C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解
起因
最近突然心血来潮想做个小程序,学习一下小程序开发流程,然后新手就想做个查询的就可以了,少点交互能力,这种思来想去还是周公解梦比较靠谱,
网上一搜,还真有小程序源码,但是这里面似乎数据都是取第三方api的或者固定死的演示数据,或者残缺不全的数据,然后csdn上面居然还有积分下载周公
解梦数据的,评论都是说数据不全的,我这个脑子啊,这我就不愿意了,我要就要最全的,搞出来我也分享一下数据。。。。。。(其实是不是还是拖延症啊
不想学习小程序!!!)
然后网上搜了一下周公解梦,目前有一家数据是比较全的,而且页面结构是比较清晰的,可能是有程序员在维护。。。锁定数据源xzw。com 当然,如果
这种行为侵犯了xzw权益,请联系我删除。
言归正传
下面开始访问数据站,结构还是挺清晰的,梦的类别 梦的名称 里面的子项 及简介,我们大致可以设计一个表出来了

我们再点击进去看一下子项的内容,原来子项的内容都是依赖于外层的“孕妇”,这里我使用的是mysql数据库存储,
其实这种结构似乎更适合存储为nosql数据库,不纠结于这个,最多加个外键就OK。

可能初步的表是这样的
Dream表
| Id | 自增列 |
| Name | 梦的名字 例如 “孕妇” |
| Summary | 简介 这是搜索列表最外层的那个简介 |
| CateName | 分类名称 总分类可能就那固定的几个,我们这里只保存名称就好了 |
| CreateTime | 附属属性 |
| Url | 详细页面地址(这个是在下面会做说明) |
DreamInfo表
| Id | 自增列 |
| FkDreamId | Dream表主键 |
| DreamName | Dream表Name 例如 孕妇,为了不重复查询直接id和name都保存 |
| Name | 梦的详细名称,例如 未婚女人梦见孕妇 |
| Content | 梦的详细内容 |
| CreateTime | 附属属性,时间 |
分解页面结构
然后开始我们的页面分解之路,这个页面我们可以拿到 DreamName 还有Dream Summary 后面还要进入详情页绑定内容建立从属关系,
那么保存下这个详细页面的url,供我们第二次爬详细页面的时候使用,所以才会有上面dream表里的url字段,边发现边修改。
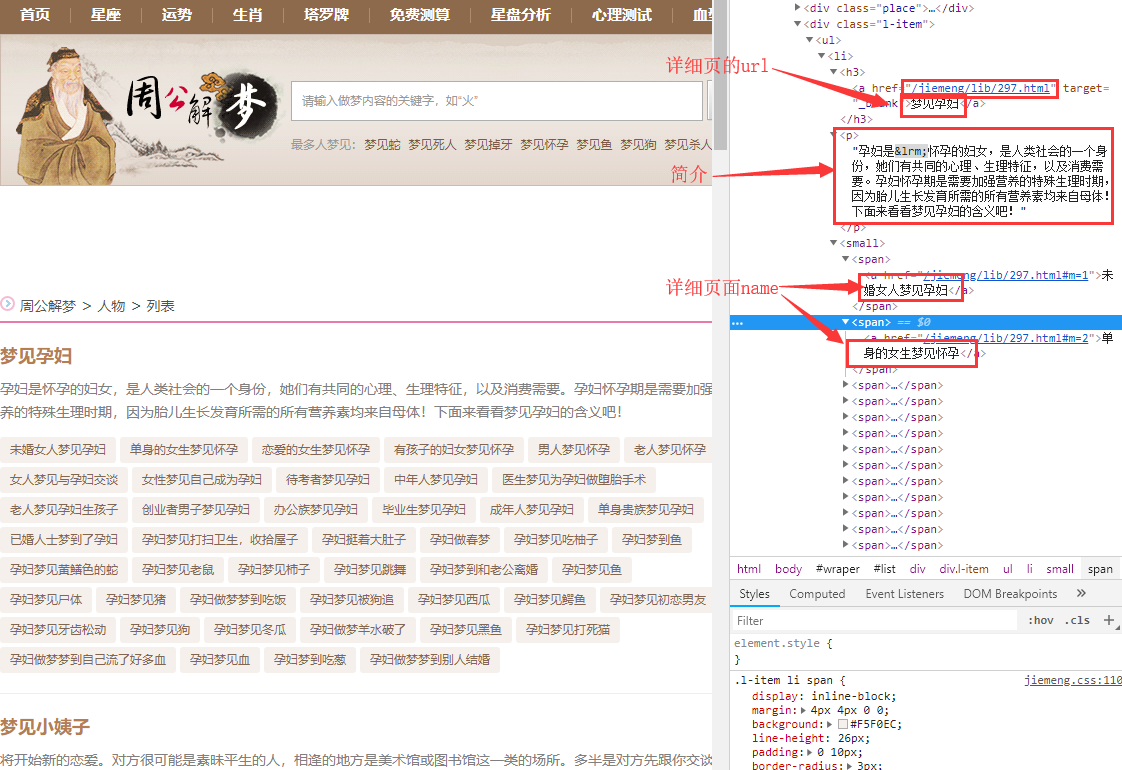
具体思路就有了,先获取分类下的名称信息、简介以及详情页url信息,下面有翻页,还是老规矩 递归翻页直到结束。
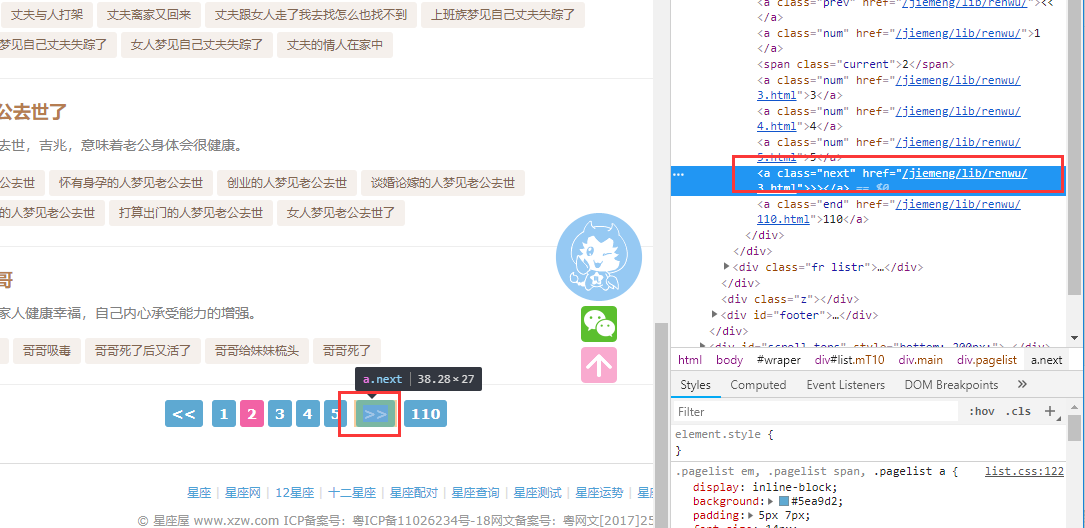
再来看看翻页,发现翻页这个地方,这里有个下一页的按钮,那么这个是不是就可以一直往下翻页了呢,我们就用它了。完美
总结
感觉自己脑袋乱糟糟的,没有固定的想法,可能一个想法牵扯出来多个想法,忘记自己第一个想法是什么了,感觉这种思维很可怕,咸鱼一般的感觉。
下一章开始详细编码。。。
C# NetCore使用AngleSharp爬取周公解梦数据 起因和页面数据拆解的更多相关文章
- C# NetCore使用AngleSharp爬取周公解梦数据
这一章详细讲解编码过程 那么接下来就是码代码了,GO 新建NetCore WebApi项目 空的就可以 NuGet安装 Install-Package AngleSharp 或者界面安装 using. ...
- Python爬取网上车市[http://www.cheshi.com/]的数据
#coding:utf8 #爬取网上车市[http://www.cheshi.com/]的数据 import requests, json, time, re, os, sys, time,urlli ...
- bert+seq2seq 周公解梦,看AI如何解析你的梦境?【转】
介绍 在参与的项目和产品中,涉及到模型和算法的需求,主要以自然语言处理(NLP)和知识图谱(KG)为主.NLP涉及面太广,而聚焦在具体场景下,想要生产落地的还需要花很多功夫. 作为NLP的主要方向,情 ...
- C#使用phantomjs,爬取AJAX加载完成之后的页面
1.开发思路:入参根据apiSetting配置文件,分配静态文件存储地址,可实现不同站点的静态页生成功能.静态页生成功能使用无头浏览器生成,生成之后的字符串进行正则替换为固定地址,实现本地正常访问. ...
- 几句简单的python代码完成周公解梦功能
<周公解梦>是靠人的梦来卜吉凶的一本于民间流传的解梦书籍,共有七类梦境的解述.这是非常传统的中国文化体系的一部分,但是如何用代码来获取并搜索周公解梦的数据呢?一般情况下,要通过爬虫获取数据 ...
- APISpace 周公解梦API接口 免费好用
<周公解梦>,是根据人的梦来卜吉凶的一本解梦书籍,它对人的七类梦境进行解述. 周公解梦API,周公解梦大全,周公解梦查询,免费周公解梦. APISpace 有很多免费通用的API接 ...
- 猫眼电影爬取(二):requests+beautifulsoup,并将数据存储到mysql数据库
上一篇通过requests+正则爬取了猫眼电影榜单,这次通过requests+beautifulsoup再爬取一次(其实这个网站更适合使用beautifulsoup库爬取) 1.先分析网页源码 可以看 ...
- python爬取返利网中值得买中的数据
先使用以前的方法将返利网的数据爬取下来,scrapy框架还不熟练,明日再战scrapy 查找目标数据使用的是beautifulsoup模块. 1.观察网页,寻找规律 打开值得买这块内容 1>分析 ...
- selenium跳过webdriver检测并爬取淘宝我已购买的宝贝数据
简介 上一个博文已经讲述了如何使用selenium跳过webdriver检测并爬取天猫商品数据,所以在此不再详细讲,有需要思路的可以查看另外一篇博文. 源代码 # -*- coding: utf-8 ...
随机推荐
- 解决maven项目找不到maven依赖的解决办法
不同的IDE对应的.classpath中的maven声明也不一样,这样就会导致项目找不到maven依赖. 即Java Build Path--->Libraries中找不到Maven Depen ...
- 附加数据库 对于server XXX失败
近期在学习MVC+EF,看着视频做小demo.EF这一块须要涉及到数据库的连接,视频中所讲的样例与先前牛腩新闻系统数据库挺类似的. 所以,就偷个懒,利用这个数据库,可是在附加的时候出错 ...
- js课程 2-6 js如何进行类型转换及js运算符有哪些
js课程 2-6 js如何进行类型转换及js运算符有哪些 一.总结 一句话总结: 1.所有类型->布尔类型(为假的情况)有哪些(6种)? 1)字符串('')2)整型(0)3)浮点型(0.0)4) ...
- The trust relationship between this workstation and the primary domain failed(断网可以登进来)(正确的解决方式用管理员登进去 :退域再加域)
The trust relationship between this workstation and the primary domain failed(断网可以登进来)(正确的解决方式用管理员登进 ...
- python 标准库 —— io(StringIO)
0. io流(io stream) 流是一种抽象概念,它代表了数据的无结构化传递.按照流的方式进行输入输出,数据被当成无结构的字节序或字符序列.从流中取得数据的操作称为提取操作,而向流中添加数据的操作 ...
- Android多线程研究(7)——Java5中的线程并发库
从这一篇开始我们将看看Java 5之后给我们添加的新的对线程操作的API,首先看看api文档: java.util.concurrent包含许多线程安全.测试良好.高性能的并发构建块,我们先看看ato ...
- php实现 提取不重复的整数(编程题目能够最快的熟悉函数)
php实现 提取不重复的整数(编程题目能够最快的熟悉函数) 一.总结 一句话总结:编程题目能够最快的熟悉函数. 1.字符串反转函数? 没有str_revserse,有arr_reverse,这里是st ...
- 【CF706C】Hard problem
Description Vasiliy is fond of solving different tasks. Today he found one he wasn't able to solve h ...
- 《erlang程序设计》学习笔记-第3章 分布式编程
http://blog.csdn.net/karl_max/article/details/3985382 1. erlang分布式编程的基本模型 (1) 分布式erlang:这种模型可以让我们在一个 ...
- wpf datagrid 的单元格内容超出列宽度
---恢复内容开始--- <Window x:Class="WpfApplication2.MainWindow" xmlns="http://schemas.mi ...