数据库常用的事务隔离级别和原理?&&mysql-Innodb事务隔离级别-repeatable read详解
转载地址:https://baijiahao.baidu.com/s?id=1611918898724887602&wfr=spider&for=pc
https://blog.csdn.net/qq_38545713/article/details/79779265
什么是事务隔离?
任何支持事务的数据库,都必须具备四个特性,分别是:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability),也就是我们常说的事务ACID,这样才能保证事务((Transaction)中数据的正确性。
而事务的隔离性就是指,多个并发的事务同时访问一个数据库时,一个事务不应该被另一个事务所干扰,每个并发的事务间要相互进行隔离。
如果没有事务隔离,会出现什么样的情况呢?
假设我们现在有这样一张表(T),里面记录了很多牛人的名字,我们不进行事务的隔离看看会发生什么呢?
第一天,事务A访问了数据库,它干了一件事情,往数据库里加上了新来的牛人的名字,但是没有提交事务。
insert into T values (4, '牛D');
这时,来了另一个事务B,他要查询所有牛人的名字。
select Name from T;
这时,如果没有事务之间没有有效隔离,那么事务B返回的结果中就会出现“牛D”的名字。这就是“脏读(dirty read)”。
第二天,事务A访问了数据库,他要查看ID是1的牛人的名字,于是执行了
select Name from T where ID = 1;
这时,事务B来了,因为ID是1的牛人改名字了,所以要更新一下,然后提交了事务。
update T set Name = '不牛' where ID = 1;
接着,事务A还想再看看ID是1的牛人的名字,于是又执行了
select Name from T where ID = 1;
结果,两次读出来的ID是1的牛人名字竟然不相同,这就是不可重复读(unrepeatable read)。

第三天,事务A访问了数据库,他想要看看数据库的牛人都有哪些,于是执行了
select * from T;
这时候,事务B来了,往数据库加入了一个新的牛人。
insert into T values(4, '牛D');
这时候,事务A忘了刚才的牛人都有哪些了,于是又执行了。
select * from T;
结果,第一次有三个牛人,第二次有四个牛人。
相信这个时候事务A就蒙了,刚才发生了什么?这种情况就叫“幻读(phantom problem)”。

很多人容易搞混不可重复读和幻读,确实这两者有些相似。但不可重复读重点在于update和delete,而幻读的重点在于insert。
避免不可重复读需要锁行就行
避免幻影读则需要锁表
如果使用锁机制来实现这两种隔离级别,在可重复读中,该sql第一次读取到数据后,就将这些数据加锁,其它事务无法修改这些数据,就可以实现可重复 读了。但这种方法却无法锁住insert的数据,所以当事务A先前读取了数据,或者修改了全部数据,事务B还是可以insert数据提交,这时事务A就会 发现莫名其妙多了一条之前没有的数据,这就是幻读,不能通过行锁来避免。需要Serializable隔离级别 ,读用读锁,写用写锁,读锁和写锁互斥,这么做可以有效的避免幻读、不可重复读、脏读等问题,但会极大的降低数据库的并发能力。
所以说不可重复读和幻读最大的区别,就在于如何通过锁机制来解决他们产生的问题。
为了防止出现脏读、不可重复读、幻读等情况,我们就需要根据我们的实际需求来设置数据库的隔离级别。
数据库都有哪些隔离级别呢?
一般的数据库,都包括以下四种隔离级别:
读未提交(Read Uncommitted)读提交(Read Committed)可重复读(Repeated Read)串行化(Serializable)如何使用这些隔离级别,那就需要根据业务的实际情况来进行判断了。
我们接下来就看看这四个隔离级别的具体情况
读未提交(Read Uncommitted)
读未提交,顾名思义,就是可以读到未提交的内容。
因此,在这种隔离级别下,查询是不会加锁的,也由于查询的不加锁,所以这种隔离级别的一致性是最差的,可能会产生“脏读”、“不可重复读”、“幻读”。
如无特殊情况,基本是不会使用这种隔离级别的。
读提交(Read Committed)
读提交,顾名思义,就是只能读到已经提交了的内容。
这是各种系统中最常用的一种隔离级别,也是SQL Server和Oracle的默认隔离级别。这种隔离级别能够有效的避免脏读,但除非在查询中显示的加锁,如:
select * from T where ID=2 lock in share mode;
select * from T where ID=2 for update;
不然,普通的查询是不会加锁的。
那为什么“读提交”同“读未提交”一样,都没有查询加锁,但是却能够避免脏读呢?
这就要说道另一个机制“快照(snapshot)”,而这种既能保证一致性又不加锁的读也被称为“快照读(Snapshot Read)”
假设没有“快照读”,那么当一个更新的事务没有提交时,另一个对更新数据进行查询的事务会因为无法查询而被阻塞,这种情况下,并发能力就相当的差。
而“快照读”就可以完成高并发的查询,不过,“读提交”只能避免“脏读”,并不能避免“不可重复读”和“幻读”。
可重复读(Repeated Read)
可重复读,顾名思义,就是专门针对“不可重复读”这种情况而制定的隔离级别,自然,它就可以有效的避免“不可重复读”。而它也是MySql的默认隔离级别。
在这个级别下,普通的查询同样是使用的“快照读”,但是,和“读提交”不同的是,当事务启动时,就不允许进行“修改操作(Update)”了,而“不可重复读”恰恰是因为两次读取之间进行了数据的修改,因此,“可重复读”能够有效的避免“不可重复读”,但却避免不了“幻读”,因为幻读是由于“插入或者删除操作(Insert or Delete)”而产生的。
串行化(Serializable)
这是数据库最高的隔离级别,这种级别下,事务“串行化顺序执行”,也就是一个一个排队执行。
这种级别下,“脏读”、“不可重复读”、“幻读”都可以被避免,但是执行效率奇差,性能开销也最大,所以基本没人会用。
总结一下
为什么会出现“脏读”?因为没有“select”操作没有规矩。
为什么会出现“不可重复读”?因为“update”操作没有规矩。
为什么会出现“幻读”?因为“insert”和“delete”操作没有规矩。
“读未提(Read Uncommitted)”能预防啥?啥都预防不了。
“读提交(Read Committed)”能预防啥?使用“快照读(Snapshot Read)”,避免“脏读”,但是可能出现“不可重复读”和“幻读”。
“可重复读(Repeated Red)”能预防啥?使用“快照读(Snapshot Read)”,锁住被读取记录,避免出现“脏读”、“不可重复读”,但是可能出现“幻读”。
“串行化(Serializable)”能预防啥?排排坐,吃果果,有效避免“脏读”、“不可重复读”、“幻读”,不过效果谁用谁知道。
mysql-Innodb事务隔离级别-repeatable read详解
转载地址:https://blog.csdn.net/alifel/article/details/6548075
一、事务隔离级别
ANSI/ISO SQL标准定义了4中事务隔离级别:未提交读(read uncommitted),提交读(read committed),重复读(repeatable read),串行读(serializable)。
对于不同的事务,采用不同的隔离级别分别有不同的结果。不同的隔离级别有不同的现象。主要有下面3种现在:
1、脏读(dirty read):一个事务可以读取另一个尚未提交事务的修改数据。
2、非重复读(nonrepeatable read):在同一个事务中,同一个查询在T1时间读取某一行,在T2时间重新读取这一行时候,这一行的数据已经发生修改,可能被更新了(update),也可能被删除了(delete)。
3、幻像读(phantom read):在同一事务中,同一查询多次进行时候,由于其他插入操作(insert)的事务提交,导致每次返回不同的结果集。
不同的隔离级别有不同的现象,并有不同的锁定/并发机制,隔离级别越高,数据库的并发性就越差,4种事务隔离级别分别表现的现象如下表:

二、数据库中的默认事务隔离级别
在Oracle中默认的事务隔离级别是提交读(read committed)。
对于MySQL的Innodb的默认事务隔离级别是重复读(repeated read)。
MYSQL的查询默认事务隔离级别的语句: SELECT @@TX_ISOLATION;
下面进行一下测试
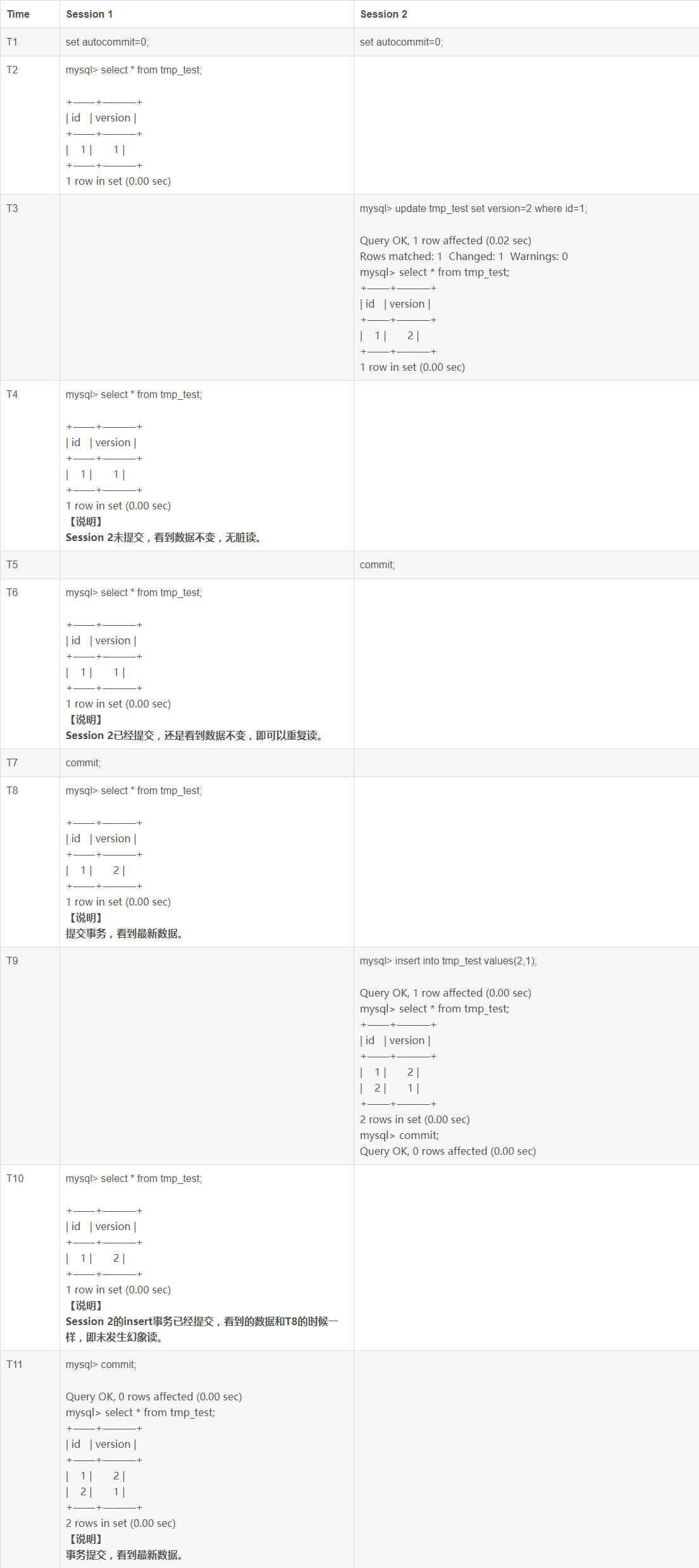
上面的结果可以看到Innodb的重复读(repeated read)不允许脏读,不允许非重复读(即可以重复读,Innodb使用多版本一致性读来实现)和不允许幻象读(这点和ANSI/ISO SQL标准定义的有所区别)。
DEMO
/**
* 数据库的事务简单案例: 转账 (顺带记住英语词缀)
* Parma payor 付款人 -er ,-or 结尾却含主动意义
* Parma payee 收款人 -ee 结尾含被动意义
*/
@Override
public void transferAccouts(String payor,String payee) {
// 1.准备SQL语句(使用update table_name set filed_name where filed_name = ?)
String sql1 = "update tb_user set sal = sal-1000 where uname = ?";
String sql2 = "update tb_user set sal = sal+1000 where uname = ?";
// 2.创建数据库连接对象,调用connection类中的setAutoCommit(boolean autoCommit)方法
// mysql默认的事务隔离级别是repeated read,调用方法修改为Read Uncommitted,在多条SQL语句执行完手动提交
conn = DBUtil.getconn(); //DBUtil为自己写的JDBC连接的工具类
try { // 调用connection类中的方法将事务隔离级别设为read uncommited。这样即使ps1、ps2执行后数据库的数据在手动提交钱也不会发生变化。 conn.setAutoCommit(false); // 3、预编译SQL语句准备执行 PreparedStatement ps1 = conn.prepareStatement(sql1); ps1.setString(1, payor); PreparedStatement ps2 = conn.prepareStatement(sql2); ps2.setString(1, payee); // 4.执行SQL语句 ps1.executeUpdate(); // 5、模拟转账中间突发情况,导致ps1执行后,ps2无法正常执行。若发生异常,则ps1执行后,ps2因为异常未正常执行 // 此种情况需在catch语句中添加回滚的方法,使发生异常前执行未提交的ps1的数据回滚,保持不变 System.out.println(3/0); ps2.executeUpdate(); conn.commit();//ps1、ps2都正常执行后再提交 System.out.println("转账成功"); } catch (SQLException e) { e.printStackTrace(); try { // 6、异常发生时,事务回滚。事务回滚需保证执行后的语句未提交,如果数据提交了,则不能回滚。 conn.rollback(); } catch (SQLException e1) { e1.printStackTrace(); } } }
数据库常用的事务隔离级别和原理?&&mysql-Innodb事务隔离级别-repeatable read详解的更多相关文章
- [原创]java WEB学习笔记78:Hibernate学习之路---session概述,session缓存(hibernate 一级缓存),数据库的隔离级别,在 MySql 中设置隔离级别,在 Hibernate 中设置隔离级别
本博客的目的:①总结自己的学习过程,相当于学习笔记 ②将自己的经验分享给大家,相互学习,互相交流,不可商用 内容难免出现问题,欢迎指正,交流,探讨,可以留言,也可以通过以下方式联系. 本人互联网技术爱 ...
- Mysql高手系列 - 第14篇:详解事务
这是Mysql系列第14篇. 环境:mysql5.7.25,cmd命令中进行演示. 开发过程中,会经常用到数据库事务,所以本章非常重要. 本篇内容 什么是事务,它有什么用? 事务的几个特性 事务常见操 ...
- kafka原理和实践(五)spring-kafka配置详解
系列目录 kafka原理和实践(一)原理:10分钟入门 kafka原理和实践(二)spring-kafka简单实践 kafka原理和实践(三)spring-kafka生产者源码 kafka原理和实践( ...
- mysql-Innodb事务隔离级别-repeatable read详解(转)
一.事务隔离级别 ANSI/ISO SQL标准定义了4中事务隔离级别:未提交读(read uncommitted),提交读(read committed),重复读(repeatable read),串 ...
- mysql-Innodb事务隔离级别-repeatable read详解1
经验总结: Python使用MySQLdb数据库后,如使用多线程,每个线程创建一个db链接,然后再各自创建一个游标cursor,其中第一个线程读一个表中数据为空,第二个写入该表一条数据并提交,第一个线 ...
- mysql-Innodb事务隔离级别-repeatable read详解
http://blog.csdn.net/dong976209075/article/details/8802778 经验总结: Python使用MySQLdb数据库后,如使用多线程,每个线程创建一个 ...
- 搞懂MySQL InnoDB事务ACID实现原理
前言 说到数据库事务,想到的就是要么都做修改,要么都不做.或者是ACID的概念.其实事务的本质就是锁和并发和重做日志的结合体.那么,这一篇主要讲一下InnoDB中的事务到底是如何实现ACID的. 原子 ...
- 一文快速搞懂MySQL InnoDB事务ACID实现原理(转)
这一篇主要讲一下 InnoDB 中的事务到底是如何实现 ACID 的: 原子性(atomicity) 一致性(consistency) 隔离性(isolation) 持久性(durability) 隔 ...
- 浅析MySQL InnoDB的隔离级别
MySQL InnoDB存储引擎中事务的隔离级别有哪些?对应隔离级别的实现机制是什么? 本文就将对上面这两个问题进行解答,分析事务的隔离级别以及相关锁机制. 隔离性简介 隔离性主要是指数据库系统提供一 ...
随机推荐
- Ansible自动化运维工具安装与使用实例
1.准备两台服务器,要确定网络是通的.服务器当然越多越好啦....Ansible的简介和好处我就不多说了,自己看百科去(*╹▽╹*) IP:192.168.139.100 IP:192.168.139 ...
- Matlab图像处理常用基本函数
之前用Matlab做图像处理工作时,用到什么函数就查什么函数,从没做过系统的总结,再做的时候又要去查,所以总结还是有必要的~ 为了方便,在此只列出函数名和基本用法,如不特别指出,不详细说明参数,辅助h ...
- java锁与监视器概念 为什么wait、notify、notifyAll定义在Object中 多线程中篇(九)
在Java中,与线程通信相关的几个方法,是定义在Object中的,大家都知道Object是Java中所有类的超类 在Java中,所有的类都是Object,借助于一个统一的形式Object,显然在有些处 ...
- linux 指令备忘
linux 指令备忘 1.ls [选项] [目录名 | 列出相关目录下的所有目录和文件 -a 列出包括.a开头的隐藏文件的所有文件 -A 通-a,但不列出"."和"..& ...
- 为什么单线程的Redis这么快?
一. Redis简介 Redis是一个开源的内存中的数据结构存储系统,它可以用作数据库.缓存和消息中间件. 它支持多种类型的数据结构,如 字符串(strings), 散列(hashes), 列表(li ...
- 持续集成-jenkins介绍与环境搭建
什么是持续集成? 转自:https://blog.csdn.net/tanshizhen119/article/details/80328523 持续集成,俗称CI, 大师Martin Fowler对 ...
- Python二级-----------程序冲刺3
1. 根据输入字符串 s,输出一个宽度为 15 字符,字符串 s 居中显示,以“=”填充的格式.如果输入字符串超过 15 个字符,则输出字符串前 15 个字符.提示代码如下: ...
- Django之无名分组,有名分组
在Django 2.0版本之前,在urls,py文件中,用url设定视图函数 urlpatterns = [ url(r'login/',views.login), ] 其中第一个参数是正则匹配,如下 ...
- 升级WIN10 (9879)后IE无响应的解决办法
身为程序猿,当然有了新系统就要尝尝鲜,有WIN8时,哥是朋友圈第一个用的,有WIN8.1时哥也是第一个升级的. 现在WIN10来了,当然也得赶紧尝尝鲜.直接下载了 9879版的预览版本安装. 要说WI ...
- Jetty 开发指南:嵌入式开发示例
Jetty具有嵌入各种应用程序的丰富历史. 在本节中,我们将向您介绍我们的git存储库中的embedded-jetty-examples项目下的一些简单示例. 重要:生成此文档时,将直接从我们的git ...