( 转 ) MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈。
explain执行计划包含的信息
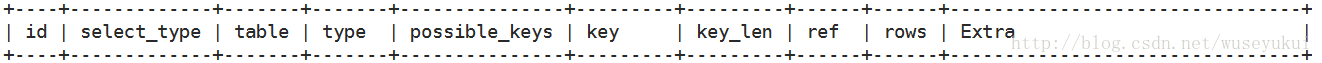
其中最重要的字段为:id、type、key、rows、Extra
各字段详解
id
select查询的序列号,包含一组数字,表示查询中执行select子句或操作表的顺序
三种情况:
1、id相同:执行顺序由上至下

2、id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行

3、id相同又不同(两种情况同时存在):id如果相同,可以认为是一组,从上往下顺序执行;在所有组中,id值越大,优先级越高,越先执行

select_type
查询的类型,主要是用于区分普通查询、联合查询、子查询等复杂的查询
1、SIMPLE:简单的select查询,查询中不包含子查询或者union
2、PRIMARY:查询中包含任何复杂的子部分,最外层查询则被标记为primary
3、SUBQUERY:在select 或 where列表中包含了子查询
4、DERIVED:在from列表中包含的子查询被标记为derived(衍生),mysql或递归执行这些子查询,把结果放在零时表里
5、UNION:若第二个select出现在union之后,则被标记为union;若union包含在from子句的子查询中,外层select将被标记为derived
6、UNION RESULT:从union表获取结果的select
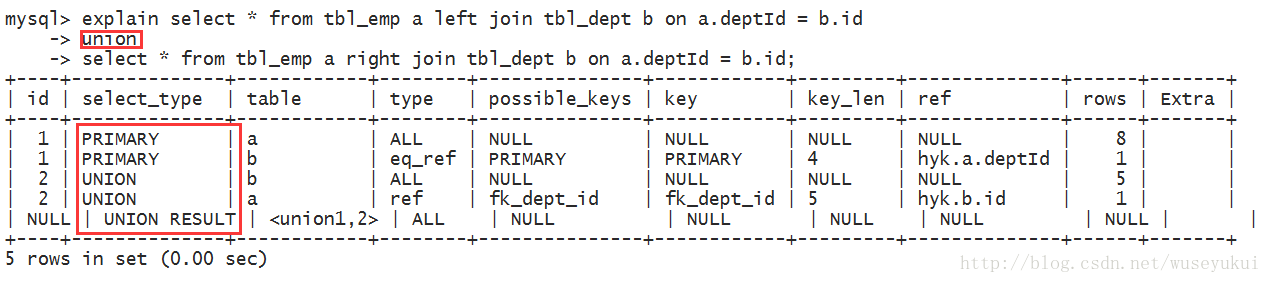
type
访问类型,sql查询优化中一个很重要的指标,结果值从好到坏依次是:
system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
一般来说,好的sql查询至少达到range级别,最好能达到ref
1、system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,可以忽略不计
2、const:表示通过索引一次就找到了,const用于比较primary key 或者 unique索引。因为只需匹配一行数据,所有很快。如果将主键置于where列表中,mysql就能将该查询转换为一个const

3、eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键 或 唯一索引扫描。
注意:ALL全表扫描的表记录最少的表如t1表

4、ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质是也是一种索引访问,它返回所有匹配某个单独值的行,然而他可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体
5、range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了那个索引。一般就是在where语句中出现了bettween、<、>、in等的查询。这种索引列上的范围扫描比全索引扫描要好。只需要开始于某个点,结束于另一个点,不用扫描全部索引

6、index:Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常为ALL块,应为索引文件通常比数据文件小。(Index与ALL虽然都是读全表,但index是从索引中读取,而ALL是从硬盘读取)

7、ALL:Full Table Scan,遍历全表以找到匹配的行

possible_keys
查询涉及到的字段上存在索引,则该索引将被列出,但不一定被查询实际使用
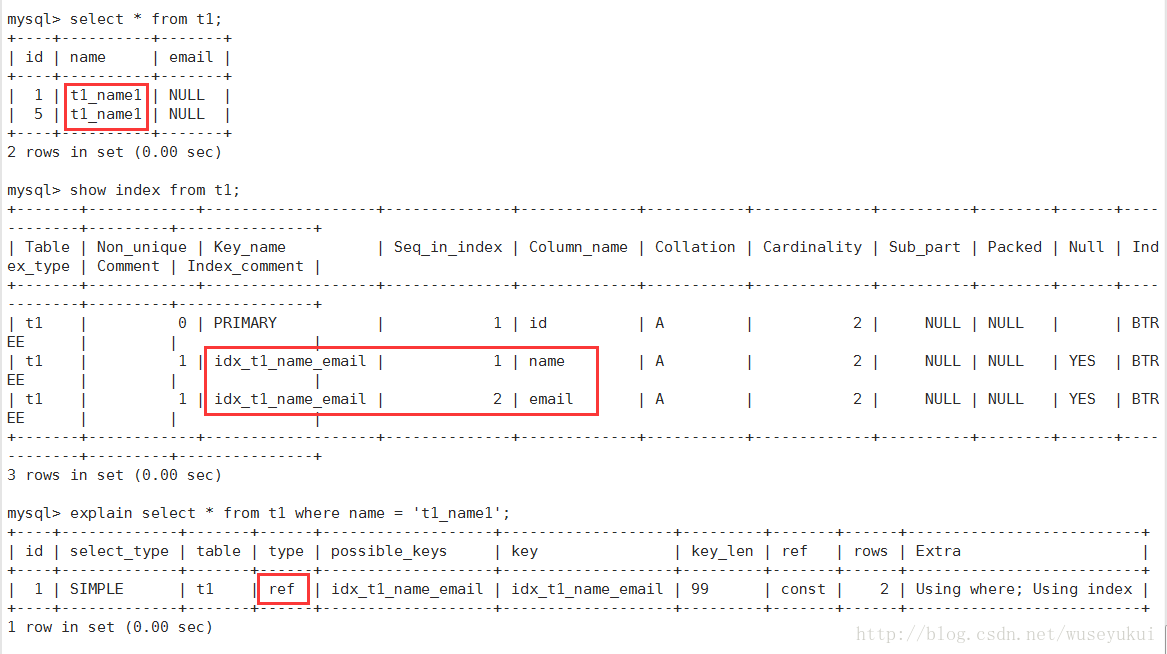
key
实际使用的索引,如果为NULL,则没有使用索引。
查询中如果使用了覆盖索引,则该索引仅出现在key列表中

key_len
表示索引中使用的字节数,查询中使用的索引的长度(最大可能长度),并非实际使用长度,理论上长度越短越好。key_len是根据表定义计算而得的,不是通过表内检索出的
ref
显示索引的那一列被使用了,如果可能,是一个常量const。
rows
根据表统计信息及索引选用情况,大致估算出找到所需的记录所需要读取的行数
Extra
不适合在其他字段中显示,但是十分重要的额外信息
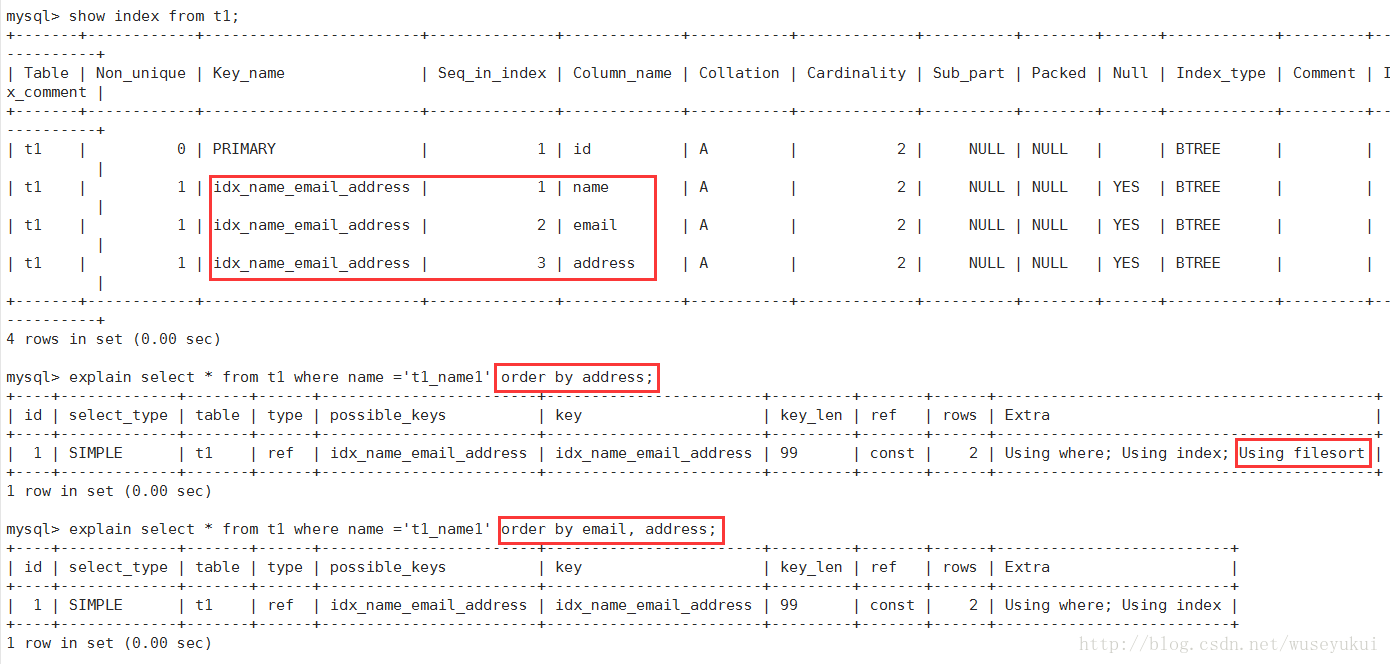
1、Using filesort :
mysql对数据使用一个外部的索引排序,而不是按照表内的索引进行排序读取。也就是说mysql无法利用索引完成的排序操作成为“文件排序”
由于索引是先按email排序、再按address排序,所以查询时如果直接按address排序,索引就不能满足要求了,mysql内部必须再实现一次“文件排序”
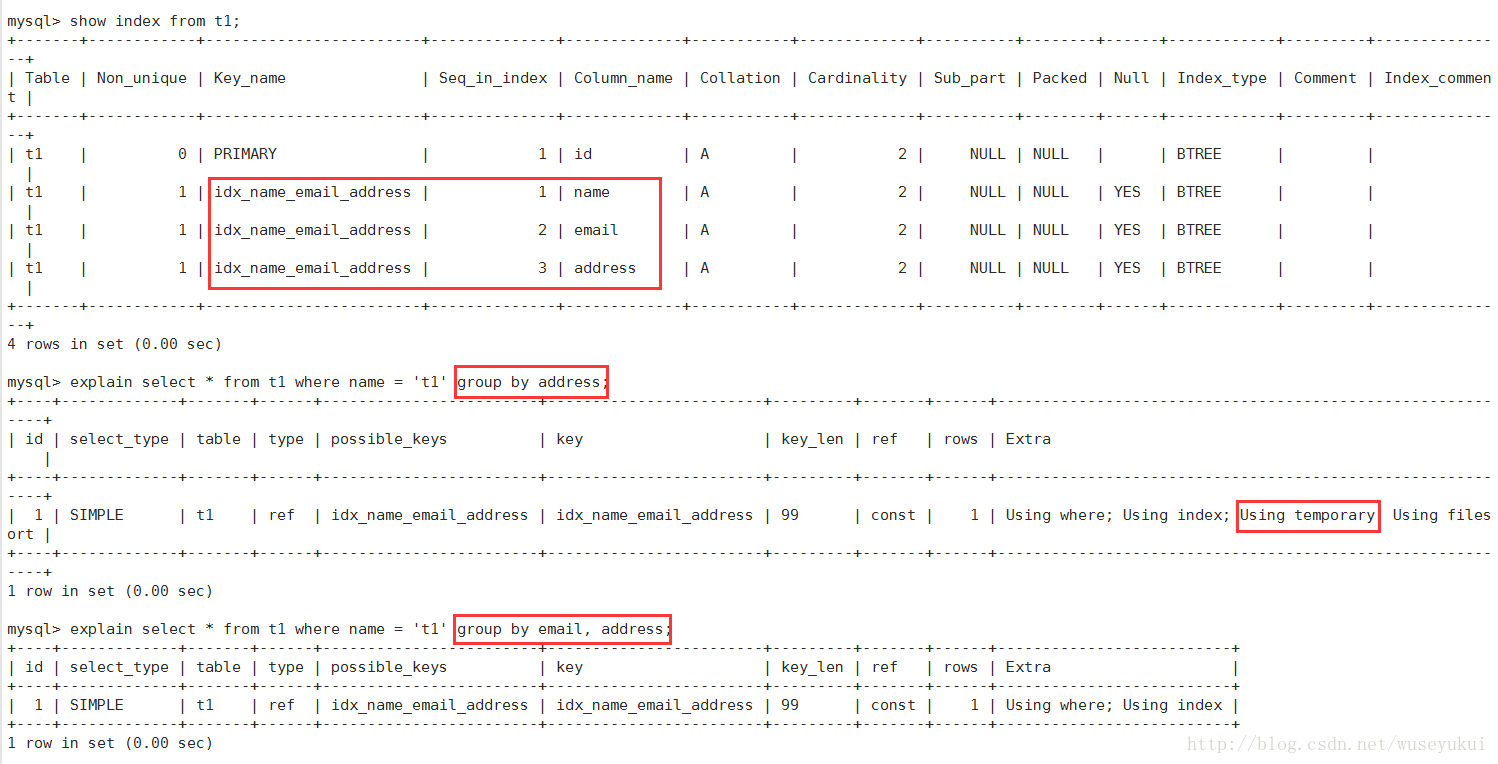
2、Using temporary:
使用临时表保存中间结果,也就是说mysql在对查询结果排序时使用了临时表,常见于order by 和 group by
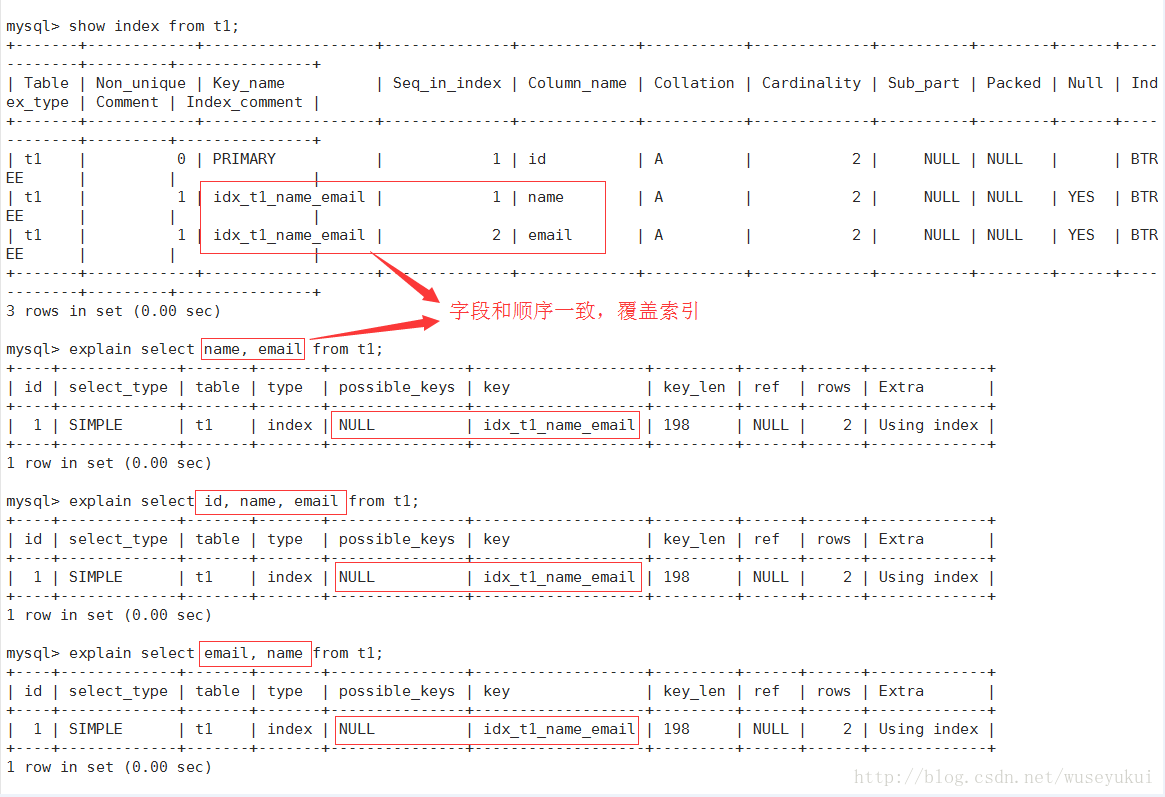
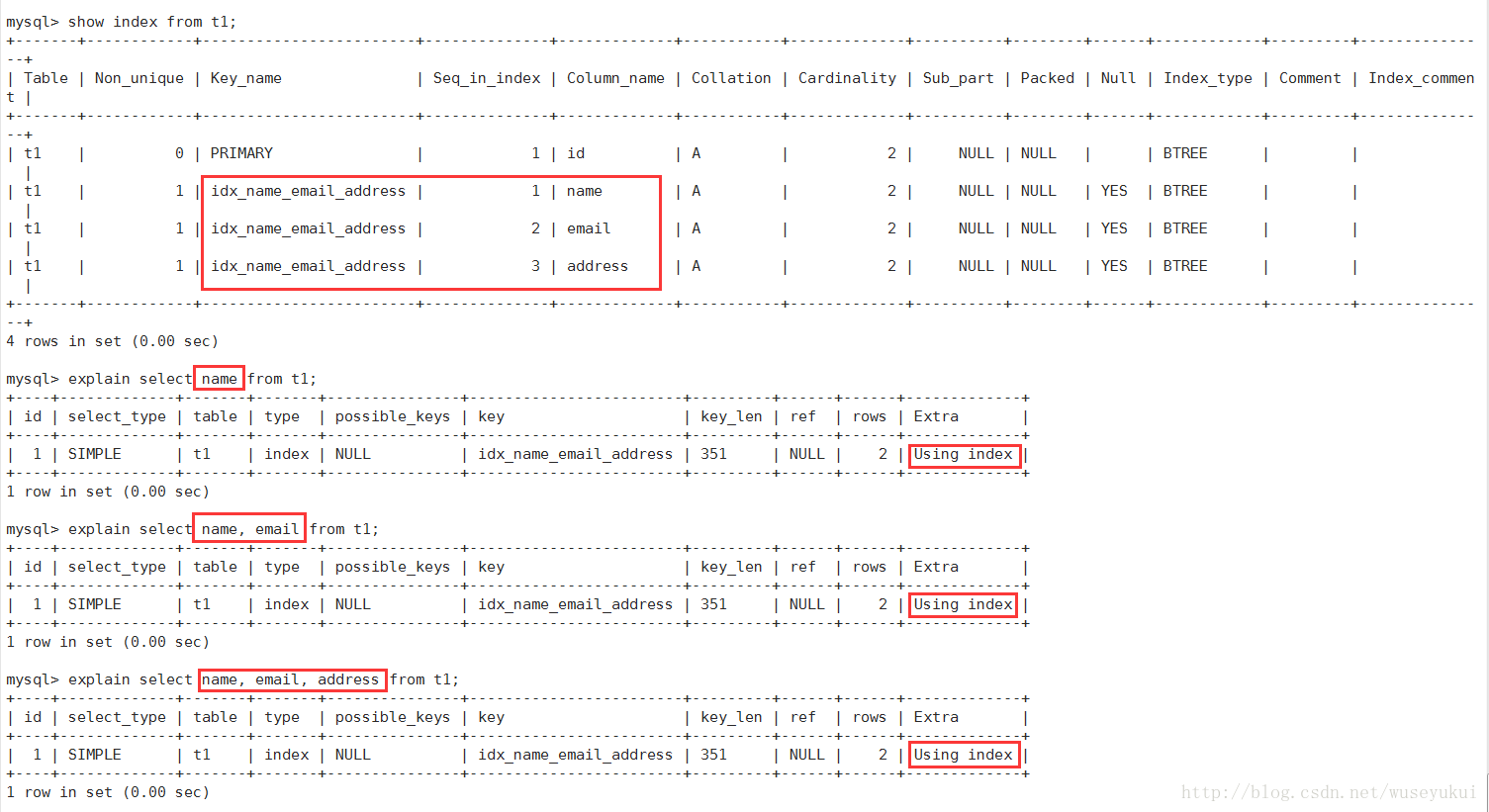
3、Using index:
表示相应的select操作中使用了覆盖索引(Covering Index),避免了访问表的数据行,效率高
如果同时出现Using where,表明索引被用来执行索引键值的查找(参考上图)
如果没用同时出现Using where,表明索引用来读取数据而非执行查找动作
覆盖索引(Covering Index):也叫索引覆盖。就是select列表中的字段,只用从索引中就能获取,不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖。
注意:
a、如需使用覆盖索引,select列表中的字段只取出需要的列,不要使用select *
b、如果将所有字段都建索引会导致索引文件过大,反而降低crud性能
4、Using where :
使用了where过滤
5、Using join buffer :
使用了链接缓存
6、Impossible WHERE:
where子句的值总是false,不能用来获取任何元祖

7、select tables optimized away:
在没有group by子句的情况下,基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作,不必等到执行阶段在进行计算,查询执行计划生成的阶段即可完成优化
8、distinct:
优化distinct操作,在找到第一个匹配的元祖后即停止找同样值得动作
综合Case

执行顺序
1(id = 4)、【select id, name from t2】:select_type 为union,说明id=4的select是union里面的第二个select。
2(id = 3)、【select id, name from t1 where address = ‘11’】:因为是在from语句中包含的子查询所以被标记为DERIVED(衍生),where address = ‘11’ 通过复合索引idx_name_email_address就能检索到,所以type为index。
3(id = 2)、【select id from t3】:因为是在select中包含的子查询所以被标记为SUBQUERY。
4(id = 1)、【select d1.name, … d2 from … d1】:select_type为PRIMARY表示该查询为最外层查询,table列被标记为 “derived3”表示查询结果来自于一个衍生表(id = 3 的select结果)。
5(id = NULL)、【 … union … 】:代表从union的临时表中读取行的阶段,table列的 “union 1, 4”表示用id=1 和 id=4 的select结果进行union操作。
原贴:https://blog.csdn.net/wuseyukui/article/details/71512793
( 转 ) MySQL高级 之 explain执行计划详解的更多相关文章
- MySQL高级 之 explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- MySQL高级 之 explain执行计划详解(转)
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- Mysql探索之Explain执行计划详解
前言 如何写出效率高的SQL语句,提到这必然离不开Explain执行计划的分析,至于什么是执行计划,如何写出高效率的SQL,本篇文章将会一一介绍. 执行计划 执行计划是数据库根据 SQL 语句和相关表 ...
- MySQL — 优化之explain执行计划详解(转)
EXPLAIN简介 EXPLAIN 命令是查看查询优化器如何决定执行查询的主要方法,使用EXPLAIN,只需要在查询中的SELECT关键字之前增加EXPLAIN这个词即可,MYSQL会在查询上设置一个 ...
- 高性能mysql 附录D explain执行计划详解
EXPLAIN: extended关键字:在explain后使用extended关键字,可以显示filtered列和warning信息.在较旧的MySQL版本中,扩展信息是使用EXPLAIN EXTE ...
- MySQL性能分析, mysql explain执行计划详解
MySQL性能分析 MySQL性能分析及explain用法的知识是本文我们主要要介绍的内容,接下来就让我们通过一些实际的例子来介绍这一过程,希望能够对您有所帮助. 1.使用explain语句去查看分析 ...
- MySql——Explain执行计划详解
使用explain关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的,分析你的查询语句或是表结构的性能瓶颈. explain执行计划包含的信息 其中最重要的字段为:i ...
- 【夯实Mysql基础】mysql explain执行计划详解
原文地址 1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A ...
- mysql explain执行计划详解
1).id列数字越大越先执行,如果说数字一样大,那么就从上往下依次执行,id列为null的就表是这是一个结果集,不需要使用它来进行查询. 2).select_type列常见的有: A:simp ...
随机推荐
- [POJ1631]Bridging signals
题目大意:不知,根据样例猜测为最长上升子序列(竟然还对了) 题解:$O(n log_2 n)$,求二维偏序,(q为存答案的序列,a存原序列,len为答案) for(int i = 1; i <= ...
- [AHOI2013]作业 & Gty的二逼妹子序列 莫队
---题面--- 题解: 题目要求统计一个区间内数值在[a, b]内的数的个数和种数,而这个是可以用树状数组统计出来的,所以可以考虑莫队. 考虑区间[l, r]转移到[l, r + 1],那么对于维护 ...
- MySQL事物机制具备四点:简称ACID操作
MySQL事物机制具备四点:简称ACID操作 1.原子性:要么都做,要么都不做(两条数据(写入和存储)一步未成功,整体回滚) 2.一致性:数据库的状态改变(两条数据(写入和存储)均成功,符合原子性,但 ...
- 洛谷P4591 [TJOI2018]碱基序列 【KMP + dp】
题目链接 洛谷P4591 题解 设\(f[i][j]\)表示前\(i\)个串匹配到位置\(j\)的方案数,匹配一下第\(i\)个串进行转移即可 本来写了\(hash\),发现没过,又写了一个\(KMP ...
- BZOJ3456 城市规划 【多项式求逆】
题目链接 BZOJ3456 题解 之前我们用分治\(ntt\)在\(O(nlog^2n)\)的复杂度下做了这题,今天我们使用多项式求逆 设\(f_n\)表示\(n\)个点带标号无向连通图数 设\(g_ ...
- 【BZOJ 1724】[Usaco2006 Nov]Fence Repair 切割木板 堆+贪心
堆对于stl priority_queue ,我们自己定义的类自己重载<,对于非自定义类我们默认大根堆,如若改成小根堆则写成std::priority<int,vector<int& ...
- 【BZOJ 3144】 [Hnoi2013]切糕 真·最小割
一开始一脸懵逼后来发现,他不就是割吗,我们只要满足条件就割就行了,于是我们把他连了P*Q*R条边,然而我们要怎样限制D呢?我们只要满足对于任意相邻的两条路,只要其有个口大于D就不行就好了因此我们只要把 ...
- APP兼容性测试
一.APP兼容性范围以及问题 1.硬件 各个硬件结构 2.软硬件之间 硬件dll库(C++) 软硬件之间的通信,各个厂商提供的ROM 3.软件 浏览器.操作系统.数据库.手机.功能兼容性(功能修改,二 ...
- Spring 学习笔记(一)
一.Spring 是什么? •Spring 是一个开源框架. •Spring 为简化企业级应用开发而生. 使用 Spring 可以使简单的 JavaBean 实现以前只有 EJB 才能实现的功能. • ...
- python_plot画图参数设置
# coding:utf-8 import pandas as pd import numpy as np import matplotlib.pyplot as plt # one_hot数据的读取 ...