[读书笔记] Python数据分析 (五) pandas入门
pandas: 基于Numpy构建的数据分析库
pandas数据结构:Series, DataFrame
Series: 带有数据标签的类一维数组对象(也可看成字典)
values, index
缺失数据检测:pd.isnull(), pd.notnull(), Series对象的实例方法
Series对象本身及其索引都有一个name属性,和pandas其他关键功能关系很密切
DataFrame: 表格型数据结构,列和行都有索引
获取DataFrame列:字典标记方式,或者属性方式(frame2['state']/frame2.state)
获取DataFrame行:ix()方法
通过索引方式返回的列只是相应的数据视图,而不是副本,Series的Copy方法可以显示地复制列
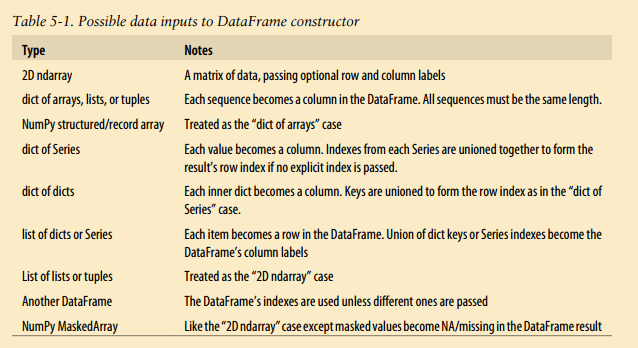
DataFrame的index和column也有name属性,可以自己设置
索引对象:pandas索引对象负责管理轴标签和其他元数据,构建Series或者DataFrame时,所用到的任何数组或者其他序列的标签会被转换成一个Index. Index对象是不可以修改(immutable)的.

Index属性
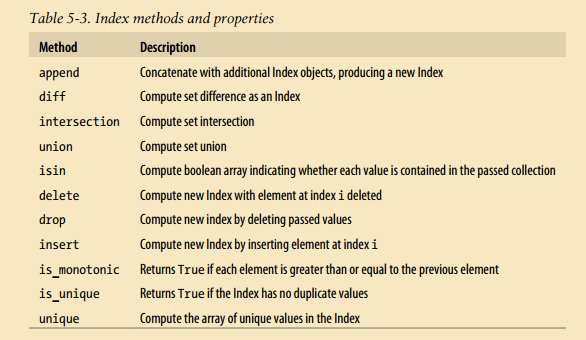
基本功能
重新索引:创建一个适合新索引的对象reindex()

指定丢弃对象:drop()
索引选取和过滤:ix()

算术运算和数据对齐
pandas可以对不同索引对象进行算术运算,对不重叠值自动填充NA
在算术方法中填充值:fill_value
DataFrame和Series之间的运算:broadcast()
默认情况下DataFrame和Series之间的算术运算会将Series的索引匹配到DataFrame列,然后沿着行向下传播;如果想匹配行且在列上广播,必须使用算术运算方法
函数应用和映射
numpy的ufuncs(元素级数组方法),也可以用于操作pandas对象
DataFrame的apply()方法,可以将函数应用到行或者列形成的一维数组
排序和排名
排序:
sort_index() 对行或者列的索引排序(按照字典顺序)
sort_index(by = ) 按照一个或者多个列中值进行排序
Series按值进行排序, order方法
排名:
rank()
带有重复值的轴索引
索引的is_unique()属性可以告诉你它的值是否是唯一的
汇总和计算描述性统计
sum()
mean()
describe()

描述和汇总统计函数
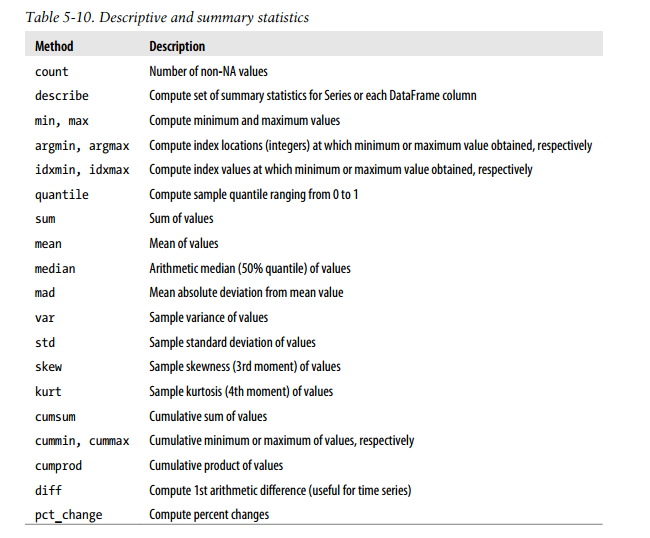
相关系数和协方差
对参数对进行计算得到,Series和DataFrame方法
唯一值,值计数,以及成员资格
唯一值:unique()方法
值计数:value_counts()方法计算一个Series中各个值出现的频率
成员资格:isin, 用于判断矢量化集合的成员资格,可以选取Series或DataFrame列中数据的子集

处理缺失数据

过滤缺失数据:dropna
对于DataFrame对象,dropna默认丢弃任何含有缺失值的行; dropna(how = 'all') 丢弃全为NA那些行.
如果是针对列,传入axis = 1便可
填充缺失数据:fillna
传入常数值:所有na被替换为常数值
传入字典:不同的列填充不同的值
默认返回新的对象,但是也可以就地修改 inplace = TRUE

层次化索引:数据重塑和基于分组的操作(透视表)
stack和unstack
对DataFrame来说,每条轴都可以有分层索引.
根据级别进行汇总:DataFrame和Series的描述和汇总统计都用一个level选项.
使用列作为行索引,将行索引变为DataFrame的列:set_index() 相反reset_index()
[读书笔记] Python数据分析 (五) pandas入门的更多相关文章
- Python数据分析之pandas入门
一.pandas库简介 pandas是一个专门用于数据分析的开源Python库,目前很多使用Python分析数据的专业人员都将pandas作为基础工具来使用.pandas是以Numpy作为基础来设计开 ...
- [读书笔记] Python数据分析 (二) 引言
1. 数据分析的任务:数据读写,数据准备(清洗,修整,规范化,重塑,切片切块,变形),转换,建模计算,呈现(模型/数据) 2. 数据集: bit.ly的1.usa.gov数据:URL缩短服务bit ...
- [读书笔记] Python数据分析 (一) 准备工作
1. python中数据结构:矩阵,数组,数据框,通过关键列相互联系的多个表(SQL主键,外键),时间序列 2. python 解释型语言,程序员时间和CPU时间衡量,高频交易系统 3. 全局解释器锁 ...
- [读书笔记] Python数据分析 (三) IPython
1. 什么是IPython IPyhton 本身没有提供任何的计算或者数据分析功能,在交互式计算和软件开发者两个方面最大化地提高生产力,execute-explore instead of edit- ...
- [读书笔记] Python数据分析 (四) 数组和矢量计算
Numpy:高性能计算和数学分析的基础包 ndarray, 一个具有矢量算术运算和复杂广播能力的快速且节省空间的多维数组 用于对数组数据进行快速运算的标准数学函数 用于读写磁盘数据的工具和用于操作内存 ...
- [读书笔记] Python 数据分析 (十一)经济和金融数据应用
resample: 重采样函数,可以按照时间来提高或者降低采样频率,fill_method可以使用不同的填充方式. pandas.data_range 的freq参数枚举: Alias Descrip ...
- [读书笔记] Python 数据分析 (八)画图和数据可视化
ipython3 --pyplot pyplot: matplotlib 画图的交互使用环境
- [读书笔记] Python 数据分析 (十二)高级NumPy
da array: 一个快速而灵活的同构多维大数据集容器,可以利用这种数组对整块的数据进行一些数学运算 数据指针,系统内存的一部分 数据类型 data type/dtype 指示数据大小的元组 str ...
- Python 数据处理库 pandas 入门教程
Python 数据处理库 pandas 入门教程2018/04/17 · 工具与框架 · Pandas, Python 原文出处: 强波的技术博客 pandas是一个Python语言的软件包,在我们使 ...
随机推荐
- [USACO4.2] 草地排水 Drainage Ditches (最大流)
题目背景 在农夫约翰的农场上,每逢下雨,贝茜最喜欢的三叶草地就积聚了一潭水.这意味着草地被水淹没了,并且小草要继续生长还要花相当长一段时间.因此,农夫约翰修建了一套排水系统来使贝茜的草地免除被大水淹没 ...
- [LUOGU]P4098[HEOI2013]ALO
BZOJ上的权限题,流下了贫穷的泪水... 可持久化trie的题. 一开始zz了,看错了题,以为是要把所有的宝石缩起来,后来仔细一看好像只缩一次...昨天刷了一晚上的语文病句题白做了... 这样的话就 ...
- Docker学习总结(14)——从代码到上线, 云端Docker化持续交付实践
2016云栖大会·北京峰会于8月9号在国家会议中心拉开帷幕,在云栖社区开发者技术专场中,来自阿里云技术专家罗晶(瑶靖)为在场的听众带来<从代码到上线,云端Docker化持续交付实践>精彩分 ...
- Spring Boot 第一个demo
Sring boot 一直没有使用过,跳槽来到新公司,暂时没有事情就学习一下. Spring boot 这里采用的是maven 来创建的 maven项目的pom.xml 文件 <?xml v ...
- TCP打洞技术
//转http://iamgyg.blog.163.com/blog/static/3822325720118202419740/ 建立穿越NAT设备的p2p的TCP连接仅仅比UDP复杂一点点,TCP ...
- Windows 7 x64环境下JDK8安装过程
Windows 7 x64环境下JDK8安装过程 下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads ...
- 为data盘加入磁盘(asm external)
1.创建盘,并两个节点皆能够訪问. 2.检查集群状态 [grid@rac1 ~]$ crsctl status res -t ------------------------------------- ...
- Android UI 优化 使用<include/>和 <merge />标签
使用<include /> 标签来重用layout代码 如果在一个项目中需要用到相同的布局设计,可以通过<include /> 标签来重用layout代码,该标签在Androi ...
- 2017第33周四JDK8并发
Java 8在Lambda表达式.接口默认方式.新的日期API等方面引入的新特性广受关注,同时在并发编程方面也做出了大量改进.以往的几个Java版本都对java.util.concurrent做了不同 ...
- No changes detected or App 'blog' could not be found. Is it in INSTALLED_APPS?
出现该问题的原因: django没有在setting.py的配置文件中找到app内容,需要增加app的名称 E:\PycharmProjects\Mysite>python manage.py ...