[翻译] softmax和softmax_cross_entropy_with_logits的区别
翻译自:https://stackoverflow.com/questions/34240703/whats-the-difference-between-softmax-and-softmax-cross-entropy-with-logits
问题:
在Tensorflow官方文档中,他们使用一个关键词,称为logits。这个logits是什么?比如说在API文档中有很多方法(methods),经常像下面这么写:
tf.nn.softmax(logits, name=None)
另外一个问题是,有2个方法我不知道该怎么区分,它们是:
tf.nn.softmax(logits, name=None)
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
它们之间的区别是什么?
回答:
简短版本:
假设你有2个tensors,其中y_hat包含每个类预测的得分(比如说,从y = W*x +b计算得到),y_true包含one-hot编码后的正确的label。
y_hat = ... # Predicted label, e.g. y = tf.matmul(X, W) + b
y_true = ... # True label, one-hot encoded
如果你将y_hat的得分解释为未归一化的log概率,那么它们就是logits。
另外,总的交叉熵损失可以用如下方式计算得到:
y_hat_softmax = tf.nn.softmax(y_hat)
total_loss = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), [1]))
从本质上来说,与用softmax_cross_entropy_with_logits()函数计算得到的总的交叉熵损失是一样的,计算方法为:
total_loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true))
完整版:
举个例子,我们创建一个2x3大小的y_hat,其中行对应着训练样本,列对应类别。因此,这里有2个训练样本和3个类别。
import tensorflow as tf
import numpy as np sess = tf.Session() # Create example y_hat.
y_hat = tf.convert_to_tensor(np.array([[0.5, 1.5, 0.1],[2.2, 1.3, 1.7]]))
sess.run(y_hat)
# array([[ 0.5, 1.5, 0.1],
# [ 2.2, 1.3, 1.7]])
注意到这些值并没有归一化(每一行加起来并不等于1)。为了归一化这些数,我们可以使用softmax函数,这个函数的输入就是未归一化的log概率(也称为logits),输出是归一化的线性概率。
y_hat_softmax = tf.nn.softmax(y_hat)
sess.run(y_hat_softmax)
# array([[ 0.227863 , 0.61939586, 0.15274114],
# [ 0.49674623, 0.20196195, 0.30129182]])
完全理解softmax输出的内容是很重要的。下面我将展示一个表格来更加清楚地解释上面的输出。从表格中可以看出来,训练样本实例1属于类别2的概率是0.619,每个训练样本实例的类概率被归一化,所有每一行的和是1.0。
Pr(Class 1) Pr(Class 2) Pr(Class 3)
--------------------------------------
Training instance 1 | 0.227863 | 0.61939586 | 0.15274114
Training instance 2 | 0.49674623 | 0.20196195 | 0.30129182
现在我们有了每个训练样本在每个类上的概率,我们可以对每一行使用argmax()来产生一个最终的分类结果。从上面的表格上来看,我们可以判断出训练样本实例1属于类别2,训练样本实例2属于类别1。
那么,这些分类正确么?我们需要根据训练样本正确的标签来衡量。你需要一个one-hot编码的y_true数组,其中每一行表示训练样本实例,每一列表示类别。下面我将创建一个例子,y_true为one-hot编码的数组,其中对于训练样本1正确的标签是类别2,对于训练样本2正确的标签是类别3。
y_true = tf.convert_to_tensor(np.array([[0.0, 1.0, 0.0],[0.0, 0.0, 1.0]]))
sess.run(y_true)
# array([[ 0., 1., 0.],
# [ 0., 0., 1.]])
y_hat_softmax的概率分布接近y_true的概率分布么?我们可以使用交叉熵损失( cross-entropy loss)来衡量错误程度。
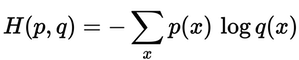
根据下面的式子,我们可以计算出每一行的交叉熵损失。从下面的结果中可以看出训练样本1的损失为0.479,训练样本2的损失比较高,是1.200。这个结果是有道理的,因为y_hat_softmax显示训练样本1的最高概率是类别2,与正确标签y_true匹配,而训练样本2的最高概率预测为类别1,与实际标签(类别3)不匹配。
loss_per_instance_1 = -tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1])
sess.run(loss_per_instance_1)
# array([ 0.4790107 , 1.19967598])
我们想要的是训练集上的所有的loss,因此我们需要将每个训练样本的loss加起来,如下:
total_loss_1 = tf.reduce_mean(-tf.reduce_sum(y_true * tf.log(y_hat_softmax), reduction_indices=[1]))
sess.run(total_loss_1)
# 0.83934333897877944
使用softmax_cross_entropy_with_logits()
我们也可以使用tf.nn.softmax_cross_entropy_with_logits()函数来计算整个交叉熵损失,代码如下:
loss_per_instance_2 = tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true)
sess.run(loss_per_instance_2)
# array([ 0.4790107 , 1.19967598]) total_loss_2 = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(y_hat, y_true))
sess.run(total_loss_2)
# 0.83934333897877922
注意到,total_loss_1和total_loss_2计算得到的结果是基本一样的(有一点点小的差别)。然而,还是建议使用第二种方法,原因是1)代码量更少,2)方法二的内部考虑到了一些边界情况,不容易产生错误。
[翻译] softmax和softmax_cross_entropy_with_logits的区别的更多相关文章
- PyTorch学习笔记——softmax和log_softmax的区别、CrossEntropyLoss() 与 NLLLoss() 的区别、log似然代价函数
1.softmax 函数 Softmax(x) 也是一个 non-linearity, 但它的特殊之处在于它通常是网络中一次操作. 这是因为它接受了一个实数向量并返回一个概率分布.其定义如下. 定义 ...
- sigmoid和softmax的应用意义区别
转载自:https://baijiahao.baidu.com/s?id=1636737136973859154&wfr=spider&for=pc写的很清楚,并举例佐证,容易理解,推 ...
- Difference between nn.softmax & softmax_cross_entropy_with_logits & softmax_cross_entropy_with_logits_v2
nn.softmax 和 softmax_cross_entropy_with_logits 和 softmax_cross_entropy_with_logits_v2 的区别 You have ...
- CNKI翻译助手-连接数据库失败
IP并发数限制,老师说西工大的CNKI才20个并发指标,HPU自不必说.但是我略表怀疑,这只是翻译助手而已,就像百度翻译和百度数据库的区别,如何验证呢?去校外用该助手,如果能用,那么就不是IP并发限制 ...
- 你真的了解word-wrap和word-break的区别吗?
这两个东西是什么,我相信至今还有很多人搞不清,只会死记硬背的写一个word-wrap:break-word;word-break:break-all;这样的东西来强制断句,又或者是因为这两个东西实在是 ...
- 你真的了解word-wrap和word-break的区别吗? (转载)
这两个东西是什么,我相信至今还有很多人搞不清,只会死记硬背的写一个word-wrap:break-word;word-break:break-all;这样的东西来强制断句,又或者是因为这两个东西实在是 ...
- Pytorch之CrossEntropyLoss() 与 NLLLoss() 的区别
(三)PyTorch学习笔记——softmax和log_softmax的区别.CrossEntropyLoss() 与 NLLLoss() 的区别.log似然代价函数 pytorch loss fun ...
- word-wrap和word-break的区别吗?
word-wrap: css的 word-wrap 属性用来标明是否允许浏览器在单词内进行断句,这是为了防止当一个字符串太长而找不到它的自然断句点时产生溢出现象. word-break: css的 w ...
- softmax、cross entropy和softmax loss学习笔记
之前做手写数字识别时,接触到softmax网络,知道其是全连接层,但没有搞清楚它的实现方式,今天学习Alexnet网络,又接触到了softmax,果断仔细研究研究,有了softmax,损失函数自然不可 ...
随机推荐
- C语言最后一次作业--总结报告
1.当初你是如何做出选择计算机专业的决定的? 经过一个学期,你的看法改变了么,为什么? 你觉得计算机是你喜欢的领域吗,它是你擅长的领域吗? 为什么? 当时选择计算机专业,是基于自己的高考分数和想出省的 ...
- mysql学习第一天
Mysql语句语法 一.数据库定义语句(DDL) 1.alter database 语法 alter database 用于更改数据库的全局特性,这些特性存储在数据库目录中的db.opt文件中.要使用 ...
- dom4j 最常用最简单的用法(转)
要使用dom4j读写XML文档,需要先下载dom4j包,dom4j官方网站在 http://www.dom4j.org/目前最新dom4j包下载地址:http://nchc.dl.sourceforg ...
- struct2_拦截器知识点.
Struts2拦截器原理: Struts2拦截器的实现原理相对简单,当请求struts2的action时,Struts 2会查找配置文件,并根据其配置实例化相对的拦截器对象,然后串成一个列表,最后一个 ...
- @Cacheable的实现原理
如果你用过Spring Cache,你一定对这种配置和代码不陌生: <cache:annotation-driven cache-manager="cacheManager" ...
- 2018.3.29 div内容格式设置
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> ...
- Bate版敏捷冲刺每日报告--day1
1 团队介绍 团队组成: PM:齐爽爽(258) 小组成员:马帅(248),何健(267),蔡凯峰(285) Git链接:https://github.com/WHUSE2017/C-team 2 ...
- java实现同步的两种方式
同步是多线程中的重要概念.同步的使用可以保证在多线程运行的环境中,程序不会产生设计之外的错误结果.同步的实现方式有两种,同步方法和同步块,这两种方式都要用到synchronized关键字. 给一个方法 ...
- bzoj千题计划244:bzoj3730: 震波
http://www.lydsy.com/JudgeOnline/problem.php?id=3730 点分树内对每个节点动态维护2颗线段树 线段树以距离为下标,城市的价值为权值 对于节点x的两棵线 ...
- python 面向对象之封装与类与对象
封装 一,引子 从封装本身的意思去理解,封装就好像是拿来一个麻袋,把小猫,小狗,小王八,小老虎一起装进麻袋,然后把麻袋封上口子.照这种逻辑看,封装='隐藏',这种理解是相当片面的 二,先看如何隐藏 在 ...