HttpClient拉取连载小说
上午刚入手的小说,下午心血来潮想从网站上拉取下来做成电子书,呵呵,瞎折腾~说做就做~
【抓包】
这一步比什么都重要,如果找不到获取真正资源的那个请求,就什么都不用做了~
先是打算用迅雷把所有页面都下载下来然后本地处理,结果发现保存下来的页面都只有界面没有内容~看了看Javascript的代码,原来是ready的时候再ajax发送post到另一个网址取内容。
于是再抓包核实一下。抓包工具真难搞,试了两三个都没成功,最后还是用firefox搞定了~打开页面共发送了50个请求,不过post只有两个,很快就看到http包的内容了。
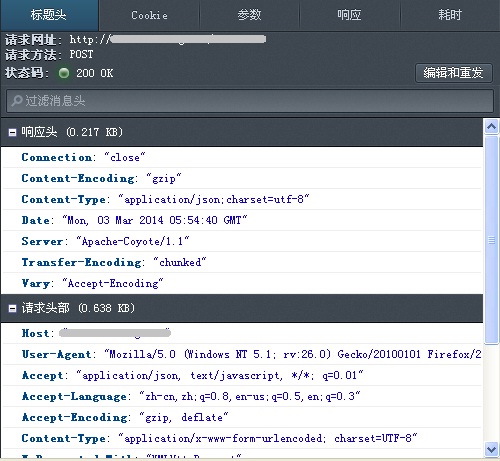
【写程序拉取】
网址,请求的header,表单 都具备了,还等什么,赶紧码字爬取啦~本来还担心要伪装浏览器,要填入cookies内容,调试起来发现是想太多了,直奔网址带上表单就够了~
HttpClient的用法是现炒现卖,官方example的QuickStart.java就够很清晰了。再有就是debug进去看请求和响应。
用法见HttpPost和crawlOnePage(HttpRequestBase)。MyFileWriter就不贴出来献丑了,反正就是个I/O。
遇到并解决的问题:
1.响应回来的资源是gzip压缩过的,要用对应的类去解码;
2.网址序列号中个别缺页,通过判断响应里的状态码跳过即可。
(全文完,以下是代码。)
package mycrawl; import java.io.IOException;
import java.util.ArrayList;
import java.util.List; import org.apache.http.HttpEntity;
import org.apache.http.NameValuePair;
import org.apache.http.client.ClientProtocolException;
import org.apache.http.client.entity.GzipDecompressingEntity;
import org.apache.http.client.entity.UrlEncodedFormEntity;
import org.apache.http.client.methods.CloseableHttpResponse;
import org.apache.http.client.methods.HttpPost;
import org.apache.http.client.methods.HttpRequestBase;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClients;
import org.apache.http.message.BasicNameValuePair;
import org.apache.http.util.EntityUtils; import crawl.common.MyFileWriter; public class MyCrawl { private static CloseableHttpClient httpclient = HttpClients.createDefault(); /**
* (1)建立post对象,包括网址和表单 (2)循环抓取每页并处理输出
*
* @param args
* @throws IOException
*/
public static void main(String[] args) throws IOException {
final int startChapter = 页面序列号;
final int endChapter = 页面序列号;
final Integer bookId = bookid;
String outPattern = "c:\\book*.txt";
MyFileWriter fw = new MyFileWriter(outPattern); // 创建post操作
HttpPost httpPost = new HttpPost("网址");
List<NameValuePair> nvps = new ArrayList<NameValuePair>(2); try {
// post的表单内容
nvps.add(new BasicNameValuePair("b", bookId.toString()));
nvps.add(new BasicNameValuePair("c", "placeholder")); for (Integer i = startChapter, j = 0; i <= endChapter; i++, j++) {
// 循环抓取连续章节
nvps.set(1, new BasicNameValuePair("c", i.toString()));
httpPost.setEntity(new UrlEncodedFormEntity(nvps)); String outStr = MyCrawl.crawlOnePage(httpPost);
if (outStr == null || outStr.isEmpty()) {
j--;
continue;
}
// 处理章节标题,懒得去抓取标题页了。
outStr = "====== " + MyCrawl.chapterArr[j] + "\r\n"
+ MyCrawl.prettyTxt(outStr);
// System.out.println(outStr);
fw.rollingAppend(outStr);
}
fw.getFileWriter().flush();
fw.getFileWriter().close();
System.out.println("已完成"); } finally {
httpclient.close();
}
} /**
* 抓取单页
*
* @param req
* @return result
* @throws ClientProtocolException
* @throws IOException
*/
public static String crawlOnePage(HttpRequestBase req)
throws ClientProtocolException, IOException { String result;
CloseableHttpResponse resp = httpclient.execute(req); // 处理返回码
int status = resp.getStatusLine().getStatusCode();
if (status < 200 || status >= 300) {
System.out.println("[Error] " + resp.getStatusLine().toString());
return "";
} else if (status != 200) {
System.out.println("[Warn] " + resp.getStatusLine().toString());
return "";
} HttpEntity entity = resp.getEntity();
if (entity instanceof GzipDecompressingEntity) {
// 解压缩内容
GzipDecompressingEntity gEntity = (GzipDecompressingEntity) entity;
result = EntityUtils.toString(gEntity);
} else {
result = EntityUtils.toString(entity);
} EntityUtils.consume(entity);
resp.close();
return result;
} /**
* 处理换行等特殊字符
*
* @param txt
* @return string
*/
public static String prettyTxt(String txt) {
if (txt == null || txt.isEmpty()) {
return "";
}
int contentStart = txt.indexOf("content") + 10;
int contentEnd = txt.indexOf(" <br/><br/> \",\"next");
txt = txt.substring(contentStart, contentEnd);
return txt.replace("<br/><br/>", "\r\n");
} // 章节标题
private static final String[] chapterArr = new String[] { "第一章",
"第二章" }; }
HttpClient拉取连载小说的更多相关文章
- 《破碎的残阳,我们逆光》连载小说- HashMap剖析
破碎的残阳,我们逆光[连载小说]- HashMap剖析 "行到水穷处,坐看云起时" 前言: 偶尔翻阅了自己当时高中时代写的日志,发现了几篇自己多年未打开的自写小说草本 ...
- Python的scrapy之爬取顶点小说网的所有小说
闲来无事用Python的scrapy框架练练手,爬取顶点小说网的所有小说的详细信息. 看一下网页的构造: tr标签里面的 td 使我们所要爬取的信息 下面是我们要爬取的二级页面 小说的简介信息: 下面 ...
- 一步步教你用Prometheus搭建实时监控系统系列(二)——详细分析拉取和推送两种不同模式
前言 本系列着重介绍Prometheus以及如何用它和其周边的生态来搭建一套属于自己的实时监控告警平台. 本系列受众对象为初次接触Prometheus的用户,大神勿喷,偏重于操作和实战,但是重要的概念 ...
- github拉取和推送
登入github 创建一个开源项目 然后打开安装好的git 首先进入一个指定的文件夹 例如: 1)E:\>cd miaov/testGit 回车 进入E盘的testGit文件夹 2)E:\mia ...
- git&sourcetree安装及在IntelliIJ下拉取项目基础使用
be careful: 1)git版本与Sourcetree版本最好一致 ,不能git为2.5,sourcetree为1.8 2)先安装git再安装Sourcetree 3)拥有git和sourcet ...
- ***git 本地提交后如果让服务器上的GIT 自动更新拉取
Q: 最近配了个服务器,用的GIT,本地提交后服务器必须再拉取一下才能更新出来..求个提交后自动更新的方法 A: 最佳工具 git hook post-update.sample 改名为post-up ...
- Spark Streaming中向flume拉取数据
在这里看到的解决方法 https://issues.apache.org/jira/browse/SPARK-1729 请是个人理解,有问题请大家留言. 其实本身flume是不支持像KAFKA一样的发 ...
- 用setTimeout 代替 setInterval实时拉取数据
在开发中,我们常常碰到需要定时拉取网站数据,如: setInterval(function(){ $.ajax({ url: 'xx', success: function( response ){ ...
- laravel项目拉取下来安装,node.js库安装
1.拉取项目 2.切换分支 圈圈里面是版本 composer 安装laravel组件其他库 安装node.js安装包 npm set registry=https://registry.npm.ta ...
随机推荐
- 毕业设计 python opencv实现车牌识别 码云地址
码云地址:https://gitee.com/yinghualuowu/Python_VLPR 删除了冗余代码,可以更加便于运行.其实是为了那些进不去github准备的~
- datetime和date如何转json
import json from datetime import datetime, date class MyJson(json.JSONEncoder): def default(self, o) ...
- spring初始化bean的目的
初始化bean就是为了将所有需要的bean全部装载到容器里面,等我们需要用到哪个bean就将哪个bean从容器里面拿出来
- pjsip与QT进行适配
pjsip是纯C语言写的一个sip协议库,整个代码写得还是比较模块化的,得益于此的设计,只要理解了pjsip的设计,就可以对其网络层进行扩展. 我们项目是QT作为主要开发工具,而PJSIP的库默认是利 ...
- LeetCode 200.岛屿的个数
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量.一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的.你可以假设网格的四个边均被水包围. 示例 1: 输入: ...
- 如何实现一个简单的MVVM框架
接触过web开发的同学想必都接触过MVVM,业界著名的MVVM框架就有AngelaJS.今天闲来无事,决定自己实现一个简单的MVVM框架玩一玩.所谓简单,就是仅仅实现一个骨架,仅表其意,不摹其形. 分 ...
- java线程中的 sleep() wait() yield()
sleep()方法是让线程休眠 可以指定时间 其实就是让线程进入阻塞状态 指定的时间过后 进入就绪状态 不释锁 相当于抱着锁睡觉 wait() 让线程进入等待状态 被唤醒后才会继续执行 ...
- Linux IO
Linux 系统编程(IO) 工具 strace: 根据系统调用 od -tcx: 查看二进制 函数参数 使用const修改的指针为传入参数 不使用const的指针为传出参数 string操作的函数 ...
- js 中 前端过滤数据到后端的方法
第一种方法: <!DOCTYPE html><html lang="en"><head> <meta charset="UTF- ...
- PCA (主成分分析)详解——转载 古剑寒
转载地址:http://my.oschina.net/gujianhan/blog/225241 另外可以参考相关博文:http://blog.csdn.net/neal1991/article/de ...