Python【8】-分析json文件
一、本节用到的基础知识
1.逐行读取文件
for line in open('E:\Demo\python\json.txt'):
print line
2.解析json字符串
Python中有一些内置模块可以非常便捷地将json字符串转换为Python对象。比如json模块中的json.relaods()方法可以将json字符串解析为相应的字典。
import json
s='{ "a": "GoogleMaps\/RochesterNY", "c": "US", "nk": 0, "tz": "America\/Denver", "gr": "UT", "g": "mwszkS", "h": "mwszkS", "l": "bitly", "hh": "1.usa.gov", "r": "http:\/\/www.AwareMap.com\/", "u": "http:\/\/www.monroecounty.gov\/etc\/911\/rss.php", "t": 1331926741, "hc": 1308262393, "cy": "Provo", "ll": [ 40.218102, -111.613297 ] }'
o=json.loads(s)
print o
运行结果:
{u'a': u'GoogleMaps/RochesterNY', u'c': u'US', u'nk': 0, u'tz': u'America/Denver', u'gr': u'UT', u'g': u'mwszkS', u'h': u'mwszkS', u'cy': u'Provo', u'l': u'bitly', u'hh': u'1.usa.gov', u'r': u'http://www.AwareMap.com/', u'u': u'http://www.monroecounty.gov/etc/911/rss.php', u't': 1331926741, u'hc': 1308262393, u'll': [40.218102, -111.613297]}
3.列表生成式
详见:http://www.cnblogs.com/janes/p/5530979.html
二、将json文件解析为字典列表
要对json文件进行分析,首先我们逐行读取该文件,并把每行转换成对应的字典对象,然后组成一个列表。
import json
#读取文件并解析为字典组成的列表
dicList=[json.loads(line) for line in open('E:\Demo\python\json.txt')]
#打印第一个字典元素
print dicList[0]
#打印第一个元素中的时区
print dicList[0]['tz']
运行结果:
{u'a': u'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.11 (KHTML, like Gecko) Chrome/17.0.963.78 Safari/535.11', u'c': u'US', u'nk': 1, u'tz': u'America/New_York', u'gr': u'MA', u'g': u'A6qOVH', u'h': u'wfLQtf', u'cy': u'Danvers', u'l': u'orofrog', u'al': u'en-US,en;q=0.8', u'hh': u'1.usa.gov', u'r': u'http://www.facebook.com/l/7AQEFzjSi/1.usa.gov/wfLQtf', u'u': u'http://www.ncbi.nlm.nih.gov/pubmed/22415991', u't': 1331923247, u'hc': 1331822918, u'll': [42.576698, -70.954903]}
America/New_York
三、利用Python标准库统计json文件中的时区数据
1.首先将所有时区数据放在一个列表中
#获取所有时区数据
timezones=[item['tz'] for item in dicList if 'tz' in item]
#测试打印前五条
print timezones[0:5]
运行结果:
[u'America/New_York', u'America/Denver', u'America/New_York', u'America/Sao_Paulo', u'America/New_York']
2.然后将时区列表转换为时区计数字典,key为时区名,value为出现次数。
#自定义函数,统计时区出现次数
def countZone(timezones):
count_zone={}
for tz in timezones:
if(tz in count_zone):
count_zone[tz]+=1
else:
count_zone[tz]=1
return count_zone #自定义函数,返回top N
def countTop(dicCount,n):
valueKeyItems=[(value,key) for key,value in dicCount.items()]
valueKeyItems.sort()
return valueKeyItems[-n:] #测试并打印出现次数最多的5个时区
count=countZone(timezones)
print countTop(count,5)
运行结果:
[(191, u'America/Denver'), (382, u'America/Los_Angeles'), (400, u'America/Chicago'), (521, u''), (1251, u'America/New_York')]
3.利用defaultdict简化函数countZone函数
Python标准库collections对一些数据结构进行了拓展操作,使用起来更加便捷,其中defaultdict可以给字典赋值默认value。
from collections import defaultdict,Counter
def countZone(timezones):
count_zone=defaultdict(int)
for tz in timezones:
count_zone[tz]+=1
return count_zone
4.利用collections.Counter简化countTop函数
from collections import Counter def countTop(dicCount,n):
return Counter(dicCount).most_common(n)
5.完整代码
# -*- coding: utf-8 -*-
import json
#1.读取文件并转换为字典列表
#读取文件并解析为字典组成的列表
dicList=[json.loads(line) for line in open('E:\Demo\python\json.txt')] #2.统计时区
#获取所有时区数据
timezones=[item['tz'] for item in dicList if 'tz' in item] #统计时区出现次数
from collections import defaultdict,Counter
def countZone(timezones):
count_zone=defaultdict(int)
for tz in timezones:
count_zone[tz]+=1
return count_zone #返回top N
def countTop(dicCount,n):
return Counter(dicCount).most_common(n) #测试并打印出现次数最多的5个时区
count=countZone(timezones)
print countTop(count,5)
#运行结果:[(u'America/New_York', 1251), (u'', 521), (u'America/Chicago', 400), (u'America/Los_Angeles', 382), (u'America/Denver', 191)]
四 利用pandas统计json文件中的时区数据
1.运用DataFrame统计时区数据
①DataFrame是pandas中很常用的数据结构,它把数据转换为一个类似表格的结构。
# -*- coding: utf-8 -*-
import json
from pandas import DataFrame
dicList=[json.loads(line) for line in open('E:\Demo\python\json.txt')]
frame=DataFrame(dicList)
#测试打印时区列表中前5个元素
print frame['tz'][:5]
运行结果:
0 America/New_York
1 America/Denver
2 America/New_York
3 America/Sao_Paulo
4 America/New_York
②frame['tz']有value_counts()函数,可以直接返回对应的计数。
#打印出现次数最多的5个时区
print frame['tz'].value_counts()[:5]
运行结果:
America/New_York 1251
521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
③为不存在时区数据或者时区为空字符串的数据补全默认值。
fillna()函数可以补全不存在的字段;空字符串可以通过布尔型索引的形式进行替换。
tzList=frame['tz'].fillna('Missing')
tzList[tzList =='']='Unknown'
print tzList.value_counts()[:5]
运行结果:
America/New_York 1251
Unknown 521
America/Chicago 400
America/Los_Angeles 382
America/Denver 191
这样我们就完成了之前用标准Python库相同的工作,完整代码如下:
# -*- coding: utf-8 -*-
import json
from pandas import DataFrame
dicList=[json.loads(line) for line in open('E:\Demo\python\json.txt')]
frame=DataFrame(dicList)
#打印出现次数最多的5个时区
print frame['tz'].value_counts()[:5] #补全时区不存在或者为空的情况
tzList=frame['tz'].fillna('Missing')
tzList[tzList =='']='Unknown'
print tzList.value_counts()[:5]
2.利用plot方法绘制垂直条形图
参考:http://pandas.pydata.org/pandas-docs/stable/generated/pandas.DataFrame.plot.html
tzList.value_counts()[:5].plot(kind='bar',rot=0)
运行:我们可以利用%paste命令将代码粘贴运行。
命令行:
ipython %pylab %paste
运行结果:
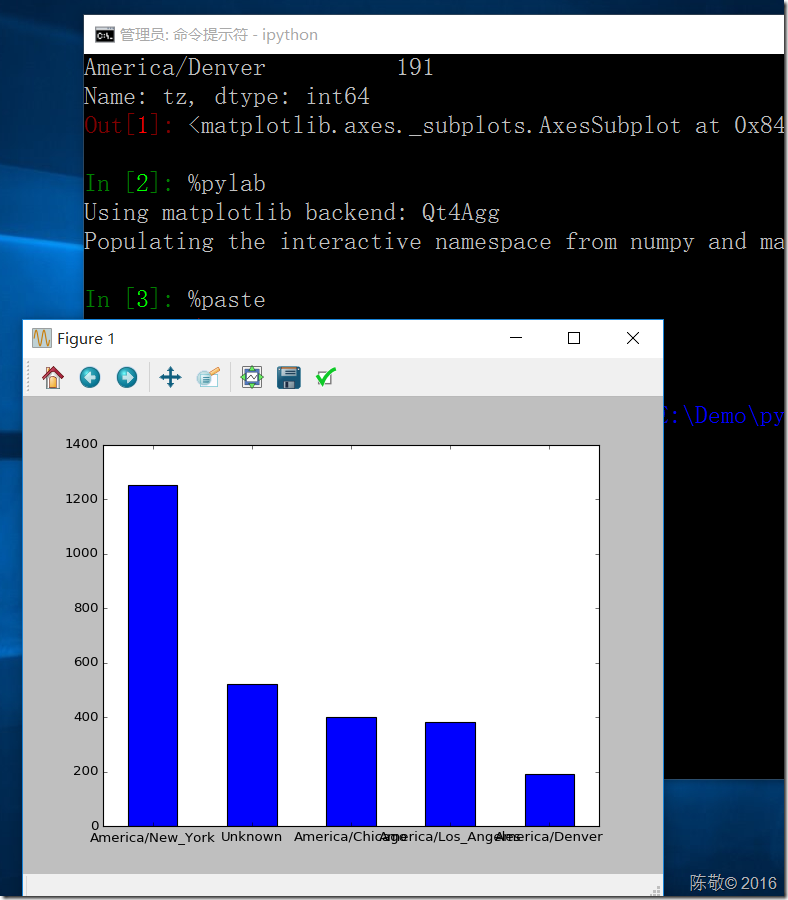
本文用到的json文件:点此下载
参考:《利用Python进行数据分析》
如需转载,请标明出处:http://www.cnblogs.com/janes/p/5546673.html
Python【8】-分析json文件的更多相关文章
- python脚本解析json文件
python脚本解析json文件 没写完.但是有效果.初次尝试,写的比较不简洁... 比较烦的地方在于: 1,中文编码: pSpecs.decode('raw_unicode_escape') 2,花 ...
- python中读取json文件报错,TypeError:the Json object must be str, bytes or bytearray,not ‘TextIOWrapper’
利用python中的json读取json文件时,因为错误使用了相应的方法导致报错:TypeError:the Json object must be str, bytes or bytearray,n ...
- python脚本将json文件生成C语言结构体
1.引言 以前用过python脚本根据excel生成相关C语言代码,其实本质就是文件的读写,主要是逻辑问题,这次尝试将json文件生成C语言的结构体. 2.代码 这是一个json文件,生成这个结构体的 ...
- Python实现读取json文件到excel表
一.需求 1.'score.json' 文件内容: { "1":["小花",99,100,98.5], "2":["小王" ...
- python 数据写入json文件时中文显示Unicode编码问题
一.问题描述 import json dir = { '春晓':'asfffa', '春眠不觉晓' : '处处闻啼鸟', '夜来风雨声' : 56789, 'asdga':'asdasda' } fp ...
- Python 3 操作json 文件
背景 json 是一种轻量级的数据交换格式.易于人阅读和编写,同时也易于机器解析和生成. 一般表现形式是一个无序的 键值对 的集合. 资料: 官方文档: https://docs.python.org ...
- python加载json文件
主要是加载进来,之后就没难度了 import json path = 'predict2.json' file = open(path, "rb") fileJson = json ...
- Python【读写Json文件】
indent=10:缩进10个空格
- python json及mysql——读取json文件存sql、数据库日期类型转换、终端操纵mysql及python codecs读取大文件问题
preface: 近期帮师兄处理json文件,须要读到数据库里面,以备其兴许从数据库读取数据.数据是关于yelp站点里面的: https://github.com/Yelp/dataset-examp ...
随机推荐
- OC-《购票系统》
来个命令行的购票系统 --1-- 需求分析 1.1 分析 1.2 功能分析 1.3 流程分析 --2-- 原型展示 2.1 界面原型 --3-- 系统设计 3.1 类设计 3.2 框架模块设计 --4 ...
- Java注解和代理实现
1.定义注解 import java.lang.annotation.Documented; import java.lang.annotation.ElementType; import java. ...
- Java,double类型转换成String,String装换成double型
今天,老师布置了小系统,银行用户管理系统,突然发现自己的基础知识好薄弱,就把这些记录一下, double类型转化string:Double.toString(double doub); String类 ...
- 有向图的强连通分量的求解算法Tarjan
Tarjan算法 Tarjan算法是基于dfs算法,每一个强连通分量为搜索树中的一颗子树.搜索时,把当前搜索树中的未处理的结点加入一个栈中,回溯时可以判断栈顶到栈中的结点是不是在同一个强连通分量中.当 ...
- Network网络
ifconfig 查看服务器网卡名称 ethtool ethXXX 查看网卡具体信息 要测试一个网卡是否真是1000M的,最保险的说用wget测试一个对方的带宽足够大的下载地址 wget http:/ ...
- 网易测试分享会——“一起打造你想要的QA团队”
昨天(2016.11.30)参加了网易资深测试专家王晓明的测试分享会——“一起打造你想要的QA团队”,以下为笔者做的归纳总结. 重点 1.让测试更加容易做好.不容易测试的代码,不具有健壮性. 2.Ke ...
- laravel框架总结(十一) -- 集合
创建集合: collect 辅助函数会利用传入的数组生成一个新的 Illuminate\Support\Collection 实例. $collection = collect([1, 2, 3] ...
- javaScript AJAX
AJAX的实现 var sAjax = function () { var sendMsg = { url: "", sendType: "POST", Con ...
- 工作中积累整理-CSS样式表(一)
[layout] clear:该属性的值指出了不允许有浮动对象的边. 默认值:none none: 允许两边都可以有浮动对象 both: 不允许有浮动对象 left: 不允许左边有浮动对象 right ...
- Linux and the Device Tree
来之\kernel\Documentation\devicetree\usage-model.txt Linux and the Device Tree ----------------------- ...