使用caffe训练mnist数据集 - caffe教程实战(一)
个人认为学习一个陌生的框架,最好从例子开始,所以我们也从一个例子开始。
学习本教程之前,你需要首先对卷积神经网络算法原理有些了解,而且安装好了caffe
卷积神经网络原理参考:http://cs231n.stanford.edu/syllabus.html
Ubuntu安装caffe教程参考:http://caffe.berkeleyvision.org/install_apt.html
先讲解一下caffe设计的架构吧:

训练mnist数据集使用 build/tools/caffe
训练步骤:
准备数据:
cd $CAFFE_ROOT //安装caffe的根目录./data/mnist/get_mnist.sh //下载mnist数据集
./examples/mnist/create_mnist.sh //将图片转为lmdb数据格式
定义网络模型:
首先定义数据层:
layer {
name: "mnist" //名字可以随便写 字符串类型
type: "Data" //类型 必须是 Data 字符串类型
transform_param {
scale: 0.00390625
}
data_param {
source: "mnist_train_lmdb"
backend: LMDB
batch_size: 64
}
top: "data"
top: "label"
}
定义卷基层:
layer {
name: "conv1"
type: "Convolution"
param { lr_mult: 1 } #定义w参数的学习率
param { lr_mult: 2 } #定义b参数的学习率
convolution_param {
num_output: 20 #定义输出map数量
kernel_size: 5
stride: 1
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "data"
top: "conv1"
}
定义pool层:
layer {
name: "pool1"
type: "Pooling"
pooling_param {
kernel_size: 2
stride: 2
pool: MAX
}
bottom: "conv1"
top: "pool1"
}
定义全连接层:
layer {
name: "ip1"
type: "InnerProduct"
param { lr_mult: 1 }
param { lr_mult: 2 }
inner_product_param {
num_output: 500
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "pool2"
top: "ip1"
}
定义relu层:
layer {
name: "relu1"
type: "ReLU"
bottom: "ip1"
top: "ip1"
}
再定义一个全连接层: 注意这里的输出为 分类的个数layer {
name: "ip2"
type: "InnerProduct"
param { lr_mult: 1 }
param { lr_mult: 2 }
inner_product_param {
num_output: 10 #表示有10个类别 从0-9个数字
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
}
}
bottom: "ip1"
top: "ip2"
}
最后定义 损失函数
layer {
name: "loss"
type: "SoftmaxWithLoss"
bottom: "ip2"
bottom: "label"
}
定义好网络模型后,需要定义 模型训练的策略, solver# The train/test net protocol buffer definition
net: "examples/mnist/lenet_train_test.prototxt"
# test_iter specifies how many forward passes the test should carry out.
# In the case of MNIST, we have test batch size 100 and 100 test iterations,
# covering the full 10,000 testing images.
test_iter: 100
# Carry out testing every 500 training iterations.
test_interval: 500
# The base learning rate, momentum and the weight decay of the network.
base_lr: 0.01
momentum: 0.9
weight_decay: 0.0005
# The learning rate policy
lr_policy: "inv"
gamma: 0.0001
power: 0.75
# Display every 100 iterations
display: 100
# The maximum number of iterations
max_iter: 10000
# snapshot intermediate results
snapshot: 5000
snapshot_prefix: "examples/mnist/lenet"
# solver mode: CPU or GPU
solver_mode: GPU #使用gpu进行训练
开始训练网络:
cd $CAFFE_ROOT
./examples/mnist/train_lenet.sh你会看到类似下面的输出:
I1203 net.cpp:66] Creating Layer conv1
I1203 net.cpp:76] conv1 <- data
I1203 net.cpp:101] conv1 -> conv1
I1203 net.cpp:116] Top shape: 20 24 24
I1203 net.cpp:127] conv1 needs backward computation.
。。。。。
I1203 net.cpp:142] Network initialization done.
I1203 solver.cpp:36] Solver scaffolding done.
I1203 solver.cpp:44] Solving LeNet
。。。。。I1203 solver.cpp:84] Testing net
I1203 solver.cpp:111] Test score #0: 0.9897
I1203 solver.cpp:111] Test score #1: 0.0324599
I1203 solver.cpp:126] Snapshotting to lenet_iter_10000
I1203 solver.cpp:133] Snapshotting solver state to lenet_iter_10000.solverstate
I1203 solver.cpp:78] Optimization Done.
结束
运行结构图:
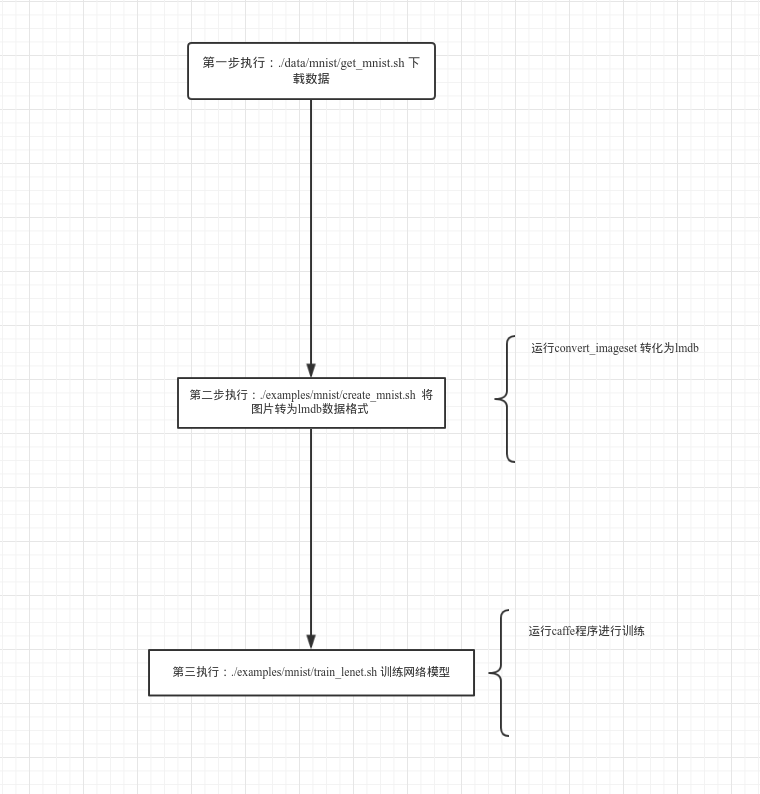
接下来的教程会结合源码详细展开 这三部做了什么 看懂caffe源码
欢迎加入深度学习交流群,群号码:317703095
使用caffe训练mnist数据集 - caffe教程实战(一)的更多相关文章
- 实践详细篇-Windows下使用VS2015编译的Caffe训练mnist数据集
上一篇记录的是学习caffe前的环境准备以及如何创建好自己需要的caffe版本.这一篇记录的是如何使用编译好的caffe做训练mnist数据集,步骤编号延用上一篇 <实践详细篇-Windows下 ...
- ubuntu16.04+caffe训练mnist数据集
1. caffe-master文件夹权限修改 下载的caffe源码编译的caffe-master文件夹貌似没有写入权限,输入以下命令修改: sudo chmod -R 777 ~/caffe-ma ...
- Caffe系列4——基于Caffe的MNIST数据集训练与测试(手把手教你使用Lenet识别手写字体)
基于Caffe的MNIST数据集训练与测试 原创:转载请注明https://www.cnblogs.com/xiaoboge/p/10688926.html 摘要 在前面的博文中,我详细介绍了Caf ...
- windows下使用caffe测试mnist数据集
在win10机子上装了caffe,感谢大神们的帖子,要入坑caffe-windows的朋友们看这里,还有这里,安装下来基本没什么问题. 好了,本博文写一下使用caffe测试mnist数据集的步骤. 1 ...
- 【Mxnet】----1、使用mxnet训练mnist数据集
使用自己准备的mnist数据集,将0-9的bmp图像分别放到0-9文件夹下,然后用mxnet训练. 1.制作rec数据集 (1).制作list
- TensorFlow 训练MNIST数据集(2)—— 多层神经网络
在我的上一篇随笔中,采用了单层神经网络来对MNIST进行训练,在测试集中只有约90%的正确率.这次换一种神经网络(多层神经网络)来进行训练和测试. 1.获取MNIST数据 MNIST数据集只要一行代码 ...
- TensorFlow训练MNIST数据集(1) —— softmax 单层神经网络
1.MNIST数据集简介 首先通过下面两行代码获取到TensorFlow内置的MNIST数据集: from tensorflow.examples.tutorials.mnist import inp ...
- 搭建简单模型训练MNIST数据集
# -*- coding = utf-8 -*- # @Time : 2021/3/16 # @Author : pistachio # @File : test1.py # @Software : ...
- MXNet学习-第一个例子:训练MNIST数据集
一个门外汉写的MXNET跑MNIST的例子,三层全连接层最后验证率是97%左右,毕竟是第一个例子,主要就是用来理解MXNet怎么使用. #导入需要的模块 import numpy as np #num ...
随机推荐
- js如何开发游戏(聊天篇)
公司最近有这方面的需求,期望我们能搞出点有趣的小游戏来帮助公司进行推广,公司没有专门做游戏开发的员工,很不幸这件事情掉到了前端头上. 我记得我以前在学习的时候曾经见过一些厉害的前端工程师编写过一些网页 ...
- 踩坑の SpringMVC文件上传
环境准备 添加两个jar包 commons-fileupload-1.2.2.jar commons-io-2.4.jar 配置要求 在springmvc.xml中配置multipart类型解 ...
- 关系型数据库工作原理-客户端连接管理器(翻译自Coding-Geek文章)
本文翻译自Coding-Geek文章:< How does a relational database work>.原文链接:http://coding-geek.com/how-data ...
- 云计算之路-阿里云上:docker swarm 集群再次出现故障
非常非常抱歉!16:30 ~ 17:00 左右我们用于跑 ASP.NET Core 站点的 docker swarm 集群再次出现宕机,由此给您带来了很大很大的麻烦,恳请您的谅解! 受此次故障影响的站 ...
- [sharepoint]rest api文档库文件上传,下载,拷贝,剪切,删除文件,创建文件夹,修改文件夹属性,删除文件夹,获取文档列表
写在前面 最近对文档库的知识点进行了整理,也就有了这篇文章,当时查找这些接口,并用在实践中,确实废了一些功夫,也为了让更多的人走更少的弯路. 系列文章 sharepoint环境安装过程中几点需要注意的 ...
- 8.String StringBuffer StringBuilder
http://www.cnblogs.com/xiohao/p/4271140.html
- 【网络】 应用&传输层笔记
应用层 应用层常用的协议和各自对应的TCP/UDP端口: DNS TCP/UDP 53 HTTP TCP 80 SMTP TCP 25 POP UDP 110 Telnet TCP 23 DHCP U ...
- java各种概念 Core Java总结
Base: OOA是什么?OOD是什么?OOP是什么?{ oo(object-oriented):基于对象概念,以对象为中心,以类和继承为构造机制,来认识,理解,刻画客观世界和设计,构建相应的软件系统 ...
- runtime.getruntime.availableprocessors
1:获取cpu核心数: Runtime.getRuntime().availableProcessors(); 创建线程池: Executors.newFixedThreadPool(nThreads ...
- lua向文件中写入数据,进行记录
function readfile(path) local file = io.open(path, "r") if file then local content = file: ...