Python进阶6---序列化与反序列化
序列化与反序列化***
为什么要序列化 ?

定义

pickle库

#序列化实例
import pickle
lst = 'a b c'.split()
with open('test.txt','wb+')as f:
pickle.dump(lst,f) file = 'test.txt'
with open(file,'wb')as f:
s1 = 99
s2 = 'abc'
s3 = ['a','b',['c','d']] pickle.dump(s1,f)
pickle.dump(s2,f)
pickle.dump(s3,f) with open(file,'rb') as f:
s=[]
for i in range(3):
s.append(pickle.load(f))
print(s)
#对象序列化1
import pickle class AA:
ttt = 'ABC'
def show(self):
print('abc') a1 = AA()
sr = pickle.dumps(a1)
print('sr={}'.format(sr))#AA a2 = pickle.loads(sr)
print(a2.ttt)
a2.show()
#上面的例子中,其实就保存了一个类名,因为所有的其他东西都是类定义的东西,是不变的,
#所以序列化只序列化了一个AA类名。反序列化的时候找到类就可以恢复一个对象。
#对象序列化2
import pickle
class AAA:
def __init__(self):
self.tttt = 'abc' b1 = AAA()
sr = pickle.dumps(b1)
print('sr={}'.format(sr)) #AAA b2 = pickle.loads(sr)
print(b2.tttt) #可以看出这回保存了AAA,tttt和abc,因为这才是每一个对象每次都变化的。但是,反序列化的时候要找到AAA类的定义,才能成功。否则会就会抛出异常。
#可以这样理解:反序列化的时候,类是模子,二进制序列就是铁水。
应用
本地序列化的情况,情况较少。
一般来说,大多数情况都应用在网络中。将数据序列化后通过网络传输到远程节点,远程服务器上的服务将接收到的数据反序列化后,就可以使用了。
但是,要注意一点,远程接收端,反序列化时必须有对应的数据类型,否则就会报错。尤其是自定义类,必须远程得有。
#实验
import pickle
class AAA:
def __init__(self):
self.tttt = 'abc' aaa = AAA()
sr = pickle.dumps(aaa)
print(sr)
print(len(sr)) file = 'text.txt'
with open(file,'wb')as f:
pickle.dump(aaa,f)
#将生产的序列化发送到其他节点运行
with open('text1.txt','rb')as f:
a = pickle.load(f) #解决办法
'''
现在,大多数项目,都不是单机的,也不是单服务的。需要通过网络将数据传送到其他节点上去,这就需要大量的
序列化、反序列化。但是,问题是,Python程序之间还可以都是用pickle解决序列化、反序列化,如果是跨平台、
跨语言、跨协议pickle就不太合适了,就需要公共的协议。例如XML、Json、Protocol Buffer等。
不同协议,效率不同,学习曲线不同,适用不同场景,要根据不同的情况分析选型。
'''
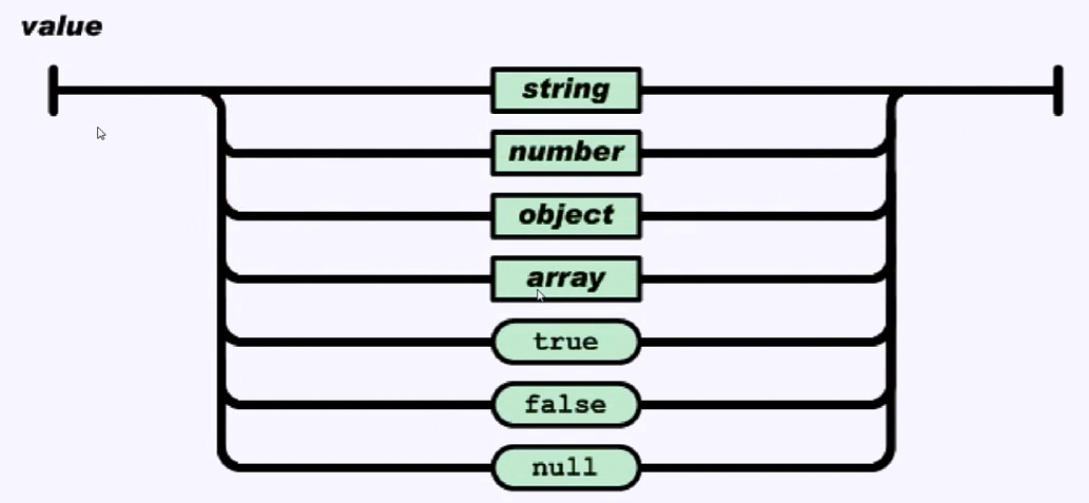
Json

Json的数据类型



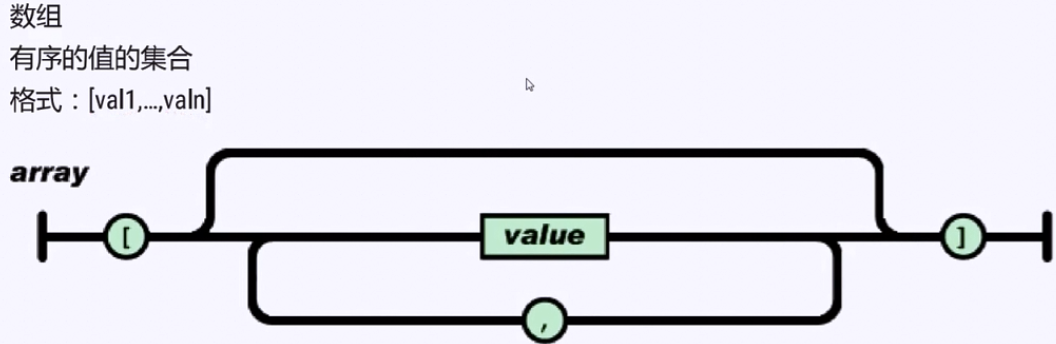
实例
{
"person": [
{
"name": "tom",
"age": 18
},
{
"name": "cy",
"age": ""
}
],
"total": 2
}
json模块
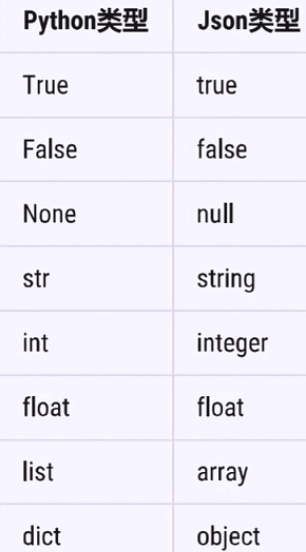
Python与Json
Python支持少量内建数据类型到Json类型的转换
常用方法
dumps json编码
dump json编码并存入文件
loads json解码
load dump解码,从文件读取数据
import json
d = {'name':'chengyu','age':20,'interest':['music','movie']}
j = json.dumps(d)#传入一个对象,return JSONEncoder
print(j) d1 = json.loads(j)
print(d1) 注意:一般json编码的数据很少落地,数据都是通过网络传输。传输的时候,要考虑压缩它。
本质上来说它就是个文本,就是个字符串。json很简单,几乎所有语言编程都支持json,因而应用范围很广。
MessagePack(第三方库)
安装
pip install msgpack-python

常用方法

#示例:
import msgpack
import json
d ={'person':[{'name':'tom','age':18},{'name':'cheng','age':23}],'total':2}
a = json.dumps(d)
print("json格式:{},{}".format(len(a),a))
b = msgpack.packb(d)
print("magpack格式:{},{}".format(len(b),b)) d1 = msgpack.unpackb(b)
print(d1)
d1 = msgpack.unpackb(b,encoding='utf-8')
print(d1) 注意:MessagePack简单易用,高效压缩,支持语言丰富。
所以,用它序列化也是一个不错的选择。
作页:

argparse模块
参数分类

基本解析
先来一段最简单的程序
import argparse
parser = argparse.ArgumentParser() #获得一个参数解析器
args = parser.parse_args() #分析参数
parser.print_help() #打印帮助
#运行结果
#python test.py -h
usage:test.py [-h]
optional arguments:
-h, --help show this help message and exit argparse不仅仅做了参数的定义和解析,还自动帮助生成了帮助信息。尤其是usage,可以看到现在定义的参数是不是自己想要的
参数解析器ArgumentParser的参数

位置参数解析

import argparse
parser = argparse.ArgumentParser(prog='ls',add_help=True,description='list directory contents') #获得一个参数解析器
parser.add_argument('path')#位置参数 args = parser.parse_args() #分析参数
parser.print_help() #打印帮助
print('*'*10,args)
#运行结果:
'''
usage: ls [-h] path
ls: error: the following arguments are required: path
'''
'''
程序等定义为:
ls [-h] path
-h为帮助,可有可无
path为位置参数,必须提供
'''
传参

import argparse
parser = argparse.ArgumentParser(prog='ls',add_help=True,description='list directory contents') #获得一个参数解析器
parser.add_argument('path')#位置参数 args = parser.parse_args(('/etc',)) #分析参数,同时传入可迭代的参数
parser.print_help() #打印帮助
print('*'*3,args) #打印名词空间中收集的参数
#运行结果:
'''
usage: ls [-h] path
list directory contents positional arguments:
path optional arguments:
-h, --help show this help message and exit
*** Namespace(path='/etc')
'''
#注意:Namespace(path='/etc')里面的path可以通过Namespace对象访问,例如args.path
非必须位置参数

#改进1
import argparse #获取一个参数解析器
parser = argparse.ArgumentParser(prog='ls',add_help=True,description='list directory contents')
parser.add_argument('path',nargs='?',default='.',help='path help')#位置参数,可有可无,缺省值,帮助 args = parser.parse_args()#分析参数,同时传入可迭代的参数
print(args) #打印名词空间中收集的参数
parser.print_help()#打印帮助
'''#运行结果
Namespace(path='path')
usage: ls [-h] [path]
list directory contents positional arguments:
path path help optional arguments:
-h, --help show this help message and exit
'''

选项参数
-l的实现

-a的实现

#改进2
import argparse #获取一个参数解析器
parser = argparse.ArgumentParser(prog='ls',add_help=True,description='list directory contents')
parser.add_argument('path',nargs='?',default='.',help='path help')#位置参数,可有可无,缺省值,帮助
parser.add_argument('-l',action='store_true',help='use a long listing format')
parser.add_argument('-a','--all',action='store_true',help='show all files,do not ignore entries starting with .') args = parser.parse_args()#分析参数,同时传入可迭代的参数
print(args)
parser.print_help() '''运行结果:
Namespace(all=False, l=False, path='path')
usage: ls [-h] [-l] [-a] [path]
list directory contents positional arguments:
path path help optional arguments:
-h, --help show this help message and exit
-l use a long listing format
-a, --all show all files,do not ignore entries starting with .
''' #parser.parse_args('-l -a /tmp'.split())语句的运行结果如下:
#Namespace(all=True, l=True, path='/tmp')
ls业务功能的实现

#最终版
import argparse
from pathlib import Path
from datetime import datetime
import stat # print(args)#d打印名词空间中收集的参数
# parser.print_help()#打印帮助 #获取文件类型
def _getfiletype(f:Path):
if f.is_dir():
return 'd'
elif f.is_block_device():
return 'b'
elif f.is_char_device():
return 'c'
elif f.is_socket():
return 's'
elif f.is_symlink():
return 'l'
else:
return '-' modelist = ['r', 'w', 'x', 'r', 'w', 'x', 'r', 'w', 'x']
def _getmodestr(mode:int):
m = int(mode) & 0o777
print(mode,m,bin(m))
mstr =''
# for i,v in enumerate(bin(m)[-9:]):
# if v == '1':
# mstr += modelist[i]
# else:
# mstr += '-'
for i in range(8,-1,-1):
if m >>i & 1:
mstr += modelist[8-i]
else:
mstr += '-'
return mstr #目标:-rw-rw-r-- 1 python python 5 Oct 25 00:07 test4
#return (mode,st.st_uid,st.st_gid,size,atime,file.name)
def list_dir(path,all=False,detail=False,human=False): #return "{}{}".format(size, units[depth] 即换算后的文件大小
units = ['', 'K', 'M', 'G', 'T', 'P'] # ' KMGTP'
def _gethuman(size: int):
depth = 0
while size >= 1000:
size = size // 1000
depth += 1 return "{}{}".format(size, units[depth]) #yield (mode,st.st_uid,st.st_gid,size,atime,file.name)
def _showdir(path='',all=False,detail=False,human=False):
'''列出本文件目录'''
p = Path(path)
for file in p.iterdir():
if not all and str(file.name).startswith('.'):#不显示隐藏文件
continue
if not detail:
yield (file.name,)
else:
#mode 硬链接 属主 属组 字节 时间 name
st = file.stat()
#调用内部函数stat.filemode,功能等同于自定义getfiletype函数
mode = stat.filemode(st.st_mode)
size = str(st.st_size)
if human:
size = _gethuman(st.st_size)
atime = datetime.fromtimestamp(st.st_atime).strftime('%Y-%m-%d %H:%M:%S')
yield (mode,st.st_nlink,st.st_uid,st.st_gid,size,atime,file.name) yield from sorted(_showdir(args.path,args.all,args.l,args.s),key=lambda x:x[-1])#等同于下面语句
# for x in sorted(_showdir(args.path,args.all,args.l,args.human),key=lambda x:x[-1]):
# yield x
#获取一个参数解析器
parser = argparse.ArgumentParser(prog='ls',add_help=True,description='list directory contents')
parser.add_argument('path',nargs='?',default='.',help='path help')#位置参数,可有可无,缺省值,帮助
parser.add_argument('-l',action='store_true',help='use a long listing format')
parser.add_argument('--all','-a',action='store_true',help='show all files,do not ignore entries ')
parser.add_argument('-s',action='store_true') if __name__ == '__main__':
args = parser.parse_args() # 分析参数,同时传入可迭代的参数
parser.print_help()
print('*'*10,args)
for st in list_dir(args.path,args.all,args.s,args.l):
print(st)
其他的完善


Python进阶6---序列化与反序列化的更多相关文章
- python类库32[序列化和反序列化之pickle]
一 pickle pickle模块用来实现python对象的序列化和反序列化.通常地pickle将python对象序列化为二进制流或文件. python对象与文件之间的序列化和反序列化: pi ...
- Python库:序列化和反序列化模块pickle介绍
1 前言 在“通过简单示例来理解什么是机器学习”这篇文章里提到了pickle库的使用,本文来做进一步的阐述. 通过简单示例来理解什么是机器学习 pickle是python语言的一个标准模块,安装pyt ...
- Python开发之序列化与反序列化:pickle、json模块使用详解
1 引言 在日常开发中,所有的对象都是存储在内存当中,尤其是像python这样的坚持一切接对象的高级程序设计语言,一旦关机,在写在内存中的数据都将不复存在.另一方面,存储在内存够中的对象由于编程语言. ...
- 模块讲解----pickle模块(只在python用的序列化与反序列化)
特点 1.只能在python中使用,只支持python的基本数据类型. 2.可以处理复杂的序列化语法.(例如自定义的类的方法,游戏的存档等) 3.序列化的时候,只是序列化了整个序列对象,而不是内存地址 ...
- python marshal 对象序列化和反序列化
有时候,要把内存中的一个对象持久化保存到磁盘上,或者序列化成二进制流通过网络发送到远程主机上.Python中有很多模块提供了序列化与反序列化的功能,如:marshal, pickle, cPickle ...
- python接口测试之序列化与反序列化(四)
在python中,序列化可以理解为:把python的对象编码转换为json格式的字符串,反序列化可以理解为:把json格式 字符串解码为python数据对象.在python的标准库中,专门提供了jso ...
- python中的序列化和反序列化
~~~~~~滴滴,,什么是序列呢?可以理解为序列就是字符串.序列化的应用 写文件(数据传输) 网络传输 序列化和反序列化的概念 序列化模块:将原本的字典.列表等内容转换成一个字符串的过程就叫做序列 ...
- Python实现JSON序列化和反序列化
在我的应用中,序列化就是把类转成符合JSON格式的字符串,反序列化就是把JSON格式的字符串转换成类.C#的话直接用Newtonsoft.JSON就可以了,非常好用.本来以为python也会有类似的库 ...
- python处理JSON 序列化与反序列化
#序列化 >>> import json>>> d={"key":"value"}>>> d{'key': ...
- 【Python】Json序列化和反序列化模块dumps、loads、dump、load函数介绍
1.json.dumps() json.dumps()用于将dict类型的数据转成str,因为如果直接将dict类型的数据写入json文件中会发生报错,因此在将数据写入时需要用到该函数. 转换案例: ...
随机推荐
- 禁用 Chrome 的黑色模式/Dark Mode
macOS Mojave 中引入了系统层面的黑色模式,Chrome 73 在应用中支行了这一模式,即系统设置为黑色模式时,Chrome 会自动适应切换到 Dark Mode. Chrome 跟随系统设 ...
- MySQL在CenterOS和Ubuntu的安装
声明:作者原创,转载注明出处. 作者:帅气陈吃苹果 下载地址:https://dev.mysql.com/get/Downloads/MySQL-5.7/mysql-5.7.20-linux-glib ...
- java~modelMapper需要注意的几点
对于modelMapper来说,主要实现的是对象与对象的赋值,在这微服务里的数据传输对象中用的比较多,DTO这个对象是从业务模型抽象出来的,满足某一种业务,它与数据持久化模型没有关系,而如果我们把数据 ...
- Jvm垃圾回收器(终结篇)
知识回顾: 第一篇<Jvm垃圾回收器(基础篇)>主要讲述了判断对象的生死?两种基础判断对象生死的算法.引用计数法.可达性分析算法,方法区的回收.在第二篇<Jvm垃圾回收器(算法篇)& ...
- element-ui 动态换肤
1.在安装好 element-ui@2.x 以后,首先安装sass-loader npm i sass-loader node-sass -D 2.安装 element-theme npm i ele ...
- SLAM+语音机器人DIY系列:(三)感知与大脑——1.ydlidar-x4激光雷达
摘要 在我的想象中机器人首先应该能自由的走来走去,然后应该能流利的与主人对话.朝着这个理想,我准备设计一个能自由行走,并且可以与人语音对话的机器人.实现的关键是让机器人能通过传感器感知周围环境,并通过 ...
- 浅谈基于Linux的Redis环境搭建
本篇文章主要讲解基于Linux环境的Redis服务搭建,Redis服务配置.客户端访问和防火强配置等技术,适合具有一定Linux基础和Redis基础的读者阅读. 一 Redis服务搭建 1.在根路径 ...
- 表单数据验证方法(二)——ASP.NET后台验证
昨天写了一下关于如何在前台快捷实现表单数据验证的方法,今天接着昨天的,把后台实现数据验证的方法记录一下.先说明一下哈,我用的是asp.net,所以后台验证方法也是基于.net mvc来做的. 好了,闲 ...
- The openssl extension is required for SSL/TLS protection but is not available
今天使用composer update发现报错:The openssl extension is required for SSL/TLS protection but is not availabl ...
- JAVA设计模式——简单工厂
工厂模式分为三种:简单工厂模式,工厂方法模式,抽象工厂模式.我看有的书上和有的文章里是分为两种,没有简单工厂. 工厂模式主要的作用是:一个对象在实例化的时候可以选择多个类,在实例化的时候根据一些业务规 ...