SQLite3源程序分析之查询处理及优化
前言
查询处理及优化是关系数据库得以流行的根本原因,也是关系数据库系统最核心的技术之一。SQLite的查询处理模块很精致,而且很容易移植到不支持SQL的存储引擎(Berkeley DB最新的版本已经将其完整的移植过来)。
查询处理一般来说,包括词法分析、语法分析、语义分析、生成执行计划以及执行计划几个部分。SQLite的词法分析器是手工写的(比较简单),语法分析器由Lemon生成,语义分析主要是进行语义方面的一些检查,比如table是否存在等。而执行计划的生成及执行是最核心的两部分,也是相对比较复杂、有点技术含量的部分。SQLite的执行计划采用了虚拟机的思想,实际上,这种基于虚拟机的思想并非SQLite所独有,但是,SQLite将其发挥到了极致,它生成的执行计划非常详细,而且易读(不得不佩服D. Richard Hipp在编译理论方面的功底)。
1、语法分析——语法树
语法分析的主要任务是对用户输入的SQL语句进行语法检查,然后生成一个包含所有信息的语法树。对于SELECT语句,这个语法树最终由结构体Select表示:
struct Select {
ExprList *pEList; /* The fields of the result 结果的字段 */
u8 op; /* One of: TK_UNION TK_ALL TK_INTERSECT TK_EXCEPT */
char affinity; /* MakeRecord with this affinity for SRT_Set */
u16 selFlags; /* Various SF_* values */
SrcList *pSrc; /* The FROM clause */
Expr *pWhere; /* The WHERE clause */
ExprList *pGroupBy; /* The GROUP BY clause */
Expr *pHaving; /* The HAVING clause */
ExprList *pOrderBy; /* The ORDER BY clause */
Select *pPrior; /* Prior select in a compound select statement 在一个复合选择语句中的优先选择 */
Select *pNext; /* Next select to the left in a compound */
Select *pRightmost; /* Right-most select in a compound select statement 在一个复合选择语句中的最右边的选择*/
Expr *pLimit; /* LIMIT expression. NULL means not used. */
Expr *pOffset; /* OFFSET expression. NULL means not used. */
int iLimit, iOffset; /* Memory registers holding LIMIT & OFFSET counters */
]; /* OP_OpenEphem opcodes related to this select */
};
该结构体中,pEList是结果列的语法树;pSrc为FROM子句的语法树;pWhere为WHERE部分的语法树。
select语法分析最终在sqlite3SelectNew中完成:
Select *sqlite3SelectNew(
Parse *pParse, /* Parsing context 解析上下文 */
ExprList *pEList, /* which columns to include in the result 在结果中包含哪些列 */
SrcList *pSrc, /* the FROM clause -- which tables to scan */
Expr *pWhere, /* the WHERE clause */
ExprList *pGroupBy, /* the GROUP BY clause */
Expr *pHaving, /* the HAVING clause */
ExprList *pOrderBy, /* the ORDER BY clause */
int isDistinct, /* true if the DISTINCT keyword is present */
Expr *pLimit, /* LIMIT value. NULL means not used */
Expr *pOffset /* OFFSET value. NULL means no offset */
){
Select *pNew;
Select standin;
sqlite3 *db = pParse->db;
pNew = sqlite3DbMallocZero(db, sizeof(*pNew) );
assert( db->mallocFailed || !pOffset || pLimit ); /* OFFSET implies LIMIT */
){
pNew = &standin;
memset(pNew, , sizeof(*pNew));
}
){
pEList = sqlite3ExprListAppend(pParse, , sqlite3Expr(db,TK_ALL,));
}
pNew->pEList = pEList;
pNew->pSrc = pSrc;
pNew->pWhere = pWhere;
pNew->pGroupBy = pGroupBy;
pNew->pHaving = pHaving;
pNew->pOrderBy = pOrderBy;
pNew->selFlags = isDistinct ? SF_Distinct : ;
pNew->op = TK_SELECT;
pNew->pLimit = pLimit;
pNew->pOffset = pOffset;
assert( pOffset== || pLimit!= );
pNew->addrOpenEphm[] = -;
pNew->addrOpenEphm[] = -;
pNew->addrOpenEphm[] = -;
if( db->mallocFailed ) {
clearSelect(db, pNew);
if( pNew!=&standin ) sqlite3DbFree(db, pNew);
pNew = ;
}
return pNew;
}
以上函数主要是将之前得到的各个子语法树汇总到Select结构体,并根据该结构,进行语义分析及执行计划的生成等工作。
示例(贯穿全文):
explain select s.sname,c.cname,sc.grade from students s join sc join course c on s.sid=sc.sid and sc.cid = c.cid; |Trace|||||| |Goto|||||| //////////////////////////(1)//////////////////////////// |OpenRead||||||students #打开students表 |OpenRead||||||sc #打开sc表 |OpenRead||||keyinfo(,BINARY,BINARY)||sqlite_autoindex_sc_1 #sc的索引 |OpenRead||||||course #打开course表 |OpenRead||||keyinfo(,BINARY)||sqlite_autoindex_course_1 #course的索引 //////////////////////////(2)////////////////////////////// |Rewind|||||| #将游标p0定位到students表的第一条记录 |Column||||||students.sid #取出第0列,写到r1 |IsNull|||||| |Affinity||||d|| |SeekGe|||||| #将游标p3定位到sc索引>=r1的记录处 |IdxGE|||||| |IdxRowid|||||| |Seek|||||| |Column||||||sc.cid #读取sc.cid到r3 |IsNull|||||| |Affinity||||d|| |SeekGe|||||| #将游标p4定位到course索引>=r3的记录处 |IdxGE|||||| |IdxRowid|||||| |Seek|||||| ///////////////////////////(3)////////////////////////////// |Column||||||students.sname #从游标p0取出第1列 (sname) |Column||||||course.cname #从游标p2取出第1列 (cname) |Column||||||sc.grade #从游标p1取出第2列 (grade) |ResultRow|||||| ///////////////////////////(4)/////////////////////////////// |Next|||||| |Next|||||| |Next|||||| |Close|||||| |Close|||||| |Close|||||| |Close|||||| |Close|||||| //////////////////////////(5)////////////////////////////////// |Halt|||||| |Transaction|||||| |VerifyCookie|||||| |TableLock||||students|| |TableLock||||sc|| |TableLock||||course|| |Goto||||||
该SQL语句生成的语法树如下:
FROM部分:
第一个表项:
表名zName =”stduents”,zAlias=”s”,jointype = 0
第二个表项: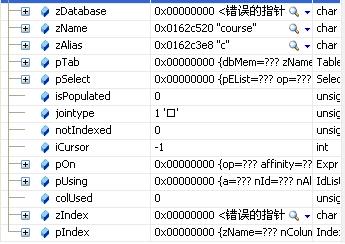
jointype = 1(JT_INNER)
第三个表项:
jointype = 1(JT_INNER)
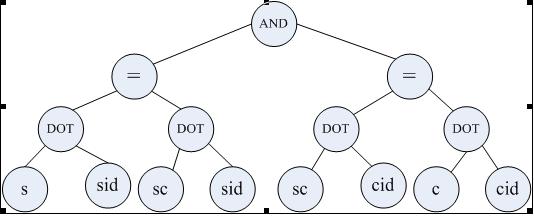
WHERE部分(结点类型为Expr的一棵二叉树):
2、生成执行计划(语法树到OPCODE)
Select的执行计划在sqlite3Select中完成:
int sqlite3Select( Parse *pParse, /* The parser context */ Select *p, /* SELECT语法树 */ SelectDest *pDest /* 如何处理结果集 */ )
该函数先对SQL语句进行语义分析,再进行优化,最后生成执行计划。
对于上面的SQL语句,生成的执行计划(虚拟机opcode)大致分成5部分,前4部分都在sqlite3Select()中生成,它主要调用了以下几个函数:

其中(1)、(2)在sqlite3WhereBegin()中生成,(2)即所谓的查询优化处理;(3)在 selectInnerLoop中生成;(4)在sqlite3WhereEnd中生成;(5)在sqlite3FinishCoding中完成。
1)sqlite3WhereBegin
该函数是查询处理最为核心的函数,它主要完成where部分的优化及相关opcode的生成。
WhereInfo *sqlite3WhereBegin( Parse *pParse, /* The parser context */ SrcList *pTabList, /* A list of all tables to be scanned 要扫描的所有表的列表*/ Expr *pWhere, /* The WHERE clause */ ExprList **ppOrderBy, /* An ORDER BY clause, or NULL */ u16 wctrlFlags /* One of the WHERE_* flags defined in sqliteInt.h */ )
pTabList是由分析器对FROM部分生成的语法树,它包含FROM语句中的表的信息;pWhere是WHERE部分的语法树,它包含WHERE中所有表达式的信息;ppOrderBy对应ORDER BY子句。
SQLite的查询优化简单而精致,在sqlite3WhereBegin函数中,即可完成所有的优化处理。查询优化的基本理念就是嵌套循环(nested loop),SELECT语句的FROM子句的每个表对应一层循环(INSERT和UPDATE语句对应只有一个表)。例如:
SELECT * FROM t1, t2, t3 WHERE ...;
进行如下操作:
foreach row1 in t1 do \ Code generated
foreach row2 in t2 do |-- by sqlite3WhereBegin()
foreach row3 in t3 do /
...
end \ Code generated
end |-- by sqlite3WhereEnd()
end /
而对于每一层的优化,基本的理念就是分析WHERE子句中是否有表达式能够使用该层循环的表的索引。
SQLite有三种基本的扫描策略:
① 全表扫描,这种情况通常出现在没有WHERE子句时;
② 基于索引扫描,这种情况通常出现在表有索引,而且WHERE中的表达式又能够使用该索引的情况;
③ 基本rowid的扫描,这种情况通常出现在WHERE表达式中含有rowid的条件。(该情况实际上也是对表进行扫描,SQLite以rowid为聚簇索引)
第一种情况比较简单,第三种情况与第二种情况没有本质的差别。下面就第二种情况进行详细讨论。
以下为sqlite3WhereBegin的关键代码:
/*分析where子句的所有表达式**如果表达式的形式为X <op> Y,则增加一个Y <op> X形式的虚Term,并在后面进行单独分析*/
exprAnalyzeAll(pTabList, pWC);
WHERETRACE(("*** Optimizer Start ***\n"));
//优化开始
, pLevel=pWInfo->a; i<nTabList; i++, pLevel++){
WhereCost bestPlan; /* Most efficient plan seen so far 迄今为止最有效的计划 */
Index *pIdx; /* Index for FROM table at pTabItem */
int j; /* For looping over FROM tables 从表循环*/
; /* The value of j */
Bitmask m; /* Bitmask value for j or bestJ */
int isOptimal; /* Iterator for optimal/non-optimal search 优化/非优化搜索的迭代器 */
memset(&bestPlan, , sizeof(bestPlan));
bestPlan.rCost = SQLITE_BIG_DBL;
/*进行两次扫描:*/
//如果第一次扫描没有找到优化的扫描策略,此时,isOptimal==0,bestJ==-1,则进行第二次扫描
; isOptimal>= && bestJ<; isOptimal--){
//第一次扫描的mask==0,表示所有表都已经准备好
Bitmask mask = (isOptimal ? : notReady);
assert( (nTabList-iFrom)> || isOptimal );
for(j=iFrom, pTabItem=&pTabList->a[j]; j<nTabList; j++, pTabItem++){
int doNotReorder; /* True if this table should not be reordered 如果该表不应该被重新排序为True */
WhereCost sCost; /* Cost information from best[Virtual]Index() */
ExprList *pOrderBy; /* ORDER BY clause for index to optimize */
//对于左连接和交叉连接,不能改变嵌套的顺序
doNotReorder = (pTabItem->jointype & (JT_LEFT|JT_CROSS))!=;
if( j!=iFrom && doNotReorder ) //如果j==iFrom,仍要进行优化处理(此时,是第一次处理iFrom项)
break;
m = getMask(pMaskSet, pTabItem->iCursor);
){//如果该pTabItem已经进行处理,则不需要再处理
if( j==iFrom )
iFrom++;
continue;
}
pOrderBy = ((i== && ppOrderBy )?*ppOrderBy:);
{
//对一个表(pTabItem),找到它的可用于本次查询的最好的索引,sCost返回对应的代价
bestBtreeIndex(pParse, pWC, pTabItem, mask, pOrderBy, &sCost);
}
&& (j==iFrom || sCost.rCost<bestPlan.rCost)
){
bestPlan = sCost;
bestJ = j; //如果bestJ>=0,表示找到了优化的扫描策略
}
if( doNotReorder ) break;
}//end for
}//end for
WHERETRACE(("*** Optimizer selects table %d for loop %d\n", bestJ,
pLevel-pWInfo->a));
){//不需要进行排序操作
*ppOrderBy = ;
}
//设置该层选用的查询策略
andFlags &= bestPlan.plan.wsFlags;
pLevel->plan = bestPlan.plan;
//如果可以使用索引,则设置索引对应的游标的下标
if( bestPlan.plan.wsFlags & WHERE_INDEXED ){
pLevel->iIdxCur = pParse->nTab++;
}else{
pLevel->iIdxCur = -;
}
notReady &= ~getMask(pMaskSet, pTabList->a[bestJ].iCursor);
//该层对应的FROM的表项,即该层循环是对哪个表进行的操作
pLevel->iFrom = (u8)bestJ;
}
//优化结束
WHERETRACE(("*** Optimizer Finished ***\n"));
优化部分的代码的基本算法如下:
foreach level in all_levels
bestPlan.rCost = SQLITE_BIG_DBL
foreach table in tables that not handled
{
//计算where中表达式能使用其索引的策略及代价rCost
If(sCost.rCost < bestPlan.rCost)
bestPlan = sCost
}
level.plan = bestPlan
该算法本质上是一个贪婪算法(greedy algorithm)。其中,bestBtreeIndex(pParse, pWC, pTabItem, mask, pOrderBy, &sCost)是pParse对应的表针对where子句的表达式分析查询策略的核心函数。
对于之前的示例,经过以上优化处理后,得到的查询策略分3层循环,最外层是students表,全表扫描;中间层是sc表,利用索引sqlite_autoindex_sc_1,即sc的key对应的索引;内层是course表,利用索引sqlite_autoindex_course_1。
之后,开始生成(1)、(2)两部分opcode。
其中(1)的opcode由以下代码生成:
//生成打开表的指令
&& (wctrlFlags & WHERE_OMIT_OPEN)== ){
//pTabItem->iCursor为表对应的游标下标
int op = pWInfo->okOnePass ? OP_OpenWrite : OP_OpenRead;
sqlite3OpenTable(pParse, pTabItem->iCursor, iDb, pTab, op);
}
//生成打开索引的指令
){
Index *pIx = pLevel->plan.u.pIdx;
KeyInfo *pKey = sqlite3IndexKeyinfo(pParse, pIx);
int iIdxCur = pLevel->iIdxCur; //索引对应的游标下标
sqlite3VdbeAddOp4(v, OP_OpenRead, iIdxCur, pIx->tnum, iDb,(char*)pKey, P4_KEYINFO_HANDOFF); VdbeComment((v, "%s", pIx->zName)); }
而(2)的opcode由以下代码生成:
notReady = ~(Bitmask);
; i<nTabList; i++){
//核心代码,从最外层向最内层,为每一层循环生成opcode
notReady = codeOneLoopStart(pWInfo, i, wctrlFlags, notReady);
pWInfo->iContinue = pWInfo->a[i].addrCont;
}
其中codeOneLoopStart(pWInfo, i, wctrlFlags, notReady)函数,根据优化分析得到的结果生成每层循环的opcode:
static Bitmask codeOneLoopStart( WhereInfo *pWInfo, /* Complete information about the WHERE clause */ int iLevel, /* Which level of pWInfo->a[] should be coded */ u16 wctrlFlags, /* One of the WHERE_* flags defined in sqliteInt.h */ Bitmask notReady /* Which tables are currently available */ )
codeOneLoopStart针对5种不同的查询策略,生成各自不同的opcode:
if( pLevel->plan.wsFlags & WHERE_ROWID_EQ ){ //rowid的等值查询
...
}else if( pLevel->plan.wsFlags & WHERE_ROWID_RANGE ){ //rowid的范围查询
...
}else if( pLevel->plan.wsFlags & (WHERE_COLUMN_RANGE|WHERE_COLUMN_EQ) ){ //使用索引的等值/范围查询
...
}if( pLevel->plan.wsFlags & WHERE_MULTI_OR ){ //or
...
}else{ //全表扫描
...
}
其中,全表扫描如下:
static const u8 aStep[] = { OP_Next, OP_Prev };
static const u8 aStart[] = { OP_Rewind, OP_Last };
pLevel->op = aStep[bRev];
pLevel->p1 = iCur;
pLevel->p2 = + sqlite3VdbeAddOp2(v, aStart[bRev], iCur, addrBrk); //生成OP_Rewind/OP_Last指令
pLevel->p5 = SQLITE_STMTSTATUS_FULLSCAN_STEP;
示例中最外层循环students是全表扫描,生成指令7。
其中,利用索引的等值/范围查询:
对于示例:中间循环sc表,用到索引,指令8~14是对应的opcode。
内层循环course表,也用到索引,指令15~21是对应的opcode。
在通用数据库中,连接操作会生成所谓的结果集(用临时表存储)。而SQLite不会生成中间结果集,例如示例中,会分别对students、sc和course表各分配一个游标,每次调用接口sqlite3_step时,游标根据where条件分别定位到各自的记录,然后取出查询输出列的数据,放到用于存放结果的寄存器中(如示例(3)中的opcode)。所以在SQLite中,必须不断调用sqlite3_step才能读取所有记录。
2)selectInnerLoop
该函数主要生成输出结果列的opcode,即示例(3)中的opcode。
3)sqlite3WhereEnd
该函数主要完成嵌套循环的收尾工作的opcode的生成,为每层循环生成OP_Next/OP_Prev,以及关闭表和索引游标的OP_Close。
3、SQLite的代价模型
再看bestBtreeIndex函数,其完成查询代价的计算以及查询策略的确定。
SQLite采用基于代价的优化。根据处理查询时CPU和磁盘I/O的代价,主要考虑以下一些因素:
A、查询读取的记录数;
B、结果是否排序(这可能会导致使用临时表);
C、是否需要访问索引和原表。
static void bestBtreeIndex( Parse *pParse, /* The parsing context */ WhereClause *pWC, /* The WHERE clause */ struct SrcList_item *pSrc, /* The FROM clause term to search */ Bitmask notReady, /* Mask of cursors that are not available */ ExprList *pOrderBy, /* The ORDER BY clause */ WhereCost *pCost /* Lowest cost query plan */ )
该函数的主要工作就是输出pCost,它包含查询策略信息及相应的代价。
其核心算法如下:
//遍历其所有索引,找到一个代价最小的索引
for(; pProbe; pIdx=pProbe=pProbe->pNext){
const unsigned int * const aiRowEst = pProbe->aiRowEst;
double cost; /* Cost of using pProbe */
double nRow; /* Estimated number of rows in result set */
int rev; /* True to scan in reverse order */
;
Bitmask used = ; //该表达式使用的表的位码
int nEq; //可以使用索引的等值表达式的个数
; //如果存在 x IN (SELECT...),则设为true
; //处理IN子句
; //估计需要扫描的表中的元素,100表示需要扫描整个表,范围条件意味着只需要扫描表的某一部分
; //是否需要排序
; //如果对索引中的每个列,需要对应的表进行查询,则为true
/* Determine the values of nEq and nInMul */
//计算nEq和nInMul值
; nEq<pProbe->nColumn; nEq++){
WhereTerm *pTerm; /* A single term of the WHERE clause */
int j = pProbe->aiColumn[nEq];
pTerm = findTerm(pWC, iCur, j, notReady, eqTermMask, pIdx);
) //如果该条件在索引中找不到,则break
break;
wsFlags |= (WHERE_COLUMN_EQ|WHERE_ROWID_EQ);
if( pTerm->eOperator & WO_IN ){
Expr *pExpr = pTerm->pExpr;
wsFlags |= WHERE_COLUMN_IN;
if( ExprHasProperty(pExpr, EP_xIsSelect) ){ //IN (SELECT...)
nInMul *= ;
bInEst = ;
}else if( pExpr->x.pList ){
nInMul *= pExpr->x.pList->nExpr + ;
}
}else if( pTerm->eOperator & WO_ISNULL ){
wsFlags |= WHERE_COLUMN_NULL;
}
used |= pTerm->prereqRight; //设置该表达式使用的表的位码
}
//计算nBound值
if( nEq<pProbe->nColumn ){//考虑不能使用索引的列
int j = pProbe->aiColumn[nEq];
if( findTerm(pWC, iCur, j, notReady, WO_LT|WO_LE|WO_GT|WO_GE, pIdx) ){
WhereTerm *pTop = findTerm(pWC, iCur, j, notReady, WO_LT|WO_LE, pIdx);
WhereTerm *pBtm = findTerm(pWC, iCur, j, notReady, WO_GT|WO_GE, pIdx);//>=
//估计范围条件的代价
whereRangeScanEst(pParse, pProbe, nEq, pBtm, pTop, &nBound);
if( pTop ){
wsFlags |= WHERE_TOP_LIMIT;
used |= pTop->prereqRight;
}
if( pBtm ){
wsFlags |= WHERE_BTM_LIMIT;
used |= pBtm->prereqRight;
}
wsFlags |= (WHERE_COLUMN_RANGE|WHERE_ROWID_RANGE);
}
}else if( pProbe->onError!=OE_None ){//所有列都能使用索引
){
wsFlags |= WHERE_UNIQUE;
}
}
if( pOrderBy ){//处理order by
&& isSortingIndex(pParse,pWC->pMaskSet,pProbe,iCur,pOrderBy,nEq,&rev)
){
wsFlags |= WHERE_ROWID_RANGE|WHERE_COLUMN_RANGE|WHERE_ORDERBY;
wsFlags |= (rev ? WHERE_REVERSE : );
}else{
bSort = ;
}
}
if( pIdx && wsFlags ){
Bitmask m = pSrc->colUsed; //m为src使用的列的位图
int j;
; j<pIdx->nColumn; j++){
int x = pIdx->aiColumn[j];
){
m &= ~(((Bitmask))<<x); //将索引中列对应的位清0
}
}
){//如果索引包含src中的所有列,则只需要查询索引即可
wsFlags |= WHERE_IDX_ONLY;
}else{
bLookup = ;//需要查询原表
}
}
//估计输出行数,同时考虑IN运算
nRow = (double)(aiRowEst[nEq] * nInMul);
>aiRowEst[] ){
nRow = aiRowEst[]/;
nInMul = (int)(nRow / aiRowEst[nEq]);
}
//代价为输出的行数+二分查找的代价
cost = nRow + nInMul*estLog(aiRowEst[]);
//考虑范围条件影响
nRow = (nRow * (;
cost = (cost * (;
//加上排序的代价:cost *log (cost)
if( bSort ){
cost += cost*estLog(cost);
}
//如果只查询索引,则代价减半
){
cost /= (;
}
//如果当前的代价更小
if( (!pIdx || wsFlags) && cost<pCost->rCost ){
pCost->rCost = cost; //代价
pCost->nRow = nRow; //估计扫描的元组数
pCost->used = used; //表达式使用的表的位图
pCost->plan.wsFlags = (wsFlags&wsFlagMask); //查询策略标志(全表扫描,使用索引进行扫描)
pCost->plan.nEq = nEq; //查询策略使用等值表达式个数
pCost->plan.u.pIdx = pIdx; //查询策略使用的索引(全表扫描则为NULL)
}
//如果SQL语句存在INDEXED BY,则只考虑该索引
if( pSrc->pIndex ) break;
/* Reset masks for the next index in the loop */
wsFlagMask = ~(WHERE_ROWID_EQ|WHERE_ROWID_RANGE);
eqTermMask = idxEqTermMask;
}
SQLite的代价模型比较简单,而通用数据库一般是将基于规则的优化和基于代价的优化结合起来,更为复杂。
SQLite3源程序分析之查询处理及优化的更多相关文章
- SQLite3源程序分析之虚拟机
前言 最早的虚拟机可追溯到IBM的VM/370,到上个世纪90年代,在计算机程序设计语言领域又出现一件革命性的事情——Java语言的出现,它与c++最大的不同在于它必须在Java虚拟机上运行.Java ...
- SQLite3源程序分析之分析器的生成
1.概述 Lemon是一个LALR(1)文法分析器生成工具,与bison和yacc类似,是一个可以独立于SQLite使用的开源的分析器生成工具.而且它使用与yacc(bison)不同的语法规则,可以减 ...
- 高性能MySql进化论(十一):常见查询语句的优化
总结一下常见查询语句的优化方式 1 COUNT 1. COUNT的作用 · COUNT(table.filed)统计的该字段非空值的记录行数 · ...
- mysql数据库的优化和查询效率的优化
一.数据库的优化 1.优化索引.SQL 语句.分析慢查询: 2.设计表的时候严格根据数据库的设计范式来设计数据库: 3.使用缓存,把经常访问到的数据而且不需要经常变化的数据放在缓存中,能节约磁盘IO: ...
- SQL Server 2016 查询存储性能优化小结
SQL Server 2016已经发布了有半年多,相信还有很多小伙伴还没有开始使用,今天我们来谈谈SQL Server 2016 查询存储性能优化,希望大家能够喜欢 作为一个DBA,排除SQL Ser ...
- 0613pt-query-digest分析慢查询日志
转自http://www.jb51.net/article/107698.htm 这篇文章主要介绍了关于MySQL慢查询之pt-query-digest分析慢查询日志的相关资料,文中介绍的非常详细,对 ...
- 通过force index了解的MySQL查询的性能优化
查询是数据库技术中最常用的操作.查询操作的过程比较简单,首先从客户端发出查询的SQL语句,数据库服务端在接收到由客户端发来的SQL语句后, 执行这条SQL语句,然后将查询到的结果返回给客户端.虽然过程 ...
- Mysql系列(五)—— 分页查询及问题优化
一.用法 在Mysql中分页查询使用关键字limit.limit的语法如下: SELECT * FROM tbl LIMIT 5,10; # Retrieve rows 6-15 limit关键字带有 ...
- 如何提高sql查询性能到达优化程序的目的
1.关于SQL查询效率,100w数据 SQL查询效率 step by step -- setp 1.-- 建表create table t_userinfo(userid int identity(1 ...
随机推荐
- ASP.NET Core 中文文档 第四章 MVC(2.3)格式化响应数据
原文:Formatting Response Data 作者:Steve Smith 翻译:刘怡(AlexLEWIS) 校对:许登洋(Seay) ASP.NET Core MVC 内建支持对相应数据( ...
- 学习EF之贪婪加载和延迟加载(1)
从暑假开始接触code first以来,一直感觉很好用,主要在于开发过程中以业务为中心可以随时修改数据模型生成数据库,还有一个原因就是查询起来很方便 这里找了一个以前database first的一段 ...
- 数据结构:堆排序 (python版) 小顶堆实现从大到小排序 | 大顶堆实现从小到大排序
#!/usr/bin/env python # -*- coding:utf-8 -*- ''' Author: Minion-Xu 小堆序实现从大到小排序,大堆序实现从小到大排序 重点的地方:小堆序 ...
- Java多线程整理(li)
目录: 1.volatile变量 2.Java并发编程学习 3.CountDownLatch用法 4.CyclicBarrier使用 5.BlockingQueue使用 6.任务执行器Executor ...
- Ubantu【第一篇】:Ubantu中openssh连接
h3 { color: rgb(255, 255, 255); background-color: rgb(30,144,255); padding: 3px; margin: 10px 0px } ...
- 自己实现一个简易web服务器
一个web服务器是网络应用中最基础的环节. 构建需要理解三个内容: 1.http协议 2.socket类 3.服务端实现原理 1.1 HTTP http请求 一般一个http请求包括以下三个部分: 1 ...
- Oracle Sales Cloud:报告和分析(BIEE)小细节1——创建双提示并建立关联(例如,部门和子部门提示)
Oracle Sales Cloud(Oracle 销售云)是一套基于Oracle云端的客户商机管理系统,通过提供丰富的功能来帮助提高销售效率,更好地去了解客户,发现和追踪商机,为最终的销售成交 (d ...
- 利用Sharding-Jdbc实现分表
你们团队使用SpringMVC+Spring+JPA框架,快速开发了一个NB的系统,上线后客户订单跟雪花一样纷沓而来. 慢慢地,你的心情开始变差,因为客户和产品的抱怨越来越频繁,抱怨的最多的一个问题就 ...
- Maven:jar 下载相关的问题
在使用Maven下载jar包时,会遇到一些问题,如何解决他们呢? 1.仓库里有jar 包,更新Maven时报仓库里找不到jar包的错误 这个问题,时常在版本有大的变动时出现.(例如:新增加了一些fea ...
- Java线程并发:知识点
Java线程并发:知识点 发布:一个对象是使它能够被当前范围之外的代码所引用: 常见形式:将对象的的引用存储到公共静态域:非私有方法中返回引用:发布内部类实例,包含引用. 逃逸:在对象尚未准备 ...