Hadoop一主一从部署(2)
Hadoop部署一主一从(2)
1.关闭防火墙和Linux守护进程
执行命令:
iptables -F
setenforce 0
2.对Hadoop集群进行初始化,在namenode(主机)上执行命令
hdfs namenode -format
3.启动Hadoop,在namenode(主机)上执行如下命令
start-all.sh
4.主机和从机执行命令jps,检查集群是否正常启动,结果如图
主机:
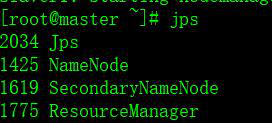
从机:

5.对Hadoop进行一些简单的操作处理:
在hdfs上创建一个bigdata目录,并向目录中上传一个wordcount_test文件
hadoop fs -mkdir /bigdata
hadoop fs -put /root/wordcount_test /bigdata
6.利用Hadoop的shell接口执行Wordcount
hadoop jar /root/hadoop-2.8.0/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.0.jar wordcount /bigdata/wordcount_test /output
备注:1 /output这个文件输出目录一定不能提前创建,否则会报错
2 执行wordcount要分配足够内存,不然会卡死(我分配了4G),这个在yarn-site.xml这个文件中配置,否则会卡死,如下所示:
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
7.查看是否执行成功
执行命令hadoop fs -ls /output

8.查看执行结果
执行命令hadoop fs -cat /output/part-r-00000

至此,Hadoop搭建已全部完成,而且利用Hadoop完成了一个简单的Wordcount小程序。
总结:
防火墙一定要提前关闭,不然向hdfs上传文件会报错。
一定要分配足够的内存,否则执行MapReduce会卡死。
Hadoop一主一从部署(2)的更多相关文章
- hadoop一主一从部署(1)
一.安装前说明 主机IP:192.168.132.128 从机IP:192.168.132.129 1. 所有的安装包我放在了/root/这个目录下,你要根据自己情况去修改,这点必须注意 2. 采用的 ...
- Hadoop 2.2.0部署安装(笔记,单机安装)
SSH无密安装与配置 具体配置步骤: ◎ 在root根目录下创建.ssh目录 (必须root用户登录) cd /root & mkdir .ssh chmod 700 .ssh & c ...
- Hadoop生态圈-离线方式部署Cloudera Manager5.15.1
Hadoop生态圈-离线方式部署Cloudera Manager5.15.1 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 到目前位置,Cloudera Manager和CDH最新 ...
- Hadoop生态圈-HUE环境部署
Hadoop生态圈-HUE环境部署 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.HUE简介 1>.HUE的由来 HUE全称是HadoopUser Experienc ...
- Hadoop分布式集群部署(单namenode节点)
Hadoop分布式集群部署 系统系统环境: OS: CentOS 6.8 内存:2G CPU:1核 Software:jdk-8u151-linux-x64.rpm hadoop-2.7.4.tar. ...
- Hadoop教程(五)Hadoop分布式集群部署安装
Hadoop教程(五)Hadoop分布式集群部署安装 1 Hadoop分布式集群部署安装 在hadoop2.0中通常由两个NameNode组成,一个处于active状态,还有一个处于standby状态 ...
- 1.Hadoop集群安装部署
Hadoop集群安装部署 1.介绍 (1)架构模型 (2)使用工具 VMWARE cenos7 Xshell Xftp jdk-8u91-linux-x64.rpm hadoop-2.7.3.tar. ...
- Hadoop记录-Apache hadoop+spark集群部署
Hadoop+Spark集群部署指南 (多节点文件分发.集群操作建议salt/ansible) 1.集群规划节点名称 主机名 IP地址 操作系统Master centos1 192.168.0.1 C ...
- 2 Hadoop集群安装部署准备
2 Hadoop集群安装部署准备 集群安装前需要考虑的几点硬件选型--CPU.内存.磁盘.网卡等--什么配置?需要多少? 网络规划--1 GB? 10 GB?--网络拓扑? 操作系统选型及基础环境-- ...
随机推荐
- 关于css定位的一些总结
#pay_pic{ overflow: hidden; width: 200px; margin: 0 auto; } table.dataintable { margin-top: 15px; bo ...
- 发布自己的nuget包
1.先到www.nuget.org注册账户,然后在用户中心获取apikey 2.到https://dist.nuget.org/index.html下载最新的nuget.exe,放到你的项目根目录下 ...
- 10java内存
java内存 1.栈---存储的是变量(不仅仅只有变量),不会对存储的内容进行赋值,存储的内容使用完成之后会立即进行清除 2.堆---存储的是对象.会对存储的内容进行赋值,存储内容使用完成之后会在某个 ...
- Learning opencv续不足(七)线图像的设计D
因为线图像startline有了起点和终点,我们就可以用DDA法求出线上所有点,任意斜率直线通过四象限八区域查表法界定.我们只示范一个区域:函数为: public PointF DdaFindPtIm ...
- 洛谷——P2814 家谱
P2814 家谱 题目背景 现代的人对于本家族血统越来越感兴趣. 题目描述 给出充足的父子关系,请你编写程序找到某个人的最早的祖先. 输入输出格式 输入格式: 输入由多行组成,首先是一系列有关父子关系 ...
- uva 524(Prime Ring Problem UVA - 524 )
dfs练习题,我素数打表的时候j=i了,一直没发现实际上是j=i*i,以后可记住了.还有最后一行不能有空格...昏迷了半天 我的代码(紫书上的算法) #include <bits/stdc++. ...
- 五、Scrapy中Item Pipeline的用法
本文转载自以下链接: https://scrapy-chs.readthedocs.io/zh_CN/latest/topics/item-pipeline.html https://doc.scra ...
- 20170622-编译Uboot错误
参照:http://docs.widora.io/zh/uboot编译 Assembler messages:Error: unknown architecture `4kc' Error: unre ...
- cuda npp库旋转图片
#include <stdio.h> #include <stdlib.h> #include <string.h> #include <assert.h&g ...
- SpringMVC demo 小例子,实现简单的登录和注册
1.创建一个动态的web工程 2.导入springMvc所需要的jar包(这里可以去网上找,资源有很多) 前两部就不详细描述了,后面才是正经代码~ 首先有一个web.xml文件,这个属于大配置文件,由 ...