Linux C/C++基础——内存分区
1.内存分区
在生活中,为了提高办事效率,某个单位经常会分成N个部门,每个部门职责不同,同样,为了提高
效率,我们的内存也会被分成N个区。这里我们将内存分为五个区。也有四区模型。
首先看一下一个二进制可执行文件的结构
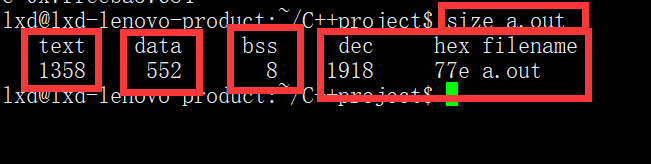
在程序没有执行前,有几个内存分区已经确定,虽然分区确定,但是没有加载内存,程序只有运行时
才加载内存:
- text(代码区):只读
- data:初始化的数据,全局变量,static变量,文字常量区(只读)
- bss:没有初始化的数据,全局变量,static变量
- dec,hex,filename保存的分别是十进制总和,十六进制总和,和文件名
除了上面这三个区,还额外增加了栈区和堆区
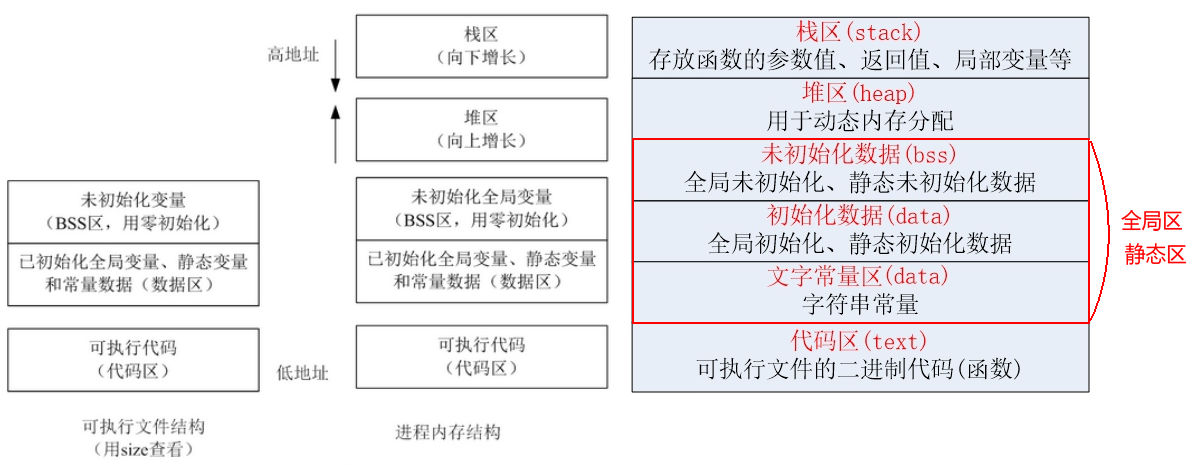
- 代码区:
加载的是可执行文件代码段,所有的可执行代码都加载到代码区,这块内存是不可以在运行期间修改的。
未初始化数据区(BSS)
加载的是可执行文件BSS段,位置可以分开亦可以紧靠数据段,存储于数据段的数据(全局未初始化,静态未初始化数据)
的生存周期为整个程序运行过程。
全局初始化数据区/静态数据区(data segment)
加载的是可执行文件数据段,存储于数据段(全局初始化,静态初始化数据,文字常量(只读))的数据的生存周期为整个程序运行过程。
栈区(stack)
栈是一种先进后出的内存结构,由编译器自动分配释放,存放函数的参数值、返回值、局部变量等。在程序运行过程中实时加载和释放,因此,局部变量的生存周期为申请到释放该段栈空间。
堆区(heap)
堆是一个大容器,它的容量要远远大于栈,但没有栈那样先进后出的顺序。用于动态内存分配。堆在内存中位于BSS区和栈区之间。一般由程序员分配和释放,若程序员不释放,程序结束时由操作系统回收。
栈区和堆区的空间都有限,定义变量时,不能分配很大的空间,否则会栈越界,导致段错误
#include<stdio.h> int main()
{
int a[]={};//语法没错,会栈越界 return ;
}
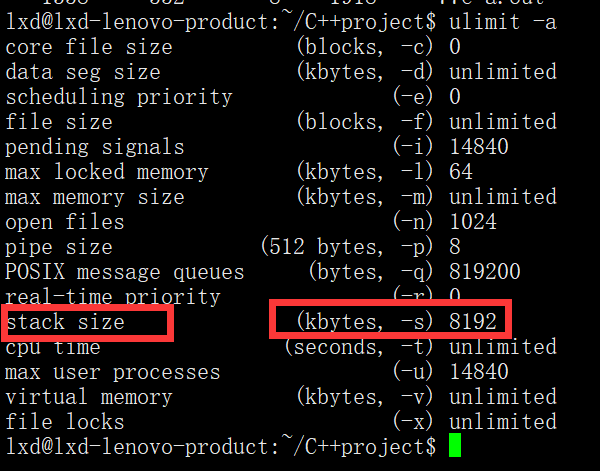
栈空间大小
堆区空间越界,但有的编译器检测不出来。
#include<stdlib.h>
#include<string.h>
#include<stdio.h> int main()
{
char *p=NULL;
p=(char*)malloc(sizeof()); //堆区空间为0,
if(p==NULL);
{
printf("分配失败\n");
return ;
}
strcpy(p,"helloworld");
printf("%s\n",p);
free(p);
return ; }

上面的代码,少了一个判断,没有检查出来,所示要尽量避免
#include<stdlib.h>
#include<string.h>
#include<stdio.h> int main()
{
char *p=NULL;
p=(char*)malloc(sizeof()); //堆区空间为0 strcpy(p,"helloworld");
printf("%s\n",p);
free(p);
return ;
}

Linux C/C++基础——内存分区的更多相关文章
- [内存管理]linux内存管理 之 内存节点和内存分区
Linux支持多种硬件体系结构,因此Linux必须采用通用的方法来描述内存,以方便对内存进行管理.为此,Linux有了内存节点.内存区.页框的概念,这些概念也是一目了然的. 内存节点:主要依据CPU访 ...
- Linux基础——硬盘分区、格式化及文件系统的管理
1. 硬件设备与文件名的对应关系 掌握在Linux系统中,每个设备都被当初一个文件来对待. 设备 设备在Linux内的文件名 IDE硬盘 /dev/hd[a-d] SCSI硬盘 /dev/sd[a-p ...
- #内存不够,swap来凑# Linux上创建SWAP文件/分区
转自:https://www.vmvps.com/how-to-create-a-swap-file-on-the-linux-os.html 很久很久以前,电脑的内存是个珍贵东西,于是乎就有了swa ...
- 2.Linux系统之硬盘与分区基础知识
我们是在虚拟机上安装的Linux系统.在安装的过程中,可能会遇到磁盘分区的问题,我们下面简单介绍一下分区的原理. 1.硬盘的基础知识 下面是一块空白的硬盘: 这是一块格式化后的硬盘: 格式化就是,在空 ...
- c语言学习之基础知识点介绍(十八):几个修饰关键字和内存分区
一.几个修饰关键字 全局变量: 全局变量跟函数一样也分为声明和实现.如果是全局变量,实现在它调用之后,那么需要在调用之前进行声明.注意:全局变量的声明只能写在函数外,写在函数就不是全局变量了而是局部变 ...
- java语言:Linux与JVM的内存关系分
在一些物理内存为8g的服务器上,主要运行一个Java服务,系统内存分配如下:Java服务的JVM堆大小设置为6g,一个监控进程占用大约 600m,Linux自身使用大约800m.从表面上,物理内存应该 ...
- 转: 关于Linux与JVM的内存关系分析
转自: http://tech.meituan.com/linux-jvm-memory.html Linux与JVM的内存关系分析 葛吒2014-08-29 10:00 引言 在一些物理内存为8g的 ...
- linux内核分析之内存管理
1.struct page /* Each physical page in the system has a struct page associated with * it to keep tra ...
- Linux与JVM的内存关系分析
引言 在一些物理内存为8g的server上,主要执行一个Java服务,系统内存分配例如以下:Java服务的JVM堆大小设置为6g,一个监控进程占用大约600m,Linux自身使用大约800m. 从表面 ...
随机推荐
- python脚本攻略之log日志
1 logging模块简介 logging模块是Python内置的标准模块,主要用于输出运行日志,可以设置输出日志的等级.日志保存路径.日志文件回滚等:相比print,具备如下优点: 可以通过设置不同 ...
- BZOJ 1758 / Luogu P4292 [WC2010]重建计划 (分数规划(二分/迭代) + 长链剖分/点分治)
题意 自己看. 分析 求这个平均值的最大值就是分数规划,二分一下就变成了求一条长度在[L,R]内路径的权值和最大.有淀粉质的做法但是我没写,感觉常数会很大.这道题可以用长链剖分做. 先对树长链剖分. ...
- BZOJ 4522: [Cqoi2016]密钥破解 exgcd+Pollard-Rho
挺简单的,正好能再复习一遍 $exgcd$~ 按照题意一遍一遍模拟即可,注意一下 $pollard-rho$ 中的细节. #include <ctime> #include <cma ...
- HDU 6154 CaoHaha's staff(2017中国大学生程序设计竞赛 - 网络选拔赛)
题目代号:HDU 6154 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=6154 CaoHaha's staff Time Limit: 2000/1 ...
- dup和dup2函数简单使用
dup函数 头文件和函数原型: #include <unistd.h> int dup(int oldfd); dup函数是用来打开一个新的文件描述符,指向和oldfd同一个文件,共享文件 ...
- AcWing:112. 雷达设备(贪心 + 笛卡尔坐标系化区间)
假设海岸是一条无限长的直线,陆地位于海岸的一侧,海洋位于另外一侧. 每个小岛都位于海洋一侧的某个点上. 雷达装置均位于海岸线上,且雷达的监测范围为d,当小岛与某雷达的距离不超过d时,该小岛可以被雷达覆 ...
- Codeforces 963 A. Alternating Sum(快速幂,逆元)
Codeforces 963 A. Alternating Sum 题目大意:给出一组长度为n+1且元素为1或者-1的数组S(0~n),数组每k个元素为一周期,保证n+1可以被k整除.给a和b,求对1 ...
- HDU 5818 Joint Stacks ——(栈的操作模拟,优先队列)
题意:有两个栈A和B,有3种操作:push,pop,merge.前两种都是栈的操作,最后一种表示的是如果“merge A B”,那么把B中的元素全部放到A中,且满足先入后出的栈原则. 分析:显然,我们 ...
- 【Nginx】Linux 环境下 Nginx 配置SSL 证书
一.解压三个包到相同目录编译nginx cd /usr/local/src/nginx-1.12.2 # 将下列的包版本号换成自己下载的版本号 ./configure --prefix=/usr/lo ...
- 前世今生:Hive、Shark、spark SQL
Hive (http://en.wikipedia.org/wiki/Apache_Hive )(非严格的原文顺序翻译) Apache Hive是一个构建在Hadoop上的数据仓库框架,它提供数据的 ...