7. ensemble learning & AdaBoost
1. ensemble learning 集成学习
集成学习是通过构建并结合多个学习器来完成学习任务,如下图:
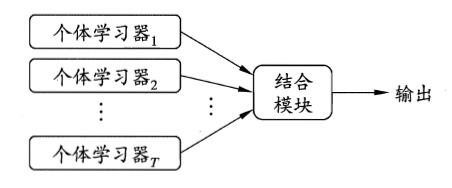
集成学习通过将多个学习学习器进行结合,常可以获得比单一学习器更优秀的泛化性能
从理论上来说,使用“弱学习器”集成足以获得好的性能,当实践中出于种种考虑,人们往往会使用比较强的学习器。
以下面为例,集成学习的结构通过投票法Voting(少数服从多数)产生:

由上面可以看出:个体学习器应该“好而不同”,即个体学习器要有一定的“准确性”,并且彼此间要有差异。
从理论上来说,假设个体学习器的误差 $\epsilon$ 相互独立,那么随着集成中个体分类器数目 $T$ 的增加,集成的错误率将呈指数级下降。但现实任务中,个体学习器是为解决同一个问题而训练出来的,它们显然不可能相互独立。
根据个体学习器的生成方式,目前的集成学习方法大致分为两大类:
1. 个体学习器间存在强依赖关系,必须串行生成的序列化方法,如 Boosting
2. 个体学习器间不存在强依赖关系,可同时生成并行化方法,如Bagging 和 Random Forest
2. Boposting & AdaBoost
Boosting: 先从初始训练集训练一个基学习器,再根据学习器的表现对训练样本分布进行调整,使得先前基类学习器做错的训练样本在后续受到更多关注,然后基于调整后的样本分布来训练下一个基学习器;如此反复进行,直至基学习器达到事先指定值$T$,最终将这$T$个基学习器进行加权结合。

Boosting族算法中最著名的代表就是AdaBoost。
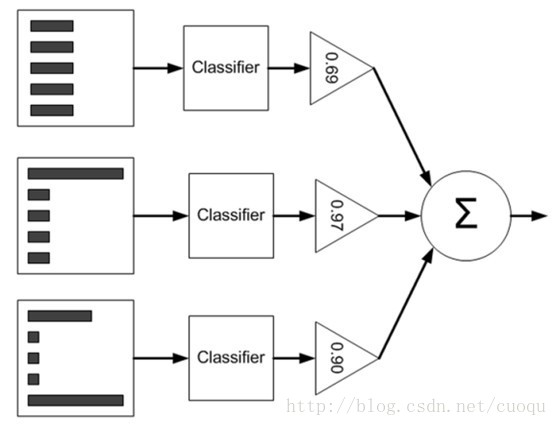
这是AdaBoost的原理示意图:左边矩形表示数据集$D$,中间是各个个体学习器,右边三角形是对每个弱学习器赋予的权重 $\alpha$ ,最后根据每个弱学习器的加权组合来判断总体类别。要注意一下数据集从上到下三个矩形内直方图不一样,这表示每个样本的权重 $\mathcal{D}$ 也发生了变化,样本的权重一开始初始化为相等的权重,然后根据弱学习器的错误率 $\epsilon$ 来调整每个弱学习器的权重 $\alpha$以及样本权重 $\mathcal{D}$.
具体过程如下:
|
|
The error $\epsilon$ is given by and $\alpha$ is given by $\mathcal{D}_{t+1,i} = \frac{\mathcal{D}_{t,i}}{Z_t} {\times} e^{-\alpha_t f(x_i) h_t(x_i)}$ $Z_t = \sum_{i=1}^{m}\mathcal{D}_{t,i} {\times} e^{-\alpha_t f(x_i) h_t(x_i)}$ 1、弱分类器的选取弱分类器的选取并没有一个特定的标准或选取准则,一般来说只要是能够实现基本的分类功能的分类器均可以作为adaboost中的弱分类器。 2、分类误差大于0.5,终止算法分类误差大于0.5代表当前的分类器是否比随机预测要好,对于一个随机预测模型来说,其分类误差就是0.5,即一半预测对,一半预测错。若当前的弱分类器还没有随机预测的效果好,那便直接终止算法。但是当adaboost遇到这种情形时可能学习的迭代次数远远没有达到初始设置的迭代次数M,这可能会导致最终集成中只有很少的弱分类器,从而导致算法整体性能不佳。为了化解这种情况Kohavi在《Bias plus variance decomposition for zero-one loss functions》提出了用重采样法使得迭代过程重新启动。
|

参考:
周志华 机器学习
http://blog.csdn.net/sinat_17451213/article/details/51055718
http://blog.csdn.net/marvin521/article/details/9319459
http://blog.csdn.net/autocyz/article/details/51305999
7. ensemble learning & AdaBoost的更多相关文章
- 6. Ensemble learning & AdaBoost
1. ensemble learning 集成学习 集成学习是通过构建并结合多个学习器来完成学习任务,如下图: 集成学习通过将多个学习学习器进行结合,常可以获得比单一学习器更优秀的泛化性能 从理论上来 ...
- 4. 集成学习(Ensemble Learning)Adaboost
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 【软件分析与挖掘】Multiple kernel ensemble learning for software defect prediction
摘要: 利用软件中的历史缺陷数据来建立分类器,进行软件缺陷的检测. 多核学习(Multiple kernel learning):把历史缺陷数据映射到高维特征空间,使得数据能够更好地表达: 集成学习( ...
- Ensemble Learning 之 Bagging 与 Random Forest
Bagging 全称是 Boostrap Aggregation,是除 Boosting 之外另一种集成学习的方式,之前在已经介绍过关与 Ensemble Learning 的内容与评价标准,其中“多 ...
- Ensemble Learning: Bootstrap aggregating (Bagging) & Boosting & Stacked generalization (Stacking)
Booststrap aggregating (有些地方译作:引导聚集),也就是通常为大家所熟知的bagging.在维基上被定义为一种提升机器学习算法稳定性和准确性的元算法,常用于统计分类和回归中. ...
- 第七章——集成学习和随机森林(Ensemble Learning and Random Forests)
俗话说,三个臭皮匠顶个诸葛亮.类似的,如果集成一系列分类器的预测结果,也将会得到由于单个预测期的预测结果.一组预测期称为一个集合(ensemble),因此这一技术被称为集成学习(Ensemble Le ...
- 壁虎书7 Ensemble Learning and Random Forests
if you aggregate the predictions of a group of predictors,you will often get better predictions than ...
- 7. 集成学习(Ensemble Learning)Stacking
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
- 6. 集成学习(Ensemble Learning)算法比较
1. 集成学习(Ensemble Learning)原理 2. 集成学习(Ensemble Learning)Bagging 3. 集成学习(Ensemble Learning)随机森林(Random ...
随机推荐
- 8-07CONTIUE 、 BREAK、RETURN
CONTIUE: 可以让程序跳过CONTIUE关键字之后的语句,回到WHILE循环的第一行命令. BREAK:让程序跳出循环,结束WHILE的循环. BREAK: 让系统完全跳出循环,结束WHILE循 ...
- Image Blending
给定两幅或者多幅图像,如何无缝自然拼接,这就是Image Blending 需要解决的问题(演示效果请看http://blog.sina.com.cn/s/blog_67f034a50100iuqt. ...
- 如何判断css是否加载完成
要判断这个 CSS 文件是否加载完毕,各个浏览器的做法差异比较大,这次要说IE浏览器做的不错,我们可以直接通过onload方法来处理CSS加载完成以后的处理: // 代码节选至seajs functi ...
- java调用sqlldr导入csv文件数据到临时表
package cn.com.file;import java.io.BufferedReader;import java.io.BufferedWriter;import java.io.File; ...
- Main 程序的入口要做哪些事情
Main 程序的入口要做哪些事: 1.从主类中实例化程序(UIApplication)对象 2.如果有委托的话,从给定的类实例化委托和设置程序(UIApplication) 的代理. 3.开启主事件的 ...
- Mac下各种网络命令的使用
Mac下各种网络命令的使用(http://blog.51yip.com/linux/745.html) pingwww.baidu.com 会一直ping下去,和windows不一样, windows ...
- ZeroMQ接口函数之 :zmq_recvmsg – 从一个socket上接收一个消息帧
ZeroMQ 官方地址 :http://api.zeromq.org/4-1:zmq-recvmsg zmq_recvmsg(3) ØMQ Manual - ØMQ/4.1.0 Nam ...
- 使用express-generator初始化你的项目目录
express 4.x以后将express命令独立到 express-generator包中,所以想使用express初始化项目目录,可以npm install express-genrator ...
- RunLoop和autorelease的一道面试题
有这么一道iOS面试题 以下代码有没有什么问题?如果有?如何解决? for (int i = 0; i < largeNumber; i++) { NSString *str = [NSStri ...
- 【转】logback logback.xml常用配置详解(一)<configuration> and <logger>
原创文章,转载请指明出处:http://aub.iteye.com/blog/1101260, 尊重他人即尊重自己 详细整理了logback常用配置, 不是官网手册的翻译版,而是使用总结,旨在更快更透 ...