Spark SQL概念学习系列之Spark SQL基本原理
Spark SQL基本原理
1、Spark SQL模块划分
2、Spark SQL架构--catalyst设计图
3、Spark SQL运行架构
4、Hive兼容性
1、Spark SQL模块划分


Spark SQL模块划分为Core、caralyst、hive和hive- ThriftServer四大模块。
Spark SQL依然是读取数据进去,然后你可以执行sql操作,然后你还可以执行其他的结构化操作,不光仅仅是只能sql操作哈!这一点,很多人都没理解到位。
也有数据的输入和输出的工作。
比如,Spark SQL模块里的core模块,就是为了处理数据的输入输出。将查询结果输出成DataFrame。具体见上图。
Spark SQL模块里的catalyst模块。具体见上图。
Spark SQL模块里的hive模块,对hive数据的处理。具体见上图。
Spark SQL模块里的hive -ThriftServer模块,具体见上图。
2、Spark SQL架构--catalyst设计图(这里说Spark SQL模块里的catalyst模块!!)
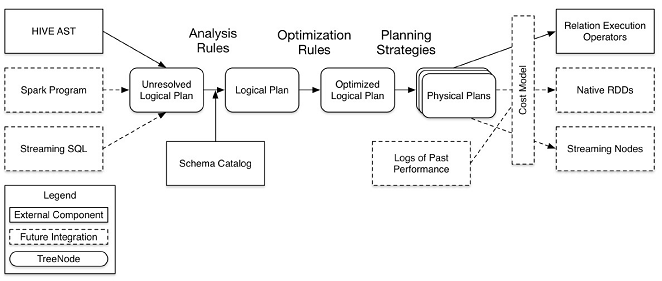
注意:图中的虚线部分是现在未实现或实现不完善的。
其中虚线部分是以后版本要实现的功能,实线部分是已经实现的功能。从上图看,catalyst主要的实现组件有:
sqlParse,完成sql语句的语法解析功能,目前只提供了一个简单的sql解析器;
Analyzer,主要完成绑定工作,将不同来源的Unresolved LogicalPlan和元数据(如hive metastore、Schema catalog)进行绑定,生成resolved LogicalPlan;
optimizer,对resolvedLogicalPlan进行优化,生成optimizedLogicalPlan(OptimizationRules,对resolvedLogicalPlan进行合并、列裁剪、过滤器下推等优化作业而转换成optimized LogicalPlan);
Planner,将LogicalPlan转换成PhysicalPlan;
CostModel,主要根据过去的性能统计数据,选择最佳的物理执行计划。
3、Spark SQL运行架构
类似于关系型数据库,SparkSQL也是语句也是由Projection(a1,a2,a3)、DataSource(tableA)、Filter(condition)组成,分别对应sql查询过程中的Result、Data Source、Operation,也就是说SQL语句按Result-->Data Source-->Operation的次序来描述的。

执行SparkSQL语句顺序为:
1.对读入的SQL语句进行解析(Parse),分辨出SQL语句中哪些词是关键词(如SELECT、FROM、WHERE),哪些是表达式、哪些是Projection、哪些是Data Source等,从而判断SQL语句是否规范;
2.将SQL语句和数据库的数据字典(列、表、视图等等)进行绑定(Bind),如果相关的Projection、DataSource等都是存在的话,就表示这个SQL语句是可以执行的;
3.一般的数据库会提供几个执行计划,这些计划一般都有运行统计数据,数据库会在这些计划中选择一个最优计划(Optimize);
4.计划执行(Execute),按Operation-->DataSource-->Result的次序来进行的,在执行过程有时候甚至不需要读取物理表就可以返回结果,比如重新运行刚运行过的SQL语句,可能直接从数据库的缓冲池中获取返回结果。
4、Hive兼容性
支持使用hql来写查询语句
兼容metastore
使用Hive的SerDes
对UDFs, UDAFs, UDTFs作了封装。
Spark SQL概念学习系列之Spark SQL基本原理的更多相关文章
- Spark SQL概念学习系列之Spark SQL概述
很多人一个误区,Spark SQL重点不是在SQL啊,而是在结构化数据处理! Spark SQL结构化数据处理 概要: 01 Spark SQL概述 02 Spark SQL基本原理 03 Spark ...
- Spark SQL概念学习系列之Spark SQL 架构分析(四)
Spark SQL 与传统 DBMS 的查询优化器 + 执行器的架构较为类似,只不过其执行器是在分布式环境中实现,并采用的 Spark 作为执行引擎. Spark SQL 的查询优化是Catalyst ...
- Spark SQL概念学习系列之分布式SQL引擎
不多说,直接上干货! parkSQL作为分布式查询引擎:两种方式 除了在Spark程序里使用Spark SQL,我们也可以把Spark SQL当作一个分布式查询引擎来使用,有以下两种使用方式: 1.T ...
- Spark RDD概念学习系列之Spark Hash Shuffle内幕彻底解密(二十)
本博文的主要内容: 1.Hash Shuffle彻底解密 2.Shuffle Pluggable解密 3.Sorted Shuffle解密 4.Shuffle性能优化 一:到底什么是Shuffle? ...
- Spark SQL概念学习系列之Spark SQL的简介(一)
Spark SQL提供在大数据上的SQL查询功能,类似于Shark在整个生态系统的角色,它们可以统称为SQL on Spark. 之前,Shark的查询编译和优化器依赖于Hive,使得Shark不得不 ...
- Spark SQL概念学习系列之Spark SQL 优化策略(五)
查询优化是传统数据库中最为重要的一环,这项技术在传统数据库中已经很成熟.除了查询优化, Spark SQL 在存储上也进行了优化,从以下几点查看 Spark SQL 的一些优化策略. (1)内存列式存 ...
- Spark SQL概念学习系列之Spark SQL入门
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark SQL入门(八)
前言 第1章 为什么Spark SQL? 第2章 Spark SQL运行架构 第3章 Spark SQL组件之解析 第4章 深入了解Spark SQL运行计划 第5章 测试环境之搭建 第6章 ...
- Spark SQL概念学习系列之Spark生态之Spark SQL(七)
具体,见
随机推荐
- PullToRefreshListView中嵌套ViewPager滑动冲突的解决
PullToRefreshListView中嵌套ViewPager滑动冲突的解决 最近恰好遇到PullToRefreshListView中需要嵌套ViewPager的情况,ViewPager 作为头部 ...
- Linux下搭建iSCSI共享存储详细步骤(服务器模拟IPSAN存储)
一.简介 iSCSI(internet SCSI)技术由IBM公司研究开发,是一个供硬件设备使用的.可以在IP协议的上层运行的SCSI指令集,这种指令集合可以实现在IP网络上运行SCSI协议,使其能够 ...
- python pdb小结
Debug功能对于developer是非常重要的,python提供了相应的模块pdb让你可以在用文本编辑器写脚本的情况下进行debug. pdb是python debugger的简称.常用的一些命令如 ...
- idea和Pycharm 等系列产品激活激活方法和激活码
引用自大神:雪中皓月原文链接 --------------------- 以下两种方法均可用于激活Idea,Pycharm等jetbrains系列产品第一种方法:使用现有的注册服务器优点:快捷,方便, ...
- CrawlSpider爬取读书网
crawlspider用于定义一些规则用于提取页面符合规则的数据,然后继续爬取. 一.开始一个读书网项目 scrapy startproject 项目名称cd 项目名称/项目名称/spidersscr ...
- Command "python setup.py egg_info" failed with error code 1 in /tmp/pip-build-qvc66dfs/supervisor/
# 安装supervisor 出错 pip3 install supervisor # 解决 sudo pip3 install supervisor
- python垃圾回收算法
标准python垃圾回收器由两部分组成,即引用计数回收器和分代垃圾回收器(即python包中的gc module).其中,引用计数模块不能被禁用,而GC模块可以被禁用. 引用计数算法 python中每 ...
- 封装TensorFlow神经网络
为了参加今年的软件杯设计大赛,这几个月学习了很多新知识.现在大赛的第二轮作品优化已经提交,开始对这四个月所学知识做一些总结与记录. 用TensorFlow搭建神经网络.TensorFlow将神经网络的 ...
- Flat UI简介
Flat UI简介 一.简介 Flat UI是基于Bootstrap之上进行二次开发的扁平化前端框架,他提供了动感.时尚的风格色调搭配,简洁.炫丽的功能组件,同时还提供了更为平滑的js交互动画,可以称 ...
- Oracel 格式化日期 to_char()
select empno,ename,job,mgr,to_char(HIREDATE,'yyyy-mm-dd') as 入职日期,sal,comm,deptno from emp order by ...