Opencv Surf算子中keyPoints,描述子Mat矩阵,配对向量DMatch里都包含了哪些好玩的东东?
Surf算法是一把牛刀,我们可以很轻易的从网上或各种Opencv教程里找到Surf的用例,把例程中的代码或贴或敲过来,满心期待的按下F5,当屏幕终于被满屏花花绿绿的小圆点或者N多道连接线条霸占时,内心的民族自豪感油然而生,仿佛屠龙宝刀在手,屁颠屁颠的很开心。
如果对Surf的探究或者使用到此为止,我觉得只是用Surf这把牛刀吓唬了一个小鸡仔,万里长征才刚刚开始第一步,最少有三个问题需要得到解答:
- 1. 保存特征点信息的keyPoints向量内每个元素包含有哪些内容?
- 2. 通过comput方法生成的特征描述子是一个Mat矩阵,该Mat矩阵的结构是怎样的?
- 3. 特征点匹配后生成一个DMatch型的向量matches,这个matches里边的内容又是什么,以及如何有效操作众多匹配信息,为之后在实际中的应用做好基础?
这三个基本的问题得不到一个很好的答案,所谓的利用Sruf进行图像的拼接、融合,物体识别,3D建模等应用应该连纸上谈兵都算不上吧~
通过一个小例子,尝试对这三个问题进行解读。
1. 保存特征点信息的keyPoints向量内每个元素包含有哪些内容?
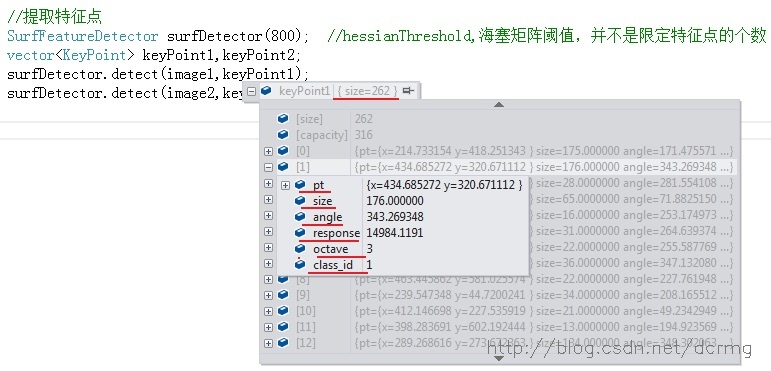
keyPoints数据结构包含的内容有:
- size1:特征点的总个数
- pt: 特征点的坐标
- size2:特征点的大小
- angle:特征点的角度
- response:特征点的响应强度,代表该点的稳健程度,可以在Surf特征探测器的含参构造函数中设置响应强度的最低阈值,如: SurfFeatureDetector surfDetector(800);
- octave:特征点所在的金字塔的哪一组
- class_id:特征点的分类
2. 通过comput方法生成的特征描述子是一个Mat矩阵,该Mat矩阵的结构是怎样的?
经过归一化后的描述子Mat矩阵显示:


这两个长的很大条的图像就是描述子的图像显示,图像的行数是特征点的个数,上例中图像1的特征点数比图像二的少,表现出来就是图像的高度小一些。
图像的列数是描述特征点的描述子的维度数,在Surf中,维度是64,在SIft中,维度是128,所以如果使用Sift特征的话,图像应该宽两倍。
3. 特征点匹配后生成一个DMatch型的向量matches,这个matches里边的内容又是什么,以及如何有效操作众多匹配信息,为之后在实际中的应用做好基础?
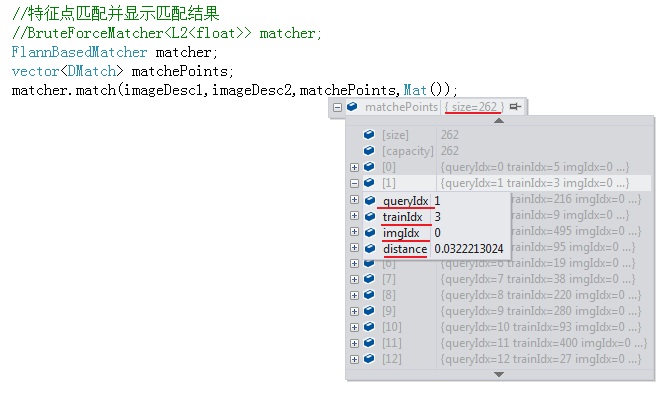
matches数据结构包含的内容有:
- size:配对成功的特征点对数
- queryIdx:当前“匹配点”在查询图像的特征在KeyPoints1向量中的索引号,可以据此找到匹配点在查询图像中的位置
- trainIdx:当前“匹配点”在训练(模板)图像的特征在KeyPoints2向量中的索引号,可以据此找到匹配点在训练图像中的位置
- imgIdx:当前匹配点对应训练图像(如果有若干个)的索引,如果只有一个训练图像跟查询图像配对,即两两配对,则imgIdx=0
- distance:连个特征点之间的欧氏距离,越小表明匹配度越高
4. 匹配特征点sort排序
sort方法可以对匹配点进行从小到大的排序:
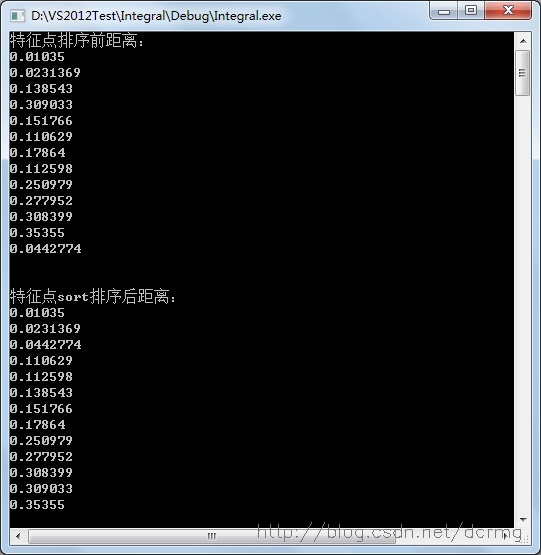
使用sort排序之前,每个匹配点对间的距离(即匹配稳健性程度)是随机分布的,排序之后,距离按由小到大的顺序排列,越靠前的,匹配度越高,可以通过排序后把靠前的匹配提取出来。
本例中提取前10个最优匹配(匹配很完美吧,因为这是同一幅图像~):

以下是完整的程序,有兴趣可参考:
#include "highgui/highgui.hpp"
#include "opencv2/nonfree/nonfree.hpp"
#include "opencv2/legacy/legacy.hpp"
#include <iostream>
using namespace cv;
using namespace std;
int main(int argc,char *argv[])
{
Mat image01=imread(argv[1]);
Mat image02=imread(argv[2]);
Mat image1,image2;
image1=image01.clone();
image2=image02.clone();
//提取特征点
SurfFeatureDetector surfDetector(800); //hessianThreshold,海塞矩阵阈值,并不是限定特征点的个数
vector<KeyPoint> keyPoint1,keyPoint2;
surfDetector.detect(image1,keyPoint1);
surfDetector.detect(image2,keyPoint2);
//绘制特征点
drawKeypoints(image1,keyPoint1,image1,Scalar::all(-1));
drawKeypoints(image2,keyPoint2,image2,Scalar::all(-1),DrawMatchesFlags::DRAW_RICH_KEYPOINTS);
imshow("KeyPoints of image1",image1);
imshow("KeyPoints of image2",image2);
//特征点描述,为下边的特征点匹配做准备
SurfDescriptorExtractor SurfDescriptor;
Mat imageDesc1,imageDesc2;
SurfDescriptor.compute(image1,keyPoint1,imageDesc1);
SurfDescriptor.compute(image2,keyPoint2,imageDesc2);
//归一化并显示出来描述子
Mat imageDescShow1;
Mat imageDescShow2;
normalize(imageDesc1,imageDescShow1,0,255,CV_MINMAX);
normalize(imageDesc2,imageDescShow2,0,255,CV_MINMAX);
convertScaleAbs(imageDescShow1,imageDescShow1);
convertScaleAbs(imageDescShow2,imageDescShow2);
imshow("描述子1",imageDescShow1);
imshow("描述子2",imageDescShow2);
//特征点匹配并显示匹配结果
//BruteForceMatcher<L2<float>> matcher;
FlannBasedMatcher matcher;
vector<DMatch> matchePoints;
matcher.match(imageDesc1,imageDesc2,matchePoints,Mat());
//特征点排序并输出
cout<<"特征点排序前距离:"<<endl;
for(int i=0;i<matchePoints.size();i++) //输出特征点按距离排序前内容
{
cout<<matchePoints[i].distance<<endl;
}
cout<<endl<<endl;
cout<<"特征点sort排序后距离:"<<endl;
sort(matchePoints.begin(),matchePoints.end()); //按距离从小到大排序
for(int i=0;i<matchePoints.size();i++)//输出特征点按距离排序前后内容
{
cout<<matchePoints[i].distance<<endl;
}
//提取强特征点
//获取排在前N个的最优匹配结果
vector<DMatch> goodMatchePoints;
for(int i=0;i<10;i++)
{
goodMatchePoints.push_back(matchePoints[i]);
}
//绘制最优匹配点
Mat imageOutput;
drawMatches(image01,keyPoint1,image02,keyPoint2,goodMatchePoints,imageOutput,Scalar::all(-1),
Scalar::all(-1),vector<char>(),DrawMatchesFlags::NOT_DRAW_SINGLE_POINTS);
imwrite("E:\\ss.jpg",imageOutput);
imshow("Mathch Points",imageOutput);
waitKey();
return 0;
}Opencv Surf算子中keyPoints,描述子Mat矩阵,配对向量DMatch里都包含了哪些好玩的东东?的更多相关文章
- Opencv Surf算子特征提取与最优匹配
Opencv中Surf算子提取特征,生成特征描述子,匹配特征的流程跟Sift是完全一致的,这里主要介绍一下整个过程中需要使用到的主要的几个Opencv方法. 1. 特征提取 特征提取使用SurfFea ...
- OpenCV 3.0中IplImage* 转cv::Mat
在OpenCV 2.0中使用: IplImage * ipl1, *ipl2; // ... const cv::Mat m = cv::Mat(ipl,false); cv::Mat m2 = ip ...
- Opencv中Mat矩阵相乘——点乘、dot、mul运算详解
Opencv中Mat矩阵相乘——点乘.dot.mul运算详解 2016年09月02日 00:00:36 -牧野- 阅读数:59593 标签: Opencv矩阵相乘点乘dotmul 更多 个人分类: O ...
- (一)ORB描述子提取
ORBSLAM2中使用ORB描述子的方法 经典的视觉SLAM系统大体分为两种:其一是基于特征点法的,其二是基于直接法的.那么本文主要就讲特征点法的SLAM. 基于特征点法的视觉SLAM系统典型的有PT ...
- OpenCV中图像的格式Mat 图像深度
opencv中图像的格式Mat 有图像的定义,图像深度.类型格式等,其中Mat的参数depth为深度,深度反应出图像颜色像素值: 关于数据的储存:(转) Mat_<uchar>对应的是CV ...
- Opencv Mat矩阵中data、size、depth、elemSize、step等属性的理解
data: uchar类型的指针,指向Mat数据矩阵的首地址.可以理解为标示一个房屋的门牌号: dims: Mat矩阵的维度,若Mat是一个二维矩阵,则dims=2,三维则dims=3,大多数情况下处 ...
- Distinctive Image Features from Scale-Invariant Keypoints(SIFT) 基于尺度不变关键点的特征描述子——2004年
Abstract摘要本文提出了一种从图像中提取特征不变性的方法,该方法可用于在对象或场景的不同视图之间进行可靠的匹配(适用场景和任务).这些特征对图像的尺度和旋转不变性,并且在很大范围的仿射失真.3d ...
- 学习OpenCV——Surf(特征点篇)&flann
Surf(Speed Up Robust Feature) Surf算法的原理 ...
- OpenCV——SURF特征检测、匹配与对象查找
SURF原理详解:https://wenku.baidu.com/view/2f1e4d8ef705cc1754270945.html SURF算法工作原理 选择图像中的POI(Points of i ...
随机推荐
- javascript之Ajax起步
XMLHttpRequest readyState属性的值: UNSENT--0--已创建XMLHttpRequest对象. OPENED--1--已调用open方法: HEADERS_RECEIV ...
- java list 容器的ConcurrentModificationException
java中的很多容器在遍历的同时进行修改里面的元素都会ConcurrentModificationException,包括多线程情况和单线程的情况.多线程的情况就用说了,单线程出现这个异常一般是遍历( ...
- Spring RootBeanDefinition,ChildBeanDefinition,GenericBeanDefinition
转自:https://blog.csdn.net/joenqc/article/details/68942972 RootBeanDefinition,ChildBeanDefinition,Gene ...
- 94.文件bat脚本自删除
taskkill / f / im 自删除.exedel 自删除.exedel 1.bat void main() { FILE *pf = fopen("1.bat", &quo ...
- datetime小练习
题目: 1.计算你的生日比如近30年来(1990-2019),每年的生日是星期几,统计一下星期几出现的次数比较多2,生日提醒,距离生日还有几天 # !/usr/bin/env python # -*- ...
- Playing with coroutines and Qt
你好!我最近想知道C ++中的协程的状态,我发现了几个实现.我决定选择一个用于我的实验.它简单易用,适用于Linux和Windows. 我的目标是试图找到一种方法来让代码异步运行,而不必等待信号触发插 ...
- 21、IIS声卡驱动程序
声卡芯片的数据通道一般都是IIS接口,但是控制音量等控制信息的接口都不相同 (新内核在linux-3.4.2\sound\soc\codecs\uda134x.c) uda134x_codec_pro ...
- ios_webView
iOS开发中WebView的使用 在AppDelegate.m文件里 view sourceprint" class="item about" style="c ...
- [Node] Use babel-preset-env with Native Node Features and Also Use Babel Plugins
In this lesson we'll show how to setup a .babelrc file with presets and plugins. Then create npm scr ...
- 目前以lib后缀的库有两种,一种为静态链接库(Static Libary,以下简称“静态库”),另一种为动态连接库(DLL,以下简称“动态库”)的导入库(Import Libary,以下简称“导入库”)。静态库是一个或者多个obj文件的打包
前以lib后缀的库有两种,一种为静态链接库(Static Libary,以下简称“静态库”),另一种为动态连接库(DLL,以下简称“动态库”)的导入库(Import Libary,以下简称“导入库”) ...