Python HTTP库requests中文页面乱码解决方案!
http://www.cnblogs.com/bitpeng/p/4748872.html
Python中文乱码,是一个很大的坑,自己不知道在这里遇到多少问题了。还好通过自己不断的总结,现在遇到乱码的情况越来越少,就算出现,一般也能快速解决问题。这个问题,我七月就解决了,今天总结出来,和朋友一起分享。
最近写过好几个爬虫,熟悉了下python requests库的用法,这个库真的Python的官方api接口好用多了。美中不足的是:这个库好像对中文的支持不是很友好,有些页面会出现乱码,然后换成urllib后,问题就没有了。由于requests库最终使用的是urllib3作为底层传输适配器,requests只是把urllib3库读取的原始进行人性化的处理,所以问题requests库本身上!于是决定阅读库源码,解决该中文乱码问题;一方面,也是希望加强自己对HTTP协议、Python的理解。
先是按照api接口,一行行阅读代码,尝试了解问题出在哪里!真个过程进展比较慢,我大概花了5天左右的时间,通读了该库的源代码。阅读代码过程中,有不懂的地方,就自己打印日志信息,以帮助理解。
最后我是这样发现问题所在的!

>>> req = requests.get('http://www.jd.com')
>>> req
<Response [200]>
>>> print req.text[:100]
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 770 <==> ISO-8859-1
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 781 <==> ISO-8859-1
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>¾©¶«(JD.COM)-×ÛºÏÍø¹ºÊ×Ñ¡-ÕýÆ·µÍ¼Û¡¢Æ·ÖÊ
# 这里出现了乱码
>>> dir(req)
['__attrs__', '__bool__', '__class__', '__delattr__', '__dict__', '__doc__', '__format__', '__getattribute__', '__getstate__', '__hash__', '__init__', '__iter__', '__module__', '__new__', '__nonzero__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_content', '_content_consumed', 'apparent_encoding', 'close', 'connection', 'content', 'cookies', 'elapsed', 'encoding', 'headers', 'history', 'is_redirect', 'iter_content', 'iter_lines', 'json', 'links', 'ok', 'raise_for_status', 'raw', 'reason', 'request', 'status_code', 'text', 'url']
req有content属性,还有text属性,我们看看content属性:
>>> print req.content[:100]
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>¾©¶«(JD.COM)-؛ºЍ닗ѡ-ֽƷµͼۡ¢Ʒ
>>>
>>>
>>> print req.content.decode('gbk')[:100]
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>京东(JD.COM)-综合网购首选-正品低价、品质保障、配送及时、轻松购物!</
## 由于该页面时gbk编码的,而Linux是utf-8编码,所以打印肯定是乱码,我们先进行解码。就能正确显示了。
可是,text属性,按照此种方式,并不可行!
>>> print req.text[:100]
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 770 <==> ISO-8859-1
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 781 <==> ISO-8859-1
<!DOCTYPE html>
<html>
<head>
<meta charset="gbk" />
<title>¾©¶«(JD.COM)-×ÛºÏÍø¹ºÊ×Ñ¡-ÕýÆ·µÍ¼Û¡¢Æ·ÖÊ
>>> print req.text.decode('gbk')[:100]
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 770 <==> ISO-8859-1
FILE: /usr/lib/python2.7/dist-packages/requests/models.pyc, LINE: 781 <==> ISO-8859-1
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
UnicodeEncodeError: 'ascii' codec can't encode characters in position 60-63: ordinal not in range(128)
# 对text属性进行解码,就会出现错误。
让我们来看看,这两个属性的源码:
# /requests/models.py
@property
def content(self):
"""Content of the response, in bytes.""" if self._content is False:
# Read the contents.
try:
if self._content_consumed:
raise RuntimeError(
'The content for this response was already consumed') if self.status_code == 0:
self._content = None
else:
self._content = bytes().join(self.iter_content(CONTENT_CHUNK_SIZE)) or bytes() except AttributeError:
self._content = None self._content_consumed = True
# don't need to release the connection; that's been handled by urllib3
# since we exhausted the data.
return self._content
# requests/models.py
@property
def text(self):
"""Content of the response, in unicode. If Response.encoding is None, encoding will be guessed using
``chardet``. The encoding of the response content is determined based solely on HTTP
headers, following RFC 2616 to the letter. If you can take advantage of
non-HTTP knowledge to make a better guess at the encoding, you should
set ``r.encoding`` appropriately before accessing this property.
""" # Try charset from content-type
content = None
encoding = self.encoding if not self.content:
return str('') # Fallback to auto-detected encoding.
if self.encoding is None:
encoding = self.apparent_encoding # Decode unicode from given encoding.
try:
content = str(self.content, encoding, errors='replace')
except (LookupError, TypeError):
# A LookupError is raised if the encoding was not found which could
# indicate a misspelling or similar mistake.
#
# A TypeError can be raised if encoding is None
#
# So we try blindly encoding.
content = str(self.content, errors='replace') return content
看看注和源码知道,content是urllib3读取回来的原始字节码,而text不过是尝试对content通过编码方式解码为unicode。jd.com 页面为gbk编码,问题就出在这里。
>>> req.apparent_encoding;req.encoding'GB2312'
'ISO-8859-1'
这里的两种编码方式和页面编码方式不一致,而content却还尝试用错误的编码方式进行解码。肯定会出现问题!
我们来看看,req的两种编码方式是怎么获取的:
# rquests/models.py
@property
def apparent_encoding(self):
"""The apparent encoding, provided by the chardet library"""
return chardet.detect(self.content)['encoding']
顺便说一下:chardet库监测编码不一定是完全对的,只有一定的可信度。比如jd.com页面,编码是gbk,但是检测出来却是GB2312,虽然这两种编码是兼容的,但是用GB2312区解码gbk编码的网页字节串是会有运行时错误的!
获取encoding的代码在这里:
# requests/adapters.py
def build_response(self, req, resp):
"""Builds a :class:`Response <requests.Response>` object from a urllib3
response. This should not be called from user code, and is only exposed
for use when subclassing the
:class:`HTTPAdapter <requests.adapters.HTTPAdapter>` :param req: The :class:`PreparedRequest <PreparedRequest>` used to generate the response.
:param resp: The urllib3 response object.
"""
response = Response() # Fallback to None if there's no status_code, for whatever reason.
response.status_code = getattr(resp, 'status', None) # Make headers case-insensitive.
response.headers = CaseInsensitiveDict(getattr(resp, 'headers', {})) # Set encoding.
response.encoding = get_encoding_from_headers(response.headers)
# .......
通过get_encoding_from_headers(response.headers)函数获取编码,我们再来看看这个函数!
# requests/utils.py
def get_encoding_from_headers(headers):
"""Returns encodings from given HTTP Header Dict. :param headers: dictionary to extract encoding from.
""" content_type = headers.get('content-type') if not content_type:
return None content_type, params = cgi.parse_header(content_type) if 'charset' in params:
return params['charset'].strip("'\"") if 'text' in content_type:
return 'ISO-8859-1'
发现了吗?程序只通过http响应首部获取编码,假如响应中,没有指定charset, 那么直接返回'ISO-8859-1'。
我们尝试进行抓包,看看http响应内容是什么:
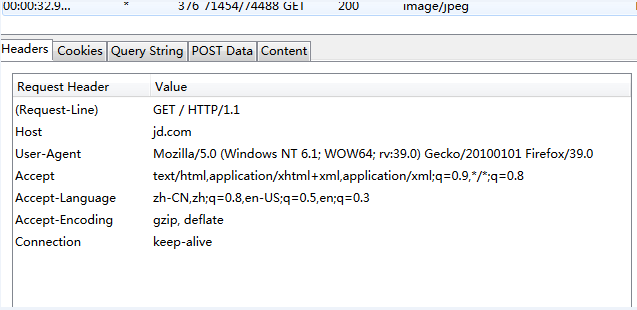

可以看到,reqponse header只指定了type,但是没有指定编码(一般现在页面编码都直接在html页面中)。所有该函数就直接返回'ISO-8859-1'。
可能大家会问:作者为什么要默认这样处理呢?这是一个bug吗?其实,作者是严格http协议标准写这个库的,《HTTP权威指南》里第16章国际化里提到,如果HTTP响应中Content-Type字段没有指定charset,则默认页面是'ISO-8859-1'编码。这处理英文页面当然没有问题,但是中文页面,就会有乱码了!
解决方案:
找到了问题所在,我们现在有两种方式解决该问题。
1. 修改get_encoding_from_headers函数,通过正则匹配,来检测页面编码。由于现在的页面都在HTML代码中指定了charset,所以通过正则式匹配的编码方式是完全正确的。
2. 由于content是HTTP相应的原始字节串,所以我们需要直接可以通过使用它。把content按照页面编码方式解码为unicode!
转载时注:3.reponse.json()方法也有这个问题,解决方法,就是json.dumps(response.content)
Python HTTP库requests中文页面乱码解决方案!的更多相关文章
- requests中文页面乱码解决方案【转】
requests中文页面乱码解决方案! 请给作者点赞 --> 原文链接 Python中文乱码,是一个很大的坑,自己不知道在这里遇到多少问题了.还好通过自己不断的总结,现在遇到乱码的情况越来越 ...
- css中文字体乱码解决方案
css中文字体乱码解决方案:把css编码和html页面编码统一起来.如果html页面是utf-8.css.js也统一成utf-8编码.还有一个避免中文乱码的办法就是把中文字体写成英文来表示 css中文 ...
- asp.net——地址栏传递中文参数乱码解决方案
地址栏传递中文参数乱码解决方案: 很多人在使用地址栏传递参数的时候都会遇到一个麻烦的问题(参数为中文时乱码了),那要怎么解决呢? 其实解决这个问题也不怎么难,无非就是给要传递的中文参数一个编码解码的过 ...
- g++编译后中文显示乱码解决方案(c++)
g++编译后中文显示乱码解决方案 环境:Windows 10 专业版 GCC版本:5.3.0 测试代码: 1 #include <iostream> 2 using namespace ...
- python第三方库requests简单介绍
一.发送请求与传递参数 简单demo: import requests r = requests.get(url='http://www.itwhy.org') # 最基本的GET请求 print(r ...
- Python 标准库 BaseHTTPServer 中文翻译
Python 标准库 BaseHTTPServer 中文翻译. 注意: BaseHTTPServer模块在Python3中已被合并到http.server,当转换你的资源为 Python3 时 2to ...
- Hive中文注释乱码解决方案(2)
本文来自网易云社区 作者:王潘安 执行阶段 launchTask 回到Driver类的runInternal方法,看以下执行过程.在runInternal方法中,执行过程调用了execute方法 ...
- python 标准库 -- requests
一. 安装 $ pip install requests requests 并不是python 标准库, 但为了汇总方便, 将其放置于此. 二. 用法 requests.get() : GET 请求 ...
- linux系统挂载U盘,中文文件名乱码解决方案
本人(壮壮熊)所用系统:ubuntu 12.4 今天在使用mount指令挂在硬盘时,出现令人头疼的中文文件名乱码. 问题: 使用mount /dev/sdb1 /media指令挂在第二颗硬盘的第一个分 ...
随机推荐
- x264 n-th pass编码时候Stats文件的含义
x264 n-th pass(一般是2pass)编码时所用的文件包括下述x264参数生成.stats文件 options: 1280x816 fps=2997/125 timebase=125/299 ...
- Spark SQL官方文档阅读--待完善
1,DataFrame是一个将数据格式化为列形式的分布式容器,类似于一个关系型数据库表. 编程入口:SQLContext 2,SQLContext由SparkContext对象创建 也可创建一个功能更 ...
- JS中回调函数的写法
<!DOCTYPE HTML> <html><head> <meta charset="GBK" /><title>回 ...
- 【一天一道LeetCode】#87. Scramble String
一天一道LeetCode 本系列文章已全部上传至我的github,地址:ZeeCoder's Github 欢迎大家关注我的新浪微博,我的新浪微博 欢迎转载,转载请注明出处 (一)题目 Given a ...
- ARM v7汇编与相关练习
程序入口: _startc 语言入口: main@: 注释;main: 标签;伪指令: 给汇编器读的指令;.global main ...
- 《Oracle Applications DBA 基础》- 9 - Concurrent Processing
来自:http://www.itpub.net/thread-1411293-1-4.html <Oracle Applications DBA 基础>- 9 - Concurrent P ...
- 漫谈程序员(十八)windows中的命令subst
漫谈程序员(十八)windows中的命令subst 用法格式 一.subst [盘符] [路径] 将指定的路径替代盘符,该路径将作为驱动器使用 二.subst /d 解除替代 三.不加任何参数键入 ...
- 开发资源库(repositiory)
1.. 52研发网MTK软件 2.一流研发 3. android+MTK/华为的源代码及资料库(CryToCry96) 点击打开链接 4.android+MTK/华为/联想的源代码及资料库(lucka ...
- FFMPEG列出DirectShow支持的设备
FFMPEG列出dshow支持的设备: ffmpeg -list_devices true -f dshow -idummy 举例: 采集摄像头和麦克风 ffmpeg -f dshow -i vide ...
- NumberProgressBar开源项目学习
1.概述 多看多学涨姿势, github真是个宝库 这个项目主要是实现数字进度条效果 github地址在https://github.com/daimajia/NumberProgressBar 感谢 ...