文本三剑客之grep及正则表达式
1、grep
1. 什么是grep、egrep和fgrep
Linux系统中grep命令是一种强大的文本搜索工具,它能使用正则表达式搜索文本,并把匹配的行打印出来(匹配到的标红)。grep全称是Global Regular Expression Print,表示全局正则表达式版本,它的使用权限是所有用户。
grep的工作方式是这样的,它在一个或多个文件中搜索字符串模板。如果模板包括空格,则必须被引用,模板后的所有字符串被看作文件名。搜索的结果被送到标准输出,不影响原文件内容。
grep可用于shell脚本,因为grep通过返回一个状态值来说明搜索的状态,如果模板搜索成功,则返回0,如果搜索不成功,则返回1,如果搜索的文件不存在,则返回2。我们利用这些返回值就可进行一些自动化的文本处理工作。
egrep = grep -E:扩展的正则表达式 (除了\< , \> , \b 使用其他正则都可以去掉\)
fgrep=grep -F:不支持正则表达式,可以过滤普通的字符串
作用:文本搜索工具,根据用户指定的“模式”对目标文本逐行进行匹配检查;打印匹配到的行
模式:由正则表达式字符及文本字符所编写的过滤条件
用法:grep [OPTIONS] PATTERN [FILE...]
选项:
--color=auto: 对匹配到的文本着色显示
-v: 显示不被pattern匹配到的行
-i: 忽略字符大小写
-n:显示匹配的行号
-c: 统计匹配的行数
-o: 仅显示匹配到的字符串
-q: 静默模式,不输出任何信息
-A #: after, 后#行
-B #: before, 前#行
-C #:context, 前后各#行
-e:实现多个选项间的逻辑or关系
grep –e ‘cat ’ -e ‘dog’ file
-w:匹配整个单词
-E:使用ERE
-F:相当于fgrep,不支持正则表达式
-f file: 根据模式文件处理
2. grep实战演示
示例一:
将磁盘利用率进行倒序排序:
[root@ansibledata]#df | grep /dev/sd |tr -s " " % |cut -d% -f5 |sort -nr
17
5
1
示例二:
[root@ansibledata]#cat /etc/passwd | grep -nA1 root #过滤root的后一行
1:root:x:0:0:root:/root:/bin/bash
2-bin:x:1:1:bin:/bin:/sbin/nologin
--
10:operator:x:11:0:operator:/root:/sbin/nologin
11-games:x:12:100:games:/usr/games:/sbin/nologin
[root@ansibledata]#cat /etc/passwd | grep -nB1 root #过滤root的前一行
1:root:x:0:0:root:/root:/bin/bash
--
9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10:operator:x:11:0:operator:/root:/sbin/nologin
[root@ansibledata]#cat /etc/passwd | grep -nC1 root #过滤root的前后一行
1:root:x:0:0:root:/root:/bin/bash
2-bin:x:1:1:bin:/bin:/sbin/nologin
--
9-mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
10:operator:x:11:0:operator:/root:/sbin/nologin
11-games:x:12:100:games:/usr/games:/sbin/nologin
示例三:
[root@ansibledata]#grep -e root -e wang /etc/passwd 包含wang或者root的用户
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
wang:x:1001:1001::/home/wang:/bin/bash
示例四:
[root@ansibledata]#grep root /etc/passwd | grep bash 包括root并且包括bash的行
root:x:0:0:root:/root:/bin/bash
示例五:
[root@ansibledata]#grep -v root /etc/passwd 显示除了root的字符
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
sync:x:5:0:sync:/sbin:/bin/sync
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
halt:x:7:0:halt:/sbin:/sbin/halt
示例六:
取出字符串内的交集:
[root@ansibledata]#grep -f f1 f2
aa
ccc
[root@ansibledata]#cat f1
aa
bbb
ccc
ee
[root@ansibledata]#cat f2
aa
ss
ccc
2、正则表达式
1、REGEXP: Regular Expressions,由一类特殊字符及文本字符所编写的模式,其中有些字符(元字符)不表示字符字面意义,而表示控制或通配的功能
2、程序支持:grep,sed,awk,vim, less,nginx,varnish等
3、分两类:
4、基本正则表达式:BRE
5、扩展正则表达式:ERE
grep -E, egrep
6、正则表达式引擎:
采用不同算法,检查处理正则表达式的软件模块PCRE(Perl Compatible Regular Expressions)
元字符分类:字符匹配、匹配次数、位置锚定、分组
man 7 regex
基本正则表达式元字符
. 匹配任意单个字符
[] 匹配指定范围内的任意单个字符,示例:[wang] [0-9] [a-z] [a-zA-Z]
[^] 匹配指定范围外的任意单个字符
[:alnum:] 字母和数字
[:alpha:] 代表任何英文大小写字符,亦即 A-Z, a-z
[:lower:] 小写字母 [:upper:] 大写字母
[:blank:] 空白字符(空格和制表符)
[:space:] 水平和垂直的空白字符(比[:blank:]包含的范围广)
[:cntrl:] 不可打印的控制字符(退格、删除、警铃...)
[:digit:] 十进制数字 [:xdigit:]十六进制数字
[:graph:] 可打印的非空白字符
[:print:] 可打印字符
[:punct:] 标点符号
实战演练:
(1). 匹配任意单个字符
[root@centos7-1~]#grep r..t /etc/passwd 匹配r后面跟的两个任意字符
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
[root@centos7-1~]#grep home. /etc/passwd 匹配home后面跟一个任意字符
liu:x:1000:1000:liu:/home/liu:/bin/bash
wang:x:1001:1001::/home/wang:/bin/bash
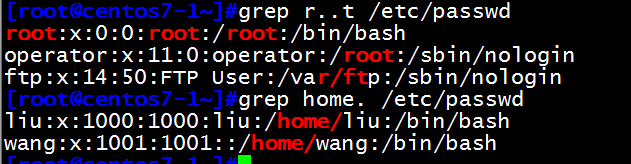
(2)[ ] 匹配指定范围内的任意单个字符 示例:[wang] [0-9] [a-z] [a-zA-Z]
[root@centos7-1~]#grep [wang] /etc/passwd
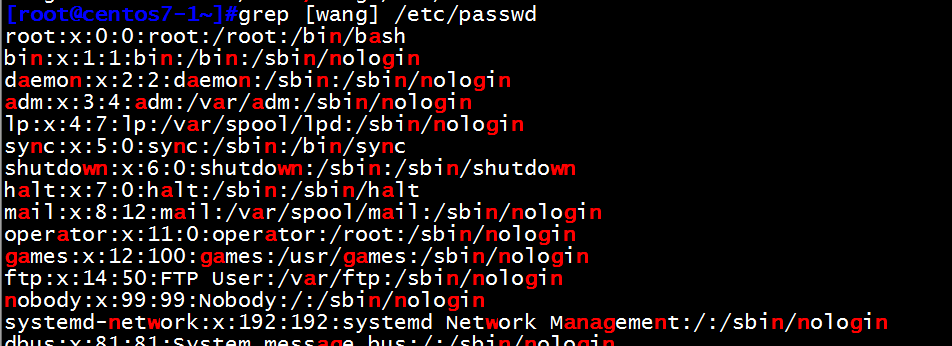
(3)[^] 匹配指定范围外的任意单个字符
grep [^0-9] /etc/fstab 匹配当前配置文件非数字的信息
(4)ifconfig ens33 | grep netmask | grep [[:digit:].] 匹配数字和.的内容
注意:[ .]在中括号里边的点就是一个点,在[ ].的点就是匹配任意一个字符。

匹配次数:用在要指定次数的字符后面,用于指定前面的字符要出现的次数
* 匹配前面的字符任意次,包括0次
贪婪模式:尽可能长的匹配
.* 任意长度的任意字符
\? 匹配其前面的字符0或1次
\+ 匹配其前面的字符至少1次
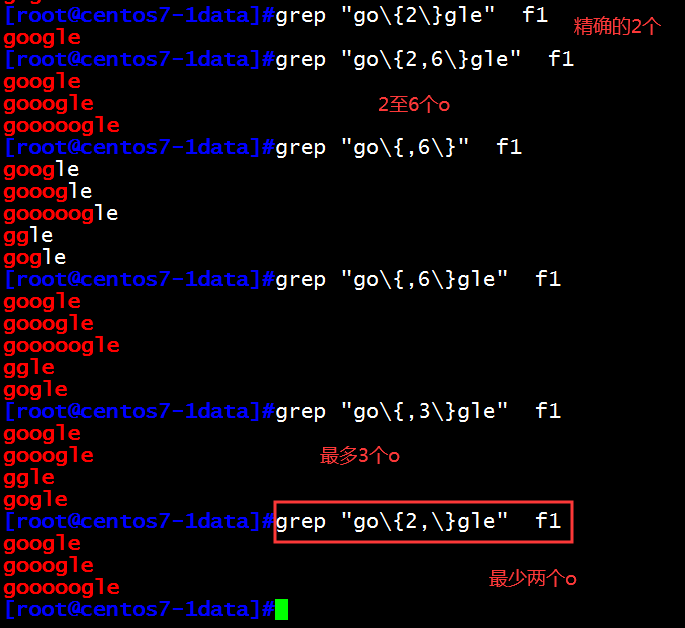
\{n\} 匹配前面的字符n次
\{m,n\} 匹配前面的字符至少m次,至多n次
\{,n\} 匹配前面的字符至多n次
\{n,\} 匹配前面的字符至少n次
(1)* 匹配前面的字符任意次,包括0次
贪婪模式:尽可能长的匹配

(2).* 任意长度的任意字符
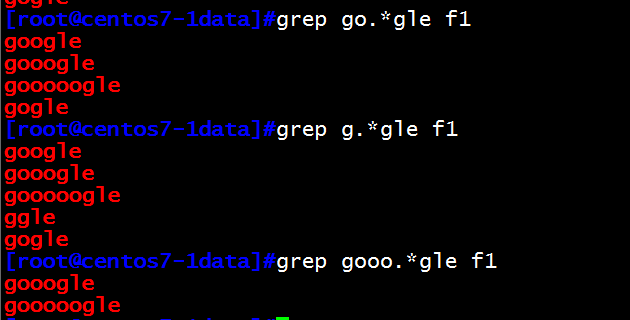
(3).* 任意长度的任意字符
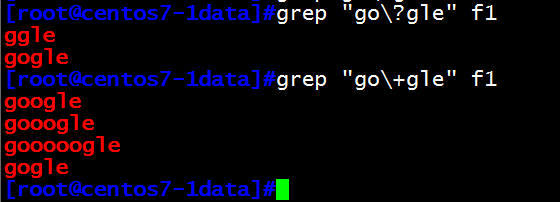
grep "go.*gle" f1 匹配一次以上的o字母
grep "g.*gle" f1 匹配一次以上的g字母开头的字符
(4)\? 匹配其前面的字符0或1次
(5)\+ 匹配其前面的字符至少1次
(6)取出IP地址:
ifconfig ens33 | grep -o "[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}\.[0-9]\{1,3\}" | head -n1

位置锚定:定位出现的位置
^ 行首锚定,用于模式的最左侧
$ 行尾锚定,用于模式的最右侧
^PATTERN$ 用于模式匹配整行
^$ 空行
^[[:space:]]*$ 空白行
\< 或 \b 词首锚定,用于单词模式的左侧
\> 或 \b 词尾锚定,用于单词模式的右侧
\<PATTERN\> 匹配整个单词
(1)^ 行首锚定,用于模式的最左侧
(2)$ 行尾锚定,用于模式的最右侧
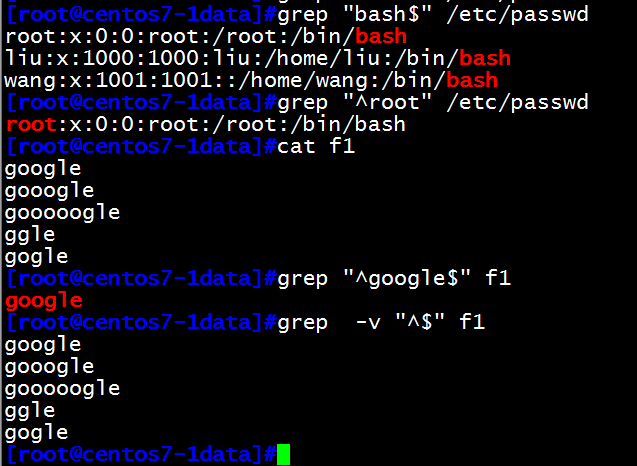
[root@centos7-1data]#grep "bash$" /etc/passwd #以bash结尾的行
root:x:0:0:root:/root:/bin/bash
liu:x:1000:1000:liu:/home/liu:/bin/bash
wang:x:1001:1001::/home/wang:/bin/bash
[root@centos7-1data]#grep "^root" /etc/passwd #以root开头的行
root:x:0:0:root:/root:/bin/bash
[root@centos7-1data]#cat f1
gooogle
gooooogle
ggle
gogle
[root@centos7-1data]#grep "^google$" f1 #只筛选google的行
[root@centos7-1data]#grep -v "^$" f1 显示非空行
gooogle
gooooogle
ggle
gogle
grep -v "^#" /etc/fstab 显示非#开头的行

(3)\< 或 \b 词首锚定,用于单词模式的左侧
(4)\> 或 \b 词尾锚定,用于单词模式的右侧
(5)\<PATTERN\> 匹配整个单词
什么是单词的分隔符?
答曰:不能是数字、字母、下划线,其他的都可以。
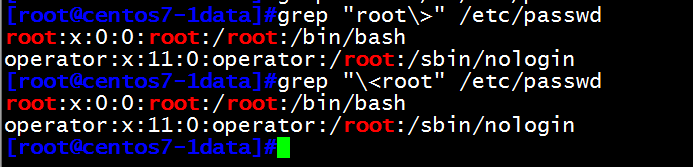
[root@centos7-1data]#grep "root\>" /etc/passwd 以root为结尾的单词
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
[root@centos7-1data]#grep "\<root" /etc/passwd 以root为开头的单词
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
分组和后向引用
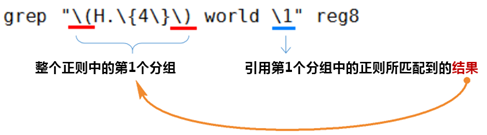
(1)格式
① 分组:\(\) 将一个或多个字符捆绑在一起,当作一个整体进行处理
分组括号中的模式匹配到的内容会被正则表达式引擎记录于内部的变量中,这些变量的命名方式为: \1, \2, \3, ...
② 后向引用
引用前面的分组括号中的模式所匹配字符,而非模式本身
\1 表示从左侧起第一个左括号以及与之匹配右括号之间的模式所匹配到的字符
\2 表示从左侧起第2个左括号以及与之匹配右括号之间的模式所匹配到的字符,以此类推
\& 表示前面的分组中所有字符
③ 流程分析如下:
(2)或者:\|
[root@centos7-1data]#grep "\(abc\)\{3\}" f2 #表示匹配3次abc
abcabcabc
[root@centos7-1data]#cat > f2
xyz xyz
abc xyz abc xyz
abc xyz xyz abc
^C
[root@centos7-1data]#grep "\(abc\).*\(xyz\).*\1" f2 #含义是匹配以abc和xyz中间的内容,最后以abc结尾的行
abc xyz abc xyz
abc xyz xyz abc
[root@centos7-1data]#grep "\(abc\).*\(xyz\).*\2" f2 # 含义是匹配以abc至xyz中间的内容,最后以xyz结尾的行
abc xyz abc xyz
abc xyz xyz abc

grep "^\(a\|b\)" /etc/passwd 取出a或b开头的行

ifconfig ens33 | grep -o "\([0-9]\{1,3\}\.\)\{3\}[0-9]\{1,3\}" 取出IP地址,前面的括号分组是第一个IP. {3}是将此IP重复3次,最后[0-9]\{1,3\} 是最后一次的IP地址

3、扩展正则表达式:
(1)字符匹配:
- . 任意单个字符
- [] 指定范围的字符
- [^] 不在指定范围的字符
- 次数匹配:
- * :匹配前面字符任意次
- ? : 0 或1次
- + :1 次或多次
- {m} :匹配m次 次
- {m,n} :至少m ,至多n次
(2)位置锚定:
- ^ : 行首
- $ : 行尾
- \<, \b : 语首
- \>, \b : 语尾
- 分组:()
- 后向引用:\1, \2, ...
- 或者:
a|b a或b
C|cat C或cat
(C|c)at Cat或cat
(3)总结
除了\<, \b : 语首、\>, \b : 语尾;使用其他正则都可以去掉\。
实战演示:
(1)显示基名
[root@centos7-1data]#echo "/etc/rc.d/init.d/function" | grep -oE "[^/]+$"
function
(2)显示目录名:两次的grep为了处理两次/
[root@centos7-1data]#echo "/etc/rc.d/init.d/function/" | grep -oE ".*[^/]" | grep -Eo ".*/"
/etc/rc.d/init.d/
(3)筛选出所有的IP地址
[root@centos7-1data]#ifconfig | grep -Eo "(([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])\.){3}([1-9]?[0-9]|1[0-9]{2}|2[0-4][0-9]|25[0-5])"
192.168.34.102
255.255.255.0
192.168.34.255
192.168.34.117
255.255.255.0
192.168.34.255
127.0.0.1
255.0.0.0
192.168.122.1
255.255.255.0
192.168.122.255

文本三剑客之grep及正则表达式的更多相关文章
- Linux文本处理三剑客之grep及正则表达式详解
Linux文本处理三剑客之grep及正则表达式详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Linux文本处理三剑客概述 grep: 全称:"Global se ...
- 文本三剑客之grep的用法
第1章 正则表达式 1.1 正则表达式的介绍 正则是用来过滤文件内容 为处理大量文本|字符串而定义的一套规则和方法. ...
- 文本三剑客之grep
接受正则表达式,按行匹配,将会过滤出匹配的所有行 格式: grep [OPTION]... PATTERN [FILE]... 可以看出,grep后可以同时接多个文件 选项OPTIO ...
- linux文本三剑客之grep
grep(global search regular expression(RE) and print out the line,全面搜索正则表达式并把行打印出来)是一种强大的文本搜索工具,它能使用正 ...
- Linux 文本三剑客之 grep
Linux 系统中一切皆文件. 文件是个文本.可以读.可以写,如果是二进制文件,还能执行. 在使用Linux的时候,大都是要和各式各样文件打交道.熟悉文本的读取.编辑.筛选就是linux系统管理员的必 ...
- Linux 三剑客之grep
目录 Linux 三剑客之grep 搭配命令-find 三剑客之grep: 正则表达式: Linux 三剑客之grep 搭配命令-find find命令是根据文件的名称或者属性查找文件,并不会显示文件 ...
- 文本处理三剑客之grep&正则表达式
grep是一个文本过滤工具,它支持正则表达式,能把搜索匹配到的行打印出来.grep的全称是Global Regular Expression Print(全局正则表达式)使用权限是所有用户. 一.gr ...
- Linux文本三剑客超详细教程---grep、sed、awk
awk.grep.sed是linux操作文本的三大利器,合称文本三剑客,也是必须掌握的linux命令之一.三者的功能都是处理文本,但侧重点各不相同,其中属awk功能最强大,但也最复杂.grep更适合单 ...
- 文本处理三剑客之 grep
grep简介 grep(Global search REgular expression and Print out the line)是Linux上的文本处理三剑客之一,另外两个是sed和awk. ...
随机推荐
- $(this).addClass('class').siblings('class').removeClass('class')的作用
$(this).addClass('class'):为当前元素添加'class'类(供选择器使用 - - ) $(this).siblings('class'):查找当前元素的所有类名为 " ...
- unity, 替换shader渲染(Rendering with Replaced Shaders)【转】
实现特效,尤其是一些后处理特效,经常需要将各物体的shader替换为另一套shader进行渲染到纹理,再后再进行合成或以某种叠加方式叠加到最后的画面上去. 再复杂一点儿的,可能不同的物体所用的替换sh ...
- Egret入门学习日记 --- 第十篇(书中 2.9~2.13节 内容)
第十篇(书中 2.9~2.13节 内容) 好的 2.9节 开始! 总结一下重点: 1.之前通过 ImageLoader 类加载图片的方式,改成了 RES.getResByUrl 的方式. 跟着做: 重 ...
- 神经网络与机器学习第3版学习笔记-第1章 Rosenblatt感知器
神经网络与机器学习第3版学习笔记 -初学者的笔记,记录花时间思考的各种疑惑 本文主要阐述该书在数学推导上一笔带过的地方.参考学习,在流畅理解书本内容的同时,还能温顾学过的数学知识,达到事半功倍的效果. ...
- 最新 中手游java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.中手游等10家互联网公司的校招Offer,因为某些自身原因最终选择了中手游.6.7月主要是做系统复习.项目复盘.LeetCo ...
- Nuget下载 MySql.Data 连接MySql数据库
打开VS项目,右键项目选择 右上角搜索框中搜索 MySql.Data 然后可以选择安装,但是可能会出现这个提示 这是因为版本的问题,所以,自己去官网重新下载,我这里选择的是这个版本, 官网地址: ht ...
- mybatis 一对多,多对一配置
一. 简介: 本实例使用顾客和订单的例子做说明: 一个顾客可以有多个订单, 一个订单只对应一个顾客 二. 例子: 1. 代码结构图: 2. 建表语句: CREATE DATABASE test; US ...
- JavaScript、TypeScript、ES6三者之间的联系和区别
ES6是什么 ECMAScript 6.0(以下简称ES6)是JavaScript语言(现在是遵循ES5标准)的下一代标准,已经在2015年6月正式发布了.它的目标,是使得JavaScript语言可以 ...
- Django与JS交互的示例代码-django js 获取 python 字典-Django 前后台的数据传递
Django与JS交互的示例代码 Django 前后台的数据传递 https://www.cnblogs.com/xibuhaohao/p/10192052.html 应用一:有时候我们想把一个 li ...
- sql server 2012 链接服务器不能链接sql server 2000的解决方案 ,
本数据源来自 https://www.kafan.cn/edu/922556.html 目的为了备忘 把原来的sql server 2005直接装成了2012,然后在建立链接服务器链接一台sql s ...