Hadoop阅读笔记(一)——强大的MapReduce
前言:来园子已经有8个月了,当初入园凭着满腔热血和一脑门子冲动,给自己起了个响亮的旗号“大数据 小世界”,顿时有了种世界都是我的,世界都在我手中的赶脚。可是......时光飞逝,岁月如梭~~~随手一翻自己的博客,可视化已经快占据了半壁江山,思来想去,还是觉得把一直挂在嘴头,放在心头的大数据拿出来说说,哦不,是拿过来学学。入园前期写了有关Nutch和Solr的自己的一些阅读体会和一些尝试,挂着大数据的旗号做着爬虫的买卖。可是,时间在流失,对于大数据的憧憬从未改变,尤其是Hadoop一直让我魂牵梦绕,打今儿起,开始着手自己的大数据系列,把别人挤牙膏的时间用在学习上,收拾好时间,收拾好资料,收拾好自己,重返Hadoop。
以下是对于大数据学习的一种预期规划:
主要理论指导材料:Hadoop实战2
主要手段:敲代码、结合API理解
预期目标:深入了解Hadoop,能为我所用
正文:记得去年还在学校写小论文的时候,我花了一天的时间,懵懵懂懂的把Hadoop的环境给打起来了,今年出来接触社会,由于各种原因,自己又搭了几次伪分布式的环境,每次想学习Hadoop的心态好比每次背单词,只要一背单词,总是又从“abandon”开始背起。所以环境这块就不多说了,网上这样的帖子早已烂大街(因为Hadoop版本更新很快,目前应该是到2.6版本了,所以博文肯定一直在推陈出新)。用的Ubuntu12.0系统,因为之前一直弄的是0.20.2版本,后来也没想着换,换也来不及了,0.20.2老朋友,可靠,还选他。倒是现在的Hadoop整个框架已经有所改变,HDFS还在,只是从0.23.0以后就不见了MapReduce的踪迹,现在好像是重新洗牌编程了YARN,小弟懂得不多,大牛莫怪。。。
今天是大数据系列第一枪,主要内容分为三个部分:1.先用理论知识压压场;2.通过Hadoop的HelloWorld程序讲解下自己的疑惑与理解;3.借助专利数据集动手写个简单的MapReduce程序。
1.首先来说说整个Hadoop大家族,然后粗略的了解下HDFS以及MapReduce。
1.1.hadoop的子项目构成以及相应的配套服务图:
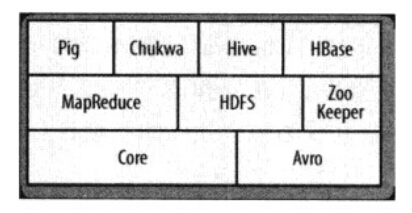
(1)Core:一系列分布式文件系统和通用I/O的组件和接口(序列化、Java RPC和持久化数据结构)
(2)Avro:一种提供高效、跨语言RPC的数据序列系统,持久化数据存储。Avro是Hadoop的一个子项目,由Hadoop的 创始人Doug Cutting(也是Lucene,Nutch等项目的创始人)牵头开发。
Avro是一个数据序列化系统,设计用于支持大 批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理 Avro数据。
(3)MapReduce:分布式数据处理模式和执行环境。
(4)HDFS:分布式文件系统。
(5)Pig:一种数据流语言和运行环境,用以检索非常大的数据集。Pig运行在MapReduce和HDFS的集群上,是对大型数据集进行分析、评估的平台。
Pig是一种编程语言,它简化了Hadoop常见的工作任务。Pig可加载数据、表达转换数据以及存储最终结果。Pig内置的操作使得半结构化数据变得有意义(如日志文件)。同时Pig可扩展使用Java中添加的自定义数据类型并支持数据转换。
(6)HBase:一个分布式的、列存储数据库。HBase使用HDFS作为底层存储,同时支持MapReduce的批量式计算和点查询(随机读取)。
(7)ZooKeeper:一个分布式的,高可用性的协调服务。ZooKeeper提供分布式锁之类的基本服务用于构建分布式应用。
(8)Hive:分布式数据仓库。Hive管理与HDFS总存储的数据,并提供基于SQL的查询语言(由运行时引擎翻译成MapReduce作业)用以查询数据。
Hive在Hadoop中扮演数据仓库的角色。Hive添加数据的结构在HDFS(hive superimposes structure on data in HDFS),并允许使用类似于SQL语法进行数据查询。与Pig一样,Hive的核心功能是可扩展的。
(9)Chukwa:分布式数据收集和分析系统。Chukwa运行HDFS中存储数据的收集器,它使用MapReduce来生成报告。
1.2HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。NameNode执行文件系统的命名操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的同意调度下进行数据块的创建、删除和复制工作。
MapReduce框架是由一个单独运行在主节点的JobTracker和运行在每个集群从节点的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。
Hadoop的MapReduce模型是通过输入key/value对进行运算得到输出key/value对。其分为Map过程和Reduce过程。
Map主要的工作是接收一个key/value对,产生一个中间key/value对,之后MapReduce把集合中所有相同key值的value放在一起并传递给Reduce函数。
Reduce函数接收key和相关的value集合并合并这些value值,得到一个较小的value集合。
下图是MapReduce的数据流图,体现了MapReduce处理大数据集的过程。这个过程就是将大数据分解为成百上千个小数据集,每个(或若干个)数据集分别由集群中的一个节点进行处理并生成的中间结果,然后这些中间结果又由大量的节点合并,形成最终结果。

2.以小见大——从Hadoop的HelloWorld说起
每种语言、框架都有属于自己的“HelloWorld”,Hadoop也不例外,在下载的Hadoop包中就有example文件夹,里面提供了10+个例子,首当其冲,各种博文中出现频率最高的当属WordCount无疑,其算法思想简单,又能结合大数据集做实验,能够很好的体现Hadoop为何物、有何用、如何用的特征。如果能把一个WordCount的每个细节都弄清楚了,基本上也算是掌握了Hadoop的大部分了,下面就来看看WordCount的原生代码:
package org.apache.hadoop.examples; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser; public class WordCount { public static class TokenizerMapper
extends Mapper<Object, Text, Text, IntWritable>{ private final static IntWritable one = new IntWritable(1);
private Text word = new Text(); public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setInputFormatClass(TextInputFormat.class);
job.setInputFormatClass(TextInputFormat.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
先且不谈整个WordCount如何借助HDFS分布式文件系统进行数据存取操作,这里我们看看WordCount的MapReducer如何处理。
2.1何为MapReduce:
MapReduce顾名思义,由Map和Reduce两部分组成,通俗点说,Map用于将数据集分拆到集群中节点运行,而Reduce负责整合聚合最终结果输出。那Hadoop为什么要废如此周折又是分又是合,直接通过传统的手段完成自己的代码逻辑不是更简单?是的,没错,对于一般操作,传统手段也能办到,设置更加简洁,但是这里讨论的背景是大数据,而Hadoop就是应这个背景而出现的。举个不恰当的例子,原始社会,大家思想很简单,生活也很简单,上山砍点柴,自个儿就能背回家取暖,这样基本能满足自己的需求了,不会有任何问题。某天有个脑洞大开的先人想到如果能够用木头造个房子,大家的生活质量必定有所改善,不怕风吹雨淋了。那么问题来了,对树木的需求量变大了,凭某个人的力量恐怕很难办到,所以,他们也弄了个集群,找了很多人,每个人负责背点柴(运行任务),大家团队协作,共同完成这个在个人面前庞大到难以完成的任务,此外,这个集群还可以随机添加个体(节点),活量很多的时候老婆、孩子都去帮忙,稍微闲点的时候让他们回家,不参与集群活动。
所以说,面对当前日益增长的数据量,传统单个pc或是服务器已经无法支撑或是成本很高,而Hadoop利用了看似繁杂的手段却能有效的解决数据量瓶颈问题,它会将一个大数据集切割以Block为单位(如64M),将这些Block分别分配到相对空闲的节点上执行任务操作,经过一系列操作后,会将这些输出作为Reduce的输入,经过合并后得到最终的输出结果,Map和Reduce中的所有输入输出都是以<key,value>的形式存在。整个过程就是Map和Reduce扮演的角色。MapReduce的数据变化历程如下图所示:

2.2如何定义输入输出格式:
从代码中可以看出对于输入文件的格式规范使用的是TextInputFormat,通过万能的Hadoop API可以发现该类是extends FileInputFormat类,而FileInputFormat是实现了InputFormat接口的。那我们先来看下这个InputFormat是干嘛用的,在API中我们发现,MapReduce是依赖于InputFormat这个接口的,主要用来验证具体任务的输入格式;将输入文件拆分为InputSplits。形象点说就是,当数据传给Map时,Map会将经过拆分后的分片(InputSplit)送给InputFormat,InputFormat调用getRecordReader方法生成RecordReader,RecordReader在调用createKey和createValue方法创建出大家熟悉的符合Map格式要求的<key,value>键值对,所以说,InputFormat是为Map的输入格式<key,value>服务的。与此相对应的OutputFormat类也是同样的道理。
这里,要特地强调一点自己对于整个WordCount是如何将文件输入并切分以及如何读取的疑惑以及理解:之前一直在想代码StringTokenizer itr = new StringTokenizer(value.toString());是如何实现很多条记录过来,比如一个文件中有二行文本,仅凭StringTokenizer如何完成切分,现在才知道因为有了TextInputFormat的约束,所以之前已经根据TextInputFormat的特性将文件中每行都划分出来,以行为单位向Map输送数据,所以代码中的StringTokenizer类只要对制表符或是空格进行分词就可以了。举例来说,有两个文件:
file1:hello world bye world
file2:hello hadoop bye hadoop
经过TextInputFormat格式限定后,就会将文件的每一行作为一条记录,并将每行记录转换为<key,value>的形式,如下:
file1:
0 hello world bye world
file2:
0 hello hadoop bye hadoop
这里两个都是0,是因为两个文件被分配到不同的Map中了。
3.自己动手使用专利数据统计每条专利被引用的次数
数据集:从NBER获得,网址为:http://www.nber.org/patents
其中包含专利引用数据集cite75_99.txt.
具体代码如下,主要是通过cite75_99.txt中的第二个属性即被引用的属性,进行计数,生成结果形式为<被引用的专利号,被引用的次数>,举例来说,cite75_99.txt中的数据形式为:
| CITTING | CITED |
| 1 | 2 |
| 2 | 3 |
| 3 | 2 |
| 4 | 1 |
| 5 | 2 |
CITTING表示专利号,CITED表示被引用的专利号,第一行表示专利1引用了专利2,所以从这个表来看,专利1和专利3分别被引用1次,专利2被应用3次。但是因为这个数据集相对来说比较大,有250+M,所以采用MapReduce进行处理。代码如下:
package org.apache.mapreduce; import java.io.IOException;
import java.util.StringTokenizer; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapred.FileInputFormat;
import org.apache.hadoop.mapred.FileOutputFormat;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.util.GenericOptionsParser; public class Test1123 { /**
* @param args
*/
public static class MapperClass extends Mapper<Object,Text,Text,IntWritable>{
public static final IntWritable one = new IntWritable(1);
public Text text = new Text(); public void map(Object key, Text value, Context context){
String citedPatent= value.toString().split(",")[1];
text.set(citedPatent);
try {
context.write(text, one);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
} public static class ReducerClass extends Reducer<Text, IntWritable, Text, IntWritable>{
public IntWritable result = new IntWritable(); public void reduce(Text key, Iterable<IntWritable> values, Context context){
int sum = 0;
for (IntWritable value:values){
sum+=value.get();
}
result.set(sum);
try {
context.write(key, result);
} catch (IOException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
} } }
public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {
Configuration conf = new Configuration();
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf, "Test1123"); job.setJarByClass(Test1123.class);
job.setMapperClass(MapperClass.class);
job.setCombinerClass(ReducerClass.class);
job.setReducerClass(ReducerClass.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class); org.apache.hadoop.mapreduce.lib.input.FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
org.apache.hadoop.mapreduce.lib.output.FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
System.out.println("end"); } }
执行过程部分片段如下:
Step1:
Step2:
Step3:
Step4:
全程耗时三分钟,觉得跑的还是很easy的,今天就到这吧,后面还需要进行理论充电,欢迎各位大牛指教,如果有用,记得点赞哦^_^
本文链接:《Hadoop阅读笔记(一)——强大的MapReduce》
友情赞助
如果你觉得博主的文章对你那么一点小帮助,恰巧你又有想打赏博主的小冲动,那么事不宜迟,赶紧扫一扫,小额地赞助下,攒个奶粉钱,也是让博主有动力继续努力,写出更好的文章^^。
1. 支付宝 2. 微信


Hadoop阅读笔记(一)——强大的MapReduce的更多相关文章
- Hadoop阅读笔记(二)——利用MapReduce求平均数和去重
前言:圣诞节来了,我怎么能虚度光阴呢?!依稀记得,那一年,大家互赠贺卡,短短几行字,字字融化在心里:那一年,大家在水果市场,寻找那些最能代表自己心意的苹果香蕉梨,摸着冰冷的水果外皮,内心早已滚烫.这一 ...
- Hadoop阅读笔记(四)——一幅图看透MapReduce机制
时至今日,已然看到第十章,似乎越是焦躁什么时候能翻完这本圣经的时候也让自己变得更加浮躁,想想后面还有一半的行程没走,我觉得这样“有口无心”的学习方式是不奏效的,或者是收效甚微的.如果有幸能有大牛路过, ...
- Hadoop阅读笔记(三)——深入MapReduce排序和单表连接
继上篇了解了使用MapReduce计算平均数以及去重后,我们再来一探MapReduce在排序以及单表关联上的处理方法.在MapReduce系列的第一篇就有说过,MapReduce不仅是一种分布式的计算 ...
- Hadoop阅读笔记(七)——代理模式
关于Hadoop已经小记了六篇,<Hadoop实战>也已经翻完7章.仔细想想,这么好的一个框架,不能只是流于应用层面,跑跑数据排序.单表链接等,想得其精髓,还需深入内部. 按照<Ha ...
- Hadoop阅读笔记(五)——重返Hadoop目录结构
常言道:男人是视觉动物.我觉得不完全对,我的理解是范围再扩大点,不管男人女人都是视觉动物.某些场合(比如面试.初次见面等),别人没有那么多的闲暇时间听你诉说过往以塑立一个关于你的完整模型.所以,第一眼 ...
- Hadoop阅读笔记(六)——洞悉Hadoop序列化机制Writable
酒,是个好东西,前提要适量.今天参加了公司的年会,主题就是吃.喝.吹,除了那些天生话唠外,大部分人需要加点酒来作催化剂,让一个平时沉默寡言的码农也能成为一个喷子!在大家推杯换盏之际,难免一些画面浮现脑 ...
- Hadoop 学习笔记 (十一) MapReduce 求平均成绩
china:张三 78李四 89王五 96赵六 67english张三 80李四 82王五 84赵六 86math张三 88李四 99王五 66赵六 77 import java.io.IOEx ...
- Hadoop 学习笔记 (十) MapReduce实现排序 全局变量
一些疑问:1 全排序的话,最后的应该sortJob.setNumReduceTasks(1);2 如果多个reduce task都去修改 一个静态的 IntWritable ,IntWritable会 ...
- [hadoop读书笔记] 第五章 MapReduce工作机制
P205 MapReduce的两种运行机制 第一种:经典的MR运行机制 - MR 1 可以通过一个简单的方法调用来运行MR作业:Job对象上的submit().也可以调用waitForCompleti ...
随机推荐
- Zookeeper初次使用
下面介绍Linux系统中Zookeeper的初次使用方法. 1.jdk安装和zookeeper下载 首先从jdk官网中下载jdk文件,然后将文件放在/usr/local/java目录下解压,并打开.b ...
- Worse Is Better
最近做的几件事和最近刚读到这篇文章(http://www.jwz.org/doc/worse-is-better.html)让我重新认识了KISS和这个所谓的Worse-is-better原则. 软件 ...
- 新版SDWebImage的使用
第一步,下载SDWebImage,导入工程.github托管地址https://github.com/rs/SDWebImage 第二步,在需要的地方导入头文件 1 #import "UII ...
- 工作当中实际运用(1)——tab选项卡
不废话 直接上代码: tab选项卡 window.onload=function(){ var titles= document.getElementById('header-dh').getElem ...
- 设计模式之美:Dynamic Property(动态属性)
索引 别名 意图 结构 参与者 适用性 效果 实现 实现方式(一):Dynamic Property 的示例实现. 别名 Property Properties Property List 意图 使对 ...
- [.net 面向对象编程基础] (17) 数组与集合
[.net 面向对象编程基础] (17) 数组与集合 学习了前面的C#三大特性,及接口,抽象类这些相对抽象的东西以后,是不是有点很累的感觉.具体的东西总是容易理解,因此我们在介绍前面抽象概念的时候,总 ...
- jQuery弹出层插件popbox
都什么年代了,还自己写弹出层插件!是的,①自己写的自己好控制②可定制性高③兼容低版本IE 本插件有以下特性: 样式分离,可定制,纯净无图片 可自定义按钮及按钮的样式.点击事件 可指定选择器选择页面元素 ...
- 统计第一个空字符前面的字符长度(java实现)
举例来说:char buf[] = {'a','b','c','d','e','f','\0','x','y','z'}当输入N=10或20,期待输出是6:当输入N=3或5,期待输出是3或5. pac ...
- Senparc.Weixin.MP SDK 微信公众平台开发教程(十二):OAuth2.0说明
紧接上一篇<Senparc.Weixin.MP SDK 微信公众平台开发教程(十一):高级接口说明>,这里专讲OAuth2.0. 理解OAuth2.0 首先我们通过一张图片来了解一下OAu ...
- Hibernate缓存(转)
来自:http://www.cnblogs.com/wean/archive/2012/05/16/2502724.html 一.why(为什么要用Hibernate缓存?) Hibernate是一个 ...