Go实现海量日志收集系统(四)
到这一步,我的收集系统就已经完成很大一部分工作,我们重新看一下我们之前画的图:
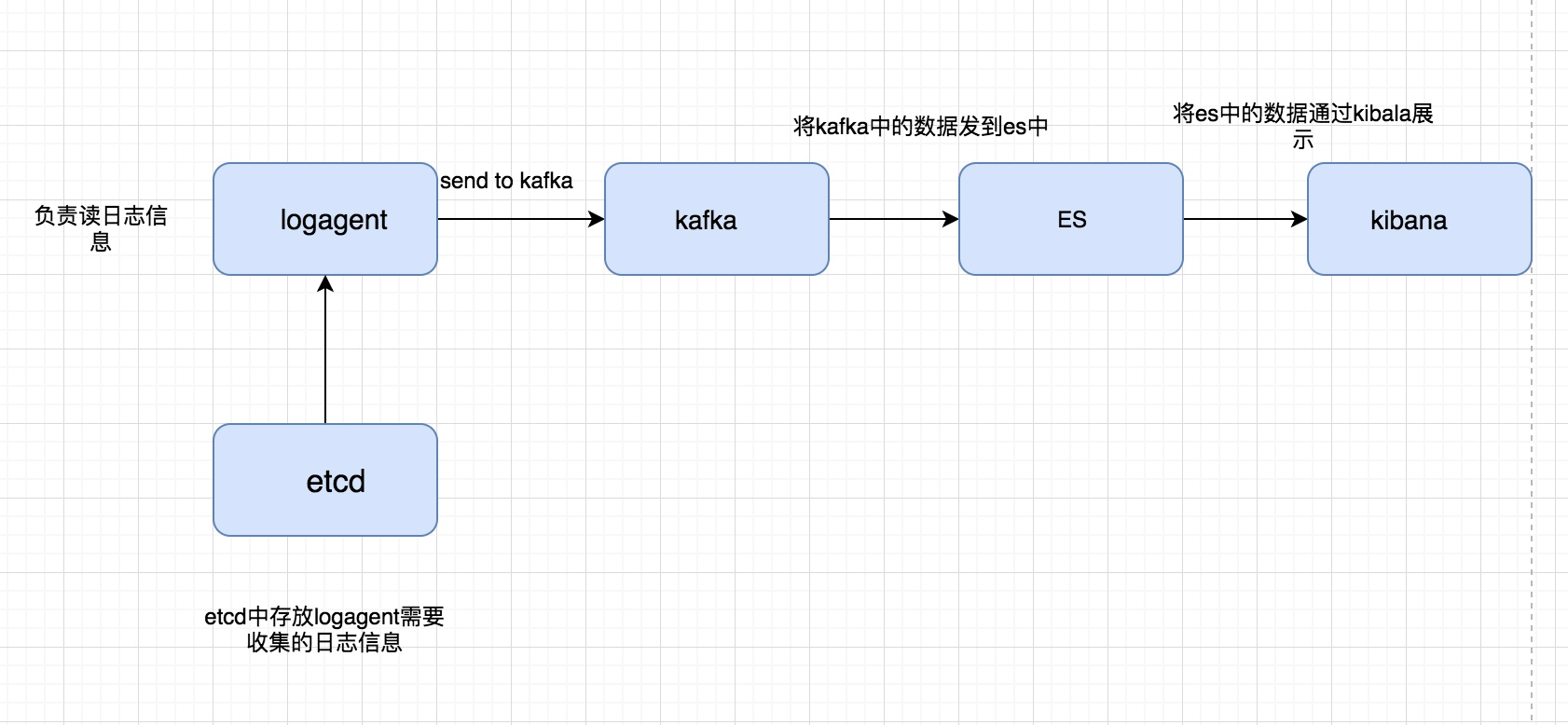
我们已经完成前面的部分,剩下是要完成后半部分,将kafka中的数据扔到ElasticSearch,并且最终通过kibana展现出来
ElasticSearch
官网地址这里介绍了非常详细的安装方法:
https://www.elastic.co/downloads/elasticsearch
但是其实这里是需要配置一些东西的,要不然直接启动是会悲剧的,在网上找了一个地址,如果出现类似的错误直接处理就行,我自己已经验证了:
https://blog.csdn.net/liangzhao_jay/article/details/56840941
如下图所示就表示已经安装完成:


通过go写一个简单的调用ElasticSearch的例子:
package main import (
"fmt"
elastic "gopkg.in/olivere/elastic.v2"
) type Tweet struct{
User string
Message string
} func main(){
client,err := elastic.NewClient(elastic.SetSniff(false),elastic.SetURL("http://192.168.0.118:9200/"))
if err != nil{
fmt.Println("connect es error",err)
return
}
fmt.Println("conn es succ")
tweet := Tweet{User:"olivere name",Message:"Take Five"}
_, err = client.Index().Index("twitter").Type("tweet").Id("1").BodyJson(tweet).Do()
if err != nil {
panic(err)
return
}
fmt.Println("insert succ")
}
logtransfer
logtransfer主要负责从 kafka队列中读取日志信息,并且添加到ElasticSearch中
看那一下logtransfer 目录结构如下:
├── conf
│ └── app.conf
├── es.go
├── etcd.go
├── ip.go
├── kafka.go
├── logs
│ └── transfer.log
└── main.go
conf:存放配置文件
es.go:主要是连接ElasticSearch的部分以及用于将消息放到ElasticSearch中
etcd.go:主要用于做动态的配置更改,当我们需要将kafka中的哪些topic日志内容扔到ElasticSearch中
ip.go: 用于获取当前服务器的ip地址
kafka.go: 主要是kafka的处理逻辑,包括连接kafka以及从kafka中读日志内容
main.go:代码的入口函数
整体大代码框架,通过如图展示:
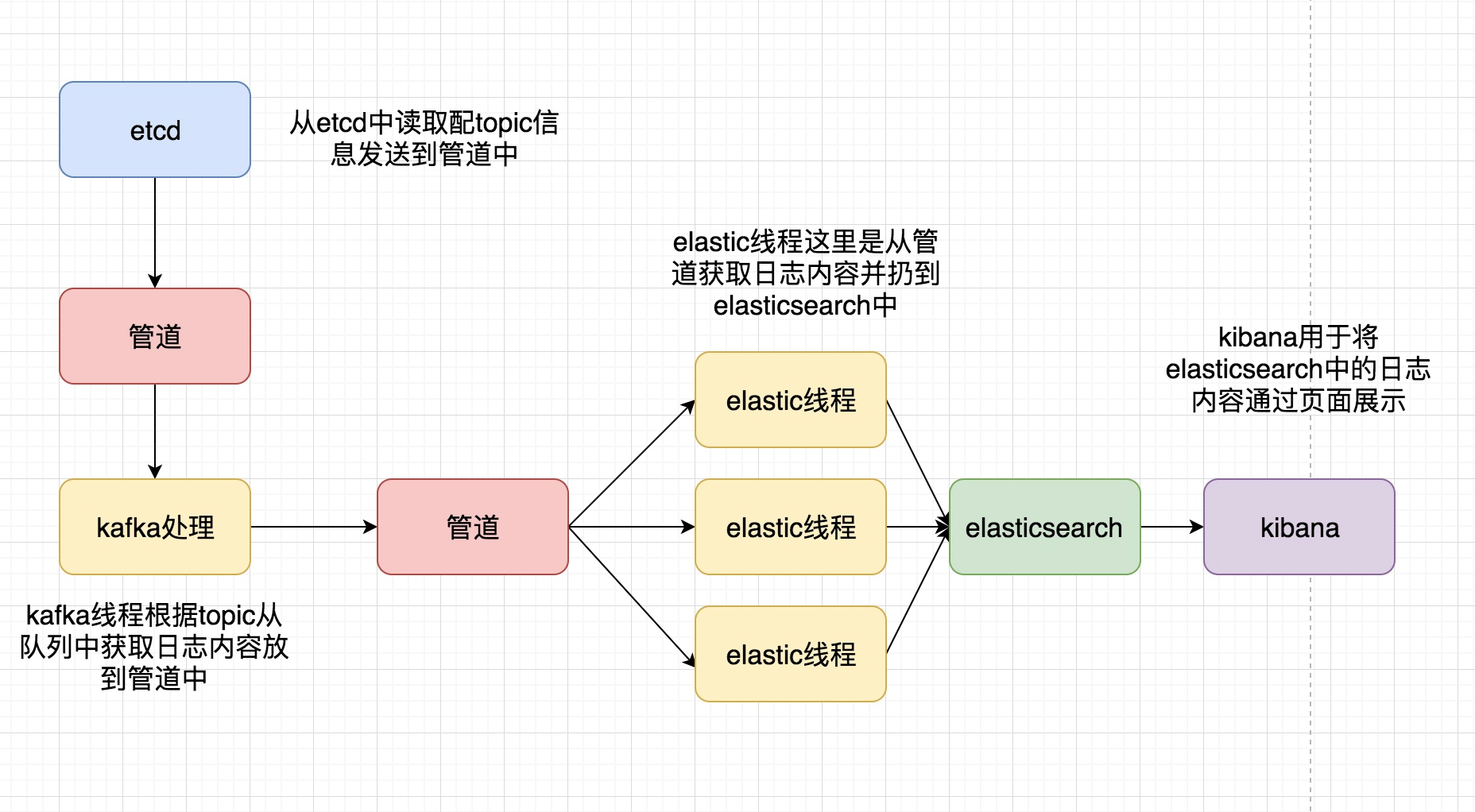
和之前的logagent中的代码有很多启示是可以复用的或者稍作更改,就可以了,其中es之心的,主要是连接ElasticSearch并将日志内容放进去
es.go的代码内容为:
package main import (
"gopkg.in/olivere/elastic.v2"
"github.com/astaxie/beego/logs"
"sync"
"encoding/json"
) var waitGroup sync.WaitGroup var client *elastic.Client func initEs(addr string,) (err error){
client,err = elastic.NewClient(elastic.SetSniff(false),elastic.SetURL(addr))
if err != nil{
logs.Error("connect to es error:%v",err)
return
}
logs.Debug("conn to es success")
return
} func reloadKafka(topicArray []string) {
for _, topic := range topicArray{
kafkaMgr.AddTopic(topic)
}
} func reload(){
//GetLogConf() 从channel中获topic信息,而这部分信息是从etcd放进去的
for conf := range GetLogConf(){
var topicArray []string
err := json.Unmarshal([]byte(conf),&topicArray)
if err != nil {
logs.Error("unmarshal failed,err:%v conf:%v",err,conf)
continue
}
reloadKafka(topicArray)
}
} func Run(esThreadNum int) (err error) {
go reload()
for i:=0;i<esThreadNum;i++{
waitGroup.Add(1)
go sendToEs()
}
waitGroup.Wait()
return
} type EsMessage struct {
Message string
} func sendToEs(){
// 从msgChan中读取日志内容并扔到elasticsearch中
for msg:= range GetMessage() {
var esMsg EsMessage
esMsg.Message = msg.line
_,err := client.Index().Index(msg.topic).Type(msg.topic).BodyJson(esMsg).Do()
if err != nil {
logs.Error("send to es failed,err:%v",err)
continue
}
logs.Debug("send to es success")
}
waitGroup.Done()
}
最终我将logagnet以及logtransfer部署到虚拟机上进行测试的效果是:

这样当我再次查日志的时候就可以不用登陆每台服务器去查日志,只需要通过页面根据关键字迅速看到相关日志,当然目前实现的功能还是有点粗糙,etcd的更改程序,是自己写的发送程序,其实更好的解决方法是通过页面,让用户点来点去,来控制自己要收集哪些日志,以及自己要将哪些topic的日志从kafka中放到ElasticSearch (本人是做后端开发,不擅长前端的开发,不过后面可以试着写个页面试试,估计会很丑哈哈)
同时这里关于各个部分的安装并没有做过多的介绍,以及维护,当然我们的目标是是通过这些开源的软件以及包来实现我们想要的功能,后期的维护,肯定需要对各个组件部分都进行深入了解
这里附赠一下那个etcd客户端代码:
package main import (
"github.com/coreos/etcd/clientv3"
"time"
"fmt"
"golang.org/x/net/context"
) var logconf = `
[
{
"topic":"eslservice_log",
"log_path":"/opt/pbx/log/eslservice.log",
"service":"eslservice",
"send_rate":50000
}
]
` var test111 = `
[
{
"topic":"test_log",
"log_path":"D:/a.log",
"service":"test",
"send_rate":50000
}
]
` var transconf = `
[
"eslservice_log"
]
` func main() {
cli, err := clientv3.New(clientv3.Config{
Endpoints:[]string{"192.168.90.78:2371"},
DialTimeout:5*time.Second,
})
if err != nil {
fmt.Println("connect failed,err:",err)
return
}
fmt.Println("connect success")
defer cli.Close()
ctx,cancel := context.WithTimeout(context.Background(),time.Second)
//_,err = cli.Put(ctx,"/logagent/192.168.90.11/log_config",logconf)
//_,err = cli.Put(ctx,"/logagent/192.168.90.61/log_config",test111)
_, err = cli.Put(ctx,"/logtransfer/192.168.90.11/log_config",transconf)
cancel()
if err != nil {
fmt.Println("put failed ,err:",err)
return
}
ctx,cancel = context.WithTimeout(context.Background(),time.Second)
resp,err := cli.Get(ctx,"/logtransfer/",clientv3.WithPrefix())
cancel()
if err != nil {
fmt.Println("get failed,err:",err)
return
}
for _,ev:=range resp.Kvs{
fmt.Printf("%s:%s\n",ev.Key,ev.Value)
}
}
到目前为止基本的功能都已经实现了,当然了现在的代码结构还有的糙,后面会进行优化!
整个项目中的代码:
logagent代码地址:https://github.com/pythonsite/logagent
logtransfer代码地址:https://github.com/pythonsite/logtransfer
Go实现海量日志收集系统(四)的更多相关文章
- Go实现海量日志收集系统(一)
项目背景 每个系统都有日志,当系统出现问题时,需要通过日志解决问题 当系统机器比较少时,登陆到服务器上查看即可满足 当系统机器规模巨大,登陆到机器上查看几乎不现实 当然即使是机器规模不大,一个系统通常 ...
- Go实现海量日志收集系统(三)
再次整理了一下这个日志收集系统的框,如下图 这次要实现的代码的整体逻辑为: 完整代码地址为: https://github.com/pythonsite/logagent etcd介绍 高可用的分布式 ...
- Go实现海量日志收集系统(二)
一篇文章主要是关于整体架构以及用到的软件的一些介绍,这一篇文章是对各个软件的使用介绍,当然这里主要是关于架构中我们agent的实现用到的内容 关于zookeeper+kafka 我们需要先把两者启动, ...
- Flume -- 开源分布式日志收集系统
Flume是Cloudera提供的一个高可用的.高可靠的开源分布式海量日志收集系统,日志数据可以经过Flume流向需要存储终端目的地.这里的日志是一个统称,泛指文件.操作记录等许多数据. 一.Flum ...
- [转载] 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
原文: http://www.36dsj.com/archives/25042 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要有日志收集系统.消息系统.分布式服务 ...
- 一共81个,开源大数据处理工具汇总(下),包括日志收集系统/集群管理/RPC等
作者:大数据女神-诺蓝(微信公号:dashujunvshen).本文是36大数据专稿,转载必须标明来源36大数据. 接上一部分:一共81个,开源大数据处理工具汇总(上),第二部分主要收集整理的内容主要 ...
- 基于Flume的美团日志收集系统(一)架构和设计
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 基于Flume的美团日志收集系统(一)架构和设计【转】
美团的日志收集系统负责美团的所有业务日志的收集,并分别给Hadoop平台提供离线数据和Storm平台提供实时数据流.美团的日志收集系统基于Flume设计和搭建而成. <基于Flume的美团日志收 ...
- 分布式日志收集系统- Cloudera Flume 介绍
Flume是Cloudera提供的日志收集系统,具有分布式.高可靠.高可用性等特点,对海量日志采集.聚合和传输, Flume支持在日志系统中定制各类数据发送方, 同时,Flume提供对数据进行 ...
随机推荐
- 格式化输出io:format的奇技淫巧
格式化输出io:format是我接触Erlang使用的第一个库函数(io:format("Hello World")),随着学习的深入,它也是我debug优先选择最简单直接的工具. ...
- Python爬虫之urllib模块1
Python爬虫之urllib模块1 本文来自网友投稿.作者PG,一个待毕业待就业二流大学生.玄魂工作室未对该文章内容做任何改变. 因为本人一直对推理悬疑比较感兴趣,所以这次爬取的网站也是平时看一些悬 ...
- Python内置函数(43)——type
英文文档: class type(object) class type(name, bases, dict) With one argument, return the type of an obje ...
- 阿里云API网关(13)请求身份识别:客户端请求签名和服务网关请求签名
网关指南: https://help.aliyun.com/document_detail/29487.html?spm=5176.doc48835.6.550.23Oqbl 网关控制台: https ...
- GIT入门笔记(18)- 标签创建和管理
git tag <name>用于新建一个标签,默认为HEAD,也可以指定一个commit id: git tag -a <tagname> -m "blablabla ...
- GIT入门笔记(20)- git 开发提交代码过程梳理
git开发提交流程新项目开发,可以直接往master上提交老项目维护,可以在分支上修改提交,多次add和commit之后,也可以用pull合并主干和本地master,解决冲突后再push 1.检出代码 ...
- [SHOI2009] 会场预约 - Treap
Description PP大厦有一间空的礼堂,可以为企业或者单位提供会议场地.这些会议中的大多数都需要连续几天的时间(个别的可能只需要一天),不过场地只有一个,所以不同的会议的时间申请不能够冲突.也 ...
- python/MySQL练习题(二)
python/MySQL练习题(二) 查询各科成绩前三名的记录:(不考虑成绩并列情况) select score.sid,score.course_id,score.num,T.first_num,T ...
- Linux:日期用法,及格式定义
在shell脚本中经常会需要获取当前日期的地方,linux的系统时间在shell里是可以直接调用系统变量: 获取今天时期---`date +%Y%m%d` 或 `date +%F` 或 $(date ...
- Java-Maven(八):IDEA使用本地maven,并配置远程中央仓库
声明:已经安装了maven,安装请参考:<Java-Maven(一):Maven的简介与安装> 1)一般我们从github.码云(https://gitee.com)上获取代码后,实际上我 ...