C#采用vony.Html.AIO插件批量爬MM网站图片
一、创建项目
1.创建一个.netframework的控制台项目命名为Crawler
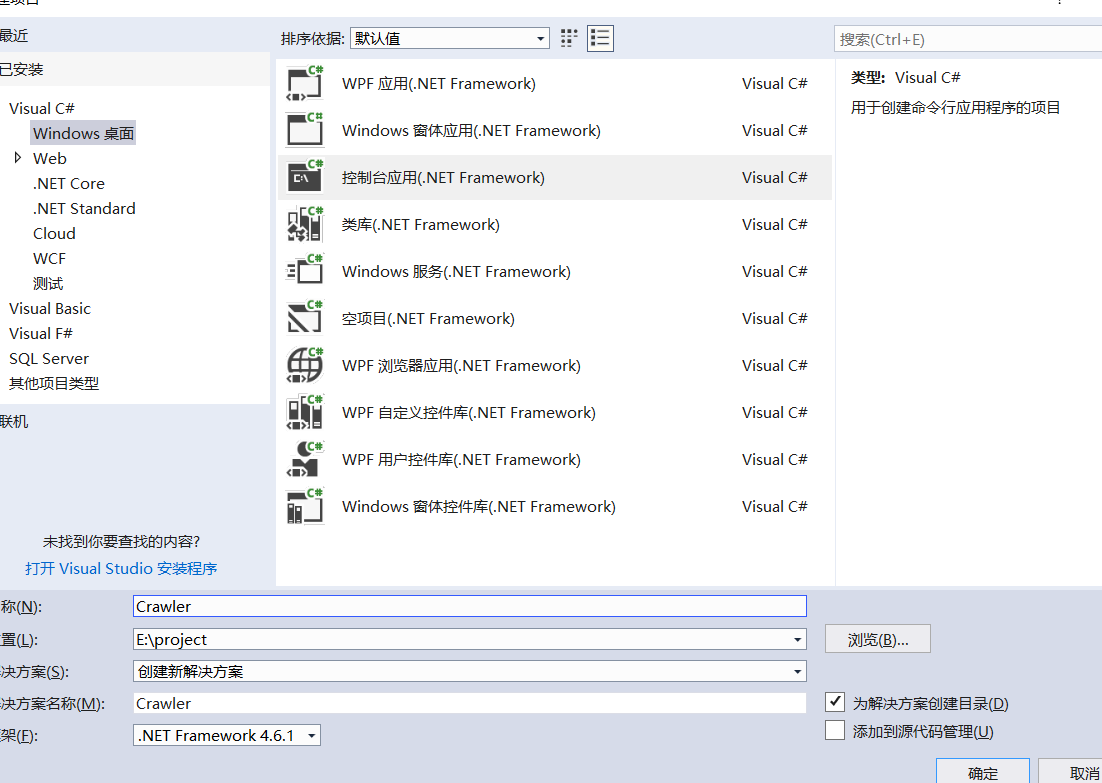
2.安装nuget包搜索名称Ivony.Html.AIO,使用该类库什么方便类似jqury的选择器可以根据类名或者元素类型来匹配元素,无需要写正则表达式。
3.创建一个图片类Image

一、抓取页面图片
1.拿到所有图片页面的地址
本次爬取的网站为https://www.mntup.com/,打开页面进入二级目录https://www.mntup.com/SiWa.html,并查页面看源代码,如下图:

图片页都在class=“dana”的div下面,我们要拿去div中超链接的href,如下格式:
<div class="dana"><a href=/Rosimm/liantiyimeizi_4f4d781d.html title=[Rosi写真]NO.2637_红色吊带高叉连体衣妹子床上狗爬式秀浑圆翘臀撩人诱惑写真38P target=_blank>
[Rosi写真]NO.2637_红色吊带高叉连体衣妹子床上狗爬式秀浑圆翘臀撩人诱惑写真38P <b> <font color=ff0000>2019-02-26</b></font>
</a></div>
首先考虑要拿到所有图片页面的超链接,c#代码下:
//需要定义一个list用来存放所有的页面链接
static List<string> categoryUrl = new List<string>();
//加载url到文档
IHtmlDocument source = new JumonyParser().LoadDocument("https://www.mntup.com/XiuRen.html", System.Text.Encoding.GetEncoding("utf-8"));
//获取所有class=dana的的a标签
var divLinks = source.Find(".dana a");
foreach (var aLink in divLinks)
{
var categoryName = aLink.Attribute("href").Value(); //获取a中的链接
categoryUrl.Add(categoryName);
}
2.打开图片页,发现是带有分页的,那就要获取所有的分页的链接了。分页的地址都在页面当中,所以我们直接匹配就好。
由于每个图片页都有分页地址,所以直接匹配分页地址,C#代码如下:
foreach (var url in categoryUrl)
{
//获取图片也的的文档
IHtmlDocument html = new JumonyParser().LoadDocument($"{address}{url}", System.Text.Encoding.GetEncoding("utf-8"));
//获取每个分页面并下载
var pageLink = html.Find(".page a");
foreach (var alingk in pageLink)
{
string href = alingk.Attribute("href").Value();
Console.WriteLine($"获取分页地址{href}");
}
}
3.所有分页都获取到了,接下来就是要获取页面中的每张图片了,打开页面查看源代码:

观察发现,所有的图片都在class=img的div下面,那就可以从每个分页中直接下载所有的图片了,代码如下:
//获取每一个分页的文档模型
IHtmlDocument htm2 = new JumonyParser().LoadDocument($"{address}{href}", System.Text.Encoding.GetEncoding("utf-8"));
//获取class=img的div下的img标签
var aLink = htm2.Find(".img img");
foreach (var link in aLink)
{
var imgsrc = link.Attribute("src").Value();
Console.WriteLine("获取到图片路径" + imgsrc);
Console.WriteLine($"开始下载图片{imgsrc}>>>>>>>");
DownLoadImg(new Image { Address = address + imgsrc, Title = url });
}
}
图片下载方法如下,为防止下载的时候阻塞主进程,下载采用异步:
/// <summary>
/// 异不下载图片
/// </summary>
/// <param name="image"></param>
async static void DownLoadImg(Image image)
{
using (WebClient client = new WebClient())
{
try
{
int start = image.Address.LastIndexOf("/") + 1;
string fileName = image.Address.Substring(start, image.Address.Length - start);
//图片目录采用页面地址作为文件名
string directory = "c:/images/" + image.Title.Replace("/", "-").Replace("html", "") + "/";
if (!Directory.Exists(directory))
{
Directory.CreateDirectory(directory);
}
await client.DownloadFileTaskAsync(new Uri(image.Address), directory + fileName);
}
catch (Exception)
{
Console.WriteLine($"{image.Address}下载失败");
File.AppendText(@"c:/log.txt");
}
Console.WriteLine($"{image.Address}下载成功");
}
}
三、抓取图片
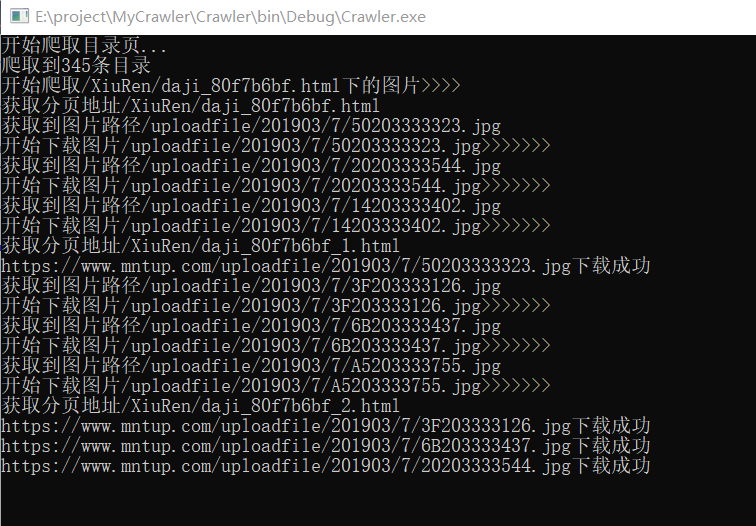
由于编码格式的问题,无法获取到中文标题,所有就采取了页面链接作为目录名称,下面是一张我抓取图片的截图:
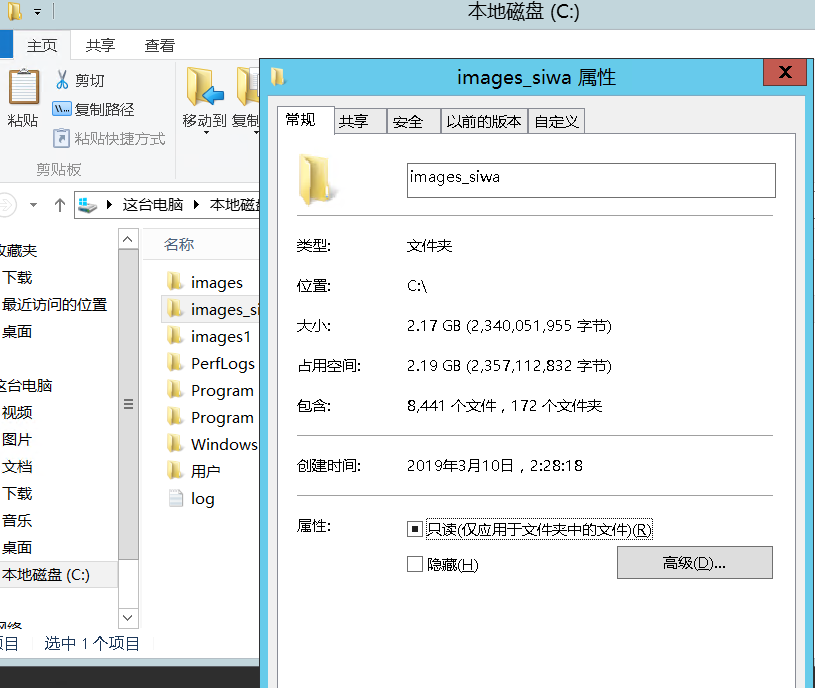
最后的战果:
最后奉上代码如下:https://github.com/peijianmin/MyCrawler.git
C#采用vony.Html.AIO插件批量爬MM网站图片的更多相关文章
- 【Python】批量爬取网站URL测试Struts2-045漏洞
1.概述都懒得写了.... 就是批量测试用的,什么工具里扣出来的POC,然后根据自己的理解写了个爬网站首页URL的代码... #!/usr/bin/env python # -*- coding: u ...
- Python:爬取网站图片并保存至本地
Python:爬取网页图片并保存至本地 python3爬取网页中的图片到本地的过程如下: 1.爬取网页 2.获取图片地址 3.爬取图片内容并保存到本地 实例:爬取百度贴吧首页图片. 代码如下: imp ...
- Python3批量爬取网页图片
所谓爬取其实就是获取链接的内容保存到本地.所以爬之前需要先知道要爬的链接是什么. 要爬取的页面是这个:http://findicons.com/pack/2787/beautiful_flat_ico ...
- 使用Python批量爬取美女图片
运行截图 实列代码: from bs4 import BeautifulSoup import requests,re,os headers = { 'User-Agent': 'Mozilla/5. ...
- 使用ajax爬取网站图片()
以下内容转载自:https://www.makcyun.top/web_scraping_withpython4.html 文章关于网站使用Ajaxj技术加载页面数据,进行爬取讲的很详细 大致步骤如下 ...
- Day11 (黑客成长日记) 爬取网站图片
#导入第三方库# coding:utf-8import requests,re #找到需要爬取的网站'http://www.qqjia.com/sucai/sucai1210.htm' #1>获 ...
- 使用python来批量抓取网站图片
今天"无意"看美女无意溜达到一个网站,发现妹子多多,但是可恨一个page只显示一张或两张图片,家里WiFi也难用,于是发挥"程序猿"的本色,写个小脚本,把图片扒 ...
- webmagic 二次开发爬虫 爬取网站图片
webmagic的是一个无须配置.便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫. webmagic介绍 编写一个简单的爬虫 webmagic的使用文档:http://w ...
- 使用Jsoup爬取网站图片
package com.test.pic.crawler; import java.io.File; import java.io.FileOutputStream; import java.io.I ...
随机推荐
- C++ 模板基础
我们学习使用C++,肯定都要了解模板这个概念.就我自己的理解,模板其实就是为复用而生,模板就是实现代码复用机制的一种工具,它可以实现类型参数化,即把类型定义为参数:进而实现了真正的代码可重用性.模版可 ...
- java语言浅显理解
从厉害的c语言.到经久不衰的java语言.到不太火的安卓和IOS,到当下流行的python,这些都是软件开发中的一员. 之前在传智播客上的免费视频资源上,听了老师对java语言的介绍,感觉挺好了.今天 ...
- SSH X11 MAC
1. X11 for Mac 2. Ubuntu下通过SSH转发X窗口需要具备的条件 原文:http://unix.stackexchange.com/questions/12755/how- ...
- 基于 HTML5 WebGL 的低碳工业园区监控系统
前言 低碳工业园区的建设与推广是我国推进工业低碳转型的重要举措,低碳工业园区能源与碳排放管控平台是低碳工业园区建设的关键环节.如何对园区内的企业的能源量进行采集.计量.碳排放核算,如何对能源消耗和碳排 ...
- Maven学习(八)-- 使用Nexus搭建Maven私服
摘自:http://www.cnblogs.com/xdp-gacl/p/4068967.html 一.搭建nexus私服的目的 为什么要搭建nexus私服,原因很简单,有些公司都不提供外网给项目组人 ...
- iframe跨域动态设置主窗口宽高
Q:在A项目的a页面嵌入一个iframe,src是B项目的b页面,怎样让a页面的高度跟b页面的高度一样? A:解决跨域方案:增加一个A项目的c页面. 操作步骤: 一,a页面的iframe设置: 获取到 ...
- POI实现Excel导入导出
我们知道要创建一张excel你得知道excel由什么组成,比如说sheet也就是一个工作表格,例如一行,一个单元格,单元格格式,单元格内容格式…这些都对应着poi里面的一个类. 一个excel表格: ...
- 向Oracle数据库插入中文乱码解决方法
解决方法: 第一步:sqlplus下执行:select userenv('language') from dual;//查看oracle字符集 注:如果oracle字符集与后台代码设置的 ...
- 如何在Visual Studio和CodeBlocks中反编译C++代码
在Visual Studio中 第一步:打断点 第二步:Debug->Star Debugging 或直接按"F5" 第三步:Debug->Windows->Di ...
- JAVA远程通信的几种选择(RPC,Webservice,RMI,JMS的区别)
RPC(Remote Procedure Call Protocol) RPC使用C/S方式,采用http协议,发送请求到服务器,等待服务器返回结果.这个请求包括一个参数集和一个文本集,通常形成&qu ...