Prim算法(一)之 C语言详解
本章介绍普里姆算法。和以往一样,本文会先对普里姆算法的理论论知识进行介绍,然后给出C语言的实现。后续再分别给出C++和Java版本的实现。
目录
1. 普里姆算法介绍
2. 普里姆算法图解
3. 普里姆算法的代码说明
4. 普里姆算法的源码转载请注明出处:http://www.cnblogs.com/skywang12345/
更多内容:数据结构与算法系列 目录
普里姆算法介绍
普里姆(Prim)算法,和克鲁斯卡尔算法一样,是用来求加权连通图的最小生成树的算法。
基本思想
对于图G而言,V是所有顶点的集合;现在,设置两个新的集合U和T,其中U用于存放G的最小生成树中的顶点,T存放G的最小生成树中的边。
从所有uЄU,vЄ(V-U) (V-U表示出去U的所有顶点)的边中选取权值最小的边(u, v),将顶点v加入集合U中,将边(u, v)加入集合T中,如此不断重复,直到U=V为止,最小生成树构造完毕,这时集合T中包含了最小生成树中的所有边。
普里姆算法图解
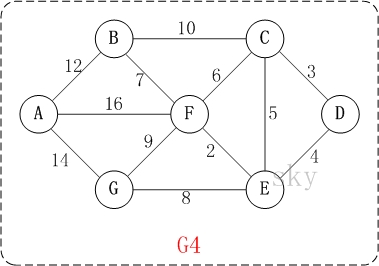
以上图G4为例,来对普里姆进行演示(从第一个顶点A开始通过普里姆算法生成最小生成树)。

初始状态:V是所有顶点的集合,即V={A,B,C,D,E,F,G};U和T都是空!
第1步:将顶点A加入到U中。
此时,U={A}。
第2步:将顶点B加入到U中。
上一步操作之后,U={A}, V-U={B,C,D,E,F,G};因此,边(A,B)的权值最小。将顶点B添加到U中;此时,U={A,B}。
第3步:将顶点F加入到U中。
上一步操作之后,U={A,B}, V-U={C,D,E,F,G};因此,边(B,F)的权值最小。将顶点F添加到U中;此时,U={A,B,F}。
第4步:将顶点E加入到U中。
上一步操作之后,U={A,B,F}, V-U={C,D,E,G};因此,边(F,E)的权值最小。将顶点E添加到U中;此时,U={A,B,F,E}。
第5步:将顶点D加入到U中。
上一步操作之后,U={A,B,F,E}, V-U={C,D,G};因此,边(E,D)的权值最小。将顶点D添加到U中;此时,U={A,B,F,E,D}。
第6步:将顶点C加入到U中。
上一步操作之后,U={A,B,F,E,D}, V-U={C,G};因此,边(D,C)的权值最小。将顶点C添加到U中;此时,U={A,B,F,E,D,C}。
第7步:将顶点G加入到U中。
上一步操作之后,U={A,B,F,E,D,C}, V-U={G};因此,边(F,G)的权值最小。将顶点G添加到U中;此时,U=V。
此时,最小生成树构造完成!它包括的顶点依次是:A B F E D C G。
普里姆算法的代码说明
以"邻接矩阵"为例对普里姆算法进行说明,对于"邻接表"实现的图在后面会给出相应的源码。
1. 基本定义
// 邻接矩阵
typedef struct _graph
{
char vexs[MAX]; // 顶点集合
int vexnum; // 顶点数
int edgnum; // 边数
int matrix[MAX][MAX]; // 邻接矩阵
}Graph, *PGraph;
// 边的结构体
typedef struct _EdgeData
{
char start; // 边的起点
char end; // 边的终点
int weight; // 边的权重
}EData;
Graph是邻接矩阵对应的结构体。
vexs用于保存顶点,vexnum是顶点数,edgnum是边数;matrix则是用于保存矩阵信息的二维数组。例如,matrix[i][j]=1,则表示"顶点i(即vexs[i])"和"顶点j(即vexs[j])"是邻接点;matrix[i][j]=0,则表示它们不是邻接点。
EData是邻接矩阵边对应的结构体。
2. 普里姆算法
/*
* prim最小生成树
*
* 参数说明:
* G -- 邻接矩阵图
* start -- 从图中的第start个元素开始,生成最小树
*/
void prim(Graph G, int start)
{
int min,i,j,k,m,n,sum;
int index=0; // prim最小树的索引,即prims数组的索引
char prims[MAX]; // prim最小树的结果数组
int weights[MAX]; // 顶点间边的权值
// prim最小生成树中第一个数是"图中第start个顶点",因为是从start开始的。
prims[index++] = G.vexs[start];
// 初始化"顶点的权值数组",
// 将每个顶点的权值初始化为"第start个顶点"到"该顶点"的权值。
for (i = 0; i < G.vexnum; i++ )
weights[i] = G.matrix[start][i];
// 将第start个顶点的权值初始化为0。
// 可以理解为"第start个顶点到它自身的距离为0"。
weights[start] = 0;
for (i = 0; i < G.vexnum; i++)
{
// 由于从start开始的,因此不需要再对第start个顶点进行处理。
if(start == i)
continue;
j = 0;
k = 0;
min = INF;
// 在未被加入到最小生成树的顶点中,找出权值最小的顶点。
while (j < G.vexnum)
{
// 若weights[j]=0,意味着"第j个节点已经被排序过"(或者说已经加入了最小生成树中)。
if (weights[j] != 0 && weights[j] < min)
{
min = weights[j];
k = j;
}
j++;
}
// 经过上面的处理后,在未被加入到最小生成树的顶点中,权值最小的顶点是第k个顶点。
// 将第k个顶点加入到最小生成树的结果数组中
prims[index++] = G.vexs[k];
// 将"第k个顶点的权值"标记为0,意味着第k个顶点已经排序过了(或者说已经加入了最小树结果中)。
weights[k] = 0;
// 当第k个顶点被加入到最小生成树的结果数组中之后,更新其它顶点的权值。
for (j = 0 ; j < G.vexnum; j++)
{
// 当第j个节点没有被处理,并且需要更新时才被更新。
if (weights[j] != 0 && G.matrix[k][j] < weights[j])
weights[j] = G.matrix[k][j];
}
}
// 计算最小生成树的权值
sum = 0;
for (i = 1; i < index; i++)
{
min = INF;
// 获取prims[i]在G中的位置
n = get_position(G, prims[i]);
// 在vexs[0...i]中,找出到j的权值最小的顶点。
for (j = 0; j < i; j++)
{
m = get_position(G, prims[j]);
if (G.matrix[m][n]<min)
min = G.matrix[m][n];
}
sum += min;
}
// 打印最小生成树
printf("PRIM(%c)=%d: ", G.vexs[start], sum);
for (i = 0; i < index; i++)
printf("%c ", prims[i]);
printf("\n");
}
普里姆算法的源码
这里分别给出"邻接矩阵图"和"邻接表图"的普里姆算法源码。
Prim算法(一)之 C语言详解的更多相关文章
- Floyd算法(一)之 C语言详解
本章介绍弗洛伊德算法.和以往一样,本文会先对弗洛伊德算法的理论论知识进行介绍,然后给出C语言的实现.后续再分别给出C++和Java版本的实现. 目录 1. 弗洛伊德算法介绍 2. 弗洛伊德算法图解 3 ...
- Dijkstra算法(一)之 C语言详解
本章介绍迪杰斯特拉算法.和以往一样,本文会先对迪杰斯特拉算法的理论论知识进行介绍,然后给出C语言的实现.后续再分别给出C++和Java版本的实现. 目录 1. 迪杰斯特拉算法介绍 2. 迪杰斯特拉算法 ...
- Kruskal算法(一)之 C语言详解
本章介绍克鲁斯卡尔算法.和以往一样,本文会先对克鲁斯卡尔算法的理论论知识进行介绍,然后给出C语言的实现.后续再分别给出C++和Java版本的实现. 目录 1. 最小生成树 2. 克鲁斯卡尔算法介绍 3 ...
- 原来Github上的README.md文件这么有意思——Markdown语言详解(sublime text2 版本)
一直想学习 Markdown 语言,想起以前读的一篇 赵凯强 的 博客 <原来Github上的README.md文件这么有意思——Markdown语言详解>,该篇博主 使用的是Mac系统, ...
- 图的建立(邻接矩阵)+深度优先遍历+广度优先遍历+Prim算法构造最小生成树(Java语言描述)
主要参考资料:数据结构(C语言版)严蔚敏 ,http://blog.chinaunix.net/uid-25324849-id-2182922.html 代码测试通过. package 图的建 ...
- Java Web----EL(表达式语言)详解
Java Web中的EL(表达式语言)详解 表达式语言(Expression Language)简称EL,它是JSP2.0中引入的一个新内容.通过EL可以简化在JSP开发中对对象的引用,从而规范页面 ...
- 二分算法题目训练(二)——Exams详解
CodeForces732D——Exams 详解 Exam 题目描述(google翻译) Vasiliy的考试期限将持续n天.他必须通过m门科目的考试.受试者编号为1至m. 大约每天我们都知道当天可以 ...
- Kruskal算法 - C语言详解
最小生成树 在含有n个顶点的连通图中选择n-1条边,构成一棵极小连通子图,并使该连通子图中n-1条边上权值之和达到最小,则称其为连通网的最小生成树. 例如,对于如上图G4所示的连通网可以有多棵权值总 ...
- 拓扑排序(一)之 C语言详解
本章介绍图的拓扑排序.和以往一样,本文会先对拓扑排序的理论知识进行介绍,然后给出C语言的实现.后续再分别给出C++和Java版本的实现. 目录 1. 拓扑排序介绍 2. 拓扑排序的算法图解 3. 拓扑 ...
随机推荐
- java-内省与javabean
JavaBean 是一种JAVA语言写成的可重用组件.为写成JavaBean,类必须是具体的和公共的,并且具有无参数的构造器.JavaBean 通过提供符合一致性设计模式的公共方法将内部域暴露成员属性 ...
- 我的ORM之十三 -- 性能参数
我的ORM索引 测试环境 台式机: 主板:映泰Z77 CPU:i5 3470(3.2GHz) 内存:DDR3 1600 8G(单条) 硬盘:创见 SSD 256G ORM从过程上,可以分两个大的部分: ...
- 分布式系统之Quorum (NRW)算法
基于Quorum投票的冗余控制算法 Quorom 机制,是一种分布式系统中常用的,用来保证数据冗余和最终一致性的投票算法,其主要数学思想来源于鸽巢原理. 在有冗余数据的分布式存储系统当中,冗余数据对象 ...
- 004. Asp.Net Routing与MVC 之二: 请求如何激活Controller和Action
上篇讲到 请求到达 MvcRouteHandler ,并且透过 IRouteHandler.GetHttpHandler 获取到了真正的处理程序 MvcHandler 这次我们看看,MvcHandle ...
- 基于STSdb和fastJson的磁盘/内存缓存
更新 1. 增加了对批量处理的支持,写操作速度提升5倍,读操作提升100倍 2. 增加了对并发的支持 需求 业务系统用的是数据库,数据量大,部分只读或相对稳定业务查询复杂,每次页面加载都要花耗不少时间 ...
- Yii Model中添加默认搜索条件
在查询中增加条件 public function defaultScope() { return array( 'condition' => " is_deleted = 0" ...
- 更改Photoshop 语言为英语(无需语言包)
因为有时看国外教程时,手头上的PS是中文的而教程里的界面是英文的,而且中英菜单顺序在某些地方是不一样的,所以很不方便. 终于找到一个非常完美的方法可以把界面换成英文,而且不需任何语言包. 并且试了在最 ...
- JavaScript正则表达式下——相关方法
上篇博客JavaScript 正则表达式上——基本语法介绍了JavaScript正则表达式的语法,有了这些基本知识,可以看看正则表达式在JavaScript的应用了,在一切开始之前,看看RegExp实 ...
- 如何在 ASP.NET MVC 中集成 AngularJS(1)
介绍 当涉及到计算机软件的开发时,我想运用所有的最新技术.例如,前端使用最新的 JavaScript 技术,服务器端使用最新的基于 REST 的 Web API 服务.另外,还有最新的数据库技术.最新 ...
- 生成格式化的json
public static ContentResult returnJson(object obj) { var content = new ContentResult() { Content = J ...