HashMap中的resize以及死链的情况




假设这里有两个线程同时执行了put()操作,并进入了transfer()环节
while(null != e) {
Entry<K,V> next = e.next; //线程1执行到这里被调度挂起了
e.next = newTable[i];
newTable[i] = e;
e = next;
}那么现在的状态为:
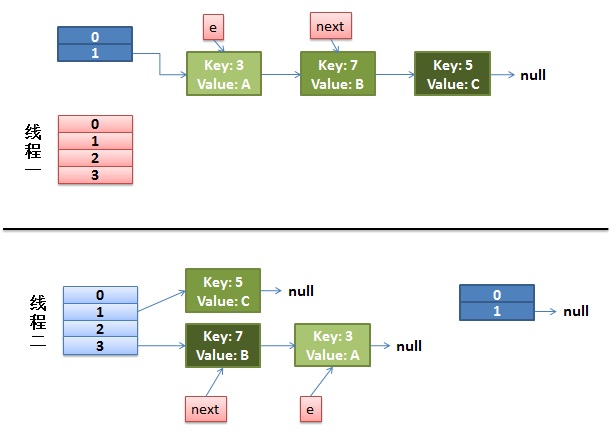
从上面的图我们可以看到,因为线程1的 e 指向了 key(3),而 next 指向了 key(7),在线程2 rehash 后,就指向了线程2 rehash 后的链表。
然后线程1被唤醒了:
- 执行
e.next = newTable[i],于是 key(3)的 next 指向了线程1的新 Hash 表,因为新 Hash 表为空,所以e.next = null, - 执行
newTable[i] = e,所以线程1的新 Hash 表第一个元素指向了线程2新 Hash 表的 key(3)。好了,e 处理完毕。 - 执行
e = next,将 e 指向 next,所以新的 e 是 key(7)
然后该执行 key(3)的 next 节点 key(7)了:
- 现在的 e 节点是 key(7),首先执行
Entry<K,V> next = e.next,那么 next 就是 key(3)了 - 执行
e.next = newTable[i],于是key(7) 的 next 就成了 key(3) - 执行
newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(7) - 执行
e = next,将 e 指向 next,所以新的 e 是 key(3)
这时候的状态图为:
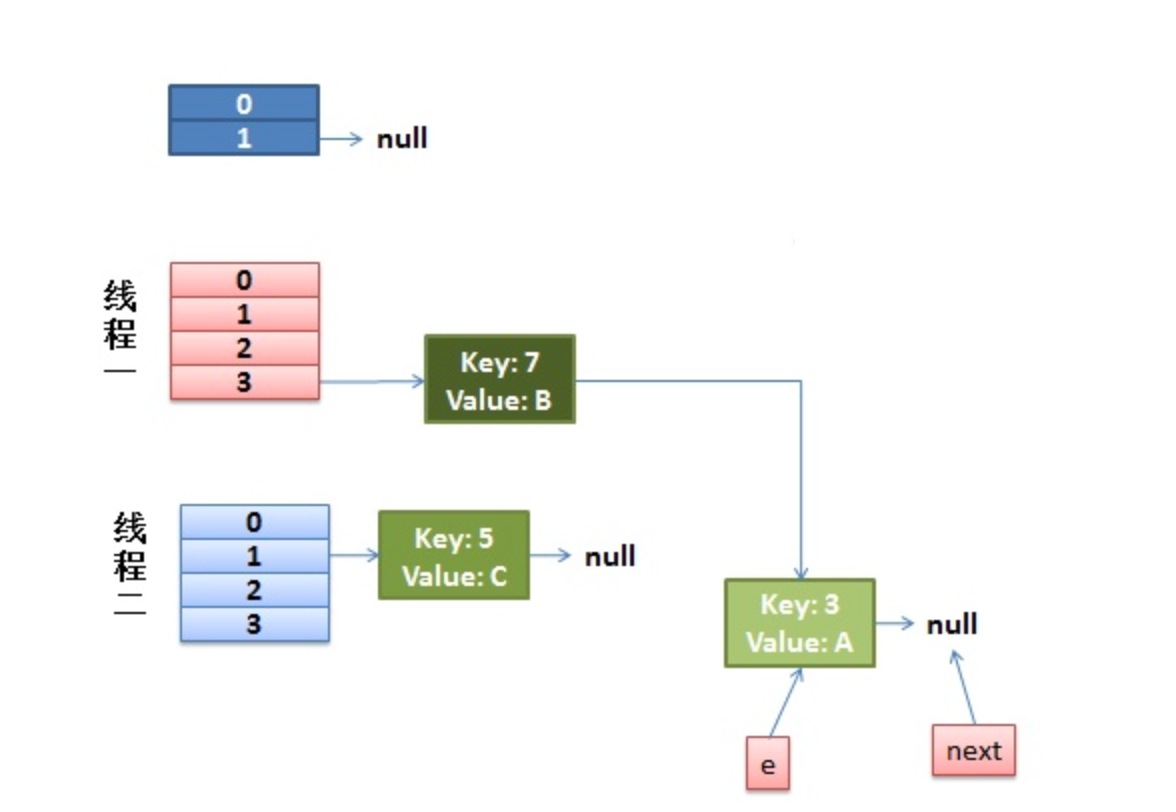
然后又该执行 key(7)的 next 节点 key(3)了:
- 现在的 e 节点是 key(3),首先执行
Entry<K,V> next = e.next,那么 next 就是 null - 执行
e.next = newTable[i],于是key(3) 的 next 就成了 key(7) - 执行
newTable[i] = e,那么线程1的新 Hash 表第一个元素变成了 key(3) - 执行
e = next,将 e 指向 next,所以新的 e 是 key(7)
这时候的状态如图所示:
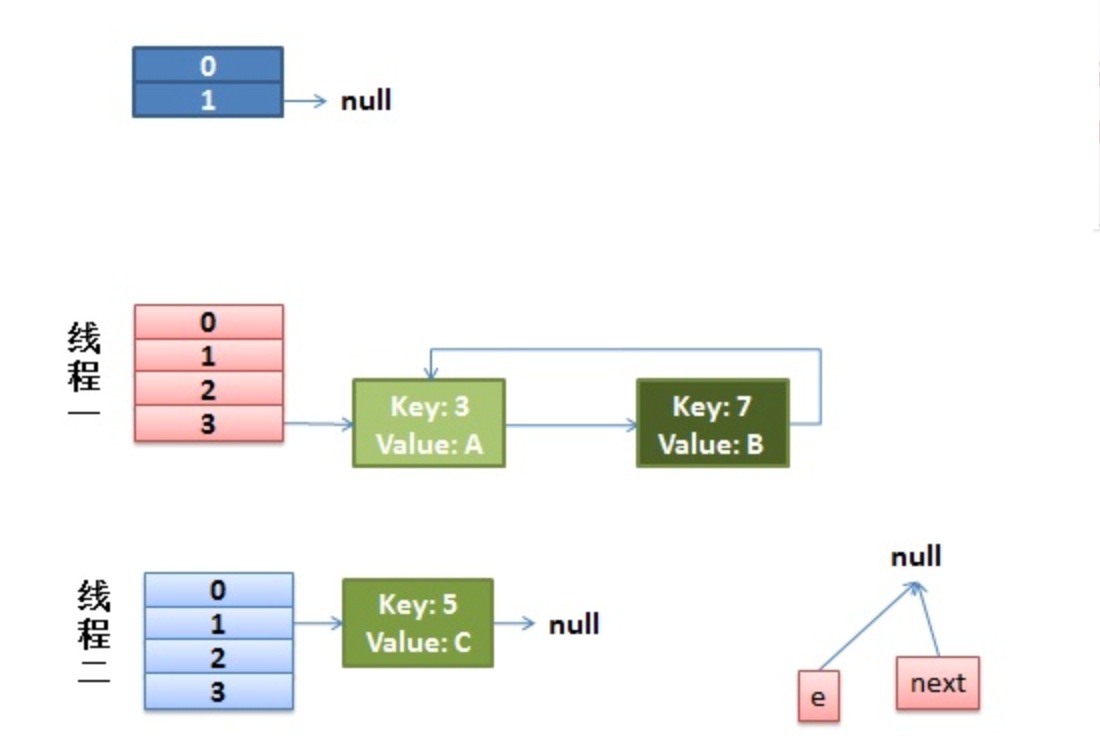
transfer()就完成了,等put()的其余过程搞定后,HashMap 的底层实现就是线程1的新 Hash 表了。HashMap中的resize以及死链的情况的更多相关文章
- Java HashMap中在resize()时候的rehash,即再哈希法的理解
HashMap的扩容机制---resize() 虽然在hashmap的原理里面有这段,但是这个单独拿出来讲rehash或者resize()也是极好的. 什么时候扩容:当向容器添加元素的时候,会判断当前 ...
- Apache下通过shell脚本提交网站404死链
网站运营人员对于死链这个概念一定不陌生,网站的一些数据删除或页面改版等都容易制造死链,影响用户体验不说,过多的死链还会影响到网站的整体权重或排名. 百度站长平台提供的死链提交工具,可将网站存在的死链( ...
- 利用shell脚本批量提交网站404死链给百度
网站运营人员对于死链这个概念一定不陌生,网站的一些数据删除或页面改版等都容易制造死链,影响用户体验不说,过多的死链还会影响到网站的整体权重或排名. 百度站长平台提供的死链提交工具,可将网站存在的死链( ...
- 使用selenium的方式获取网页中图片的链接和网页的链接,来判断是否是死链(二)
上一篇使用Java正则表达式来判断和获取图片的链接以及跳转的网址,这篇使用selenium的自带的API(getAttribute)来获取网页中指定的内容 实现内容:获取下面所有图片的链接地址以及跳转 ...
- java中避免集合死链调用
目录 1. 前言 2. 场景 3. 环境 3.1 开发环境准备 3.2 数据准备 3.2.1 Mysql数据库表及数据 3.2.2 redis库数据 4. 解决方式 5.完整代码 5.1Model 5 ...
- [改善Java代码]减少HashMap中元素的数量
在系统开发中我们经常会使用HashMap作为数据集容器,或者是用缓冲池来处理,一般很稳定,但偶尔也会出现内存溢出的问题(OutOfMemory错误),而且这经常是与HashMap有关的.而且这经常是与 ...
- Java 使用正则表达式取出图片地址以及跳转的链接地址,来判断死链(一)
任务:通过driver的getPageSource()获取网页的源码内容,在把网页中图片链接地址和跳转的url地址进行过滤,在get每个请求,来判断是否是死链 如图: 获取网页源码中所有的href,以 ...
- 【java基础 12】HashMap中是如何形成环形链表的?
导读:经过前面的博客总结,可以知道的是,HashMap是有一个一维数组和一个链表组成,从而得知,在解决冲突问题时,hashmap选择的是链地址法.为什么HashMap会用一个数组这链表组成,当时给出的 ...
- 关于红黑树,在HashMap中是怎么应用的?
关于红黑树,在HashMap中是怎么应用的? 前言 在阅读HashMap源码时,会发现在HashMap中使用了红黑树,所以需要先了解什么是红黑树,以及其原理.从而再进一步阅读HashMap中的链表到红 ...
随机推荐
- 【学习笔记】Hibernate 一对一关联映射 组件映射 二级缓存 集合缓存
啊讲道理放假这十天不到啊 感觉生活中充满了绝望 这就又开学了 好吧好吧继续学习笔记?还是什么的 一对一关联映射 这次我们仍然准备了两个表 一个是用户表Users 一个是档案表Resume 他们的关系是 ...
- Apache服务器安装-apache已经卸载,如何删除注册在系统的服务
cmd进入windows的命令行客户端,执行:sc delete apache 注意:以管理员的身份删除,同理,此方法也可以删除其他类似的服务.例如sc delete MongoDB.
- MysqL主主复制_模式之日志点复制
主主复制即在两台MySQL主机内都可以变更数据,而且另外一台主机也会做出相应的变更,可以起到一定的压力分担等作用. 测试两台虚拟机IP分别为: 192.168.136.131.192.168.136. ...
- JPA实体的常用注解
@Entity 标注于实体类上,通常和@Table是结合使用的,代表是该类是实体类@Table 标注于实体类上,表示该类映射到数据库中的表,没有指定名称的话就表示与数据库中表名为该类的简单类名的表名相 ...
- Kubernetes 使用私服镜像
非常感谢这些无私知识分享的同僚 重要参考:http://blog.csdn.net/u013812710/article/details/52766227 1.首先你得有个私库,这里我用的是阿里云私库 ...
- iOS.Animations.by.Tutorials.v2.0汉化(二)
翻译自:iOS.Animations.by.Tutorials.v2.0 第一节(第1章) 动画属性 现在你已经看到了动画是多么的简单,你可能很想知道你的视图控件是怎么动起来的.本节将给你一个UIVi ...
- 如何将ubuntu控制台输出到串口?
如何将ubuntu控制台输出到串口? Linux使用ubuntu14.04发行版本 操作步骤: 1.修改/etc/default/grub ## Modify this line by leekwen ...
- Microsoft+R:Microsoft R Open (MRO)安装和多核运作
每每以为攀得众山小,可.每每又切实来到起点,大牛们,缓缓脚步来俺笔记葩分享一下吧,please~ --------------------------- 本文转载于公众号大猫的R语言课堂,公众号作者使 ...
- yii学习笔记--快速创建一个项目
下载yii框架 下载地址:http://www.yiiframework.com/ 中文网站:http://www.yiichina.com/ 解压文件
- Caused by: java.sql.SQLException: Parameter index out of range (1 > number of parameters, which is 0
1.错误描述 [ERROR:]2015-05-05 16:35:50,664 [异常拦截] org.hibernate.exception.GenericJDBCException: error ex ...