转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数
本文只讲解视觉层(Vision Layers)的参数,视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层。
1、Convolution层:
就是卷积层,是卷积神经网络(CNN)的核心层。
层类型:Convolution
lr_mult: 学习率的系数,最终的学习率是这个数乘以solver.prototxt配置文件中的base_lr。如果有两个lr_mult, 则第一个表示权值的学习率,第二个表示偏置项的学习率。一般偏置项的学习率是权值学习率的两倍。
在后面的convolution_param中,我们可以设定卷积层的特有参数。
必须设置的参数:
num_output: 卷积核(filter)的个数
kernel_size: 卷积核的大小。如果卷积核的长和宽不等,需要用kernel_h和kernel_w分别设定
其它参数:
stride: 卷积核的步长,默认为1。也可以用stride_h和stride_w来设置。
pad: 扩充边缘,默认为0,不扩充。 扩充的时候是左右、上下对称的,比如卷积核的大小为5*5,那么pad设置为2,则四个边缘都扩充2个像素,即宽度和高度都扩充了4个像素,这样卷积运算之后的特征图就不会变小。也可以通过pad_h和pad_w来分别设定。

layer {
name: "conv1"
type: "Convolution"
bottom: "data"
top: "conv1"
param {
lr_mult: 1
}
param {
lr_mult: 2
}
convolution_param {
num_output: 20
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
}
layer {
name: "pool1"
type: "Pooling"
bottom: "conv1"
top: "pool1"
pooling_param {
pool: MAX
kernel_size: 3
stride: 2
}
}
pooling层的运算方法基本是和卷积层是一样的。
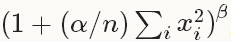 ,得到归一化后的输出
,得到归一化后的输出layers {
name: "norm1"
type: LRN
bottom: "pool1"
top: "norm1"
lrn_param {
local_size: 5
alpha: 0.0001
beta: 0.75
}
}
4、im2col层
如果对matlab比较熟悉的话,就应该知道im2col是什么意思。它先将一个大矩阵,重叠地划分为多个子矩阵,对每个子矩阵序列化成向量,最后得到另外一个矩阵。
看一看图就知道了:
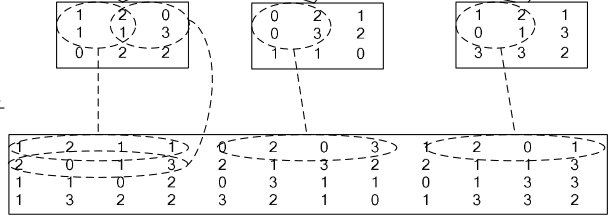
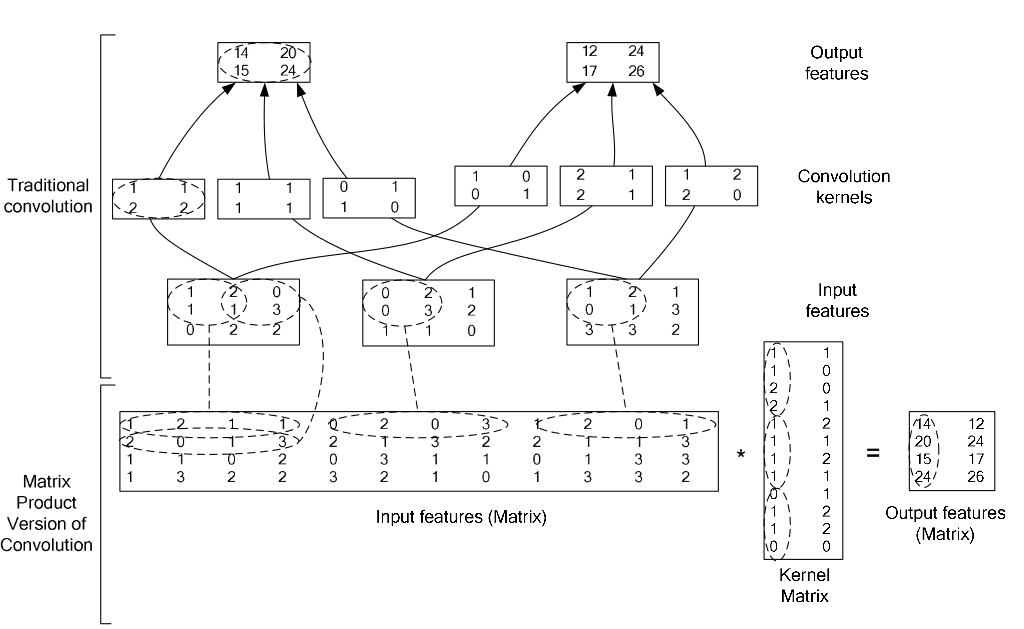
在caffe中,卷积运算就是先对数据进行im2col操作,再进行内积运算(inner product)。这样做,比原始的卷积操作速度更快。
看看两种卷积操作的异同:
转 Caffe学习系列(3):视觉层(Vision Layers)及参数的更多相关文章
- [转] caffe视觉层Vision Layers 及参数
视觉层包括Convolution, Pooling, Local Response Normalization (LRN), im2col等层. 1.Convolution层: 就是卷积层,是卷积神经 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
随机推荐
- CentOS修改Tomcat端口号
Linux下修改Tomcat默认端口 1.方法一 假设tomcat所在目录为/usr/local/apache-tomcat/ 1.打开tomcat配置文件 # vi /usr/local/apach ...
- 学会用git真的很重要
一.首先,作为一名开发人员,目前个人菜鸟一个,觉得有个仓库来管理好自己的项目是真的很重要,而目前个人认为在git上面管理自己的项目是真的很不错的推荐,接下来给大家介绍一下如何使用git上传.管理自己的 ...
- Git分支高级管理[四]
标签(linux): git 笔者Q:972581034 交流群:605799367.有任何疑问可与笔者或加群交流 切换分支 git checkout 撤销对文件的修改 git checkout -- ...
- postgres允许别人访问连接配置
- rabbitmq配置文件和站点管理(二)
前面介绍了erlang环境的安装和rabbitmq环境安装,接下来对rabbitmq详细配置和管理: 启用后台管理插件 创建目录 mkdir /etc/rabbitmq 启用插件 rabbitmq-p ...
- ABP官方文档翻译 4.6 审计日志
审计日志 介绍 关于IAuditingStore 配置 通过特性启用/禁用 注意事项 介绍 维基百科:“审计追踪(也称为审计日志)是与安全相关的按时间先后的记录.记录集合.记录的目的地和源,提供一系列 ...
- 看图说话,P2P 分享率 90% 以上的 P2P-CDN 服务,来了!
事情是这样的:今年年初的时候,公司准备筹划一个直播项目,在原有的 APP 中嵌入直播模块,其中的一个问题就是直播加速服务的选取. 老板让我负责直播加速的产品选型,那天老板把我叫到办公室,语重心长地说: ...
- Java修改maven的默认jdk版本为1.7
Java修改maven的默认jdk版本 问题: 1.创建maven项目的时候,jdk版本是1.5版本,而自己安装的是1.7或者1.8版本. 2.每次右键项目名-maven->update pro ...
- Java程序只运行一个实例[转]
如果希望你的Java程序只能存在一个实例,可以参考下面的用法. 原文链接:http://blog.csdn.net/yaerfeng/article/details/7264729 Java没有提供这 ...
- 洛谷 [P3398] 仓鼠找sugar
树剖求LCA 我们可以发现,两条路径ab,cd相交,当且仅当 dep[lca(a,b)]>=dep[lca(c,d)]&(lca(lca(a,b),c)==lca(a,b)||lca(l ...