SVM中的间隔最大化
参考链接:
1.https://blog.csdn.net/TaiJi1985/article/details/75087742
2.李航《统计学习方法》7.1节 线性可分支持向量机与硬间隔最大化
3.https://zhuanlan.zhihu.com/p/45444502,第三部分 手推SVM
本文目标:理解SVM的原始目标,即间隔最大化,并将其表示为约束最优化问题的转换道理。
背景知识:假设已经知道了分离平面的参数w和b,函数间隔γ',几何间隔γ,不懂的可以参考书本及其它。
为了将线性可分的数据集彻底分开,并分得最好,SVM的原始目标是找到一个平面(用w,b表示,二维数据中是一条直线,如下图所示),使得该平面与正负两类样本的最近样本点的距离最大化。简单的说,就是任给一个平面w,b,总有一个样本点离它的距离最近(点到平面的距离,可以用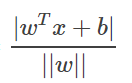 来表示),过该样本点作平行于分割平面的平面,两个平面形成分隔带。我们的目标是比较各种平面(无数个),找出一个平面使得“分隔带最胖”。那么如何来表述“分隔带最胖”呢?
来表示),过该样本点作平行于分割平面的平面,两个平面形成分隔带。我们的目标是比较各种平面(无数个),找出一个平面使得“分隔带最胖”。那么如何来表述“分隔带最胖”呢?
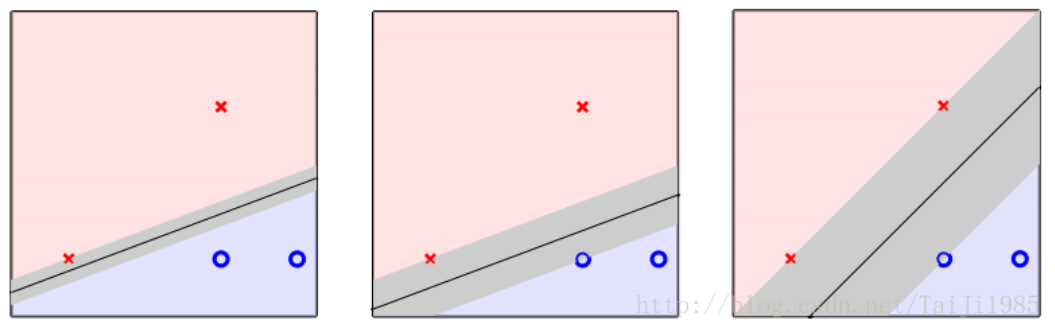 (引自参考链接1)
(引自参考链接1)
对于平面w,b来说,假设距离平面最近的点是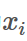 ,又由于该平面w,b可以将所有样本点正确分类,即满足
,又由于该平面w,b可以将所有样本点正确分类,即满足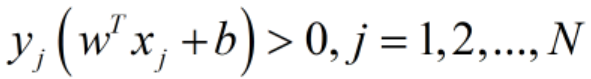 ,因此我们可以将上述最近点到平面w,b的距离改写为
,因此我们可以将上述最近点到平面w,b的距离改写为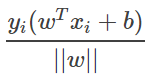 ,其中
,其中 取值为+1或-1。因此我们的目标就是最大化
取值为+1或-1。因此我们的目标就是最大化 ,注意该式子中已经是离超平面w,b最近点了,称为γ超平面w,b关于训练数据集T的几何间隔。
,注意该式子中已经是离超平面w,b最近点了,称为γ超平面w,b关于训练数据集T的几何间隔。
因此我们的原始问题:求得一个几何间隔最大的分离超平面,可以表示为下述约束最优化问题:
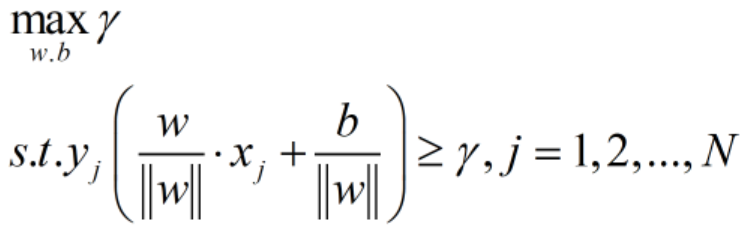
重要问题一:为何会出现第二行中的约束条件?
有了这N个约束条件,好像w,b的可选范围小了很多,跟一开始单纯的最大化几何间隔的任意选w,b有所背离啊?等等,这儿需要注意的是,一开始我们目标是最大化几何间隔,这个几何间隔其实是所有样本点的几何间隔中最小值,而所有样本点的几何间隔有可能是正数(被正确划分),也有可能是负数(被错分)。但是我们一开始讨论最大化几何间隔的时候已经默认平面w,b把训练集T中的所有样本点都正确分类了,只有这样我们才会要求“分隔带最胖”啊,如果有错分的,那分隔带越胖就越不好了。因此满足将所有样本点都正确分类的w,b本来就没多少(限制在一定的范围内了,虽然还是有无数种可能),所以原本我们就要求w,b满足,而且还得要求如下,
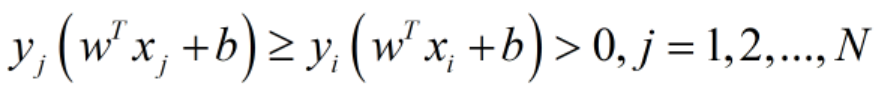 ,以保证之前是离超平面w,b最近点的设定。
,以保证之前是离超平面w,b最近点的设定。
重要问题二:能否对约束最优化问题进行简化?因为目前来看被优化的目标函数γ跟w,b和都有关系,有点不简洁。
解决思路是,对于任意的平面w,b,其实都有无数组参数(λw,λb)λ不为0,都表示该平面。因此我每次选到一个w,b,就相应的知道了最近点(最近点其实是依赖于w,b的,称为支持向量,个人理解也可以称作支持样本点),我都缩放一下w,b,使得函数间隔γ'=1,即:
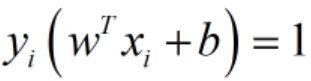 。注意到,缩放w,b前后,其所代表的平面是同一个超平面;而且缩放w,b对于目标函数γ毫无影响,因为其分子分母都是缩放相同的倍数;再者,约束条件的不等号两边都是同时缩放相同的倍数,也无影响。因此,如果我们采用枚举法来求解上述最优化问题(为直观理解,其实是枚举不完的),每次我们随机考察一个平面(w,b),我们都缩放为(w',b')=(λw,λb),使得函数间隔γ'=1,那么我们依旧在考察同一个平面,依旧能算出和缩放前一样的目标函数γ值,依旧符合同样的约束条件。这么处理(特定缩放)有何好处呢?通过这样的处理,我们把约束最优化问题可以转化为如下形式:
。注意到,缩放w,b前后,其所代表的平面是同一个超平面;而且缩放w,b对于目标函数γ毫无影响,因为其分子分母都是缩放相同的倍数;再者,约束条件的不等号两边都是同时缩放相同的倍数,也无影响。因此,如果我们采用枚举法来求解上述最优化问题(为直观理解,其实是枚举不完的),每次我们随机考察一个平面(w,b),我们都缩放为(w',b')=(λw,λb),使得函数间隔γ'=1,那么我们依旧在考察同一个平面,依旧能算出和缩放前一样的目标函数γ值,依旧符合同样的约束条件。这么处理(特定缩放)有何好处呢?通过这样的处理,我们把约束最优化问题可以转化为如下形式:
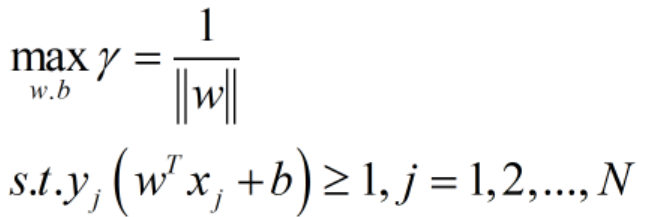
如此形式,简洁明了多了。再者我们可以将max变为min,最大化 与最小化
与最小化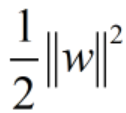 是等价的,就得到了如下线性可分支持向量机学习的最优化问题:
是等价的,就得到了如下线性可分支持向量机学习的最优化问题:

PS:
为加深上述重要问题二的理解,我们可以举一个例子来验证它。
假设有A,B两种w,b的方案,A平面的支持向量(最近点)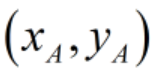 ,B平面的支持向量
,B平面的支持向量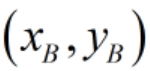 ,我们来比较A,B方案的优劣。
,我们来比较A,B方案的优劣。
1)首先在原始目标函数下,得到两个平面的γ如下:
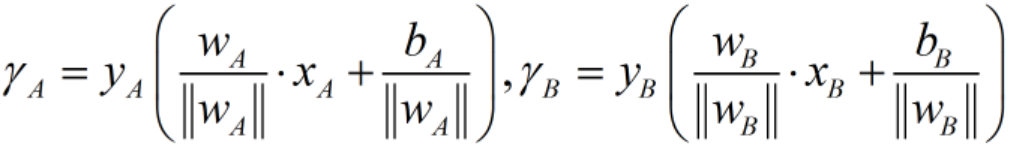
我们假设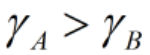 ,那么我们换种思路来比较A方案与B方案,看看结果是否一致。
,那么我们换种思路来比较A方案与B方案,看看结果是否一致。
2)令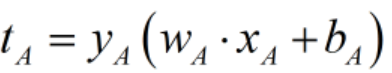 ,注意到在给定平面A的情况下这是一个数(其实就是平面A关于训练集T的函数间隔)。
,注意到在给定平面A的情况下这是一个数(其实就是平面A关于训练集T的函数间隔)。
我们令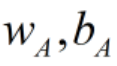 缩放为
缩放为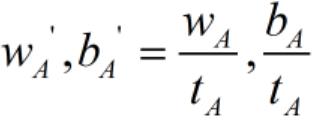 ,则
,则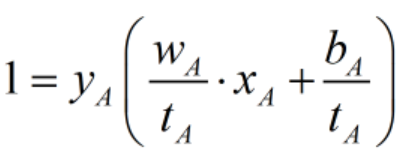 ;
;
同理,对于平面B,我们可以将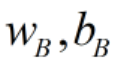 缩放为
缩放为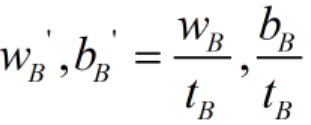 ,则
,则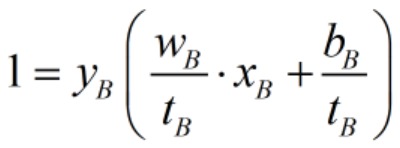 。
。
现在我们通过比较来确定哪个方案更好,是A还是B?
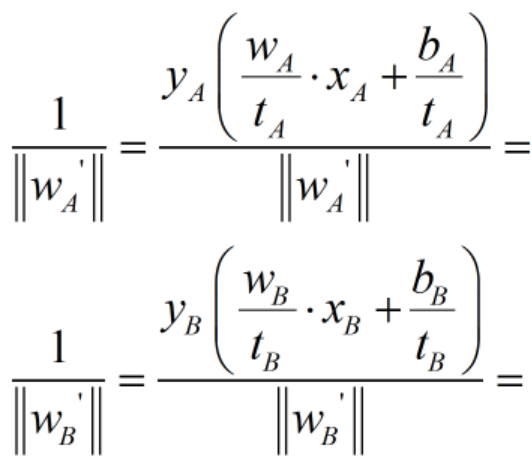
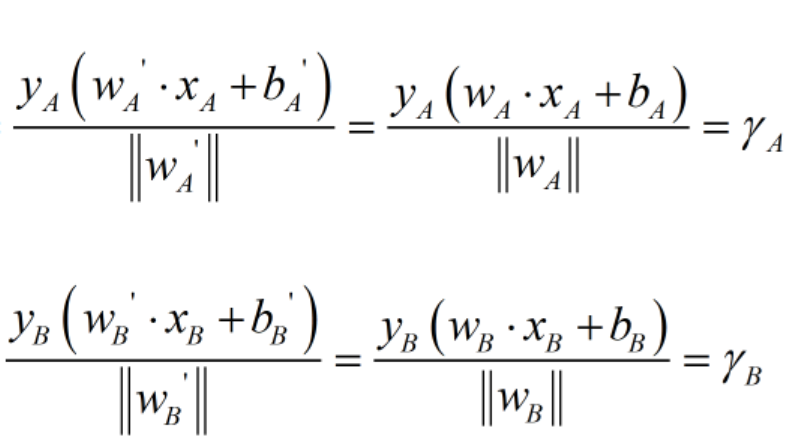
所以我们发现结果是一致的,A优于B,而且目标函数值也与原目标函数值一致。至此,我们验证了准确性,直观感受了w,b缩放前后目标函数值的不变性。
SVM中的间隔最大化的更多相关文章
- SVM中为何间隔边界的值为正负1
在WB二面中,问到让讲一下SVM算法. 我回答的时候,直接答道线性分隔面将样本分为正负两类,取平行于线性切割面的两个面作为间隔边界,分别为:wx+b=1和wx+ b = -1. 面试官就问,为什么是正 ...
- 5. 支持向量机(SVM)软间隔
1. 感知机原理(Perceptron) 2. 感知机(Perceptron)基本形式和对偶形式实现 3. 支持向量机(SVM)拉格朗日对偶性(KKT) 4. 支持向量机(SVM)原理 5. 支持向量 ...
- SVM中的软间隔最大化与硬间隔最大化
参考文献:https://blog.csdn.net/Dominic_S/article/details/83002153 1.硬间隔最大化 对于以上的KKT条件可以看出,对于任意的训练样本总有ai= ...
- SVM 推到期间 遇到的 表背景知识 (间隔最大化)
背景,在看原理的时候,发现很多地方一知半解的,补充如下. 其他补充: 注:以下的默认为2分类 1.SVM原理: (1)输入空间到特征空间得映射 所谓输入空间即是输入样本集合,有部分情况输入空间与特征空 ...
- 线性可分支持向量机与软间隔最大化--SVM(2)
线性可分支持向量机与软间隔最大化--SVM 给定线性可分的数据集 假设输入空间(特征向量)为,输出空间为. 输入 表示实例的特征向量,对应于输入空间的点: 输出 表示示例的类别. 我们说可以通过间隔最 ...
- svm中的数学和算法
支持向量机(Support Vector Machine)是Cortes和Vapnik于1995年首先提出的,它在解决小样本.非线性及高维模式识别中表现出很多特有的优势,并可以推广应用到函数拟合等其它 ...
- 支持向量机(SVM)的推导(线性SVM、软间隔SVM、Kernel Trick)
线性可分支持向量机 给定线性可分的训练数据集,通过间隔最大化或等价地求解相应的凸二次规划问题学习到的分离超平面为 \[w^{\ast }x+b^{\ast }=0\] 以及相应的决策函数 \[f\le ...
- [机器学习]SVM---硬间隔最大化数学原理
注:以下的默认为2分类 1.SVM原理: (1)输入空间到特征空间得映射 所谓输入空间即是输入样本集合,有部分情况输入空间与特征空间是相同得,有一部分情况二者是不同的,而模型定义都是定义到特征空间的, ...
- [机器学习&数据挖掘]SVM---软间隔最大化
根据上个硬间隔最大化已经知道,在解决线性可分数据集的分类问题时,求得拉格朗日乘子.w.b就得到分离超平面,然后就可以进行分类,软间隔最大化是针对非线性可分的数据集,因为并不是数据集在可分的时候会出现一 ...
随机推荐
- java中加密的方式概述
加密是用一种特殊的算法改变原有的数据,使未经授权的用户即使获得了已经加密的信息,但不知其解密的方法,仍然无法了解信息的内容. 大体上分为单向加密和双向加密,双向加密又可分为对称加密和非对称加密 ...
- Android学习——Fragment与Activity通信(一)
学会了在Activity中加载Fragment的方法之后,接下来便需要学习Activity和Fragment之间的通信.这一节先学习如何把Activity中的信息传递给Fragment. 基本过程 在 ...
- tensorflow读取jpg格式图片报错 ValueError: Only know how to handle extensions: ['png']; with Pillow installed matplotlib can handle more images
当运行mpimg.imread("img.jpg")时,spyder 出现如下错误: ValueError: Only know how to handle extensions: ...
- php之Apache压力测试
1,测试本机是否已经安装好Apache ①进入自己的Apache目录下面的bin目录,然后执行ab -V.如果返回Apache版本则表示已经装好 2,执行压力测试命令,ab -n 1000(请求总数) ...
- 构建高性能插件式Web框架
基于MVC插件模式构建支持数据库集群.数据实时同步.数据发布与订阅的Web框架系统.如下图: 1.基于插件式开发 采用插件模式开发的优点是使得系统框架和业务模式有效地进行分离,系统更新也比较简单,只需 ...
- java线程池系列(1)-ThreadPoolExecutor实现原理
前言 做java开发的,一般都避免不了要面对java线程池技术,像tomcat之类的容器天然就支持多线程. 即使是做偏后端技术,如处理一些消息,执行一些计算任务,也经常需要用到线程池技术. 鉴于线程池 ...
- 随机森林算法-Deep Dive
0-写在前面 随机森林,指的是利用多棵树对样本进行训练并预测的一种分类器.该分类器最早由Leo Breiman和Adele Cutler提出.简单来说,是一种bagging的思想,采用bootstra ...
- heidsql(mysql)安装教程和mysql修改密码
简单介绍安装 官网下载:https://mariadb.org/download/ 直接下载(mariadb-10.3.9-winx64.msi):https://github.com/weibang ...
- Android学习笔记_25_多媒体之在线播放器
一.布局文件: <?xml version="1.0" encoding="utf-8"?> <LinearLayout xmlns:andr ...
- insertAdjacentHTML与innerHTML
insertAdjacentHTML:insertAdjacentHTML() 将指定的文本解析为HTML或XML,并将结果节点插入到DOM树中的指定位置.它不会重新解析它正在使用的元素,因此它不会破 ...