Python爬取腾讯新闻首页所有新闻及评论
前言
这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫。选用Python的Scrapy框架。这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址。
Chrome的开发者工具(或Firefox的web控制台)是个很有用的工具,你可以通过它清楚的看到你在访问一个网站的过程中浏览器发送了哪些信息,接收了哪些信息。而在我们编写爬虫的时候,就需要知道我们需要爬取的内容来自哪里,来自哪个链接。
正文
腾讯新闻首页上的新闻有三种链接格式
一种是:https://news.qq.com/a/time/newsID.htm
如:https://news.qq.com/a/20180414/010445.htm
一种是:http://new.qq.com/omn/time/newsID.html
如:http://new.qq.com/omn/20180415/20180415A0Z5P3.html
一种是:http://new.qq.com/omn/newsID
如:http://new.qq.com/omn/20180414A000MX00
其中:
time:新闻发布日期,第三种新闻链接没有这个值。
newsID:新闻页面的ID,第一种新闻的ID只包含数字,后两种包含数字和字母
这三种格式的新闻链接都能在腾讯新闻首页的源代码中得到,如图:



得到了新闻页面之后,接下来是得到新闻的正文,前面两种新闻的正文及其他信息可以直接在页面的源代码中获得。第三种就比较麻烦了,下文会讲到。另外还要通过新闻页面得到评论页面。
三种格式的新闻的评论页链接的格式是相同的
都为http://coral.qq.com/cmtid
如:http://coral.qq.com/2572597712
其中的cmtid为一串数字,标识每一条新闻的评论页面。我们需要在新闻页面中找到这个值,前面两种新闻比较方便,cmtid以及其他新闻信息都在页面源码中,但是第三种新闻就不同了,页面源码中没有我们想要的东西。
这时候就要使用开发者工具来得到第三种新闻评论页的cmtid以及新闻正文。
在第三种新闻的新闻页面http://new.qq.com/omn/newsid,按F12(或右键->检查)调出开发者工具,点击network,F5快捷键刷新。如图:

然后在找到包含所需要信息的地址。如图:

在Headers栏查看地址,如图:

可以得到第三种新闻的cmtid以及正文信息通过这个地址返回:
http://openapi.inews.qq.com/getQQNewsNormalContent?id=newsid&chlid=news_rss&refer=mobilewwwqqcom&otype=jsonp&ext_data=all&srcfrom=newsapp&callback=getNewsContentOnlyOutput
如:http://openapi.inews.qq.com/getQQNewsNormalContent?id=20180414A000MX00&chlid=news_rss&refer=mobilewwwqqcom&otype=jsonp&ext_data=all&srcfrom=newsapp&callback=getNewsContentOnlyOutput
其中newsid就是新闻的id,我们可以通过这个链接得到cmtid、正文内容。
在得到了新闻的cmtid后,然后就要分析得到评论信息的来源地址了
在评论页http://coral.qq.com/cmtid调出开发者工具,刷新得到返回的信息。如图:

在Headers栏查看地址,如图:
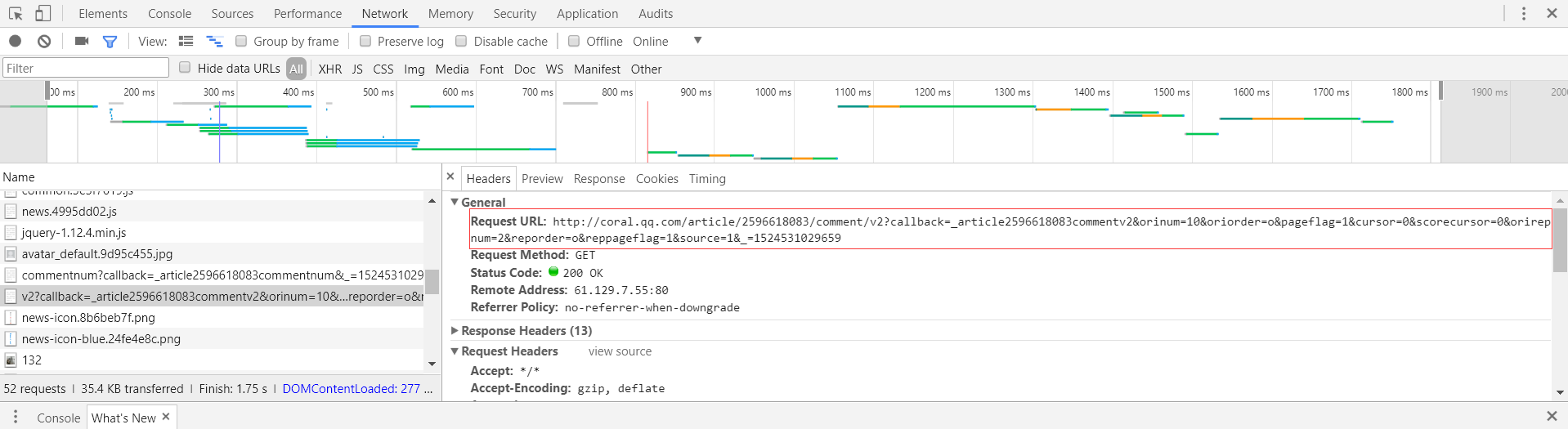
可以得到评论通过下面这个地址返回
http://coral.qq.com/article//comment/v2?callback=_articlecommentv2&:表示评论页ID。
orinum=10:表示返回评论的数目为10,这个值最大为30,也就是一个页面最多返回30个评论。
oriorder=t:表示返回的评论按时间排序 ,o表示按热度排序
orirepnum=2:表示每条评论的回复评论数最多为2,也就是楼中楼最多两层
cursor=0:起始值为0,之后根据返回页面中last的值,得到下一个评论页面。
reporder=t:同oriorder=t。
以上这些值可以根据自己的需求更改,其他的无需更改。其中为了得到所有评论,需要不断更改cursor的值,该值可以通过返回的评论页中last的值更新。
以上就是数据来源地址的获取,接下来就是爬虫的具体实现了。
爬虫的具体实现
该爬虫分为两个模块,模块一是爬取新闻首页所有的新闻,获取所有新闻的正文,新闻id、评论页id等信息。
模块二是根据获取的新闻id、评论页id,逐个爬取每个新闻的所有评论。
模块一的主要代码
# -*- coding: utf-8 -*-
from scrapy.spiders import Spider
from scrapy.http import Request
from scrapy.selector import Selector
from test1.items import NewsItem,ListCombiner
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
import requests
import re
import json
class TencentNewsSpider(CrawlSpider):
name = 'tencent_news_spider'
allowed_domains = ['new.qq.com','news.qq.com']
start_urls = [
'http://news.qq.com'
]
url_pattern1= r'(.*)/a/(\d{8})/(\d+)\.htm'
url_pattern2=r'(.*)/omn/(.+)\.html'
url_pattern3=r'(.*)/omn/([A-Z0-9]{16,19})'
url_pattern4=r'(.*)/omn/(\d{8})/(.+)\.html'
rules = (
Rule(LinkExtractor(allow=(url_pattern1)),'parse_news1'),
Rule(LinkExtractor(allow=(url_pattern2)),'parse_news2'),
Rule(LinkExtractor(allow=(url_pattern3)),'parse_news3'),
)
def parse_news1(self, response):
sel = Selector(response)
print(response.url)
pattern = re.match(self.url_pattern1, str(response.url))
item = NewsItem()
item['source'] = 'tencent'#pattern.group(1)
item['date'] = pattern.group(2)
item['newsId'] = pattern.group(3)
item['cmtId'] = (sel.re(r"cmt_id = (.*);"))[0] # unicode string需要判断有没有cmtId,因为页面有可能为空
item['comments'] = {'link':str('http://coral.qq.com/')+item['cmtId']}
item['contents'] = {'link':str(response.url), 'title':u'', 'passage':u''}
item['contents']['title'] = sel.xpath('//h1/text()').extract()[0]
item['contents']['passage'] = ListCombiner(sel.xpath('//p/text()').extract())
return item
def parse_news2(self,response):
sel = Selector(response)
pattern = re.match(self.url_pattern4, str(response.url))
item=NewsItem()
item['source'] = 'tencent'#pattern.group(1)
item['date'] = pattern.group(2)
item['newsId'] = pattern.group(3)
item['cmtId'] = (sel.re(r"\"comment_id\":\"(\d*)\","))[0]
item['comments'] = {'link':str('http://coral.qq.com/')+item['cmtId']}
item['contents'] = {'link':str(response.url), 'title':u'', 'passage':u''}
item['contents']['title'] = sel.xpath('//h1/text()').extract()[0]
item['contents']['passage'] = ListCombiner(sel.xpath('//p/text()').extract())
return item
def parse_news3(self,response):
item = NewsItem()
print(response.url)
str1='http://openapi.inews.qq.com/getQQNewsNormalContent?id='
str2='&chlid=news_rss&refer=mobilewwwqqcom&otype=jsonp&ext_data=all&srcfrom=newsapp&callback=getNewsContentOnlyOutput'
pattern = re.match(self.url_pattern3, str(response.url))
date=re.search(r"(\d{8})",pattern.group(2))#匹配时间
item['source'] = 'tencent'#pattern.group(1)
item['date'] = date.group(0)
item['newsId'] = pattern.group(2)
print(pattern.group(2))
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
}
out=self.getHTMLText(str1+pattern.group(2)+str2,headers)
g=re.search("getNewsContentOnlyOutput\\((.+)\\)", out)
out=json.loads(g.group(1))
item['cmtId'] =out["cid"]
item['comments'] = {'link':str('http://coral.qq.com/')+item['cmtId']}
item['contents'] = {'link':str(response.url), 'title':u'', 'passage':u''}
item['contents']['title'] = out["title"]
item['contents']['passage'] =out["ext_data"]["cnt_html"]
return item
def getHTMLText(self,url,headers):
try:
r=requests.get(url, headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
print("产生异常")
模块二的主要代码
以下是爬取评论的函数:
# -*- coding: utf-8 -*-
import requests
import re
import json
import codecs
import os
import datetime
# 爬取新闻评论id为commentid,日期为date,新闻id为newsID的所有评论
def crawlcomment(commentid,date,newsID):
url1='http://coral.qq.com/article/'+commentid+'/comment/v2?callback=_articlecommentv2&orinum=30&oriorder=t&pageflag=1&cursor='
url2='&orirepnum=10&_=1522383466213'
# 一定要加头要不然无法访问
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/57.0.2987.133 Safari/537.36'
}
dir=os.getcwd();
comments_file_path=dir+'/docs/tencent/' + date+'/'+newsID+'_comments.json'
news_file = codecs.open(comments_file_path, 'a', 'utf-8')
response=getHTMLText(url1+'+url2,headers)
while 1:
g=re.search("_articlecommentv2\\((.+)\\)", response)
out=json.loads(g.group(1))
if not out["data"]["last"]:
news_file.close()
print("finish!")
break;
for i in out["data"]["oriCommList"]:
time=str(datetime.datetime.fromtimestamp(int(i["time"])))#将unix时间戳转化为正常时间
line = json.dumps(time+':'+i["content"],ensure_ascii=False)+'\n'
news_file.write(line)
print(i["content"])
url=url1+out["data"]["last"]+url2#得到下一个评论页面链接
print(url)
response=getHTMLText(url,headers)
def getHTMLText(url,headers):
try:
r=requests.get(url, headers=headers)
r.raise_for_status()
r.encoding=r.apparent_encoding
return r.text
except:
return "产生异常 "
效果截图
爬取了132条新闻,如图:

新闻正文,如图:

新闻评论,如图:
可到我的github获取所有代码:
https://github.com/Hahallo/CrawlTencentNewsComments
Python爬取腾讯新闻首页所有新闻及评论的更多相关文章
- python爬取博客圆首页文章链接+标题
新人一枚,初来乍到,请多关照 来到博客园,不知道写点啥,那就去瞄一瞄大家都在干什么好了. 使用python 爬取博客园首页文章链接和标题. 首先当然是环境了,爬虫在window10系统下,python ...
- python 爬取腾讯视频的全部评论
一.网址分析 查阅了网上的大部分资料,大概都是通过抓包获取.但是抓包有点麻烦,尝试了F12,也可以获取到评论.以电视剧<在一起>为例子.评论最底端有个查看更多评论猜测过去应该是 Ajax ...
- 爬取腾讯网的热点新闻文章 并进行词频统计(Python爬虫+词频统计)
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:一棵程序树 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
- python 爬取腾讯微博并生成词云
本文以延参法师的腾讯微博为例进行爬取并分析 ,话不多说 直接附上源代码.其中有比较详细的注释. 需要用到的包有 BeautifulSoup WordCloud jieba # coding:utf-8 ...
- Python 爬取腾讯招聘职位详情 2019/12/4有效
我爬取的是Python相关职位,先po上代码,(PS:本人小白,这是跟着B站教学视频学习后,老师留的作业,因为腾讯招聘的网站变动比较大,老师的代码已经无法运行,所以po上),一些想法和过程在后面. f ...
- python爬取快手ios端首页热门视频
最近快手这种小视频app,特别的火,中午吃过午饭,闲来无聊,想搞下快手的短视频,看能不能搞到. 于是乎, 打开了fiddler,开始准备抓包, 设置代理,重启,下一步,查看本机ip 手机打开网络设置 ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- python 爬取腾讯视频评论
import urllib.request import re import urllib.error headers=('user-agent','Mozilla/5.0 (Windows NT 1 ...
- Python爬虫实战:爬取腾讯视频的评论
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者: 易某某 PS:如有需要Python学习资料的小伙伴可以加点击下方链 ...
随机推荐
- ajax 操作
ajax 操作 ajax呢,就是要做到在神不知鬼不觉的情况之下给服务端发送请求. ajax能干啥哩? 这,,,,: 利用AJAX可以做:1.注册时,输入用户名自动检测用户是否已经存在.2.登陆时,提示 ...
- JSON(四)——异步请求中前后端使用Json格式的数据进行交互
json格式的数据广泛应用于异步请求中前后端的数据交互,本文主要介绍几种使用场景和使用方法. 一,json格式字符串 <input type="button" id=&quo ...
- RxJava系列4(过滤操作符)
RxJava系列1(简介) RxJava系列2(基本概念及使用介绍) RxJava系列3(转换操作符) RxJava系列4(过滤操作符) RxJava系列5(组合操作符) RxJava系列6(从微观角 ...
- pthon/零起点(一、集合)
pthon/零起点(一.集合) set( )集合,集合是无序的,集合是可变的,集合是可迭代的 set()强型转成集合数据类型 set()集合本身就是去掉重复的元素 集合更新操作案列: j={1,2,3 ...
- Python/Django(CBV/FBV/ORM操作)
Python/Django(CBV/FBV/ORM操作) CBV:url对应的类(模式) ##====================================CBV操作============ ...
- JavaEE EL & JSTL 学习笔记
1. EL表达式(特别重要)
- Java-NIO(九):管道 (Pipe)
Java NIO 管道是2个线程之间的单向数据连接.Pipe有一个source通道和一个sink通道.数据会被写到sink通道,从source通道读取. 代码使用示例: @Test public vo ...
- Spark:导入数据到oracle
方案一: //overwrite JdbcDialect fitting for Oracle val OracleDialect = new JdbcDialect { override def c ...
- 对scrapy经典框架爬虫原理的理解
1,spider打开某网页,获取到一个或者多个request,经由scrapy engine传送给调度器schedulerrequest特别多并且速度特别快会在scheduler形成请求队列queue ...
- html5之img标签
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...