Java Set集合(HashSet、TreeSet)
什么是HashSet?操作过程是怎么样的?
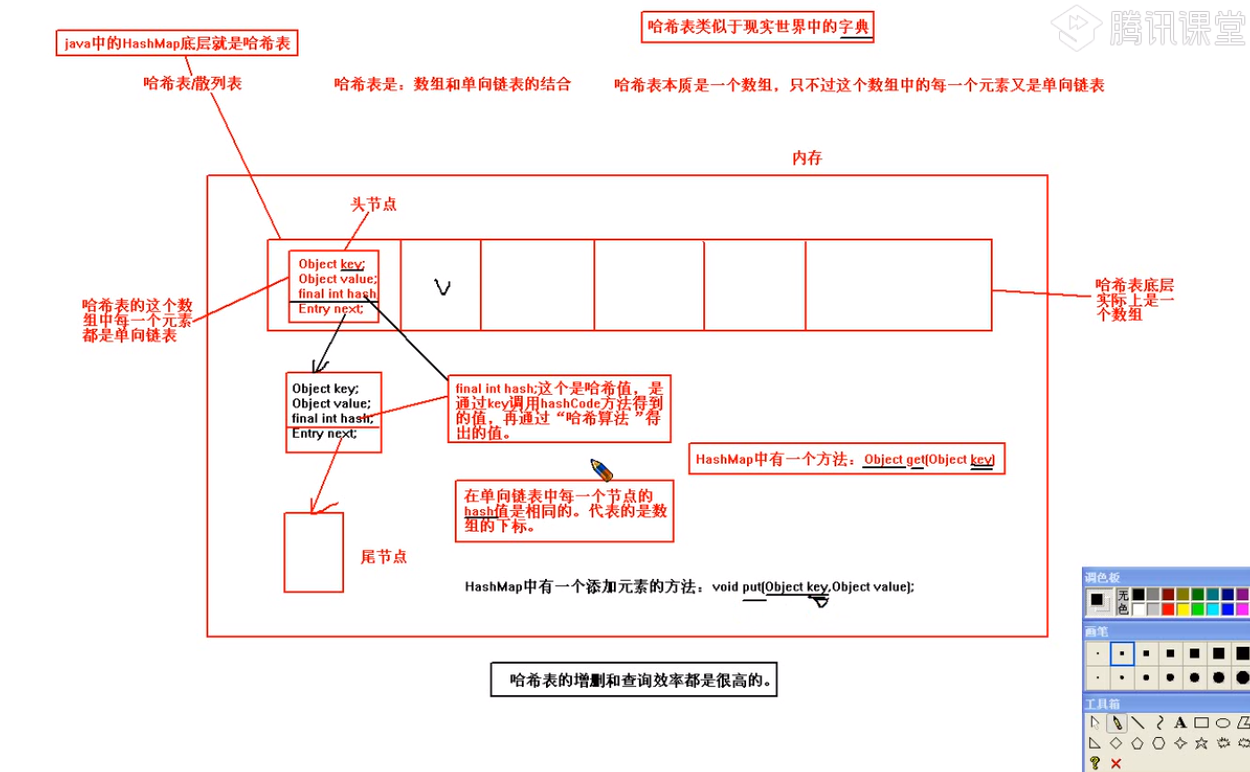
1、HashSet底层实际上是一个HashMap,HashMap底层采用了哈希表数据结构
2、哈希表又叫做散列表,哈希表底层是一个数组,这个数组中每一个元素是一个单向链表,每个单向链表都有一个独一无二的hash值,代表数组的下标。在某个单向链表中的每一个节点上的hash值是相同的。hash值实际上是key调用hashCode方法,再通过"hash function"转换成的值
3、如何向哈希表中添加元素?
先调用被存储的key的hashCode方法,经过某个算法得出hash值,如果在这个哈希表中不存在这个hash值,则直接加入元素。如果该hash值已经存在,继续 调用Key之间的equals方法,如果equals方法返回false,则将该元素添加。如果equals方法返回true,则放弃添加该元素
HashMap和HashSet初始化容量是16,默认加载因子是0.75
HashSet的数据结构
献上我看视频截的图
代码举例
public class Test{
public static void main(String[] args) {
Set set = new HashSet();
Student stu1 = new Student("1", "JACK");
Student stu2 = new Student("2", "TOM");
Student stu3 = new Student("3", "JIM");
set.add(stu1);
set.add(stu2);
set.add(stu3);
System.out.println("size :" + set.size());
}
}
class Student{
String no;
String name;
Student(String no, String name){
this.no = no;
this.name = name;
}
}
这个的输出结果显而易见是3,因为我们添加了三个元素,但是如果改一下
Student stu1 = new Student("1", "JACK");
Student stu2 = new Student("1", "JACK");
Student stu3 = new Student("3", "JIM");
System.out.println(stu1.hashCode());
System.out.println(stu2.hashCode());
可以运行试一下,stu1和stu2的hashCode是不一样的,为什么呢?因为这两个对象是New出来的,引用地址不一样。我们不希望出现这样的情况,那就要重写hashCode和equals方法
class Student{
String no;
String name;
Student(String no, String name){
this.no = no;
this.name = name;
}
public boolean equals(Object o){
if(this == o) return true;
if(o instanceof Student){
Student student = (Student) o;
if(student.no.equals(this.no) && student.name.equals(this.name)) return true;
}
return false;
}
public int hashCode(){
return no.hashCode();
}
}
再次运行,插入两个数据一样的对象,就不会重复了
TreeSet
treeset实现了sortedset接口,有个很重要的特点是里面的元素都是有序的
public class Test{
public static void main(String[] args) {
SortedSet set = new TreeSet();
set.add(1);
set.add(100);
set.add(50);
System.out.println(set);
}
}
输出结果:[1, 50, 100]
那如果我们自定义类可以进行比较吗?
public class Test{
public static void main(String[] args) {
SortedSet set = new TreeSet();
Student stu1 = new Student(22);
Student stu2 = new Student(11);
Student stu3 = new Student(100);
set.add(stu1);
set.add(stu2);
set.add(stu3);
System.out.println(set);
}
}
class Student{
int age;
Student(int age){
this.age = age;
}
}
这样运行会出现一个问题,报ClassCastException,这就需要来看看源码了,底层到底是怎么实现的,为什么自定义类就先不行呢?
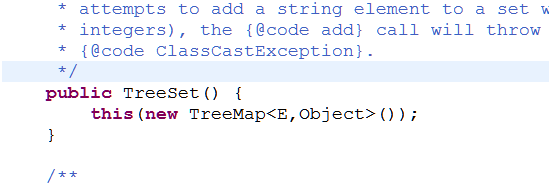
这里可以看到,当我们在创建一个TreeSet的时候,实际上是new了一个TreeMap

add的时候调用了TreeMap的put方法,来看看TreeMap中的put方法

可以看到第三个红框那里,会对key进行一个强制类型转换,我们上面的代码肯定是就是在这里装换不成功,Comparable是什么?来看看API

是一个接口,从翻译就可以看出,只要实现了这个接口,就是可以比较的,下面是实现了这个接口的类

随便框了几个,上面就有Integer,这个类实现了comparable接口,因此第一个代码是正确的,现在我们是不是只要实现这个接口就好了呢!
class Student implements Comparable{
int age;
Student(int age){
this.age = age;
}
//重写接口中的方法
//要重写比较规则
@Override
public int compareTo(Object o) {
// TODO Auto-generated method stub
int age1 = this.age;
int age2 = ((Student)o).age;
return age2 - age1;
}
}
这样OK了,再来看看上面有红框的源码,cmp<0,cmp>0,left,right都是什么东西,二叉树!所以底层是通过二叉树来排序的
如果是自定义类中的String呢,那就return String的compareTo方法就好了
Java Set集合(HashSet、TreeSet)的更多相关文章
- Set集合[HashSet,TreeSet,LinkedHashSet],Map集合[HashMap,HashTable,TreeMap]
------------ Set ------------------- 有序: 根据添加元素顺序判定, 如果输出的结果和添加元素顺序是一样 无序: 根据添加元素顺序判定,如果输出的结果和添加元素的顺 ...
- Java容器---Set: HashSet & TreeSet & LinkedHashSet
1.Set接口概述 Set 不保存重复的元素(如何判断元素相同呢?).如果你试图将相同对象的多个实例添加到Set中,那么它就会阻止这种重复现象. Set中最常被使用的是测试归属性,你可以 ...
- Java基础---集合框架---迭代器、ListIterator、Vector中枚举、LinkedList、ArrayList、HashSet、TreeSet、二叉树、Comparator
为什么出现集合类? 面向对象语言对事物的体现都是以对象的形式,所以为了方便对多个对象的操作,就对对象进行存储,集合就是存储对象最常用的一种方式. 数组和集合类同是容器,有何不同? 数组虽然也可以存储对 ...
- Java集合之TreeSet
TreeSet是一个有序的集合,它的作用是提供有序的Set集合.它继承了AbstractSet抽象类,实现了NavigableSet<E>,Cloneable,Serializable接口 ...
- Java集合 HashSet的原理及常用方法
目录 一. HashSet概述 二. HashSet构造 三. add方法 四. remove方法 五. 遍历 六. 合计合计 先看一下LinkedHashSet 在看一下TreeSet 七. 总结 ...
- java数据结构之HashSet和TreeSet以及LinkedHashSet
一.HashSet源码注释 public class HashSet<E> extends AbstractSet<E> implements Set<E>, Cl ...
- 集合框架的详解,List(ArrayList,LinkedList,Vector),Set(HashSet,TreeSet)-(14)
集合详解: /* Collection |--List:元素是有序的,元素可以重复.因为该集合体系有索引. |--ArrayList:底层的数据结构使用的是数组结构.特点:查询速度很快.但是增删稍慢. ...
- Set集合——HashSet、TreeSet、LinkedHashSet(2015年07月06日)
一.Set集合不同于List的是: Set不允许重复 Set是无序集合 Set没有下标索引,所以对Set的遍历要通过迭代器Iterator 二.HashSet 1.HashSet由一个哈希表支持,内部 ...
- Java基础知识强化之集合框架笔记47:Set集合之TreeSet保证元素唯一性和比较器排序的原理及代码实现(比较器排序:Comparator)
1. 比较器排序(定制排序) 前面我们说到的TreeSet的自然排序是根据集合元素的大小,TreeSet将它们以升序排列. 但是如果需要实现定制排序,比如实现降序排序,则要通过比较器排序(定制排序)实 ...
随机推荐
- 【转】彻底理解安卓里的ldpi、mdpi、hdpi、xhdpi、xxhdpi文件夹含义
这个问题我相信困惑了好多人包括很多老鸟,而且有的人以为自己理解其实是错误的,包括之前的我在内,在做安卓适配的时候,一般让美工做720*1280的切图,就直接放到xhdpi下,如果是做了1080*192 ...
- js前端解析excel文件
使用纯Javascript解析excel文件. 使用的是开源的解析excel的js库:sheetjs.github地址:https://github.com/SheetJS/js-xlsx 首先引用J ...
- 【luogu P2002 消息扩散】 题解
题目链接:https://www.luogu.org/problemnew/show/P2002 缩点把原图变为DAG,再在DAG上判断找入度为0的点的个数. 注意一点出度为0的点的个数不等于入度为0 ...
- C#中对于float,double,decimal的误解(转载)
浮点型 Name CTS Type Description Significant Figures Range (approximate) float System.Single 32-bit sin ...
- 微信开发----JS-SDK接口
2018.03.15:GitHub下载代码 208.3.6:更新:我们不再使用JosnHelp返回字典类或者强类型,而是直接返回动态类型,这样就会方便的多. JsonHelp更新详情:微信开发---- ...
- JSON Web Tokens介绍
转载请标明出处: http://blog.csdn.net/forezp/article/details/72804324 本文出自方志朋的博客 ##什么是JWT 这篇文章选择性翻译于https:// ...
- 跨Vlan通信:单臂路由,三层交换机
实验涉及命令以及知识补充(涉及Vlan通过的以太网口需要设置为Trunk口) 单臂路由 父接口 no ip address :删除实现单臂路由接口的IP no shutdown 虚拟子接口 R2(co ...
- c#一种存储结构解决动态平衡问题
不说其他了,最近为了实现这么一个场景了而提取的一种结构.我们把一种数据缓存,比如开辟的存储Buffer,或者连接池.放置在一个结构中.很多时候这有一个共同的特点,我们的业务在一段时间会急剧增长,我们开 ...
- SAC E#1 - 一道难题 Tree(树形DP)
题目背景 冴月麟和魏潇承是好朋友. 题目描述 冴月麟为了守护幻想乡,而制造了幻想乡的倒影,将真实的幻想乡封印了.任何人都无法进入真实的幻想乡了,但是她给前来救她的魏潇承留了一个线索. 她设置了一棵树( ...
- C++继承和派生练习(一)--关于从people(人员)类派生出student(学生)类等
. 从people(人员)类派生出student(学生)类 添加属性:班号char classNO[]:从people类派生出teacher(教师)类, 添加属性:职务char principalsh ...