data-data.min())/(data.max()-data.min()) #强制性的使输入的图像个数为平方数,不足平方的时候,手动添加几幅图
n = int(np.ceil(np.sqrt(data.shape(0))))
#每一幅小图像之间加入空隙
padding(((0,n**2-data.shape[0]),(0,1),(0,1)) + ((0,0),)*(data.ndim-3))
data = np.pad(data,padding,mode='constant',constant_values=1) #pad with ones (white)
#将所有输入的data图像平复在一个nadarray_data中
data = data.reshape((n,n),data.shape[1:]).transpose(0,2,1,3) + tuple(range(4,data.ndim + 1))
#data的一个小例子(3,120,120)
data = data.reshape((n * data.shape[1], n * data.shape[3]) + data.shape[4:])
# 显示data所对应的图像
plt.imshow(data); plt.axis('off')
可视化例子
import numpy as np
import sys,os
# 设置当前的工作环境在caffe下
caffe_root = '/home/xxx/caffe/'
# 我们也把caffe/python也添加到当前环境
sys.path.insert(0, caffe_root + 'python')
import caffe
os.chdir(caffe_root)#更换工作目录 # 设置网络结构
net_file=caffe_root + 'models/bvlc_reference_caffenet/deploy.prototxt'
# 添加训练之后的参数
caffe_model=caffe_root + 'models/bvlc_reference_caffenet/bvlc_reference_caffenet.caffemodel'
# 均值文件
mean_file=caffe_root + 'python/caffe/imagenet/ilsvrc_2012_mean.npy' # 这里对任何一个程序都是通用的,就是处理图片
# 把上面添加的两个变量都作为参数构造一个Net
net = caffe.Net(net_file,caffe_model,caffe.TEST)
# 得到data的形状,这里的图片是默认matplotlib底层加载的
transformer = caffe.io.Transformer({'data': net.blobs['data'].data.shape})
# matplotlib加载的image是像素[0-1],图片的数据格式[weight,high,channels],RGB
# caffe加载的图片需要的是[0-255]像素,数据格式[channels,weight,high],BGR,那么就需要转换 # channel 放到前面
transformer.set_transpose('data', (2,0,1))
transformer.set_mean('data', np.load(mean_file).mean(1).mean(1))
# 图片像素放大到[0-255]
transformer.set_raw_scale('data', 255)
# RGB-->BGR 转换
transformer.set_channel_swap('data', (2,1,0)) # 这里才是加载图片
im=caffe.io.load_image(caffe_root+'examples/images/cat.jpg')
# 用上面的transformer.preprocess来处理刚刚加载图片
net.blobs['data'].data[...] = transformer.preprocess('data',im)
#注意,网络开始向前传播啦
out = net.forward()
# 最终的结果: 当前这个图片的属于哪个物体的概率(列表表示)
output_prob = out['prob']
# 找出最大的那个概率
print 'predicted class is:', output_prob.argmax() # 也可以找出前五名的概率
top_inds = output_prob.argsort()[::-1][:5]
print 'probabilities and labels:'
zip(output_prob[top_inds], labels[top_inds]) # 最后加载数据集进行验证
imagenet_labels_filename = caffe_root + 'data/ilsvrc12/synset_words.txt'
labels = np.loadtxt(imagenet_labels_filename, str, delimiter='\t') top_k = net.blobs['prob'].data[0].flatten().argsort()[-1:-6:-1]
for i in np.arange(top_k.size):
print top_k[i], labels[top_k[i]]
import os
import numpy as np
import os
import matplotlib.pyplot as plt
import matplotlib.patches as mpatches
%matplotlib inline # 设置默认的属性:用于在ipython中显示图片
plt.rcParams['figure.figsize'] = (10, 10)
plt.rcParams['image.interpolation'] = 'nearest'
plt.rcParams['image.cmap'] = 'gray'
from math import pow
from skimage import transform as tf caffe_root='/opt/modules/caffe-master/'
sys.insert.path(0,caffe_root+'python') caffe_modelcaffe=caffe_root+''
caffe_deploy=caffe_root+'' caffe.set_mode_cpu()
net=caffe.Net(caffe_deploy,caffe_modelcaffe,caffe.TEST) transform=caffe.io.Transformer({'data':net.blobs['data'].data.shape})
transform.set_transpose('data',(2,0,1))
transform.set_raw_scale('data',255)
transform.set_channel_swap('data',(2,1,0)) #把加载到的图片缩放到固定的大小
net.blobs['data'].reshape(1,2,227,227) image=caffe.io.load_image('/opt/data/person/1.jpg')
transformed_image=transform.preprocess('data',image)
plt.inshow(image) # 把警告过transform.preprocess处理过的图片加载到内存
net.blobs['data'].data[...]=transformed_image output=net.forward() #因为这里仅仅测试了一张图片
#output_pro的shape中有对于1000个object相似的概率
output_pro=output['prob'][0] #从候选的区域中找出最有可能的那个object的索引
output_pro_max_index=output_pro.argmax() labels_file = caffe_root + '.../synset_words.txt'
if not os.path.exists(labels_file):
print "in the direct without this synset_words.txt "
return
labels=np.loadtxt(labels_file,str,delimiter='\t') # 从对应的索引文件中找到最终的预测结果
outpur_label=labels[output_pro_max_index]
# 也可以找到排名前五的预测结果
top_five_index=output_pro.argsort()[::-1][:5]
print 'probabilities and labels:'
zip(output_pro[top_five_index],labels[top_five_index])
pycaffe 可视化常用的更多相关文章
- BVLC CaffeNet可视化及类别预测
一.介绍 bvlc_reference_caffenet网络模型是由AlexNet的网络模型改写的,输入图片尺寸大小为227x227x3,输出的为该图片对应1000个分类的概率值. 介绍参考:caff ...
- mnist全连接层网络权值可视化
一.数据准备 网络结构:lenet_lr.prototxt 训练好的模型:lenet_lr_iter_10000.caffemodel 下载地址:链接:https://pan.baidu.com/s/ ...
- python 数据分析 Matplotlib常用图表
Matplotlib绘图一般用于数据可视化 常用的图表有: 折线图 散点图/气泡图 条形图/柱状图 饼图 直方图 箱线图 热力图 需要学习的不只是如何绘图,更要知道什么样的数据用什么图表展示效果最好 ...
- pyhton matplotlib可视化图像基础(二维函数图、柱状图、饼图、直方图以及折线图)
//2019.07.22pyhton中matplotlib模块的应用pyhton中matplotlib是可视化图像库的第三方库,它可以实现图像的可视化,输出不同形式的图形1.可视化图形的输出和展示需要 ...
- 【深度学习Deep Learning】资料大全
最近在学深度学习相关的东西,在网上搜集到了一些不错的资料,现在汇总一下: Free Online Books by Yoshua Bengio, Ian Goodfellow and Aaron C ...
- 阿铭linux笔记
2015-09-06虚拟机网络设置.wmv: curl 获取在命令行显示的网页 dhclient 分配ip地址 ifdown eth0 关闭网卡eth0 ifup eh0 ...
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)
##机器学习(Machine Learning)&深度学习(Deep Learning)资料(Chapter 2)---#####注:机器学习资料[篇目一](https://github.co ...
- [UFLDL] ConvNet
二十三(Convolution和Pooling练习) 三十八(Stacked CNN简单介绍) 三十六(关于构建深度卷积SAE网络的一点困惑) 五十(Deconvolution Network简单理 ...
- 《Tensorflow技术解析与实战》第四章
Tensorflow基础知识 Tensorflow设计理念 (1)将图的定义和图的运行完全分开,因此Tensorflow被认为是一个"符合主义"的库 (2)Tensorflow中涉 ...
随机推荐
- 神经网络预测mnist时候如果不归一化,则准确率仅仅10%下文作者svm也遇到了。
转自:http://blog.csdn.net/jeryjeryjery/article/details/72649320 这两天用Python来实现手写数字识别,刚开始用原始数据进行训练,结果预测结 ...
- 升级Ubuntu18.04后遇到的坑
升级过程: 直接do-release-update 就可以直接从16.04更新到18.04了. 中间会提升更新一些配置文件, 我大部分都选择了N. 然后就成功升级到18.04了, 显卡驱动什么的都 ...
- SparkSession - Spark SQL 的 入口
SparkSession - Spark SQL 的 入口 翻译自:https://jaceklaskowski.gitbooks.io/mastering-apache-spark/content/ ...
- (转载) android快速搭建项目积累
android快速搭建项目积累 2016-04-05 20:07 519人阅读 评论(0) 收藏 举报 分类: android优化(8) Rx技术(5) 版权声明:本文为博主原创文章,未经博主 ...
- (转载)15 个 Android 通用流行框架大全
15 个 Android 通用流行框架大全 时间:2017-03-20 11:36来源:未知 作者:admin 点击: 2089 次 15 个 Android 通用流行框架大全 1. 缓存 Dis ...
- Java文件(io)编程——简易记事本开发
public class NotePad extends JFrame implements ActionListener{ //定义需要的组件 JTextArea jta=null; //多行文本框 ...
- Springboot如何利用http请求控制器
写好了接口,现在想用postman测试一下这个接口是否正确,想请问怎么传入请求参数?先谢谢了! Springboot如何利用http请求控制器 >> java这个答案描述的挺清楚的:htt ...
- swift语言点评八-枚举
总结:swift中的枚举可以看作变量可以作为case匹配参数的类 Enumerations 枚举的作用:状态列举与匹配 枚举值与类型 If a value (known as a “raw” valu ...
- HDU-3746 Cyclic Nacklace 字符串匹配 KMP算法 求最小循环节
题目链接:https://cn.vjudge.net/problem/HDU-3746 题意 给一串珠子,我们可以在珠子的最右端或最左端加一些珠子 问做一条包含循环珠子的项链,最少还需要多少珠子 思路 ...
- luogu P1375 小猫(卡特兰数)
题意 (n<=200000) 题解 把DP转移方程写出来,这不是卡特兰数吗?然后就解决了. 做完这题我发现 DP真是一个好东西. (公式连乘所以中间要加mod要不爆longlong了) #inc ...