【零基础】神经网络优化之dropout和梯度校验
一、序言
dropout和L1、L2一样是一种解决过拟合的方法,梯度检验则是一种检验“反向传播”计算是否准确的方法,这里合并简单讲述,并在文末提供完整示例代码,代码中还包含了之前L2的示例,全都是在“深层神经网络解析”这篇基础之上修改的。
二、dropout
简单来说dropout就是在每次训练时“随机”失效网络中部分神经元,大概就是下图这么个意思。

让神经元随机消失办法很简单,我们将每一层的输出Y中部分位,置为0即可。回顾一下神经元的输出值Y:
A = np.dot(w, IN) + b
Y = relu(A)
对于输入层,IN就是img,对于其他层IN就是上一层的输出Y,A是权重w与输入IN的矩阵乘积,Y是A在0-1间的映射,表示概率。对于w与IN的乘积运算,我们若在IN中插入若干个0值,其计算结果(相乘后是累加)对下一层是没有影响的,所以将IN(Y)中某些位置为0就相当于将上一层某些神经元删除了。
具体到实现上,先按Y的形状生成0-1的随机数
D = np.random.rand(Y.shape[0], Y.shape[1])
接着将小于keep_prob的数全部置为0其他的置为1,keep_prob就是删除的神经元比例,如0.5就删除50%。
D = D < keep_prob
然后用Y乘以D,按keep_prob的比例删除输出值(也即是下一层的输入)。
Y = Y * D
最后还需要用Y除以keep_prob,目的是将训练和测试时的“期望”保持一致。
Y = Y / keep_prob
简单理解“期望“就是在训练时我们删除了一定比例的神经元,但是实际使用时这些神经元可都是在的,所以Y除以keep_prob就是让二者的”期望“保持一致。
这里我们简单讲了下过程,具体的实现在文末可以下载完整代码。
三、梯度校验
梯度校验基于这么一个事实:神经网络是一个“混沌”系统,增加一些参数、减少一些参数、写错一些参数,又比如前面dropout方法中删除一些神经元对整体网络的运行似乎没有影响,你不会得到一个明确的报错,有时训练得到的结果表现的可能还不错(有时甚至更好了)。我们需要一些手段来做一些“基本”的检测吧?
梯度校验就是这么一个“基本检测”,他的原理是“用另一种路径”来重新计算Δw,如果你计算的Δw与反向传播计算的Δw“差不多”,那说明大方向上你的网络是OK的,至少“优化”的方向是正确的。
我们知道Δw的计算是在损失函数的基础上对w进行求导,求导的结果即是w优化的方向(使cost趋向于0)。
在“反向传播”的解析中,我们的损失函数公式是标签值减去预测结果:
cost = ( Label - Y )^2
而后用cost对w求导可以得到Δw使cost值趋向于0:
Δw = ( Label - Y )*X
上式是利用对cost求导得到的,验证上式计算结果是否正确的另一种路径则是回归“求导”的本质:当自变量的增量趋于零时,因变量的增量与自变量的增量之商的极限。用数学公式表达出来就是:
cost = J(w) = ( Label - Y )^2
Y = wX + b
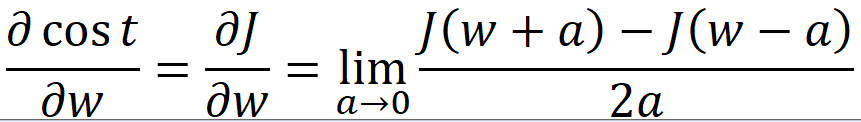
上式中a是一个趋向于0的极小值,我们可以随便取一个,比如10的-7次方(0.0000001)。上式中J(w+a)和J(w-a)可以通过向前传播和损失计算得到,这种方式可以称为极值法,而后与反向传播求得的Δw作比较,下式是一个比较科学的比较方法(二范数):
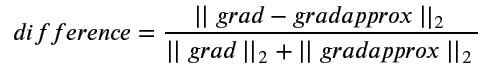
其中grad是反向传播求得的Δw,gradapprox是极值法求得的Δw,difference称为误差。
四、多维神经网络的梯度检验
上一节简述了梯度检验的原理,然鹅放到实际应用时有点抓虾,因为前面的公式范例只能契合单神经元的情况,将公式应用到多层神经网络还需要做一些修改。最主要的修改在于,我们要将w、b、dw、db转为一维向量.
一个简单的w示例如下:
w = {'1':[1,2,3,4,5],'2':[6,7,8],'3':[9,10]}
对于多层的神经网络来说,w+a、w-a不是将w中所有元素都加减a,而是每个元素依次操作,错误示例如下:
w + a = {'1':[1+a,2+a,3+a,4+a,5+a],'2':[6+a,7+a,8+a],'3':[9+a,10+a]} #这个是错误的示范!!!
正确的示例如下:
w + a = {'1':[1+a,2,3,4,5],'2':[6,7,8],'3':[9,10]}
w + a = {'1':[1,2+a,3,4,5],'2':[6,7,8],'3':[9,10]}
以此类推。
这个很好理解,如果使用错误示例中的方法,最后我们通过极值法计算出来的gradapprox只有一个元素,然鹅dw是有10个元素的。使用正确示例这个方法其实是对w中每一个位都按极值法求得了导数的近似值,正好对应了dw中每一个位的导数。
为了便于计算,我们可以将w和dw都转为一维向量:
w = [1,2,3,4,5,6,7,8,9,10]
一维向量的好处是增减a时比较方便,实际计算损失时还得再转回多维的形状。具体代码实现在文末有下载方式,为了便于理解我只实现了dw的检验,实际上你可以把w、b拼成一个向量,dw、db拼成一个向量,使用极值法计算出梯度后可以做一个整体的比较(自己试试看)。
因为梯度校验速度真的非常非常慢,为了加快测试的速度,我们可以将网络做的更简单、将训练数据减少,实际使用时可以是所有训练数据都一起上,慢就慢点吧。
需要注意的是,如果你要做梯度校验,那dropout必须得先关掉(将keep_prob设为1),原因很好理解,dropout使神经网络在训练时随机“删除”了部分神经元,使用极值法计算Δw时需要做两次向前传播,两次随机删除的神经元肯定不一样,反向传播删除的神经元也不一样,自然最后计算的difference就不准确了。
五、总结
本文简单讲了下神经网络的优化方法dropout和反向传播的检验方法“梯度校验”,其中dropout需要与之前的L2优化结合起来看。
完整实现代码可以关注公众号“零基础爱学习”回复“AI10”获取。

【零基础】神经网络优化之dropout和梯度校验的更多相关文章
- 【零基础】神经网络优化之Adam
一.序言 Adam是神经网络优化的另一种方法,有点类似上一篇中的“动量梯度下降”,实际上是先提出了RMSprop(类似动量梯度下降的优化算法),而后结合RMSprop和动量梯度下降整出了Adam,所以 ...
- 【零基础】神经网络优化之mini-batch
一.前言 回顾一下前面讲过的两种解决过拟合的方法: 1)L0.L1.L2:在向前传播.反向传播后面加个小尾巴 2)dropout:训练时随机“删除”一部分神经元 本篇要介绍的优化方法叫mini-bat ...
- 【零基础】神经网络优化之L1、L2
一.序言 前面的文章中,我们逐步从单神经元.浅层网络到深层网络,并且大概搞懂了“向前传播”和“反向传播”的原理,比较而言深层网络做“手写数字”识别已经游刃有余了,但神经网络还存在很多问题,比如最常见的 ...
- 神经网络优化算法:梯度下降法、Momentum、RMSprop和Adam
最近回顾神经网络的知识,简单做一些整理,归档一下神经网络优化算法的知识.关于神经网络的优化,吴恩达的深度学习课程讲解得非常通俗易懂,有需要的可以去学习一下,本人只是对课程知识点做一个总结.吴恩达的深度 ...
- 狗屁不通的“视频专辑:零基础学习C语言(小甲鱼版)”(2)
前文链接:狗屁不通的“视频专辑:零基础学习C语言(小甲鱼版)”(1) 小甲鱼在很多情况下是跟着谭浩强鹦鹉学舌,所以谭浩强书中的很多错误他又重复了一次.这样,加上他自己的错误,错谬之处难以胜数. 由于拙 ...
- IM开发者的零基础通信技术入门(二):通信交换技术的百年发展史(下)
1.系列文章引言 1.1 适合谁来阅读? 本系列文章尽量使用最浅显易懂的文字.图片来组织内容,力求通信技术零基础的人群也能看懂.但个人建议,至少稍微了解过网络通信方面的知识后再看,会更有收获.如果您大 ...
- IM开发者的零基础通信技术入门(一):通信交换技术的百年发展史(上)
[来源申明]本文原文来自:微信公众号“鲜枣课堂”,官方网站:xzclass.com,原题为:<通信交换的百年沧桑(上)>,本文引用时已征得原作者同意.为了更好的内容呈现,即时通讯网在收录时 ...
- 普通程序员转型AI免费教程整合,零基础也可自学
普通程序员转型AI免费教程整合,零基础也可自学 本文告诉通过什么样的顺序进行学习以及在哪儿可以找到他们.可以通过自学的方式掌握机器学习科学家的基础技能,并在论文.工作甚至日常生活中快速应用. 可以先看 ...
- Tensorflow学习:(三)神经网络优化
一.完善常用概念和细节 1.神经元模型: 之前的神经元结构都采用线上的权重w直接乘以输入数据x,用数学表达式即,但这样的结构不够完善. 完善的结构需要加上偏置,并加上激励函数.用数学公式表示为:.其中 ...
随机推荐
- 使用Idea初始化一个spring boot 项目
配置环境 Idea配置jdk8.0 1.打开Idea,点击右上角file,找到Other Settings选项,点击下方的Default Project Structure,如下所示 2.点击下图中所 ...
- Android笔记(十六) 简易计算器
实现功能: 简单计算器 布局及美化 采用LinearLayout嵌套LinearLayout实现布局. 要求 1. 按钮所有文字居于右下角 2. 按钮为白色,点击变成橘色 3. 显示屏文字居右显示并且 ...
- 【年度盘点】10个热门Python练习项目
这10个项目,约有270000人学习过. 今天给大家盘点一下实验楼最热门的10个Python练习项目.第二名是<200 行 Python 代码实现 2048>,第三名是<Python ...
- Poj-3286- How many 0's? - 【基础数位DP】
How many 0's? Description A Benedict monk No.16 writes down the decimal representations of all natur ...
- .NET Core 初体验
.NET Core 作为微软的开源项目,neter 们对之的期待还是挺大的. 以前也看过,接触过,摸索建了几个示例项目,今天就罗列下自己的初体验. .NET Core 安装.帮助等 安装的话,直接官网 ...
- 《奋斗吧!菜鸟》 第七次作业:团队项目设计完善&编码
项目 内容 这个作业属于哪个课程 任课教师链接 作业要求 https://www.cnblogs.com/nwnu-daizh/p/10980707.html 团队名称 奋斗吧!菜鸟 作业学习目标 团 ...
- Spring MVC 学习笔记(一)
• 1.SpringMVC概述 • 2.SpringMVC的HelloWorld • 3.使用@RequestMapping映射请求 • 4.映射请求参数&请求头 • 5.处理模型数据 • 6 ...
- JavaScript this 的指向问题
原文作者:SegmentFault ——写bug 原文链接:https://segmentfault.com/a/1190000015438195 this的指向已经是一个老生常谈的问题,每逢面试都要 ...
- pid 及参数调试方法
所谓PID指的是Proportion-Integral-Differential.翻译成中文是比例-积分-微分. 记住两句话: 1.PID是经典控制(使用年代久远) 2.PID是误差控制() 对直流电 ...
- 洛谷P2577 午餐【贪心】【线性dp】
题目:https://www.luogu.org/problemnew/show/P2577 题意:n个人每个人有一个打饭时间和吃饭时间,将他们分成两个队伍.每个人打到饭之后就马上去吃饭.问怎么安排可 ...