Scrapy爬虫框架第四讲(Linux环境)
下面我们来学习Selector的具体使用:(参考文档:http://scrapy-chs.readthedocs.io/zh_CN/1.0/topics/selectors.html)
Selector简介:Scrapy框架提供了自己的一套数据提取方法即Selector(选择器),它是基于lxml构建的,支持xpath、css、正则表达式
下面我们主要介绍Selector与scrapy shell(scrapy中的交互模式)并结合xpath 、css 、 正则表达式的使用
(1)、启动终端并激活虚拟环境
(2)、使用scrapy shell 下载网站例子这里我已百度阅读畅销榜为例进行分析(scrapy shell https://yuedu.baidu.com/rank/hotsale?pn=0---爬取该网站,再使用fetch(‘https://yuedu.baidu.com/ebook/09075cc5a1116c175f0e7cd184254b35effd1a77?fr=bookrank’)下载具体一本书的页面)
(course-python3.5-env) bourne@bourne-vm:~/example/example$ scrapy shell https://yuedu.baidu.com/rank/hotsale?pn=0
2018-05-14 10:56:08 [scrapy.utils.log] INFO: Scrapy 1.5.0 started (bot: example)
2018-05-14 10:56:08 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.0.3, parsel 1.4.0, w3lib 1.19.0, Twisted 18.4.0, Python 3.5.2 (default, Nov 23 2017, 16:37:01) - [GCC 5.4.0 20160609], pyOpenSSL 17.5.0 (OpenSSL 1.1.0h 27 Mar 2018), cryptography 2.2.2, Platform Linux-4.13.0-36-generic-x86_64-with-Ubuntu-16.04-xenial
2018-05-14 10:56:08 [scrapy.crawler] INFO: Overridden settings: {'BOT_NAME': 'example', 'LOGSTATS_INTERVAL': 0, 'DUPEFILTER_CLASS': 'scrapy.dupefilters.BaseDupeFilter', 'USER_AGENT': 'BaiduSpider', 'ROBOTSTXT_OBEY': True, 'SPIDER_MODULES': ['example.spiders'], 'NEWSPIDER_MODULE': 'example.spiders'}
2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled extensions:
['scrapy.extensions.memusage.MemoryUsage',
'scrapy.extensions.corestats.CoreStats',
'scrapy.extensions.telnet.TelnetConsole']
2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled downloader middlewares:
['scrapy.downloadermiddlewares.robotstxt.RobotsTxtMiddleware',
'scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware',
'scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware',
'scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware',
'scrapy.downloadermiddlewares.useragent.UserAgentMiddleware',
'scrapy.downloadermiddlewares.retry.RetryMiddleware',
'scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware',
'scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware',
'scrapy.downloadermiddlewares.redirect.RedirectMiddleware',
'scrapy.downloadermiddlewares.cookies.CookiesMiddleware',
'scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware',
'scrapy.downloadermiddlewares.stats.DownloaderStats']
2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled spider middlewares:
['scrapy.spidermiddlewares.httperror.HttpErrorMiddleware',
'scrapy.spidermiddlewares.offsite.OffsiteMiddleware',
'scrapy.spidermiddlewares.referer.RefererMiddleware',
'scrapy.spidermiddlewares.urllength.UrlLengthMiddleware',
'scrapy.spidermiddlewares.depth.DepthMiddleware']
2018-05-14 10:56:08 [scrapy.middleware] INFO: Enabled item pipelines:
[]
2018-05-14 10:56:08 [scrapy.extensions.telnet] DEBUG: Telnet console listening on 127.0.0.1:6023
2018-05-14 10:56:08 [scrapy.core.engine] INFO: Spider opened
2018-05-14 10:56:08 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://yuedu.baidu.com/robots.txt> (referer: None)
2018-05-14 10:56:09 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://yuedu.baidu.com/rank/hotsale?pn=0> (referer: None)
[s] Available Scrapy objects:
[s] scrapy scrapy module (contains scrapy.Request, scrapy.Selector, etc)
[s] crawler <scrapy.crawler.Crawler object at 0x7f603750edd8>
[s] item {}
[s] request <GET https://yuedu.baidu.com/rank/hotsale?pn=0>
[s] response <200 https://yuedu.baidu.com/rank/hotsale?pn=0>
[s] settings <scrapy.settings.Settings object at 0x7f603750eb38>
[s] spider <DefaultSpider 'default' at 0x7f60370a54a8>
[s] Useful shortcuts:
[s] fetch(url[, redirect=True]) Fetch URL and update local objects (by default, redirects are followed)
[s] fetch(req) Fetch a scrapy.Request and update local objects
[s] shelp() Shell help (print this help)
[s] view(response) View response in a browser
In [1]: fetch('https://yuedu.baidu.com/ebook/09075cc5a1116c175f0e7cd184254b35effd1a77?fr=b
...: ookrank')
2018-05-14 10:56:34 [scrapy.core.engine] DEBUG: Crawled (200) <GET https://yuedu.baidu.com/ebook/09075cc5a1116c175f0e7cd184254b35effd1a77?fr=bookrank> (referer: None)
下面开始我们的实验:
Selector与Css、Xpath 、正则表达式结合使用:

比如我要提取书名,怎么办呢?(这里向小伙伴们说明一点爬取网页后会返回一个response 对象,下面我们使用css)
答:
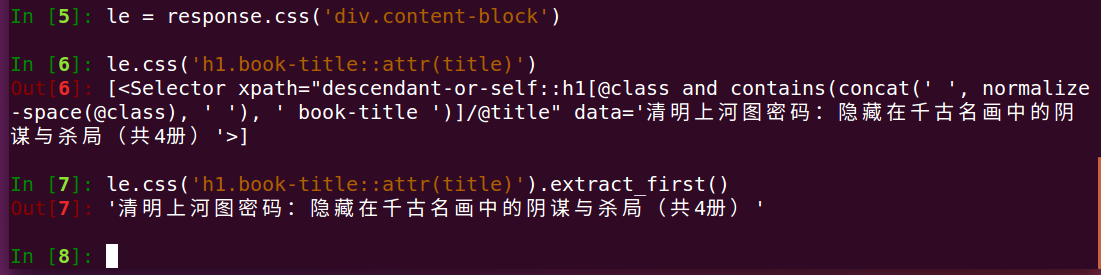
分析:这里我们先选中了class="content-block"并构造了一个le对象--接着我们选取了le对象下的h1标签下的class="book-title"的title属性--最后我们使用了restrict_first()(脱壳)提取了第一个结过并返回给我们一个字符串图书名
CSS语法如下(具体请参见http://www.w3school.com.cn/cssref/css_selectors.asp)
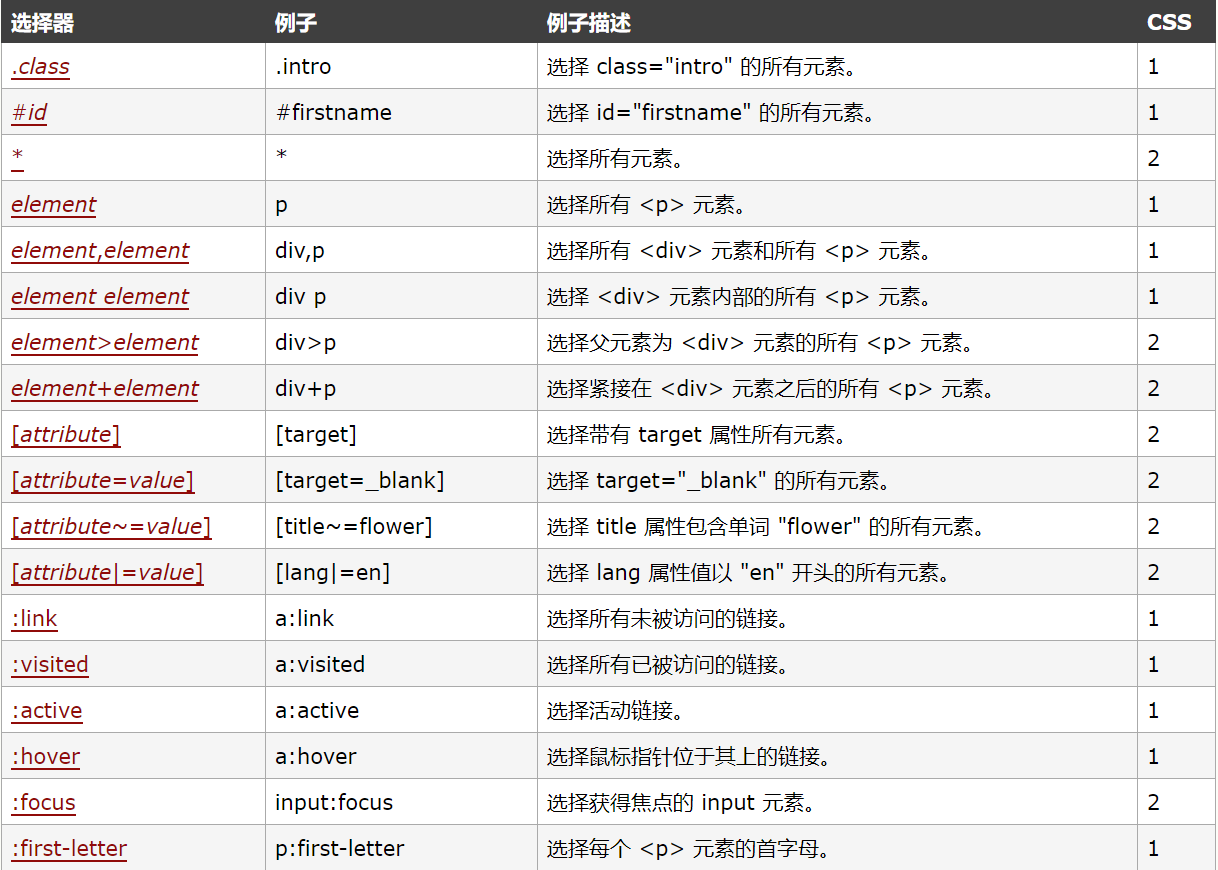
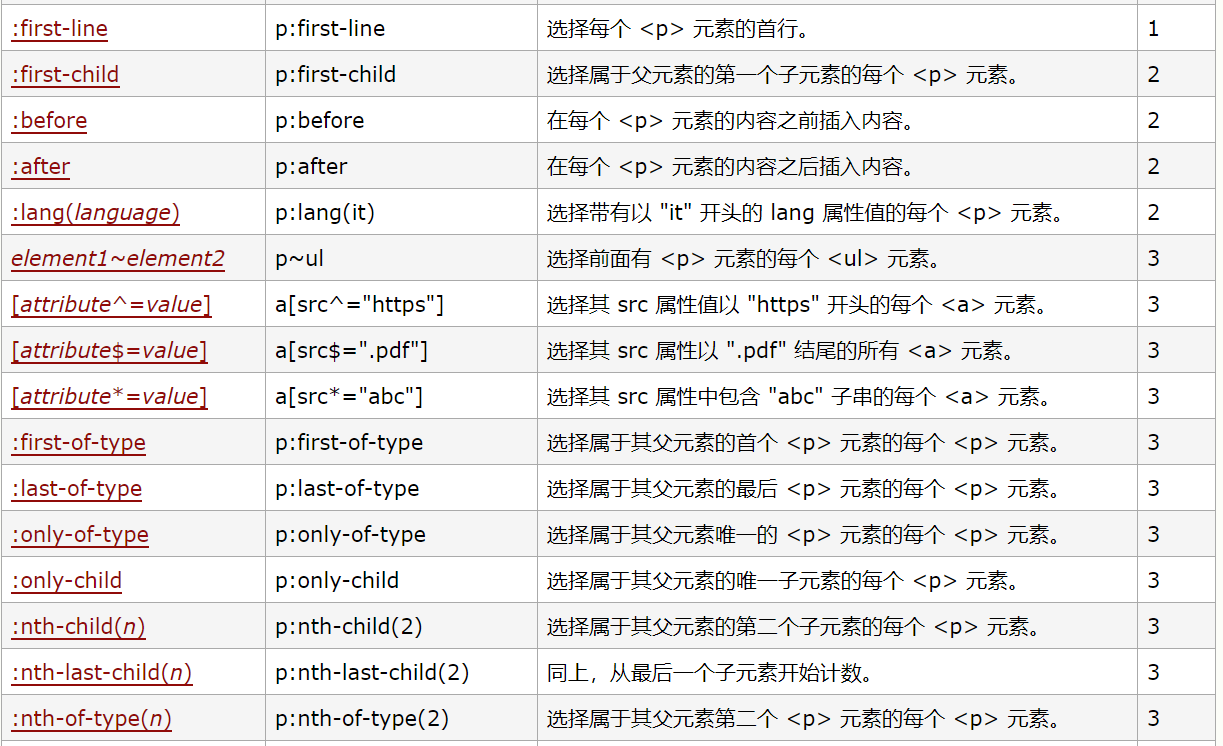
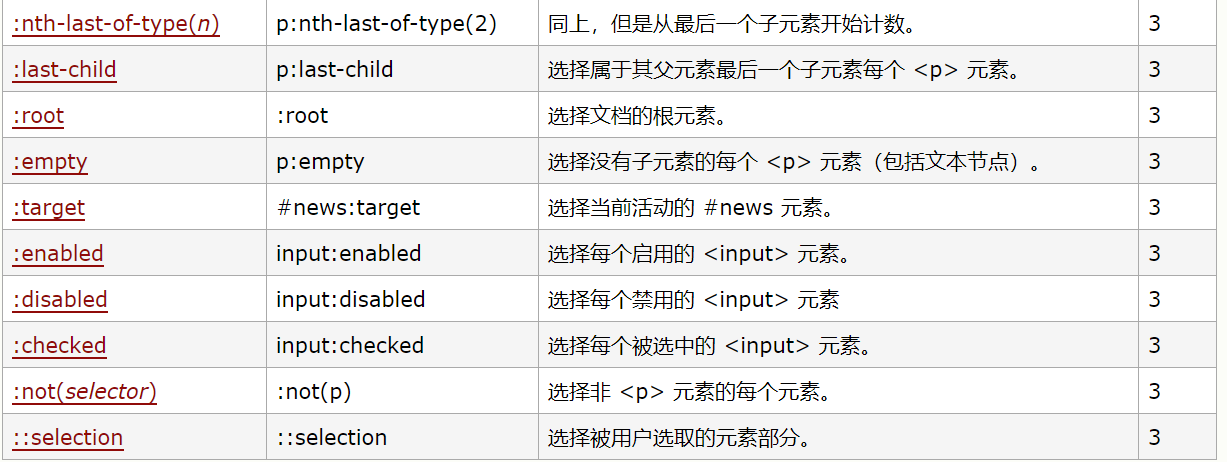
我们再使用xpath语法实现同样的效果:

xpath语法如下:
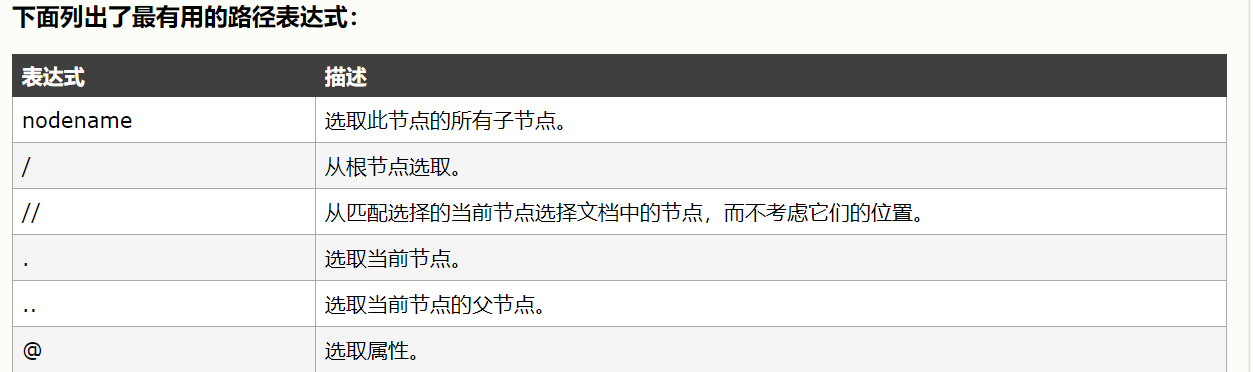
小伙伴们如需进一步了解请参考:http://www.w3school.com.cn/xpath/xpath_syntax.asp
我们再看一例:
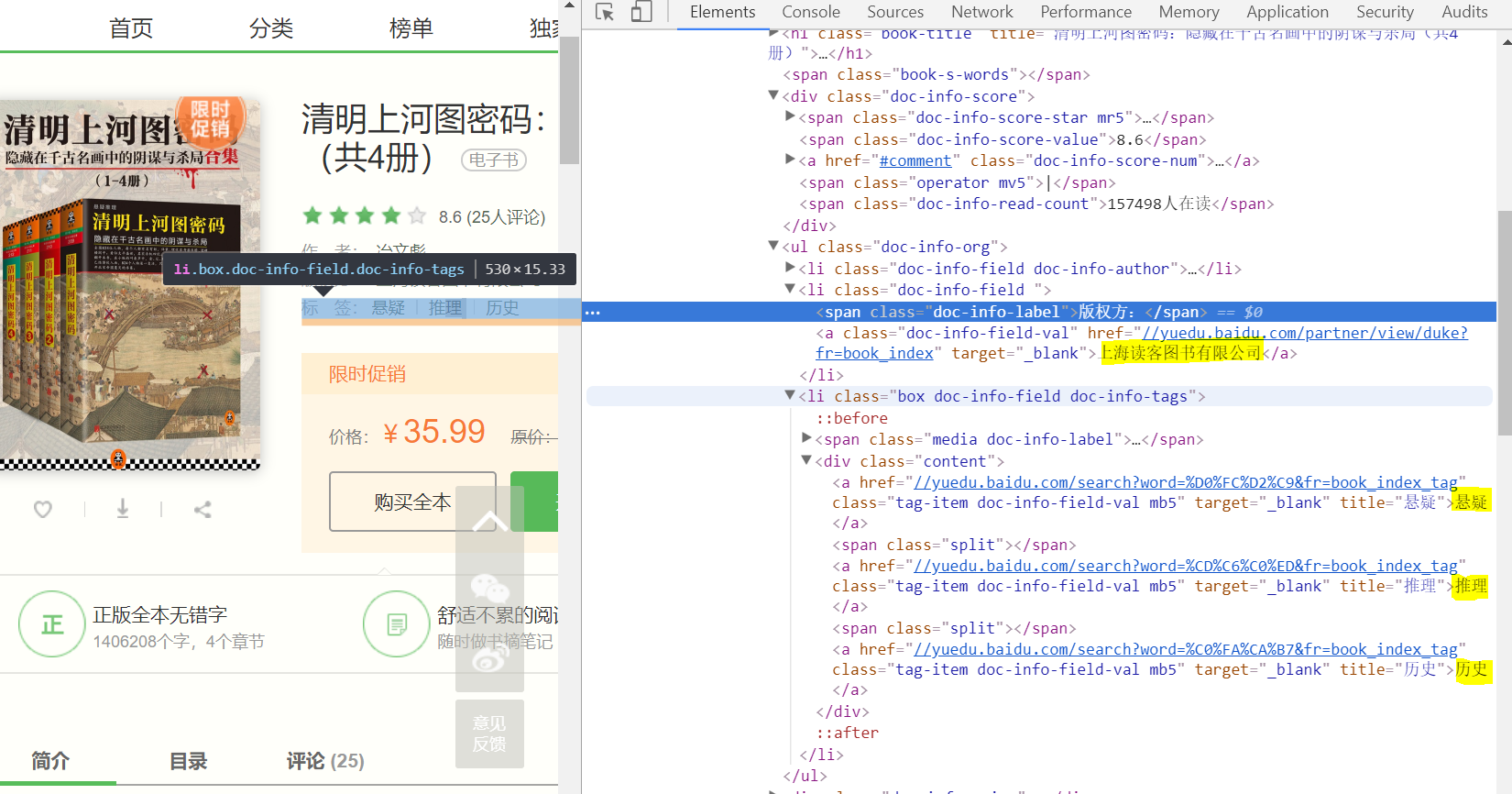
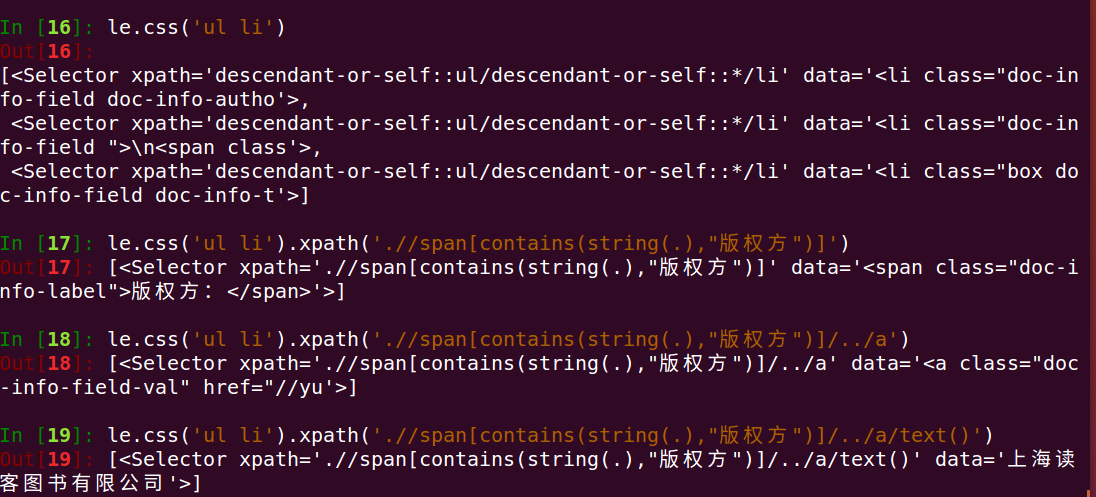
分析:我们先选中了ul 下的li 标签,接着我们使用嵌套选择使用xpath语法选择包好版权方字样的span,再选中它的父标签下的a标签下的文本

分析:这里我们同样使用了嵌套选择,首先选中了li的class为doc-info-tags标签下的 div的class为content的标签,再使用xpaht选择器选取了其下的文本,由于格式问题我们最后选用了re模块进行选择其中的文本并返回一个列表(正则表达式的用法请小伙伴们参考文档)
下面我们介绍下4个方法(我喜欢叫它们为脱壳方法)
(1)extract_first()----返回第一个文本并以字符串形式返回
(2)extract()---返回一个文本字符串列表
(3)re()---返回一个列表的值
(4)re_first()--返回第一个值
其中:(3)(4)针对一些提取需要特殊处理的数据如上例
总结:以上我们分析了Selector与xpath\css\正则的结合使用,建议小伙伴们先学习后三者的基本语法,再多加练习即可,掌握方法即可。

Scrapy爬虫框架第四讲(Linux环境)的更多相关文章
- Scrapy爬虫框架补充内容一(Linux环境)
Scrapy爬虫框架结构及工作原理详解 scrapy框架的框架结构如下: 组件分析: ENGINE:(核心):处理整个框架的数据流,各个组件在其控制下协同工作 SCHEDULER(调度器):负责接收引 ...
- Scrapy爬虫框架第五讲(linux环境)【download middleware用法】
DOWNLOAD MIDDLEWRE用法详解 通过上面的Scrapy工作架构我们对其功能进行下总结: (1).在Scheduler调度出队列时的Request送给downloader下载前对其进行修改 ...
- Scrapy爬虫框架第三讲(linux环境)
下面我们来学习下Spider的具体使用: 我们已上节的百度阅读爬虫为例来进行分析: 1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.li ...
- Scrapy爬虫框架第七讲【ITEM PIPELINE用法】
ITEM PIPELINE用法详解: ITEM PIPELINE作用: 清理HTML数据 验证爬取的数据(检查item包含某些字段) 去重(并丢弃)[预防数据去重,真正去重是在url,即请求阶段做] ...
- Scrapy爬虫框架第八讲【项目实战篇:知乎用户信息抓取】--本文参考静觅博主所写
思路分析: (1)选定起始人(即选择关注数和粉丝数较多的人--大V) (2)获取该大V的个人信息 (3)获取关注列表用户信息 (4)获取粉丝列表用户信息 (5)重复(2)(3)(4)步实现全知乎用户爬 ...
- Python之Scrapy爬虫框架安装及简单使用
题记:早已听闻python爬虫框架的大名.近些天学习了下其中的Scrapy爬虫框架,将自己理解的跟大家分享.有表述不当之处,望大神们斧正. 一.初窥Scrapy Scrapy是一个为了爬取网站数据,提 ...
- Python-S9-Day126——Scrapy爬虫框架
01 今日内容概要 02 内容回顾和补充:scrapy 03 内容回顾和补充:网络和并发编程 04 Scrapy爬虫框架:pipeline做持久化(一) 05 Scrapy爬虫框架:pipeline做 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- scrapy爬虫学习系列四:portia的学习入门
系列文章列表: scrapy爬虫学习系列一:scrapy爬虫环境的准备: http://www.cnblogs.com/zhaojiedi1992/p/zhaojiedi_python_00 ...
随机推荐
- Python学习笔记 - 列表生成式listComprehensions
#!/usr/bin/env python3 # -*- coding: utf-8 -*- list(range(1, 11)) # 生成1乘1,2乘2...10乘10 L = [] for x i ...
- Customer Form Issue: Automatic Matching Rule Set Defaults Value AutoRuleSet-1
In this Document Symptoms Changes Cause Solution References APPLIES TO: Oracle Receivables ...
- Android For JNI(一)——JNI的概念以及C语言开发工具dev-c++,编写你的第一个C语言程序,使用C启动JAVA程序
Android For JNI(一)--JNI的概念以及C语言开发工具dev-c++,编写你的第一个C语言程序 当你的Android之旅一步步的深入的时候,你其实会发现,很多东西都必须去和framew ...
- centOS 安装(光安装 和 u盘安装)
光盘安装用这个: http://www.williamlong.info/archives/1912.html 是否保留win7,要作好相关配置.有些插件可以不装. 网络设置:不好弄 如果用u盘安装, ...
- infiniDB在linux下完成倒库
在网看到自己的文章被四处烂用,经常搜到自己的文章.关键是,你能把我头像删除了不,有本事,你 把网址也给出http://blog.csdn.net/longshenlmj/article/details ...
- C/C++中关键字static的用法及作用
本文将主要从static在C和C++共有的作用及C++特有的作用两个方面进行解析. 在C和C++中共有的作用 隐藏(对变量.函数均可) 当同时编译多个文件时,所有未加static前缀的全局变量或全局函 ...
- Android回调详解
很多时候开发遇到一些Ui更新 网络数据获取,或者方法方法传递的时候会借助回调函数,那么什么是回调函数 百度百科是这么解释的 转载请标注出处 http://blog.csdn.net/sk7 ...
- linux内核中的排序接口--sort函数
linux内核中的sort函数,其实跟我们所说的qsort函数很像,我们来看看qsort: qsort 的函数原型是 void qsort(void*base,size_t num,size_t wi ...
- rails将类常量重构到数据库对应的表中之三
经过博文之一和之二的重构,貌似代码表现的还不错,正常运行和test都通过鸟,但是,感觉告诉我们还是有什么地方不对劲啊!究竟是哪里不对劲呢?我们再来好好看一下. 我们把数据库表中的支付方式集合直接放在实 ...
- JS (全局作用域)
一.全局函数作用域(把变量的声明和函数的声明放在前面) 作用域(scope):一条数据可以在哪个范围中使用. 通常来说,一段程序代码中所用到的数据并不总是有效/可用的,而限定这个数据的可用性的代码范围 ...