SparkStreaming(源码阅读十二)
要完整去学习spark源码是一件非常不容易的事情,但是咱可以积少成多嘛~那么,Spark Streaming是怎么搞的呢?
本质上,SparkStreaming接收实时输入数据流并将它们按批次划分,然后交给Spark引擎处理生成按照批次划分的结果流:

SparkStreaming提供了表示连续数据流的、高度抽象的被称为离散流的Dstream,可以使用kafka、Flume和Kiness这些数据源的输入数据流创建Dstream,也可以在其他Dstream上使用map、reduce、join、window等操作创建Dsteram。Dstream本质上呢,是表示RDD的序列。
Spark Streaming首先将数据切分为一定时间范围(Duration)的数据集,然后积累一批(Batch)Duration数据集后单独启动一个任务线程处理。Spark核心提供的从DAG重新调度任务和并行执行,能够快速完成数据从故障中恢复的工作。
那么下来就从SparkStreaming 的StreamingContext初始化开始:
StreamingContext传入的参数:1、SparkContext也就是说Spark Streaming的最终处理实际是交给SparkContext。2、Checkpoint:检查点.3、Duration:设定streaming每个批次的积累时间。当然,也可以不用设置检查点。

Dstream是Spark Streaming中所有数据流的抽象,这里对抽象类Dstream定义的一些主要方法:
1、dependencies:Dstream依赖的父级Dstream列表。
2、comput(validTime:Time):指定时间生成一个RDD。
3、isInitialized:Dstream是否已经初始化。
4、persist(level:StorageLevel):使用指定的存储级别持久化Dstream的RDD。
5、persist:存储到内存
6、cache:缓存到内存,与persisit方法一样。
(这里详细说下cache与persist的不同点:cache只有一个默认的缓存级别MEMORY_ONLY ,而persist可以根据情况设置其它的缓存级别。)
7、checkpoint(interval:Duration):设置Dstream及祖宗Dstream的DstreamGraph;
8、getOrCompute(time:Time):从缓存generatedRDDs = new HashMap[Time,RDD[T]]中获取RDD,如果缓存不存在,则生成RDD并持久化、设置检查点放入缓存。
9、generateJob(time:Time):给指定的Time对象生成Job.
10、window(windowDuration:Duration):基于原有的Dstream,返回一个包含了所有在时间滑动窗口中可见元素的新的Dstream.
......
Dsteam本质上是表示连续的一些列的RDD,Dstream中的每个RDD包含了一定间隔的数据,任何对Dstream的操作都会转化为底层RDD的操作。在Spark Streaming中,Dstream提供的接口与RDD提供的接口非常相似。构建完ReciverInputDStream后,会调用各种Dstream的接口方法,对Dstream进行各种转换,最后各个Dstream之间的依赖关系就形成了一张DStream Graph:
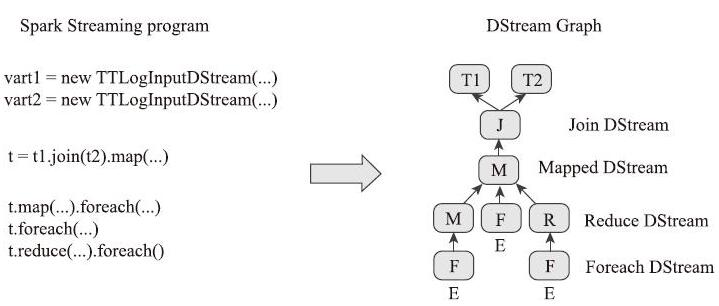
整个流程所涉及的组件为:
1、Reciever:Spark Streaming内置的输入流接收器或用户自定义的接收器,用于从数据源接收源源不断的数据流。
2、currentBuffer:用于缓存输入流接收器接收的数据流。
3、blockIntervalTimer:一个定时器,用于将CurrentBuffer中缓存的数据流封装为Block后放入blocksForPushing。
4、blockForPushing:用于缓存将要使用的Block。
5、blockPushingThread:此线程每隔100毫秒从blocksForPushing中取出一个Block存入存储体系,并缓存到ReceivedBlockQueue。
6、Block Batch:Block批次,按照批次时间间隔,从RecievedBlockQueue中获取一批Block。
7、JobGenerator:Job生成器,用于给每一批Blcok生成一个Job。
下来继续回到StreamingContext,在StreamingContext中new了一个JobScheduler,它里面创了EventLoop,对这个名字是不是很熟悉?没错,就是在Netty通信交互时创建的对象,主要用于处理JobSchedular的事件。然后启动StrreamingListenerBus,用于更新Spark UI中的StreamTab的内容。 那么最重要的就是下来创建ReceiverTracker,它用于处理数据接收、数据缓存、Block生成等工作。最后启动JobGenerator,负责对DstreamGraph的初始化、Dstream与RDD的转换、生成JOB、提交执行等工作。
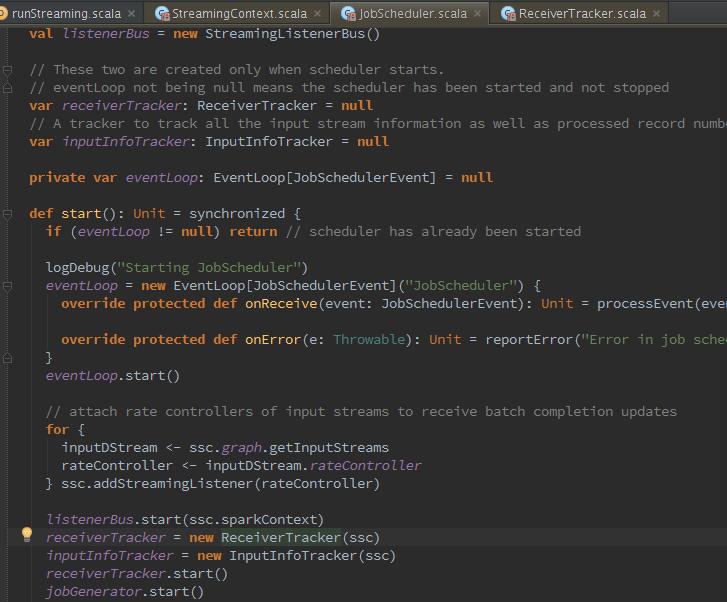
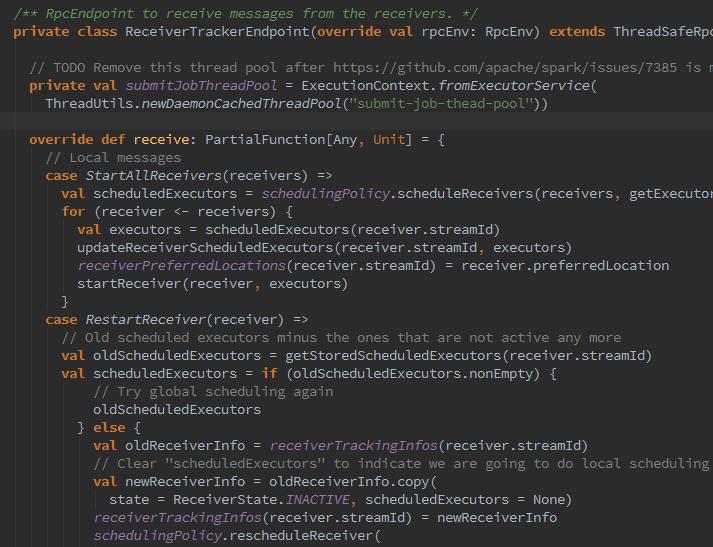
曾经是用ReciverTrackerActor接收来自Reciver的消息,包括RegisterReceiver、AddBlock、ReportError、DeregisterReceiver等,现在不再使用Akka进行通信,而是使用RPC。
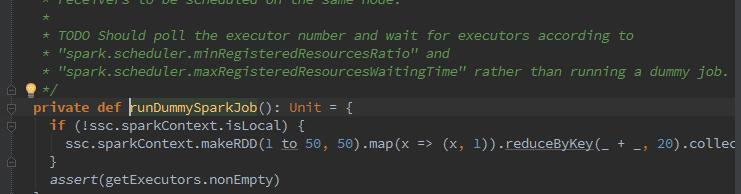
 回到launchReceivers,调用了SparkContext的makeRDD方法,将所有Receiver封装为ParallelCollectionRDD,并行度是receivers的数量,makeRDD方法实际调用了parallelize:
回到launchReceivers,调用了SparkContext的makeRDD方法,将所有Receiver封装为ParallelCollectionRDD,并行度是receivers的数量,makeRDD方法实际调用了parallelize:
今天到此为止。。明天再来会你这磨人的小妖精,玩别的去啦~~~
参考文献:《深入理解Spark:核心思想与源码分析》
SparkStreaming(源码阅读十二)的更多相关文章
- OpenJDK源码研究笔记(十二):JDBC中的元数据,数据库元数据(DatabaseMetaData),参数元数据(ParameterMetaData),结果集元数据(ResultSetMetaDa
元数据最本质.最抽象的定义为:data about data (关于数据的数据).它是一种广泛存在的现象,在许多领域有其具体的定义和应用. JDBC中的元数据,有数据库元数据(DatabaseMeta ...
- 【原】FMDB源码阅读(二)
[原]FMDB源码阅读(二) 本文转载请注明出处 -- polobymulberry-博客园 1. 前言 上一篇只是简单地过了一下FMDB一个简单例子的基本流程,并没有涉及到FMDB的所有方方面面,比 ...
- 【原】AFNetworking源码阅读(二)
[原]AFNetworking源码阅读(二) 本文转载请注明出处 —— polobymulberry-博客园 1. 前言 上一篇中我们在iOS Example代码中提到了AFHTTPSessionMa ...
- 【原】SDWebImage源码阅读(二)
[原]SDWebImage源码阅读(二) 本文转载请注明出处 —— polobymulberry-博客园 1. 解决上一篇遗留的坑 上一篇中对sd_setImageWithURL函数简单分析了一下,还 ...
- 【详解】ThreadPoolExecutor源码阅读(二)
系列目录 [详解]ThreadPoolExecutor源码阅读(一) [详解]ThreadPoolExecutor源码阅读(二) [详解]ThreadPoolExecutor源码阅读(三) AQS在W ...
- Redis源码阅读(二)高可用设计——复制
Redis源码阅读(二)高可用设计-复制 复制的概念:Redis的复制简单理解就是一个Redis服务器从另一台Redis服务器复制所有的Redis数据库数据,能保持两台Redis服务器的数据库数据一致 ...
- Caddy源码阅读(二)启动流程与 Event 事件通知
Caddy源码阅读(二)启动流程与 Event 事件通知 Preface Caddy 是 Go 语言构建的轻量配置化服务器.https://github.com/caddyserver/caddy C ...
- 【 js 基础 】【 源码学习 】backbone 源码阅读(二)
最近看完了 backbone.js 的源码,这里对于源码的细节就不再赘述了,大家可以 star 我的源码阅读项目(source-code-study)进行参考交流,有详细的源码注释,以及知识总结,同时 ...
- Rpc框架dubbo-client(v2.6.3) 源码阅读(二)
接上一篇 dubbo-server 之后,再来看一下 dubbo-client 是如何工作的. dubbo提供者服务示例, 其结构是这样的!dubbo://192.168.11.6:20880/com ...
随机推荐
- C++操作MySQL大量数据插入效率低下的解决方法
#include <iostream> #include <winsock2.h> #include <string> #include "mysql.h ...
- MVC+MQ+WinServices+Lucene.Net Demo
前言: 我之前没有接触过Lucene.Net相关的知识,最近在园子里看到很多大神在分享这块的内容,深受启发.秉着“实践出真知”的精神,再结合公司项目的实际情况,有了写一个Demo的想法,算是对自己能力 ...
- awk(2)-模式(pattern)
在上文 awk(1)-简述我们将简要描述了awk的主要使用方向和构成(由一个或多个模式-动作组成),本小节主要讲述awk的各种模式. ps:例子中使用的输入文件(如countries)内容可由awk( ...
- BP神经网络
秋招刚结束,这俩月没事就学习下斯坦福大学公开课,想学习一下深度学习(这年头不会DL,都不敢说自己懂机器学习),目前学到了神经网络部分,学习起来有点吃力,把之前学的BP(back-progagation ...
- arcgis制作兴趣点分布图
数据准备: 1.矢量:芜湖市区行政区.shp 企业分布点.shp 2.影像:Landsat 8 软件:arcgis 10.3 Envi4.8 目的:制作一幅以市区行政区为底图的企业分布点的图,同时 ...
- seo查询命令
以下内容均来自网络,只是稍微整理 感觉比较好用的是1.2.5.6.11.12.13条 1. site指令: 查询某个特定网站收录情况. 比如查询6676小游戏收录格式即为:site:www.6676. ...
- 根据内存布局定位的一个fastdfs坑
在使用fastdfs时,编写数据上传代码时,遇到一个坑.最终根据指针对应的内存布局定位到一个其client API的一个坑,值得记录一下.具体是在 tracker_connect_server() 这 ...
- ionic cordova 热更新的一些问题
因为项目需要用到更新这一块的东西,所以就查了下cordova 的热更新,然后遇到了 一些问题,记录下来备忘. 项目用的是ionic 下载cordova的内容就直接跳过了. 首先是下载cordova的插 ...
- UE4 4.14 专用服务器没有生成解决办法
简单说一下UE4 专用服务器的生成(网上也有其它版本的但是在4.14.1 上不管用) 1.用源代码编译的引擎(如何获取百度上有很多介绍)创建一个C++ UE4 工程. 2. 在vs 中找到红色这个文件 ...
- Nutch主要类代码分析之一(Injector)
Injector(org.apache.nutch.crawl.Injector): 输入:种子列表文件所在的目录 输出:crawldb(保存URL以及其相应信息的数据库) 作用:把种子URL注入到c ...