k-近邻(KNN) 算法预测签到位置
分类算法-k近邻算法(KNN):
定义:
如果一个样本在特征空间中的k个最相似 (即特征空间中最邻近) 的样本中的大多数属于某一个类别,则该样本也属于这个类别
来源:
KNN算法最早是由Cover和Hart提出的一种分类算法
计算距离公式:
两个样本的距离可以通过如下公式计算,又叫欧氏距离,比如说
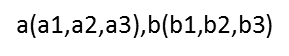
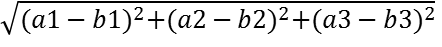
sklearn k-近邻算法API:


问题:
1. k值取多大?有什么影响?
k值取很小:容易受到异常点的影响
k值取很大:容易受最近数据太多导致比例变化
2. 性能问题
k-近邻算法的优缺点:
优点:
简单、易于理解,无需估计参数,无需训练
缺点:
懒惰算法,对测试样本分类时的计算量大,内存开销大
必须制定k值,k值选择不当则分类精度不能保证
使用场景:
小数据场景,几千~几万样本,具体场景具体业务去测试
k近邻算法实例-预测签到位置:
数据来源:
kaggle官网,链接地址:https://www.kaggle.com/c/facebook-v-predicting-check-ins/data (需官网登录后下载)
数据的处理:
1. 缩小数值范围: DataFrame.query(),因为数据量过大,所以获取部分数据
2. 处理日期数据: pd.to_datetime() 、pd.DatetimeIndex(),两个pandas库的接口
3. 增加分割的日期数据: 把源数据里面的时间戳数据转换分割后,添加为新列,day、hour等
4. 删除没用的数据: pd.drop() ,pandas库的接口
5. 将签到位置少于n个用户的数据删除,一些pandas库知识:
place_count = data.groupby('place_id').aggregate(np.count_nonzero)
tf = place_count[place_count.row_id>3].rest_index()
data = data[data['place_id'].isin(tf.place_id)]
实例流程:
1. 数据集的处理
2. 分割数据集
3. 对数据集进行表转化
4. estimator流程进行分类预测
代码实现:
import os
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier
from sklearn.preprocessing import StandardScaler def knn_cls():
"""K-近邻算法预测用户签到的位置""" # 一、读取数据
fb_location = os.path.join(os.path.join(os.path.curdir, 'data'), 'fb_location')
data = pd.read_csv(os.path.join(fb_location, 'train.csv'))
# print(data.head(10)) # 二、处理数据
# 1.缩小数据,查询数据筛选
data = data.query('x>1.0 & x<1.25 & y>2.5 & y<2.75')
# 2.处理时间的数据
time_value = pd.to_datetime(data['time'], unit='s') # 精确到秒
# print(time_value)
# 3.把日期格式转化为字典格式
time_value = pd.DatetimeIndex(time_value)
# 4.构造一些特征
data.loc[:,'day'] = time_value.day
data.loc[:,'hour'] = time_value.hour
data.loc[:,'weekday'] = time_value.weekday
# 5.把时间戳特征删除
data.drop(['time'], axis=1, inplace=True)
# print(data)
# 6.把签到数量小于n个目标位置删除
place_count = data.groupby('place_id').count()
tf = place_count[place_count.row_id>3].reset_index()
data = data[data['place_id'].isin(tf.place_id)]
# 7.取出特征值和目标值
y = data['place_id']
x = data.drop(['place_id', 'row_id'], axis=1)
# 8.进行数据的分割,训练集和测试集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25) # 三、特征工程(标准化)
std = StandardScaler()
# 对测试集和训练集的特征值进行标准化
x_train = std.fit_transform(x_train)
x_test = std.transform(x_test) # 这里用std.transform就不用fit去重新计算平均值标准差一类的了 # 四、进行算法流程
knn = KNeighborsClassifier(n_neighbors=9) # fit, predict, score
knn.fit(x_train, y_train) # 四、得出预测结果和准确率
y_predict = knn.predict(x_test)
print('预测的目标签到位置为:', y_predict)
print('预测的准确率: ', knn.score(x_test, y_test)) if __name__ == '__main__':
knn_cls()
k-近邻(KNN) 算法预测签到位置的更多相关文章
- 机器学习经典算法具体解释及Python实现--K近邻(KNN)算法
(一)KNN依旧是一种监督学习算法 KNN(K Nearest Neighbors,K近邻 )算法是机器学习全部算法中理论最简单.最好理解的.KNN是一种基于实例的学习,通过计算新数据与训练数据特征值 ...
- 机器学习-K近邻(KNN)算法详解
一.KNN算法描述 KNN(K Near Neighbor):找到k个最近的邻居,即每个样本都可以用它最接近的这k个邻居中所占数量最多的类别来代表.KNN算法属于有监督学习方式的分类算法,所谓K近 ...
- 查看neighbors大小对K近邻分类算法预测准确度和泛化能力的影响
代码: # -*- coding: utf-8 -*- """ Created on Thu Jul 12 09:36:49 2018 @author: zhen &qu ...
- [Python] 应用kNN算法预测豆瓣电影用户的性别
应用kNN算法预测豆瓣电影用户的性别 摘要 本文认为不同性别的人偏好的电影类型会有所不同,因此进行了此实验.利用较为活跃的274位豆瓣用户最近观看的100部电影,对其类型进行统计,以得到的37种电影类 ...
- TensorFlow实现knn(k近邻)算法
首先先介绍一下knn的基本原理: KNN是通过计算不同特征值之间的距离进行分类. 整体的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于 ...
- k近邻(KNN)复习总结
摘要: 1.算法概述 2.算法推导 3.算法特性及优缺点 4.注意事项 5.实现和具体例子 6.适用场合内容: 1.算法概述 K近邻算法是一种基本分类和回归方法:分类时,根据其K个最近邻的训练实例的类 ...
- K近邻分类算法实现 in Python
K近邻(KNN):分类算法 * KNN是non-parametric分类器(不做分布形式的假设,直接从数据估计概率密度),是memory-based learning. * KNN不适用于高维数据(c ...
- 理解KNN算法中的k值-knn算法中的k到底指的是什么 ?
2019-11-09 20:11:26为方便自己收藏学习,转载博文from:https://blog.csdn.net/llhwx/article/details/102652798 knn算法是指对 ...
- k近邻 KNN
KNN是通过测量对象的不同特征值之间的距离进行分类.它的思路是:如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别,其中K通常是不大于20 ...
随机推荐
- MySQL数据分析-(15)表补充:存储引擎
大家好,我是jacky,很高兴继续跟大家分享<MySQL数据分析实战>,今天跟大家分享的主题是表补充之存储引擎: 我们之前学了跟表结构相关的一些操作,那我们看一下创建表的SQL模型: 在我 ...
- idea将项目打成jar包
在用jmeter做压测时,需要将项目打成jar包放至在如下目录 /Users/admin/Documents/software/apache-jmeter-5.1.1/apache-jmeter-5. ...
- nginx 配置简单 301 重定向
server { listen ; server_name your.first.domain; rewrite ^(.*) http://your.second.domain:8000$1 perm ...
- arcgis根据表字段进行数据合并
第一步 1.地理处理-----2.数据管理工具----3.制图综合----4.融合 第二步 打开融合面板,选择输入要素,要融合的字段,选择统计字段数量,完成融合.
- 快速上手系列-C语言之指针篇(一)
快速上手系列-C语言之指针篇(一) 浊酒敬风尘 发布时间:18-06-2108:29 指针的灵活运用使得c语言更加强大,指针是C语言中十分重要的部分,可以说指针是C语言的灵魂.当然指针不是万能的,但没 ...
- spaCy 第一篇:核心类型
spaCy 是一个号称工业级的自然语言处理工具包,最核心的数据结构是Doc和Vocab.Doc对象包含Token的序列和Token的注释(Annotation),Vocab对象是spaCy使用的词汇表 ...
- golang gorm框架的默认时区问题
gorm框架的时区是在连接数据库时设置的, 如下
- Mysql表的横向拆分与纵向拆分
表的拆分分为横向拆分(记录的拆分)和纵向拆分(字段的拆分).拆分表的目的:提高查询速度. 1.横向拆分 我们从一个案例去解释,情景是这样的:某某博客,有50W的博客量,有2w的用户,发现随着用户和博客 ...
- [idea][转]理解 IntelliJ IDEA 的项目配置和Web部署
1.项目配置的理解 IDEA 中最重要的各种设置项,就是这个 Project Structre 了,关乎你的项目运行,缺胳膊少腿都不行.最近公司正好也是用之前自己比较熟悉的IDEA而不是Eclipse ...
- Build Telemetry for Distributed Services之OpenTracing简介
官网地址:https://opentracing.io/ What is Distributed Tracing? Who Uses Distributed Tracing? What is Open ...