Hadoop完全分布式环境搭建(二)——基于Ubuntu16.04设置免密登录
在Windows里,使用虚拟机软件Vmware WorkStation搭建三台机器,操作系统Ubuntu16.04,下面是IP和机器名称。
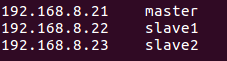
【实验目标】:在这三台机器之间实现免密登录
1、从主节点可以免密登陆到主节点
2、从主节点可以免密登陆到其它两个从节点
3、从两台从节点可以免密登陆主节点,两台从节点可以免密互相登陆。
【 注意】:1、2这两点是建立大数据Hadoop完全分布式环境需要的。
【搭建准备】
1、三台机器上已建立一个共同的账号:hadoop,口令一致
2、hadoop账号在/home下建立了hadoop文件夹
说明:简单的指令:useradd haddop 不会在/home下建立文件夹,需要加参数。
采用这种方式:useradd -m username
3、为hadoop账号授权
sudo vim /etc/sudoers
修改文件如下,在root ALL=(ALL) ALL下面增加hadoop ALL=(ALL) ALL
# User privilege specification
root ALL=(ALL) ALL
hadoop ALL=(ALL) ALL
4、检查是否已有ssh,没有,则安装,为每台机器安装openssh-server xx
sudo apt-get install openssh-server
【设置步骤】
1、在主节点master上设置
1)、$cd ~/.ssh
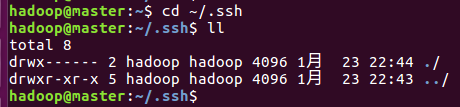
使用ll命令查看,当前~/.ssh文件夹下是空的
2)、生成一对密钥,本机的密钥,放在.ssh文件夹下
$ ssh-keygen -t rsa
生成过程中,一路回车即可。
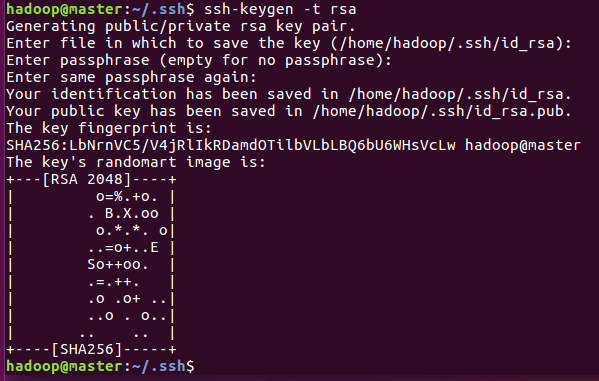
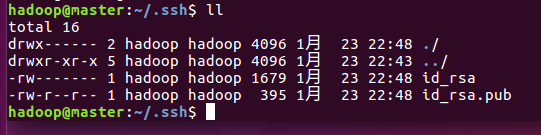
3)使用ll命令查看,可看到生成了两个文件id_rsa和id_rsa.pub
4)、让主节点能够免密登录到主节点,把密钥传到授权Keys里
$ cat ./id_rsa.pub >> ./authorized_keys
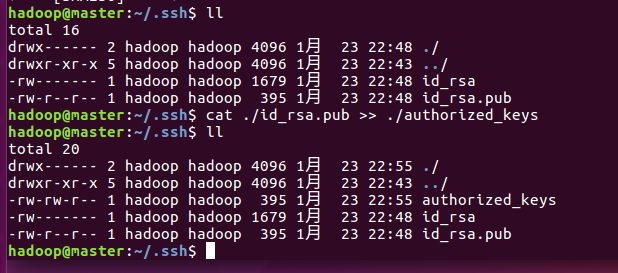
使用ll查看,在.ssh文件夹下,新生成了authorized_keys
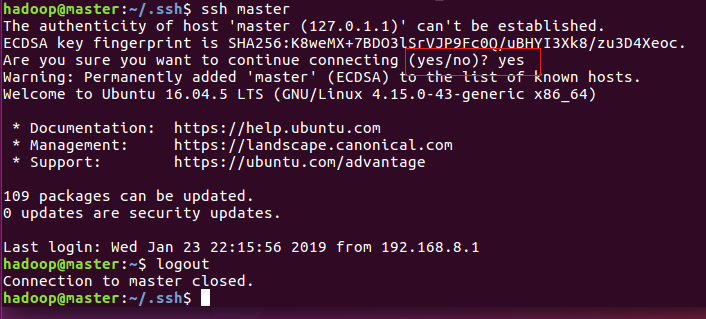
5)、使用ssh 登录主节点,$ssh master ,会询问yes/no,输入yes,如下图,使用logout退出ssh登录到本机
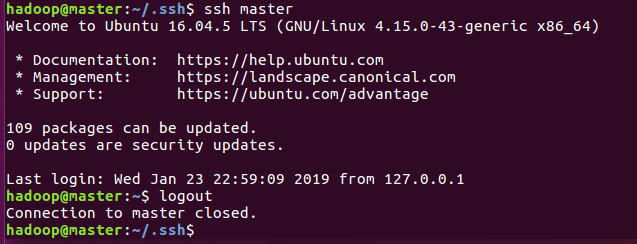
6)、再次登录,则不再提示是否yes/no,直接免密登录到本机
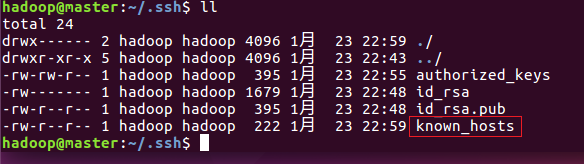
7)、在使用ssh登录主节点以后,在.ssh文件夹里新增了一个文件:known_hosts
8)、把主节点master上生成的公钥id_rsa.pub传到其它两台机器,以实现免密登录其它两台机器
$ scp ~/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/
其中,hadoop@slave1,@前面的hadoop是账号,@后面的slave1是目标机器的机器名称,也可以写成IP地址
/home/hadoop/是传到目标机器上的存储路径
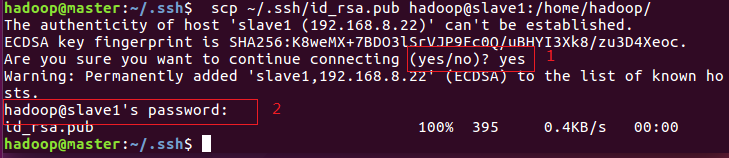
在传的过程中,会询问yes/no,输入yes,会询问目标机器的登录口令,输入指令里@前所用账号的口令
注意:这三台机器的文件路径都是:/home/hadoop/.ssh
home后面的hadoop是作为账号hadoop生成的相应文件夹
从其它机器传过来的密钥,放在.ssh的上一级目录,即:/home/hadoop下,在.ssh里存放的是本机的密钥
更改指令$ scp ~/.ssh/id_rsa.pub hadoop@slave2:/home/hadoop/ 传到另一台机器上
2、分别在另外两台机器上,以hadoop账号登录,把传过来的公钥钥传到授权Keys里
先切换目录:$cd ~
使用ll查看,发现已经有了从主节点传过来的id_rsa.pub
使用指令把传过来的公钥传入授权Keys里:$cat ~/id_rsa.pub >> ~/.ssh/authorized_keys

再另外一台机器上也进行此项操作
3、从主节点使用ssh测试是否能免密登录到其它两台机器
输入指令:$ssh slave1
由下图可以看出,已经可以免密登录,输入logout退出
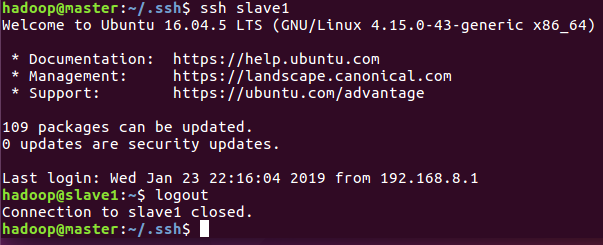
同样,从主节点测试免密登录另一台从节点。
4、清理两台从节点上由主节点传过来的公钥
cd ~
rm -f id_rsa.pub
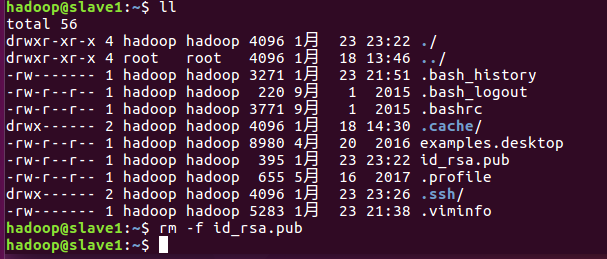
5、如果想让两台从节点也能分别访问另外一台从节点和主节点,则参照上面的步骤,把从节点生成的公钥传到另一台从节点上和主节点上,传到授权Key里
【注意事项】
1、生成密钥和把密钥传到授权keys里,都需要使用同一个账号,准备用来运行hadoop的那个账号,如果中间穿插使用其它账号,则无效。
2、生成本机密钥需进入hadoop账号下的.ssh文件夹下,在此文件夹下生成。
3、把id_rsa.pub往其它机器拷贝的时候,拷贝到目标机器/home/hadoop下,也就是在.ssh的上级目录接收其它机器传过来的密钥
4、在目标机器把密钥加到授权keys以后,从发出机器测试能免密登陆到目标机器后,及时清理传过来的id_rsa.pub,因为后面还要接收其它机器传过来的密钥,避免受到干扰,漏把id_rsa.pub传到授权keys里,或把其它机器的密钥再传一次到授权keys里。
Hadoop完全分布式环境搭建(二)——基于Ubuntu16.04设置免密登录的更多相关文章
- CentOS7下Hadoop伪分布式环境搭建
CentOS7下Hadoop伪分布式环境搭建 前期准备 1.配置hostname(可选,了解) 在CentOS中,有三种定义的主机名:静态的(static),瞬态的(transient),和灵活的(p ...
- 【转】Hadoop HDFS分布式环境搭建
原文地址 http://blog.sina.com.cn/s/blog_7060fb5a0101cson.html Hadoop HDFS分布式环境搭建 最近选择给大家介绍Hadoop HDFS系统 ...
- 【Hadoop离线基础总结】CDH版本Hadoop 伪分布式环境搭建
CDH版本Hadoop 伪分布式环境搭建 服务规划 步骤 第一步:上传压缩包并解压 cd /export/softwares/ tar -zxvf hadoop-2.6.0-cdh5.14.0.tar ...
- hadoop ——完全分布式环境搭建
hadoop 完全分布式环境搭建 1.虚拟机角色分配: 192.168.44.184 hadoop02 NameNode/DataNode ResourceManager/NodeManager 19 ...
- Hadoop完全分布式环境搭建(三)——基于Ubuntu16.04安装和配置Java环境
[系统环境] 1.宿主机OS:Win10 64位 2.虚拟机软件:VMware WorkStation 12 3.虚拟机OS:Ubuntu16.04 4.三台虚拟机 5.JDK文件:jdk-8u201 ...
- Hadoop完全分布式环境搭建(四)——基于Ubuntu16.04安装和配置Hadoop大数据环境
[系统环境] [安装配置概要] 1.上传hadoop安装文件到主节点机器 2.给文件夹设置权限 3.解压 4.拷贝到目标文件夹 放在/opt文件夹下,目录结构:/opt/hadoop/hadoop-2 ...
- 《OD大数据实战》Hadoop伪分布式环境搭建
一.安装并配置Linux 8. 使用当前root用户创建文件夹,并给/opt/下的所有文件夹及文件赋予775权限,修改用户组为当前用户 mkdir -p /opt/modules mkdir -p / ...
- Hadoop完全分布式环境搭建
前言 本文搭建了一个由三节点(master.slave1.slave2)构成的Hadoop完全分布式集群(区别单节点伪分布式集群),并通过Hadoop分布式计算的一个示例测试集群的正确性. 本文集群三 ...
- Hadoop伪分布式环境搭建+Ubuntu:16.04+hadoop-2.6.0
Hello,大家好 !下面就让我带大家一起来搭建hadoop伪分布式的环境吧!不足的地方请大家多交流.谢谢大家的支持 准备环境: 1, ubuntu系统,(我在16.04测试通过.其他版本请自行测试, ...
随机推荐
- yield 与生成器
yield的功能类似于return,但是不同之处在于它返回的是生成器. 生成器 生成器是通过一个或多个yield表达式构成的函数,每一个生成器都是一个迭代器(但是迭代器不一定是生成器). 如果一个函数 ...
- 剑指offer-第七章面试案例1(字符串转换为整型)
//将字符串转换为整型 //思路:特殊的输入测试: //1,考虑字符串是否为空.2.字符串问空的时候的返回0,和真实的返回0直键的区别.3,字符串中出现0~9的字符处理 //4.字符串中出现*,¥等一 ...
- WCF Restful 服务 Get/Post请求
Restful Get方式请求: Restful服务 Get请求方式:http://localhost:10718/Service1.svc/Get/A/B/C http://localhost:1 ...
- phpredis的使用
phpredis的具体使用方法可以参照:https://github.com/phpredis/phpredis
- 从如何优化SQL入手,提高数据仓库的ETL效率
1 引言数据仓库建设中的ETL(Extract, Transform, Load)是数据抽取.转换和装载到模型的过程,整个过程基本是通过控制用SQL语句编写的存储过程和函数的方式来实现对 ...
- 在Toad中导入导出数据
一.导出数据 右键点击所要导出的表名,选择“Export Date” 二.导入数据 一.右键点击表名,选择“import date” 二.下一步 三.下一步 四.下一步 在oracl ...
- Android Socket编程
花了大概两天的时间,终于把Android的Socket编程给整明白了.抽空和大家分享一下: Socket Programming on Android Socket 编程基础知识: 主要分服务器端编程 ...
- elang和python互通的例子
抄袭自http://www.erlangsir.com/2011/04/14/python-%E5%92%8Cerlang%E4%BA%92%E9%80%9A%E4%BE%8B%E5%AD%90/ t ...
- 利用全局变量$_SESSION和register_shutdown_function自定义会话处理
register_shutdown_function 可以注册一个自定义的函数,在程序运行结束之前 执行. 在做ecshop的二次开发过程中,虽然代码 太老太乱太冗余,但ec的会话处理的设计感觉还是不 ...
- Linux内核中常见内存分配函数
1. 原理说明 Linux内核中采用了一种同时适用于32位和64位系统的内存分页模型,对于32位系统来说,两级页表足够用了,而在x86_64系统中,用到了四级页表,如图2-1所示.四级页表分 ...