(1)Deep Learning之感知器
What is deep learning?
在人工智能领域,有一个方法叫机器学习。在机器学习这个方法里,有一类算法叫神经网络。神经网络如下图所示:
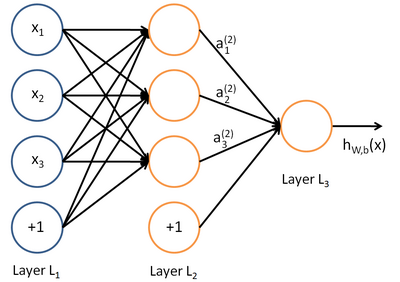
上图中每个圆圈都是一个神经元,每条线表示神经元之间的连接。我们可以看到,上面的神经元被分成了多层,层与层之间的神经元有连接,而层内之间的神经元没有连接。最左边的层叫做输入层,这层负责接收输入数据;最右边的层叫输出层,我们可以从这层获取神经网络输出数据。输入层和输出层之间的层叫做隐藏层。
隐藏层比较多(大于2)的神经网络叫做深度神经网络。而深度学习,就是使用深层架构(比如,深度神经网络)的机器学习方法。
那么深层网络和浅层网络相比有什么优势呢?简单来说深层网络能够表达力更强。事实上,一个仅有一个隐藏层的神经网络就能拟合任何一个函数,但是它需要很多很多的神经元。而深层网络用少得多的神经元就能拟合同样的函数。也就是为了拟合一个函数,要么使用一个浅而宽的网络,要么使用一个深而窄的网络。而后者往往更节约资源。
深层网络也有劣势,就是它不太容易训练。简单的说,你需要大量的数据,很多的技巧才能训练好一个深层网络。这是个手艺活。
感知器
为了理解神经网络,我们应该先理解神经网络的组成单元——神经元。神经元也叫做感知器。感知器算法在上个世纪50-70年代很流行,也成功解决了很多问题。并且,感知器算法也是非常简单的。
感知器的定义
下图是一个感知器:
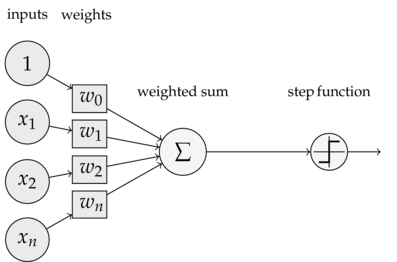
可以看到,一个感知器有如下组成部分:

用一个简单的例子来帮助理解:
例子:用感知器实现and函数
我们设计一个感知器,让它来实现and运算。程序员都知道,and是一个二元函数(带有两个参数和),下面是它的真值表:

为了计算方便,我们用0表示false,用1表示true。这没什么难理解的,对于C语言程序员来说,这是天经地义的。


例子:用感知器实现or函数
同样,我们也可以用感知器来实现or运算。仅仅需要把偏置项b的值设置为-0.3就可以了。我们验算一下,下面是or运算的真值表:


感知器还能做什么
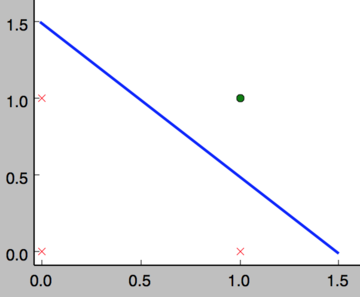
事实上,感知器不仅仅能实现简单的布尔运算。它可以拟合任何的线性函数,任何线性分类或线性回归问题都可以用感知器来解决。前面的布尔运算可以看作是二分类问题,即给定一个输入,输出0(属于分类0)或1(属于分类1)。如下面所示,and运算是一个线性分类问题,即可以用一条直线把分类0(false,红叉表示)和分类1(true,绿点表示)分开。
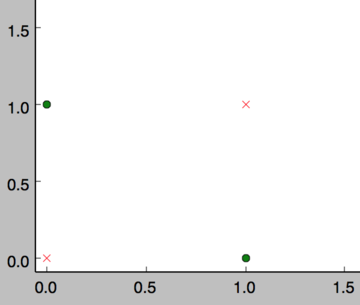
然而,感知器却不能实现异或运算,如下图所示,异或运算不是线性的,你无法用一条直线把分类0和分类1分开。
感知器的训练

每次从训练数据中取出一个样本的输入向量x,使用感知器计算其输出y,再根据上面的规则来调整权重。每处理一个样本就调整一次权重。经过多轮迭代后(即全部的训练数据被反复处理多轮),就可以训练出感知器的权重,使之实现目标函数。
编程实战:实现感知器
完整代码请参考GitHub: https://github.com/hanbt/learn_dl/blob/master/perceptron.py (python2.7)
对于程序员来说,没有什么比亲自动手实现学得更快了,而且,很多时候一行代码抵得上千言万语。接下来我们就将实现一个感知器。
下面是一些说明:
- 使用python语言。python在机器学习领域用的很广泛,而且,写python程序真的很轻松。
- 面向对象编程。面向对象是特别好的管理复杂度的工具,应对复杂问题时,用面向对象设计方法很容易将复杂问题拆解为多个简单问题,从而解救我们的大脑。
- 没有使用numpy。numpy实现了很多基础算法,对于实现机器学习算法来说是个必备的工具。但为了降低读者理解的难度,下面的代码只用到了基本的python(省去您去学习numpy的时间)。
下面是感知器类的实现,非常简单。去掉注释只有27行,而且还包括为了美观(每行不超过60个字符)而增加的很多换行。
class Perceptron(object):
def __init__(self, input_num, activator):
'''
初始化感知器,设置输入参数的个数,以及激活函数。
激活函数的类型为double -> double
'''
self.activator = activator
# 权重向量初始化为0
self.weights = [0.0 for _ in range(input_num)]
# 偏置项初始化为0
self.bias = 0.0
def __str__(self):
'''
打印学习到的权重、偏置项
'''
return 'weights\t:%s\nbias\t:%f\n' % (self.weights, self.bias)
def predict(self, input_vec):
'''
输入向量,输出感知器的计算结果
'''
# 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用map函数计算[x1*w1, x2*w2, x3*w3]
# 最后利用reduce求和
return self.activator(
reduce(lambda a, b: a + b,
map(lambda (x, w): x * w,
zip(input_vec, self.weights))
, 0.0) + self.bias)
def train(self, input_vecs, labels, iteration, rate):
'''
输入训练数据:一组向量、与每个向量对应的label;以及训练轮数、学习率
'''
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate)
def _one_iteration(self, input_vecs, labels, rate):
'''
一次迭代,把所有的训练数据过一遍
'''
# 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...]
# 而每个训练样本是(input_vec, label)
samples = zip(input_vecs, labels)
# 对每个样本,按照感知器规则更新权重
for (input_vec, label) in samples:
# 计算感知器在当前权重下的输出
output = self.predict(input_vec)
# 更新权重
self._update_weights(input_vec, output, label, rate)
def _update_weights(self, input_vec, output, label, rate):
'''
按照感知器规则更新权重
'''
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用感知器规则更新权重
delta = label - output
self.weights = map(
lambda (x, w): w + rate * delta * x,
zip(input_vec, self.weights))
# 更新bias
self.bias += rate * delta
接下来,我们利用这个感知器类去实现and函数。
def f(x):
'''
定义激活函数f
'''
return 1 if x > 0 else 0
def get_training_dataset():
'''
基于and真值表构建训练数据
'''
# 构建训练数据
# 输入向量列表
input_vecs = [[1,1], [0,0], [1,0], [0,1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0
labels = [1, 0, 0, 0]
return input_vecs, labels
def train_and_perceptron():
'''
使用and真值表训练感知器
'''
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perceptron(2, f)
# 训练,迭代10轮, 学习速率为0.1
input_vecs, labels = get_training_dataset()
p.train(input_vecs, labels, 10, 0.1)
#返回训练好的感知器
return p
if __name__ == '__main__':
# 训练and感知器
and_perception = train_and_perceptron()
# 打印训练获得的权重
print and_perception
# 测试
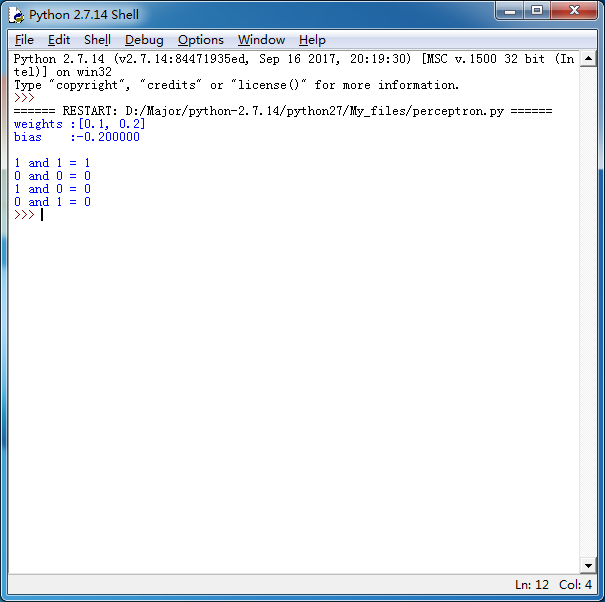
print '1 and 1 = %d' % and_perception.predict([1, 1])
print '0 and 0 = %d' % and_perception.predict([0, 0])
print '1 and 0 = %d' % and_perception.predict([1, 0])
print '0 and 1 = %d' % and_perception.predict([0, 1])
将上述程序保存为perceptron.py文件,通过命令行执行这个程序,其运行结果为:
附完整代码:
#!/usr/bin/env python
# -*- coding: UTF-8 -*- class Perceptron(object):
def __init__(self, input_num, activator):
'''
初始化感知器,设置输入参数的个数,以及激活函数。
激活函数的类型为double -> double
'''
self.activator = activator
# 权重向量初始化为0
self.weights = [0.0 for _ in range(input_num)]
# 偏置项初始化为0
self.bias = 0.0 def __str__(self):
'''
打印学习到的权重、偏置项
'''
return 'weights\t:%s\nbias\t:%f\n' % (self.weights, self.bias) def predict(self, input_vec):
'''
输入向量,输出感知器的计算结果
'''
# 把input_vec[x1,x2,x3...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用map函数计算[x1*w1, x2*w2, x3*w3]
# 最后利用reduce求和
return self.activator(
reduce(lambda a, b: a + b,
map(lambda (x, w): x * w,
zip(input_vec, self.weights))
, 0.0) + self.bias) def train(self, input_vecs, labels, iteration, rate):
'''
输入训练数据:一组向量、与每个向量对应的label;以及训练轮数、学习率
'''
for i in range(iteration):
self._one_iteration(input_vecs, labels, rate) def _one_iteration(self, input_vecs, labels, rate):
'''
一次迭代,把所有的训练数据过一遍
'''
# 把输入和输出打包在一起,成为样本的列表[(input_vec, label), ...]
# 而每个训练样本是(input_vec, label)
samples = zip(input_vecs, labels)
# 对每个样本,按照感知器规则更新权重
for (input_vec, label) in samples:
# 计算感知器在当前权重下的输出
output = self.predict(input_vec)
# 更新权重
self._update_weights(input_vec, output, label, rate) def _update_weights(self, input_vec, output, label, rate):
'''
按照感知器规则更新权重
'''
# 把input_vec[x1,x2,x3,...]和weights[w1,w2,w3,...]打包在一起
# 变成[(x1,w1),(x2,w2),(x3,w3),...]
# 然后利用感知器规则更新权重
delta = label - output
self.weights = map(
lambda (x, w): w + rate * delta * x,
zip(input_vec, self.weights))
# 更新bias
self.bias += rate * delta def f(x):
'''
定义激活函数f
'''
return 1 if x > 0 else 0 def get_training_dataset():
'''
基于and真值表构建训练数据
'''
# 构建训练数据
# 输入向量列表
input_vecs = [[1,1], [0,0], [1,0], [0,1]]
# 期望的输出列表,注意要与输入一一对应
# [1,1] -> 1, [0,0] -> 0, [1,0] -> 0, [0,1] -> 0
labels = [1, 0, 0, 0]
return input_vecs, labels def train_and_perceptron():
'''
使用and真值表训练感知器
'''
# 创建感知器,输入参数个数为2(因为and是二元函数),激活函数为f
p = Perceptron(2, f)
# 训练,迭代10轮, 学习速率为0.1
input_vecs, labels = get_training_dataset()
p.train(input_vecs, labels, 10, 0.1)
#返回训练好的感知器
return p if __name__ == '__main__':
# 训练and感知器
and_perception = train_and_perceptron()
# 打印训练获得的权重
print and_perception
# 测试
print '1 and 1 = %d' % and_perception.predict([1, 1])
print '0 and 0 = %d' % and_perception.predict([0, 0])
print '1 and 0 = %d' % and_perception.predict([1, 0])
print '0 and 1 = %d' % and_perception.predict([0, 1])
(1)Deep Learning之感知器的更多相关文章
- 机器学习(Machine Learning)&深度学习(Deep Learning)资料
机器学习(Machine Learning)&深度学习(Deep Learning)资料 機器學習.深度學習方面不錯的資料,轉載. 原作:https://github.com/ty4z2008 ...
- Deep Learning模型之:CNN卷积神经网络(一)深度解析CNN
http://m.blog.csdn.net/blog/wu010555688/24487301 本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep le ...
- Deep Learning(深度学习)学习笔记整理(二)
本文整理了网上几位大牛的博客,详细地讲解了CNN的基础结构与核心思想,欢迎交流. [1]Deep learning简介 [2]Deep Learning训练过程 [3]Deep Learning模型之 ...
- Deep Learning(深度学习)学习笔记整理
申明:本文非笔者原创,原文转载自:http://www.sigvc.org/bbs/thread-2187-1-3.html 4.2.初级(浅层)特征表示 既然像素级的特征表示方法没有作用,那怎样的表 ...
- Deep Learning 深度学习 学习教程网站集锦
http://blog.sciencenet.cn/blog-517721-852551.html 学习笔记:深度学习是机器学习的突破 2006-2007年,加拿大多伦多大学教授.机器学习领域的泰斗G ...
- Deep Learning 深度学习 学习教程网站集锦(转)
http://blog.sciencenet.cn/blog-517721-852551.html 学习笔记:深度学习是机器学习的突破 2006-2007年,加拿大多伦多大学教授.机器学习领域的泰斗G ...
- 【转载】Deep Learning(深度学习)学习笔记整理
http://blog.csdn.net/zouxy09/article/details/8775360 一.概述 Artificial Intelligence,也就是人工智能,就像长生不老和星际漫 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
- Deep Learning(深度学习)学习笔记整理系列之(七)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
随机推荐
- NOI2009 二叉查找树 【区间dp】
[NOI2009]二叉查找树 [问题描述] 已知一棵特殊的二叉查找树.根据定义,该二叉查找树中每个结点的数据值都比它左子树结点的数据值大,而比它右子树结点的数据值小.另一方面,这棵查找树中每个结点都有 ...
- 阿里云ECS服务器上搭建keepalived+mha+mysql5.6+gtid+一主两从+脚本判断架构踩的坑
最近,公司项目搭建了一套后端数据库架构,不是在RDS,是在阿里云的ECS服务器上搭建keepalived.mha.mysql5.6.gtid.一主两从架构,目前还没有实现读写分离,以后架构升级,可能代 ...
- Mock拦截ajax请求
//mock拦截ajax请求 ,生成随机数据Mock.mock('./servlet/UserServlet?method=getUser',{ 'list|1-5':[{ 'username':'@ ...
- 机器学习03:K近邻算法
本文来自同步博客. P.S. 不知道怎么显示数学公式以及排版文章.所以如果觉得文章下面格式乱的话请自行跳转到上述链接.后续我将不再对数学公式进行截图,毕竟行内公式截图的话排版会很乱.看原博客地址会有更 ...
- 对于 @Autowired注解和@service注解的理解
@Autowired相当于Spring自动给你进行了new一个对象将这个对象放入你的注解所在类里面. @service 是可以让IOC容器对于你注解的类可以在容器中生成相应的bean实例 便于我们进行 ...
- java5 - 数组与排序算法
数组是什么? 一.一维数组 1 声明与定义的区别 一般的情况下我们常常这样叙述, 把建立空间的声明称之为"定义", 而把不需要建立存储空间称之为"声明". 很明 ...
- Zookeeper笔记3——原理及其安装使用
Zookeeper到底能干什么? 1.配置管理:这个好理解.分布式系统都有好多机器,Zookeeper提供了这样的一种服务:一种集中管理配置的方法,我们在这个集中的地方修改了配置,所有对这个配置感兴趣 ...
- Eclipse远程调试hadoop源码
1. 修改对应调试端口 之前的一篇blog里讲述了hadoop单机版调试的方法,那种调试只限于单机运行hadoop命令而已,对于运行整个hadoop环境而言是不可取的,因为hadoop会开启多个jav ...
- Jmeter MD5插件
实际业务中,会要求 HTTP 协议中附加 MD5 校验字段, 防止请求参数被恶意篡改, 对于开发同学来说, 这是个很简单的需求. 但是给自动化测试增加了难度, Jmeter 原生不支持这个功能,应测试 ...
- RISC_CPU
采用Top-Down设计方法,深入理解CPU的运作原理,本文参照夏宇闻老师的<Verilog 数字系统设计教程>,并做了相应的修改.仿真工具采用Mentor公司的ModelSim. 1.C ...