Python Scrapy项目创建(基础普及篇)
在使用Scrapy开发爬虫时,通常需要创建一个Scrapy项目。通过如下命令即可创建 Scrapy 项目:
scrapy startproject ZhipinSpider
在上面命令中,scrapy 是Scrapy 框架提供的命令;startproject 是 scrapy 的子命令,专门用于创建项目;ZhipinSpider 就是要创建的项目名。
scrapy 除提供 startproject 子命令之外,它还提供了 fetch(从指定 URL 获取响应)、genspider(生成蜘蛛)、shell(启动交互式控制台)、version(查看 Scrapy 版本)等常用的子命令。可以直接输入 scrapy 来查看该命令所支持的全部子命令。
运行上面命令,将会看到如下输出结果:
New Scrapy project 'ZhipinSpider', using template directory 'd:\python3.6\lib\site-packages\scrapy\templates\project', created in:
C:\Users\mengma\ZhipinSpider You can start your first spider with:
cd ZhipinSpider
scrapy genspider example example.com
上面信息显示 Scrapy 在当前目录下创建了一个 ZhipinSpider 项目,此时在当前目录下就可以看到一个 ZhipinSpider 目录,该目录就代表 ZhipinSpider 项目。
查看 ZhipinSpider 项目,可以看到如下文件结构:
ZhipinSpider
│ scrapy.cfg
│
└──ZhipinSpider
│ item.py
│ middlewares.py
│ pipelines.py
│ setting.py
│
├─ spiders
│ │ __init__.py
│ │
│ └─ __pycache__
└─ __pycache__
下面大致介绍这些目录和文件的作用:
- scrapy.cfg:项目的总配置文件,通常无须修改。
- ZhipinSpider:项目的 Python 模块,程序将从此处导入 Python 代码。
- ZhipinSpider/items.py:用于定义项目用到的 Item 类。Item 类就是一个 DTO(数据传输对象),通常就是定义 N 个属性,该类需要由开发者来定义。
- ZhipinSpider/pipelines.py:项目的管道文件,它负责处理爬取到的信息。该文件需要由开发者编写。
- ZhipinSpider/settings.py:项目的配置文件,在该文件中进行项目相关配置。
- ZhipinSpider/spiders:在该目录下存放项目所需的蜘蛛,蜘蛛负责抓取项目感兴趣的信息。
为了更好地理解 Scrapy 项目中各组件的作用,下面给出 Scrapy 概览图,如图 1 所示。
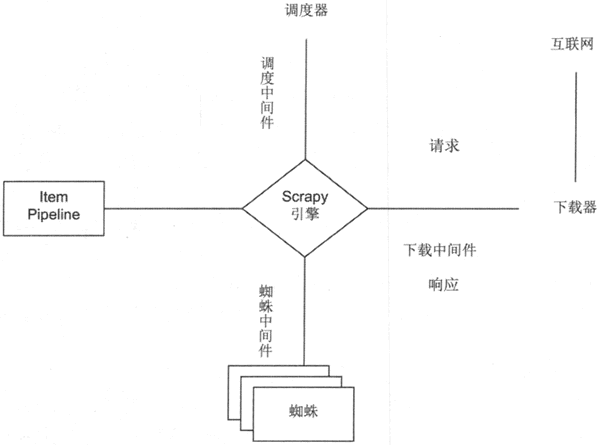
图 1 Scrapy 概览图
在图 1 中可以看到,Scrapy 包含如下核心组件:
- 调度器:该组件由 Scrapy 框架实现,它负责调用下载中间件从网络上下载资源。
- 下载器:该组件由 Scrapy 框架实现,它负责从网络上下载数据,下载得到的数据会由 Scrapy 引擎自动交给蜘蛛。
- 蜘蛛:该组件由开发者实现,蜘蛛负责从下载数据中提取有效信息。蜘蛛提取到的信息会由 Scrapy 引擎以 Item 对象的形式转交给 Pipeline。
- Pipeline:该组件由开发者实现,该组件接收到 Item 对象(包含蜘蛛提取的信息)后,可以将这些信息写入文件或数据库中。
经过上面分析可知,使用 Scrapy 开发网络爬虫主要就是开发两个组件,蜘蛛和 Pipeline。
Python Scrapy项目创建(基础普及篇)的更多相关文章
- Scrapy项目创建以及目录详情
Scrapy项目创建已经目录详情 一.新建项目(scrapy startproject) 在开始爬取之前,必须创建一个新的Scrapy项目.进入自定义的项目目录中,运行下列命令: PS C:\scra ...
- python Django 项目创建
注:后续如不特色说明,使用python版本均为python3 创建项目 django-admin startproject projectName 启动服务 python manage.py runs ...
- python django项目创建及前期准备(使用pycharm)
一.创建django项目 1.打开pycharm软件 2.点击菜单栏 File-->New Project,弹出如下对话框,如下图设置 二.基本配置 1.静态文件目录配置(用于客户端访问后台服务 ...
- scrapy分布式爬虫scrapy_redis二篇
=============================================================== Scrapy-Redis分布式爬虫框架 ================ ...
- python scrapy 爬取西刺代理ip(一基础篇)(ubuntu环境下) -赖大大
第一步:环境搭建 1.python2 或 python3 2.用pip安装下载scrapy框架 具体就自行百度了,主要内容不是在这. 第二步:创建scrapy(简单介绍) 1.Creating a p ...
- Python -- Scrapy 框架简单介绍(Scrapy 安装及项目创建)
Python -- Scrapy 框架简单介绍 最近在学习python 爬虫,先后了解学习urllib.urllib2.requests等,后来发现爬虫也有很多框架,而推荐学习最多就是Scrapy框架 ...
- cocos2dx基础篇(1) Cocos2D-X项目创建
已经入行工作半年多时间了,以前都是把这些东西记录在有道云上面的,现在抽出些时间把以前的笔记腾过来. 具体的环境配置就不用说了,因为现在已经是2018年,只需要下载对应版本解压后就能使用,不用再像多年前 ...
- python爬虫scrapy项目详解(关注、持续更新)
python爬虫scrapy项目(一) 爬取目标:腾讯招聘网站(起始url:https://hr.tencent.com/position.php?keywords=&tid=0&st ...
- (转)Python成长之路【第九篇】:Python基础之面向对象
一.三大编程范式 正本清源一:有人说,函数式编程就是用函数编程-->错误1 编程范式即编程的方法论,标识一种编程风格 大家学习了基本的Python语法后,大家就可以写Python代码了,然后每个 ...
随机推荐
- Docker 搜索镜像
文章首发个人网站: https://www.exception.site/docker/docker-search-image 本文中,您将学习 Docker 如何搜索镜像? 一.search 命令 ...
- QPainterPath 不规则提示框(二)
前一篇讲过不规则提示框,但是提示框的方向是固定的,不能达到随意变换方向的效果,本接讲述可以动态变换方向的提示框 先看效果图 图1 图2 图3 图4 如上图1所示,上一篇文章的代码可以达到类似效果 本 ...
- 装箱问题的CPLEX求解
装箱问题(Bin Packing Problem) 装箱问题即搬家公司问题.一个搬家公司有无限多的箱子,每个箱子的承重上限为W,当搬家公司进入一个房间时,所有物品都必须被装入箱子,每个物品的重量为wi ...
- ES6躬行记(21)——类的继承
ES6的继承依然是基于原型的继承,但语法更为简洁清晰.通过一个extends关键字,就能描述两个类之间的继承关系(如下代码所示),在此关键字之前的Man是子类(即派生类),而在其之后的People是父 ...
- SLAM+语音机器人DIY系列:(一)Linux基础——2.安装Linux发行版ubuntu系统
摘要 由于机器人SLAM.自动导航.语音交互这一系列算法都在机器人操作系统ROS中有很好的支持,所以后续的章节中都会使用ROS来组织构建代码:而ROS又是安装在Linux发行版ubuntu系统之上的, ...
- [Vue] vue2.0
vue实例 所有的 Vue 组件都是 Vue 实例,并且接受相同的选项对象 当一个 Vue 实例被创建时,它将 data 对象中的所有的属性加入到 Vue 的响应式系统中.当这些属性的值发生改变时,视 ...
- MVC,EF 小小封装
1.项目中经常要用到 EF,有时候大多数的增删改查都是重复性的东西,本次封装就是为了快速开发,期间没有考虑到架构上的各种思想,就感觉到欠缺点什么东西所以这次将这些拉出来,有存在问题的话还请各位多多指导 ...
- 什么是mybatis?
[学习笔记] 什么是mybatis: Mybatis本质是一种半自动化的ORM框架,前身是ibatis,除了要pojo和映射关系之外,还需要些sql语句. 怎么看待ORM框架: 处理矛盾的,java程 ...
- EF时,数据库字段和实体类不一致问题
场景:由于一些原因,实体中属性比数据库中字段多了一个startPage属性.PS:controllers中用实体类去接收参数,但是传入的参数比数据库中实体表多了一个字段, 这种情况下,应该建一个vie ...
- sql 服务启动失败 SQL Server(MSSQLSERVER) 错误码126
SQL配置管理器-->sql server 网络配置-->mssqlerver的协议-->VIA禁用服务