python爬虫入门(三)XPATH和BeautifulSoup4
XML和XPATH
用正则处理HTML文档很麻烦,我们可以先将 HTML文件 转换成 XML文档,然后用 XPath 查找 HTML 节点或元素。
- XML 指可扩展标记语言(EXtensible Markup Language)
- XML 是一种标记语言,很类似 HTML
- XML 的设计宗旨是传输数据,而非显示数据
- XML 的标签需要我们自行定义。
- XML 被设计为具有自我描述性。
- XML 是 W3C 的推荐标准
<?xml version="1.0" encoding="utf-8"?> <bookstore> <book category="cooking">
<title lang="en">Everyday Italian</title>
<author>Giada De Laurentiis</author>
<year>2005</year>
<price>30.00</price>
</book> <book category="children">
<title lang="en">Harry Potter</title>
<author>J K. Rowling</author>
<year>2005</year>
<price>29.99</price>
</book> <book category="web">
<title lang="en">XQuery Kick Start</title>
<author>James McGovern</author>
<author>Per Bothner</author>
<author>Kurt Cagle</author>
<author>James Linn</author>
<author>Vaidyanathan Nagarajan</author>
<year>2003</year>
<price>49.99</price>
</book> <book category="web" cover="paperback">
<title lang="en">Learning XML</title>
<author>Erik T. Ray</author>
<year>2003</year>
<price>39.95</price>
</book> </bookstore>
XML实例
XML和HTML区别

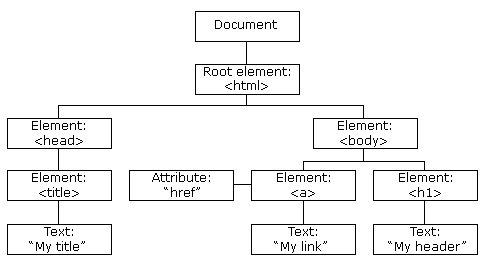
HTML DOM 模型示例
HTML DOM 定义了访问和操作 HTML 文档的标准方法,以树结构方式表达 HTML 文档
XPATH
XPath (XML Path Language) 是一门在 XML 文档中查找信息的语言,可用来在 XML 文档中对元素和属性进行遍历。
chrome插件XPATH HelPer
Firefox插件XPATH Checker
XPATH语法
最常用的路径表达式:


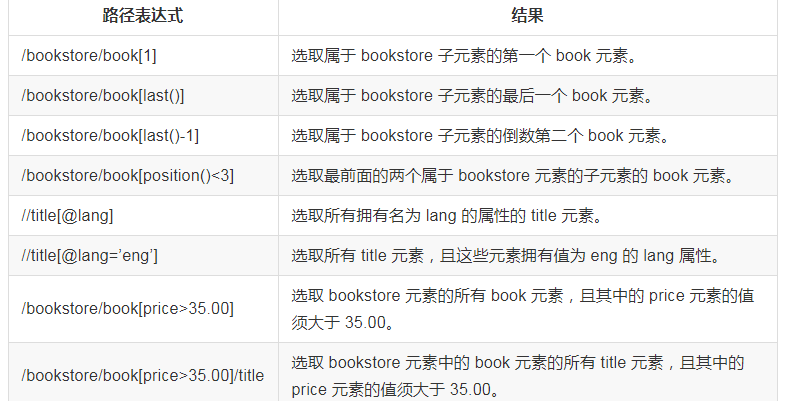
谓语
谓语用来查找某个特定的节点或者包含某个指定的值的节点,被嵌在方括号中。
在下面的表格中,我们列出了带有谓语的一些路径表达式,以及表达式的结果:
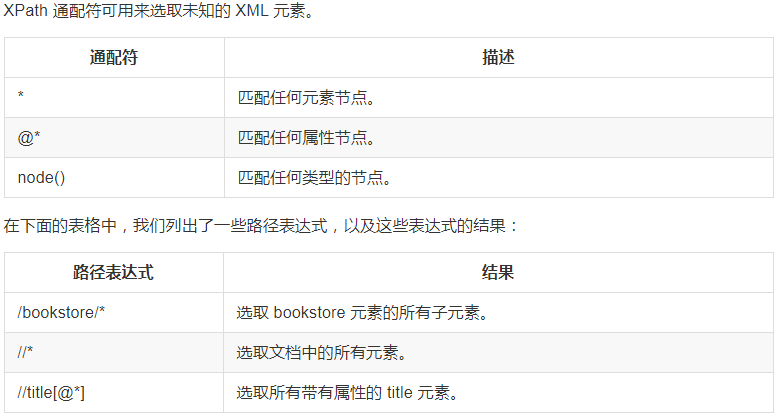
选取位置节点
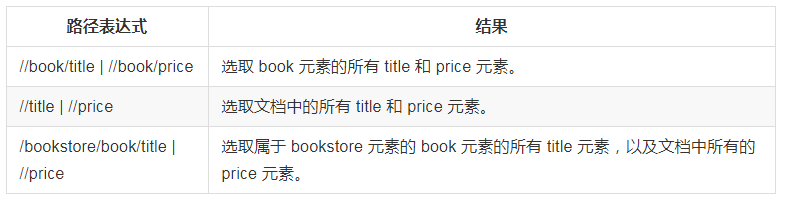
选取若干路劲
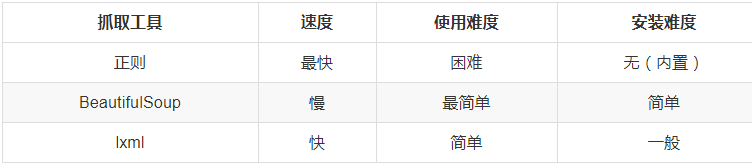
LXML库
安装:pip install lxml
lxml 是 一个HTML/XML的解析器,主要的功能是如何解析和提取 HTML/XML 数据。
lxml和正则一样,也是用 C 实现的,是一款高性能的 Python HTML/XML 解析器,可以利用XPath语法,来快速的定位特定元素以及节点信息。
简单使用方法
#!/usr/bin/env python
# -*- coding:utf-8 -*- from lxml import etree text = '''
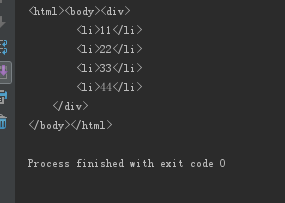
<div>
<li>11</li>
<li>22</li>
<li>33</li>
<li>44</li>
</div>
''' #利用etree.HTML,将字符串解析为HTML文档
html = etree.HTML(text) # 按字符串序列化HTML文档
result = etree.tostring(html) print(result)
结果:
爬取美女吧图片
1.先找到每个帖子列表的url集合


2.再找到每个帖子里面的每个图片的的完整url链接


3.要用到 lxml 模块去解析html
#!/usr/bin/env python
# -*- coding:utf-8 -*- import urllib
import urllib2
from lxml import etree def loadPage(url):
"""
作用:根据url发送请求,获取服务器响应文件
url: 需要爬取的url地址
"""
request = urllib2.Request(url)
html = urllib2.urlopen(request).read()
# 解析HTML文档为HTML DOM模型
content = etree.HTML(html)
# 返回所有匹配成功的列表集合
link_list = content.xpath('//div[@class="t_con cleafix"]/div/div/div/a/@href')
for link in link_list:
fulllink = "http://tieba.baidu.com" + link
# 组合为每个帖子的链接
#print link
loadImage(fulllink) # 取出每个帖子里的每个图片连接
def loadImage(link):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
request = urllib2.Request(link, headers = headers)
html = urllib2.urlopen(request).read()
# 解析
content = etree.HTML(html)
# 取出帖子里每层层主发送的图片连接集合
link_list = content.xpath('//img[@class="BDE_Image"]/@src')
# 取出每个图片的连接
for link in link_list:
# print link
writeImage(link) def writeImage(link):
"""
作用:将html内容写入到本地
link:图片连接
"""
#print "正在保存 " + filename
headers = {"User-Agent" : "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36"}
# 文件写入
request = urllib2.Request(link, headers = headers)
# 图片原始数据
image = urllib2.urlopen(request).read()
# 取出连接后10位做为文件名
filename = link[-10:]
# 写入到本地磁盘文件内
with open(filename, "wb") as f:
f.write(image)
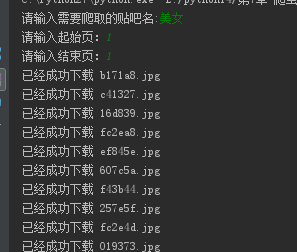
print "已经成功下载 "+ filename def tiebaSpider(url, beginPage, endPage):
"""
作用:贴吧爬虫调度器,负责组合处理每个页面的url
url : 贴吧url的前部分
beginPage : 起始页
endPage : 结束页
"""
for page in range(beginPage, endPage + 1):
pn = (page - 1) * 50
#filename = "第" + str(page) + "页.html"
fullurl = url + "&pn=" + str(pn)
#print fullurl
loadPage(fullurl)
#print html print "谢谢使用" if __name__ == "__main__":
kw = raw_input("请输入需要爬取的贴吧名:")
beginPage = int(raw_input("请输入起始页:"))
endPage = int(raw_input("请输入结束页:")) url = "http://tieba.baidu.com/f?"
key = urllib.urlencode({"kw": kw})
fullurl = url + key
tiebaSpider(fullurl, beginPage, endPage)
4.爬取的图片全部保存到了电脑里面

CSS选择器:BeautifulSoup4
和 lxml 一样,Beautiful Soup 也是一个HTML/XML的解析器,主要的功能也是如何解析和提取 HTML/XML 数据。
lxml 只会局部遍历,而Beautiful Soup 是基于HTML DOM的,会载入整个文档,解析整个DOM树,因此时间和内存开销都会大很多,所以性能要低于lxml。
BeautifulSoup 用来解析 HTML 比较简单,API非常人性化,支持CSS选择器、Python标准库中的HTML解析器,也支持 lxml 的 XML解析器。
Beautiful Soup 3 目前已经停止开发,推荐现在的项目使用Beautiful Soup 4。使用 pip 安装即可:
pip install beautifulsoup4
使用Beautifulsoup4爬取腾讯招聘职位信息
from bs4 import BeautifulSoup
import urllib2
import urllib
import json # 使用了json格式存储 def tencent():
url = 'http://hr.tencent.com/'
request = urllib2.Request(url + 'position.php?&start=10#a')
response =urllib2.urlopen(request)
resHtml = response.read() output =open('tencent.json','w') html = BeautifulSoup(resHtml,'lxml') # 创建CSS选择器
result = html.select('tr[class="even"]')
result2 = html.select('tr[class="odd"]')
result += result2 items = []
for site in result:
item = {} name = site.select('td a')[0].get_text()
detailLink = site.select('td a')[0].attrs['href']
catalog = site.select('td')[1].get_text()
recruitNumber = site.select('td')[2].get_text()
workLocation = site.select('td')[3].get_text()
publishTime = site.select('td')[4].get_text() item['name'] = name
item['detailLink'] = url + detailLink
item['catalog'] = catalog
item['recruitNumber'] = recruitNumber
item['publishTime'] = publishTime items.append(item) # 禁用ascii编码,按utf-8编码
line = json.dumps(items,ensure_ascii=False) output.write(line.encode('utf-8'))
output.close() if __name__ == "__main__":
tencent()
JSON和JSONPath
JSON(JavaScript Object Notation) 是一种轻量级的数据交换格式,它使得人们很容易的进行阅读和编写。同时也方便了机器进行解析和生成。适用于进行数据交互的场景,比如网站前台与后台之间的数据交互。
JsonPath 是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括:Javascript, Python, PHP 和 Java。
JsonPath 对于 JSON 来说,相当于 XPATH 对于 XML。
JsonPath与XPath语法对比:
Json结构清晰,可读性高,复杂度低,非常容易匹配,下表中对应了XPath的用法。

利用JSONPath爬取拉勾网上所有的城市
#!/usr/bin/env python
# -*- coding:utf-8 -*- import urllib2
# json解析库,对应到lxml
import json
# json的解析语法,对应到xpath
import jsonpath url = "http://www.lagou.com/lbs/getAllCitySearchLabels.json"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
request = urllib2.Request(url, headers = headers) response = urllib2.urlopen(request)
# 取出json文件里的内容,返回的格式是字符串
html = response.read() # 把json形式的字符串转换成python形式的Unicode字符串
unicodestr = json.loads(html) # Python形式的列表
city_list = jsonpath.jsonpath(unicodestr, "$..name") #for item in city_list:
# print item # dumps()默认中文为ascii编码格式,ensure_ascii默认为Ture
# 禁用ascii编码格式,返回的Unicode字符串,方便使用
array = json.dumps(city_list, ensure_ascii=False)
#json.dumps(city_list)
#array = json.dumps(city_list) with open("lagoucity.json", "w") as f:
f.write(array.encode("utf-8"))
结果:

糗事百科爬取
利用XPATH的模糊查询
获取每个帖子里的
内容保存到 json 文件内
#!/usr/bin/env python
# -*- coding:utf-8 -*- import urllib2
import json
from lxml import etree url = "http://www.qiushibaike.com/8hr/page/2/"
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/60.0.3112.101 Safari/537.36'}
request = urllib2.Request(url, headers = headers) html = urllib2.urlopen(request).read()
# 响应返回的是字符串,解析为HTML DOM模式 text = etree.HTML(html) text = etree.HTML(html)
# 返回所有段子的结点位置,contains()模糊查询方法,第一个参数是要匹配的标签,第二个参数是标签名部分内容
node_list = text.xpath('//div[contains(@id, "qiushi_tag")]') items ={}
for node in node_list:
# xpath返回的列表,这个列表就这一个参数,用索引方式取出来,用户名
username = node.xpath('./div/a/@title')[0]
# 取出标签下的内容,段子内容
content = node.xpath('.//div[@class="content"]/span')[0].text
# 取出标签里包含的内容,点赞
zan = node.xpath('.//i')[0].text
# 评论
comments = node.xpath('.//i')[1].text items = {
"username" : username,
"content" : content,
"zan" : zan,
"comments" : comments
} with open("qiushi.json", "a") as f:
f.write(json.dumps(items, ensure_ascii=False).encode("utf-8") + "\n")
python爬虫入门(三)XPATH和BeautifulSoup4的更多相关文章
- 3.Python爬虫入门三之Urllib和Urllib2库的基本使用
1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解释才呈现出来的,实质它是一段HTML代码,加 JS.CSS ...
- 转 Python爬虫入门三之Urllib库的基本使用
静觅 » Python爬虫入门三之Urllib库的基本使用 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器 ...
- python爬虫入门三:requests库
urllib库在很多时候都比较繁琐,比如处理Cookies.因此,我们选择学习另一个更为简单易用的HTTP库:Requests. requests官方文档 1. 什么是Requests Request ...
- Python爬虫入门三之Urllib库的基本使用
转自http://cuiqingcai.com/947.html 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由 ...
- Python爬虫入门之Urllib库的基本使用
那么接下来,小伙伴们就一起和我真正迈向我们的爬虫之路吧. 1.分分钟扒一个网页下来 怎样扒网页呢?其实就是根据URL来获取它的网页信息,虽然我们在浏览器中看到的是一幅幅优美的画面,但是其实是由浏览器解 ...
- Python爬虫教程-25-数据提取-BeautifulSoup4(三)
Python爬虫教程-25-数据提取-BeautifulSoup4(三) 本篇介绍 BeautifulSoup 中的 css 选择器 css 选择器 使用 soup.select 返回一个列表 通过标 ...
- 爬虫入门三 scrapy
title: 爬虫入门三 scrapy date: 2020-03-14 14:49:00 categories: python tags: crawler scrapy框架入门 1 scrapy简介 ...
- Python爬虫入门一之综述
大家好哈,最近博主在学习Python,学习期间也遇到一些问题,获得了一些经验,在此将自己的学习系统地整理下来,如果大家有兴趣学习爬虫的话,可以将这些文章作为参考,也欢迎大家一共分享学习经验. Pyth ...
- Python爬虫入门教程 43-100 百思不得姐APP数据-手机APP爬虫部分
1. Python爬虫入门教程 爬取背景 2019年1月10日深夜,打开了百思不得姐APP,想了一下是否可以爬呢?不自觉的安装到了夜神模拟器里面.这个APP还是比较有名和有意思的. 下面是百思不得姐的 ...
- Python爬虫入门之正则表达式
在前面我们已经搞定了怎样获取页面的内容,不过还差一步,这么多杂乱的代码夹杂文字我们怎样把它提取出来整理呢?下面就开始介绍一个十分强大的工具,正则表达式! 1.了解正则表达式 正则表达式是对字符串操作的 ...
随机推荐
- Linux Shell脚本攻略学习总结:二
比较与测试 程序中的流程控制是由比较和测试语句来处理的. 我们可以用if,if else 以及逻辑运算符来执行测试,而用一些比较运算符来比较数据项.另外,有一个test 命令也可以用来进行测试.让我们 ...
- (NO.00001)iOS游戏SpeedBoy Lite成形记(十九)
最后就是要完成前面设定的第3件事:如果玩家赌对了则赢钱,反之输钱. 前面的框架搭的差不多了,所以这里实现起来也就不难了 ;) 首先我们怎么知道用户输入完毕,然后关闭窗口了?只有在这个点上GameSce ...
- Java深拷贝浅拷贝
首先,Java中常用的拷贝操作有三个,operator = .拷贝构造函数 和 clone()方法.由于Java不支持运算符重载,我们无法在自己的自定义类型中定义operator=.拷贝构造函数大家应 ...
- LDA主体模型
一)LDA作用 传统判断两个文档相似性的方法是通过查看两个文档共同出现的单词的多少,如TF-IDF等,这种方法没有考虑到文字背后的语义关联,可能在两个文档共同出现的单词很少甚至没有,但两个文档是相似的 ...
- 开源,免费和跨平台 - MVP ComCamp 2015 KEYNOTE
2015年1月31日,作为KEYNOTE演讲嘉宾,我和来自全国各地的开发人员分享了作为一名MVP的一些体会. Keynote – Open Source, Free Tools and Cross P ...
- Web应用程序设计十个建议
原文链接: Top 10 Design Tips for Web Apps 原文日期: 2014年04月02日 翻译日期: 2014年04月11日 翻译人员: 铁锚 现代web应用通常在互联网上通过 ...
- LeetCode之“散列表”:Two Sum && 3Sum && 3Sum Closest && 4Sum
1. Two Sum 题目链接 题目要求: Given an array of integers, find two numbers such that they add up to a specif ...
- x64系统的判断和x64下文件和注册表访问的重定向——补记
原来的地址 x64系统的判断和x64下文件和注册表访问的重定向(1) x64系统的判断和x64下文件和注册表访问的重定向(2) x64系统的判断和x64下文件和注册表访问的重定向(3) 之前在(3)里 ...
- PLSQL表
PL/SQL表 一,什么是PL/SQL表? 首先PL/SQL表和记录(Record)一样,都是复合数据类型.可以看做是一种用户自定义数据类型. PL/SQL表由多列单行的标量构成的临时索引表对象.组成 ...
- Mina源码阅读笔记(一)-整体解读
今天的这一节,将从整体上对mina的源代码进行把握,网上已经有好多关于mina源码的阅读笔记,但好多都是列举了一下每个接口或者类的方法.我倒是想从mina源码的结构和功能上对这个框架进行剖析.源码的阅 ...