HTTP的原理和工作机制
HTTP到底是什么?
- 两种最直观的印象:
①、浏览器地址栏输入地址,打开网页:
②、Android中发送网络请求,返回对应的内容:
- HyperText Transfer Protocal 超文本传输协议。
HyperText,又叫超文本:在电脑中显示的、含有可以指向其它文本的链接的文本,其实也就是我们熟知的HTML啦: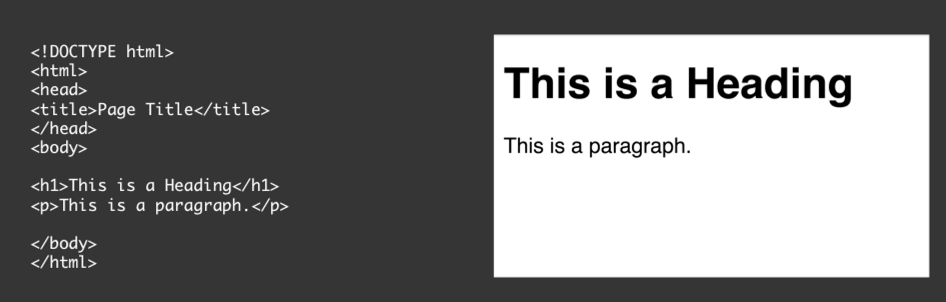
HTTP的工作方式:
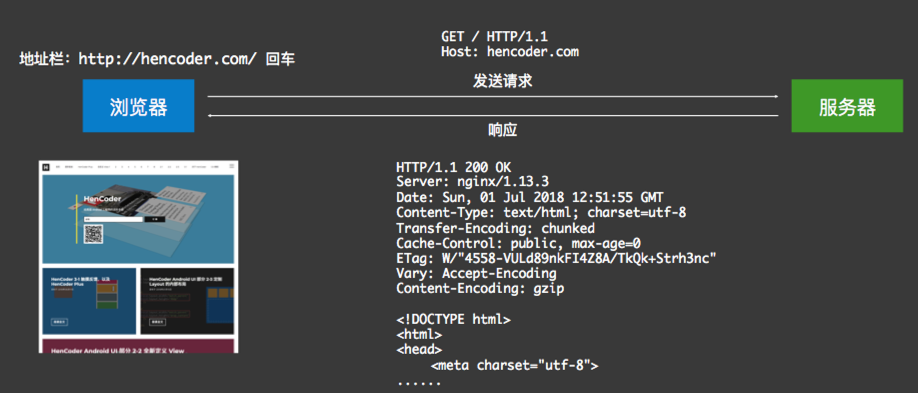
首先在浏览器中输入一个网页:

然后服务器处理请求,接着给出结果反馈,如下:

然后浏览器根据响应做出渲染显示,也就是我们所看到的网页内容了:

其中发送请求与响应其实是有一定的数据格式的,如下:
URL -> HTTP报文:
其中对于我们在浏览器中敲的网页地址最终都会对应成HTTP的报文,先来了解一下:

对于用户而言就是一个地址,但是其被定义成了:

而其实发送时的报文格式会变成:

那, 这里有一个小疑问:

这里先放一放,待了解之后的工作方式可以再回过头来理解它。
请求报文格式:
对于咱们写的请求接口的代码其整个过程会是如下:

其实对于具体请求响应细节就看不到了,对于请求报文而言其实是长这样子的:
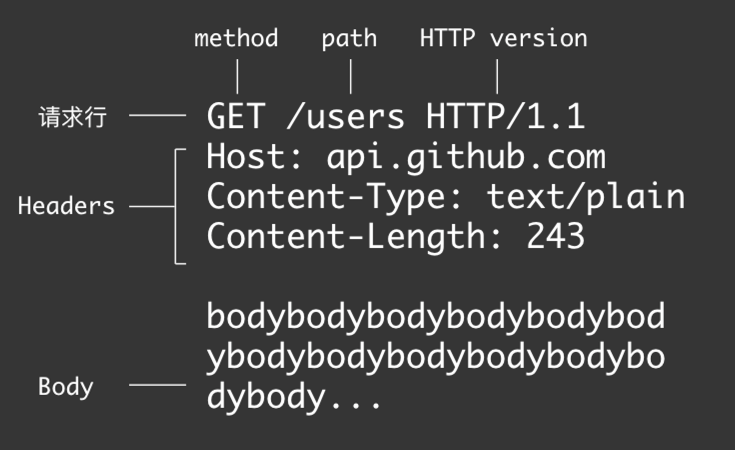
注意:GET时是没有Body的,上图只是画了一个整体的格式,并不严谨,所以这就是为啥上面请求报文不能这样写的原因了:

这样写是不符合请求报文规定的格式的。
响应报文格式:
跟请求报文格式比较相似,如下:
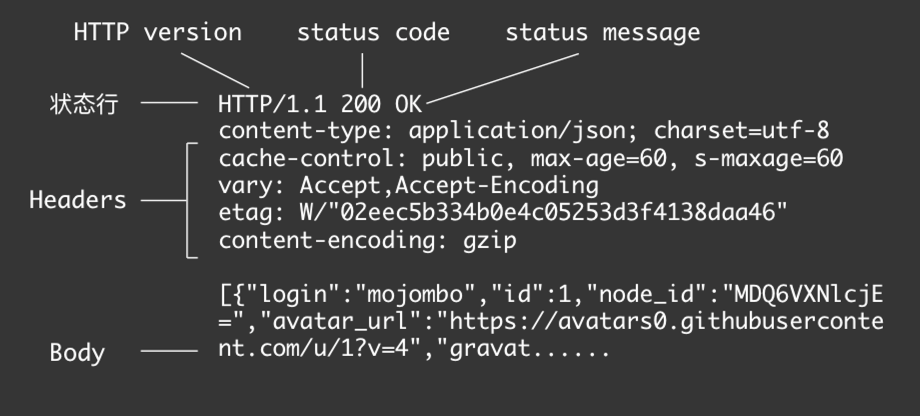
其中status message服务开发人员是可以改的,对返回状态的简要描述。
Request method:
GET: 获得资源,木有Body:【具有幂等性】
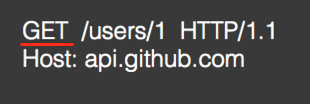

POST:增加或修改资源,有Body:【不具有幂等性】
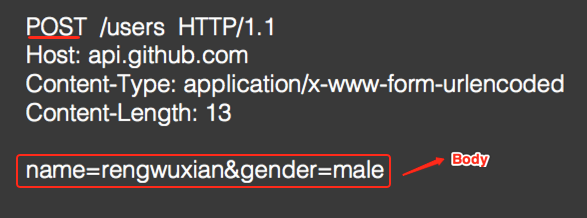

PUT: 修改资源,有Body:【具有幂等性,用得较少】
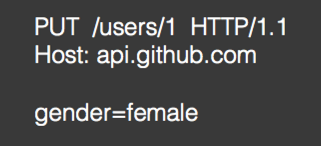

其中GET和PUT都是幂等的,啥叫幂等?
也就是我GET多次或者PUT多次是不会影响服务器的结果的,但是POST就不是幂等的,也就是用POST增加一个用户,执行多次则会在服务器中插入多条数据,也就是执行多次是会影响到结果的。
DELETE: 删除资源,没有Body:【具有幂等性】
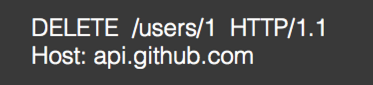
对应Retrofit代码:
HEAD:跟GET几乎是一样的,区别就是这种请求服务器是不会返回Body内容的,在做下载时可能想先知道文件有多大,支不支持断点续传之类的,用它就比较合适,先用HEAD一下获取相关的信息之后,然后再发起真正的下载请求。
Response status code:
作用:对结果做出类型化描述(如【获取成功】、【内容未找到】)
- 1xx:临时性消息。如:100 (继续发送)、101(正在切换协议)
一般是100、101,一般都是信息性的东东,比如HTTP1.x和HTTP2.x是不兼容的,在请求时可以循问服务器是否支持HTTP2.x这个协议,然后就会下发101状态码给客户端,如果下发的是200状态码则证明该服务肯定是不支持HTTP2.X协议,所以客户端就可以针对性的进行协议转换。 - 2xx:成功。最典型的是 200(OK)、201(创建成功)。
典型的200,当然除了200,还有其它2开头的,反正一点就是它代表成功的意思。 - 3xx:重定向。如 301(永久移动)、302(暂时移动)、304(内容未改变)。
典型的就是301,如对于一个https的地址输入http,就会有它,如下:
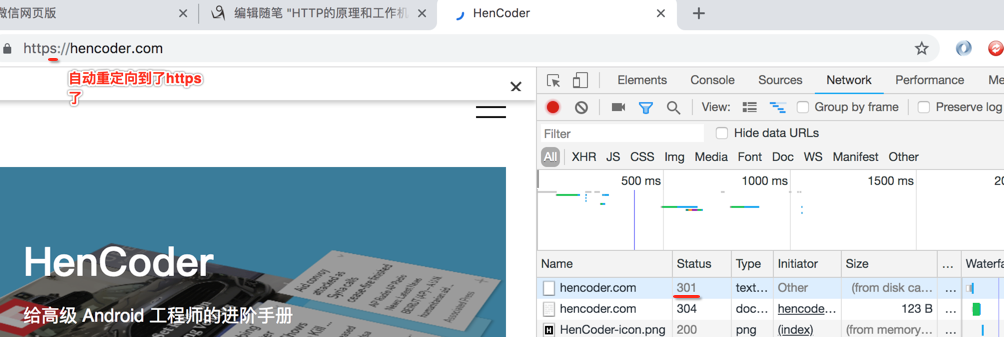
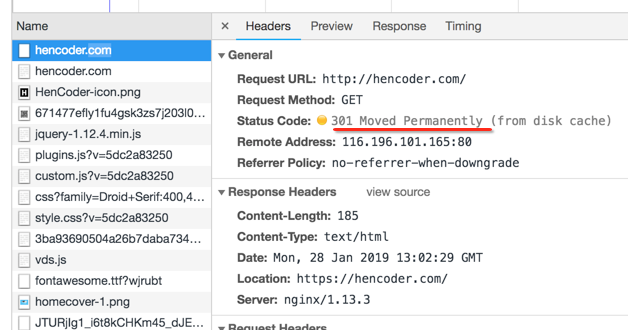
这是永久性牵移,另外还有一个302临时性牵移,一般都是用永久性301,这些重定向对于搜索引擎是有用的。
另一个典型就是304,代表着网页内容木有改变,也就是不用再次做页面刷新,比如我们还是对刚才这个网页刷一下,看状态码: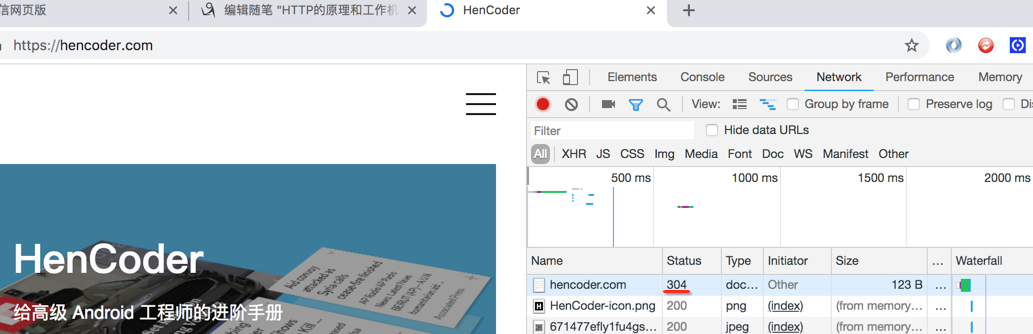
- 4xx:客户端错误。如 400(客户端请求错误)、401(认证失败)、403(被禁⽌止)、404(找 不不到内容)。
客户端是指手机软件、浏览器等,如400【参数错误】、404【页面找不到】、401【未登录去请求登录资源时】。 - 5xx:服务器错误。
典型的500。
Header:
作用:http消息的元数据(metadata)
- Host:服务器主机地址。
如:
但是需要注意的是该地址不是用来进行寻址的,其寻址是在发该请求报文之前通过DNS进行的,那既然这个地址不是用来寻址,那为啥还要发一下这个域名呢?因为一个IP地址有多个虚拟服务器主机存在,也就是对外的IP是同一个,那用户假如要访问其中的一个虚拟服务器则就需要带这个Host,没有它那服务器就蒙了,到底要找它里面的哪台虚拟主机。
- Content-Type/Content-Length:Body的类型 / 长度。
Content-Length:内容的长度(字节),那为啥要有它呢?因为可以发二进制内容,以至于要想知道该二进制内容啥时候结束用任何一种结束符都不管用,因为二进制中包含任何特殊字符的可能,所以如果不指定总长度的话,那就无法读全二进制。
Content-Type【重点】:内容的类型:
①、text/html:html文本,用于浏览器页面响应。
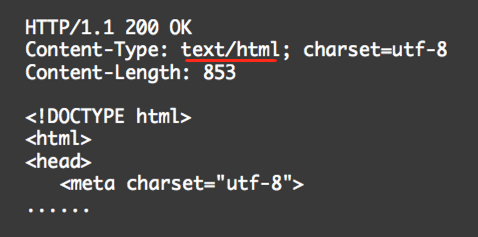
那为啥还得指定这个类型呢?因为有可能返回JSON信息,如下面这个页面:
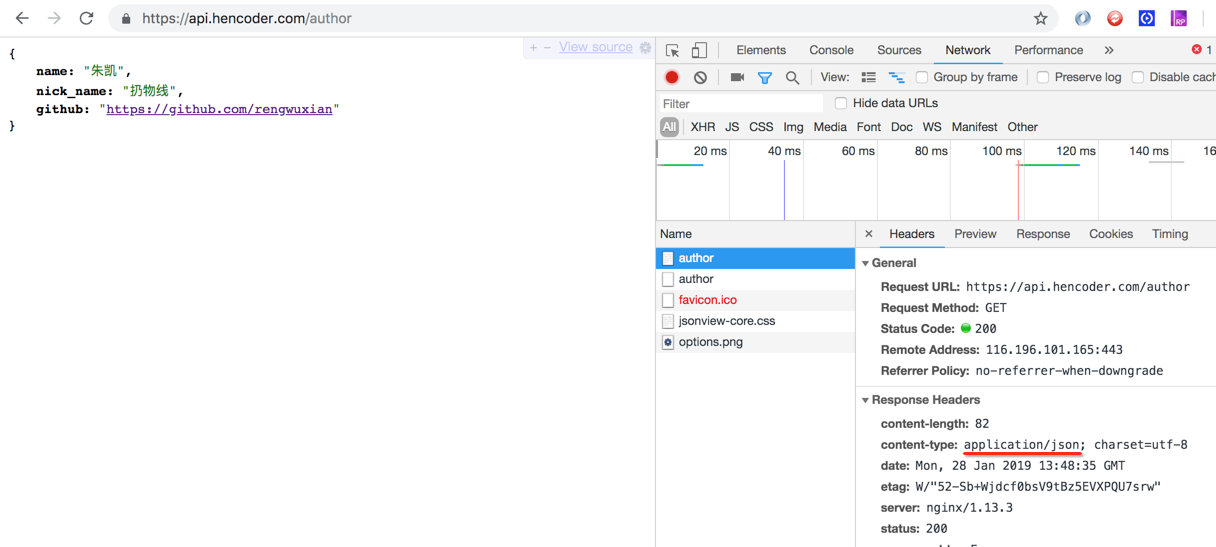
②、application/x-www-form-urlencoded:普通表单,encoded URL格式。
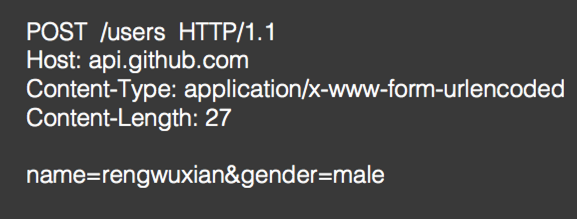
做过web开发的人肯定知道啥叫普通表单,瞅一下:


然后咱们提交一下:
然后此时瞅一下请求头信息:

也就是告诉服务器此次提交的是表单信息,然后服务器就会按如下格式读取表单数据:
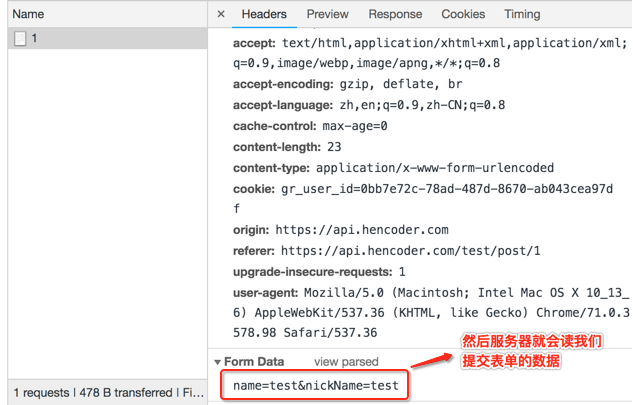
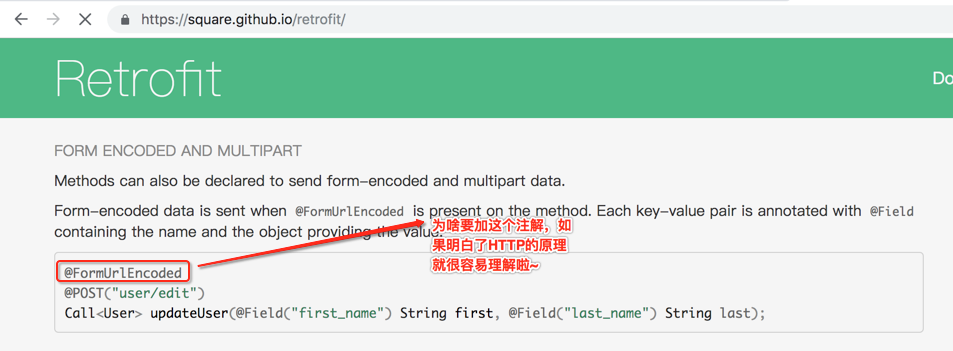
如果在Android中想要模拟表单提交,也得按这种格式去弄,但是好在有retrofit框架,使用起来大大简化了,如:
③、multipart/form-data:多部分形式,一般用于传输包含二进制内容的多项内容。
其实这种形式就是带文件的表单,不是纯文本了,如:


然后咱们上传一下:


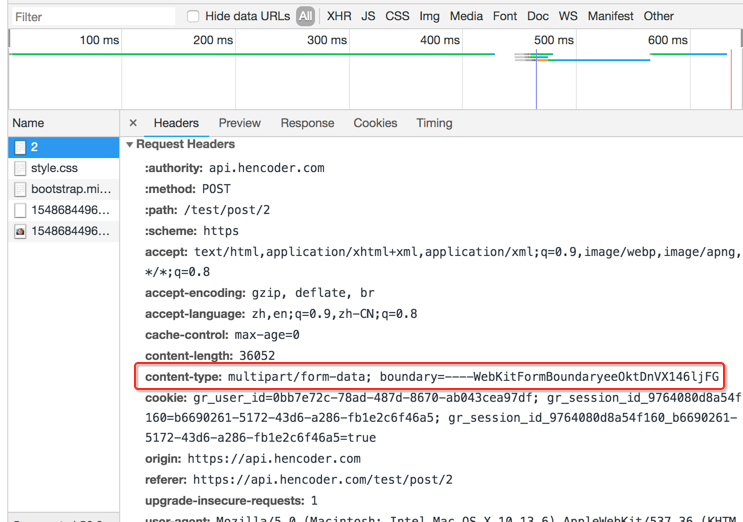
其中上传的格式如下:

其中表单数据是以boundary进行分界的,其中注意一个细节:


其实对于纯文本的表单也可以用这种形式上传,但是!!!很浪费空间,浪费空间就是浪费带宽,所以实际没这样做的,这种只适合于表单中有文件上传 的表单。而在Android的retrofit可以这样来模拟:

④、application/json:json形式,用于Web Api的响应或POST / PUT 请求。
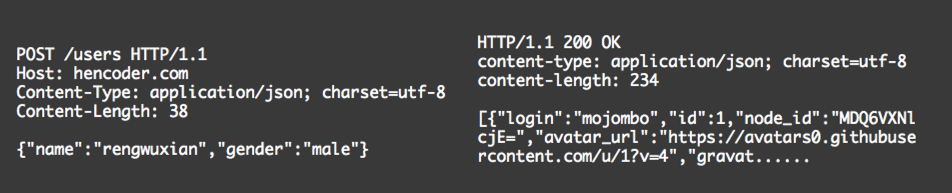
像Android的API大部分都是用的这种。对应的Retrofit的代码:

⑤、image/jpeg / application/zip ...:单文件,用于Web Api响应或POST / PUT 请求。

如果只有一个文件上传就可以采用这种方式,最高效,不需要boundary,但是!!实际用的比较少。。因为网页开发时基本没有这种方式,都需要提交表 单的,所以大部分不知道这种提交方式,所以都不会的话那API也不可能设计成这种呗,所以,前端也就使用不到啦,其实这种方式retrofit是完全支持的, 如下:

- Location:重定向的目标URL。
还是回到之前原来是https的链接,我们故意敲http,此时就会引发重定向,重定向到哪就是由这个头信息来决定的,如下:

- User-Agent:用户代理。即是谁实际发送请求、接受响应的,例如手机浏览器、某款⼿机 App。
如:
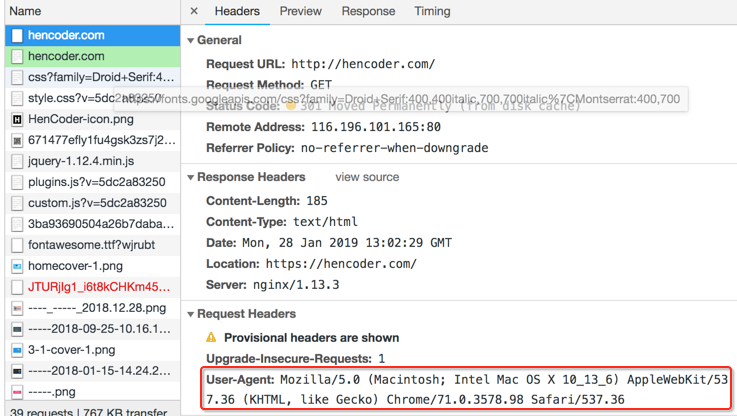
- Range / Accept-Range : 指定Body的内容范围。【断点续传、多线程下载的核心技术点】

咱们演示一下效果,先在百度地图中搜索一张图片:
然后将其地址粘贴一下,然后此时需要下载一个工具来进行演示,叫Postman,如下:

然后安装之后打开将该图片的地址粘贴到Postman里面:


然后咱们看一下服务器是否支持分段加载,看一下头信息就知道了:
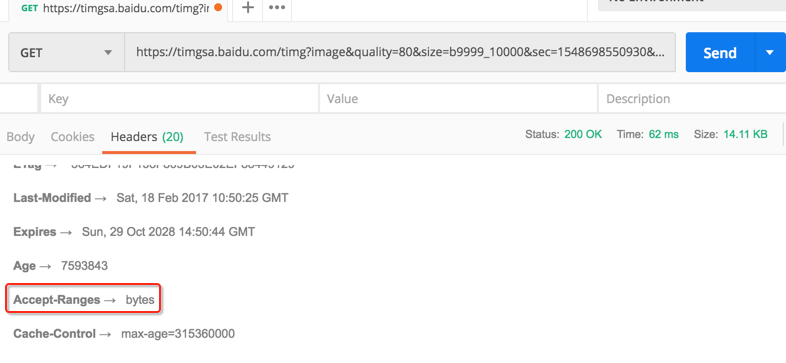
支持,然后看一下总大小: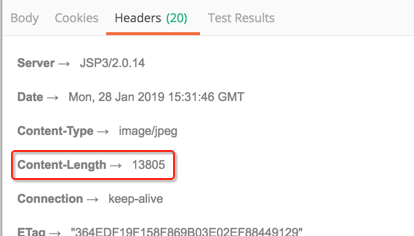
然后咱们尝试只加载图片的一半,也就是从0~6902,所以咱们来试一下:
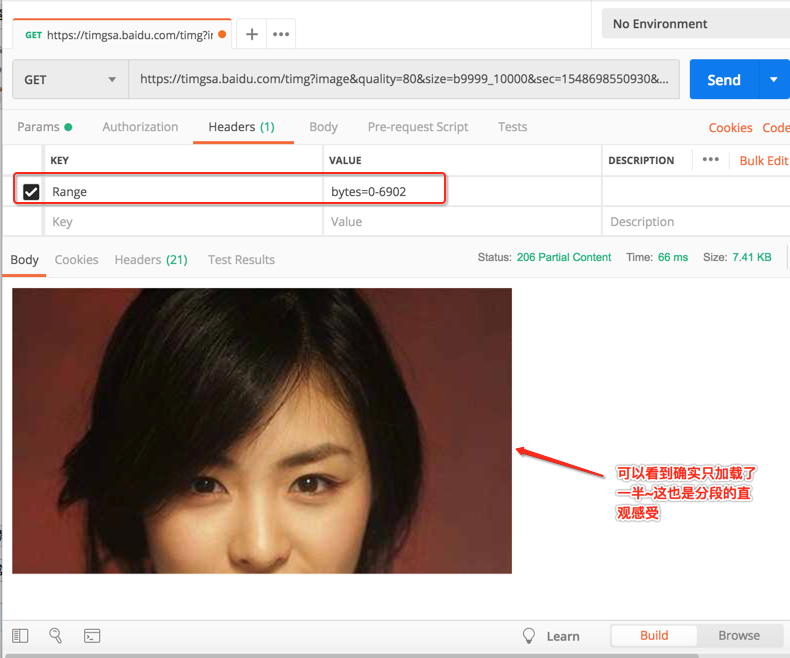
- Cookie / Set-Cookie:发送 Cookie / 设置 Cookie。【之后学习中会详说】
- Authorization:授权信息。
- Accept:客户端能接受的数据类型。如text/html。
- Accept-Charset:客户端接受的字符集。如utf-8
- Accept-Encoding:客户端接受的压缩编码类型。如gzip。【之后学习中也会详说】
- Content-Encoding:压缩类型。如gzip。
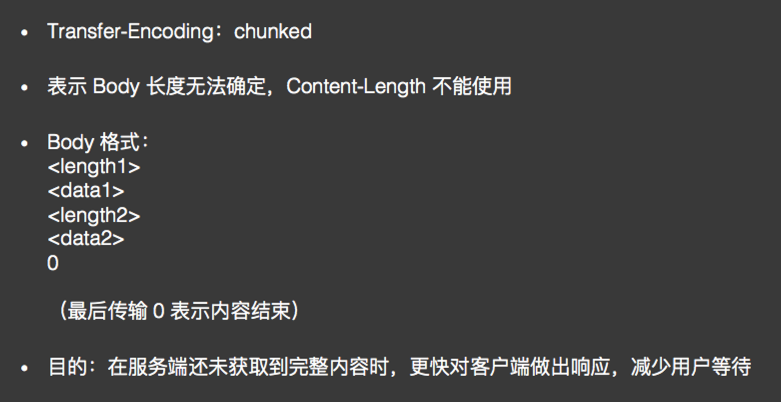
Chuncked Transfer Encoding:分块传输编码

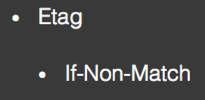
Cache:


网络发送会经过若干个中间结点,private的话则中间结点不用缓存,而public则中间结点要缓存。
RESTful HTTP:
什么是REST?先来看一下官网对它的定义:





以上不都是HTTP的特点么。。REST 的定义众说纷纭,没有统一答案。 其实REST HTTP 即正确使用 HTTP。包括:
- 使用资源的格式来定义 URL。
- 规范地使用 method 来定义⽹络请求操作,该用GET就用GET,该用POST就用POST,不要滥用。
- 规范地使用 status code 来表示响应状态。
- 其他符合 HTTP 规范的设计准则。
HTTP的原理和工作机制的更多相关文章
- [I/O]javaI/O工作机制
摘要:IO问题可以说是当今web应用中面临的主要问题之一.因为在这个数据爆发的时代,海量的数据在网络到处流动,而在这个过程中都会涉及IO问题,可以说IO问题已经成为web应用的瓶颈之一.如何优化?以此 ...
- 1 weekend110的NN元数据管理机制 + NN工作机制 + DN工作原理
第一天的笔记,是伪分布hadoop集群搭建, 后面是hadoop Ha的分布式集群搭建 第一天,是HDFS的shell操作 NN工作机制 里面是二进制 DN工作原理 上传完了之后,在hdfs的虚拟路径 ...
- Hibernate工作原理及为什么要用?. Struts工作机制?为什么要使用Struts? spring工作机制及为什么要用?
三大框架是用来开发web应用程序中使用的.Struts:基于MVC的充当了其中的试图层和控制器Hibernate:做持久化的,对JDBC轻量级的封装,使得我们能过面向对象的操作数据库Spring: 采 ...
- keepalived之 Keepalived 原理(定义、VRRP 协议、VRRP 工作机制)
1.Keepalived 定义 Keepalived 是一个基于VRRP协议来实现的LVS服务高可用方案,可以利用其来避免单点故障.一个LVS服务会有2台服务器运行Keepalived,一台为主服务器 ...
- Hadoop的namenode的管理机制,工作机制和datanode的工作原理
HDFS前言: 1) 设计思想 分而治之:将大文件.大批量文件,分布式存放在大量服务器上,以便于采取分而治之的方式对海量数据进行运算分析: 2)在大数据系统中作用: 为各类分布式运算框架(如:mapr ...
- 图文详解 HDFS 的工作机制及其原理
大家好,我是大D. 今天开始给大家分享关于大数据入门技术栈--Hadoop的学习内容. 初识 Hadoop 为了解决大数据中海量数据的存储与计算问题,Hadoop 提供了一套分布式系统基础架构,核心内 ...
- malloc 函数工作机制(转)
malloc()工作机制 malloc函数的实质体现在,它有一个将可用的内存块连接为一个长长的列表的所谓空闲链表.调用malloc函数时,它沿连接表寻找一个大到足以满足用户请求所需要的内存块.然后,将 ...
- PHP自动加载__autoload的工作机制
PHP自动加载__autoload的工作机制 PHP的懒加载lazy loading 在 2011年11月12日 那天写的 已经有 4559 次阅读了 感谢 参考或原文 服务器君一共花费了 ...
- hostapd源代码分析(二):hostapd的工作机制
[转]hostapd源代码分析(二):hostapd的工作机制 原文链接:http://blog.csdn.net/qq_21949217/article/details/46004433 在我的上一 ...
随机推荐
- 如何提高程序员的键盘使用效率?——ASE第一次作业
引言 对于程序员来说,键盘输入是我们工作的基本方式,当你的手指在键盘上飞起来的时候,不但能够提高工作效率,还常常引来旁人羡慕的目光.下面将从不同方面介绍一些提高键盘使用效率的方法. 程序员最主要的文字 ...
- EOS 资源汇总
EOS 资源汇总 A curated list of EOS Ecosystem by [SuperONE](https://superone.io/) EOS 主网 超级节点 https:/ ...
- VS2010开发.cpp与.c的注意事项
VS2010开发.cpp与.c的注意事项 声明:引用请注明出处http://blog.csdn.net/lg1259156776/ 强大的VS2010,正是由于vs2010的完全封装,让现在的wind ...
- NET Web API和Web API Client Gen使Angular 2应用程序
使用ASP.NET Web API和Web API Client Gen使Angular 2应用程序的开发更加高效 本文介绍“ 为ASP.NET Web API生成TypeScript客户端API ” ...
- 如何创建一个线程安全的Map?
1,使用普通的旧的Hashtable HashMap允许null作为key,而Hashtable不可以 2,使用Collections中同步化的包装方法synchronizedMap 3,使用conc ...
- 洛谷 题解 UVA1395 【苗条的生成树 Slim Span】
[题意] 给出一个\(n(n<=100)\)个节点的的图,求最大边减最小边尽量小的生成树. [算法] \(Kruskal\) [分析] 首先把边按边权从小到大进行排序.对于一个连续的边集区间\( ...
- [Android] 分析一个CalledFromWrongThreadException崩溃
1 问题描述 问题本身比较清晰简单,但推敲的过程中发现了不少有意思的东西. 在C++ SDK回调JNI至Java Observer函数中,直接操作了UI界面textView.setText(msg), ...
- vue A对象赋值给B对象,修改B属性会影响到A问题
实际在vue中 this.A = this.B,没有进行深层赋值,只是把this.A的地址指向了与this.B相同的地址,所有对于A的修改会影响到B. 解决相互影响的思路是在this.A必须是新建的 ...
- [官网]Windows 10 版本信息
对应于服务选项的 Windows 10 当前版本 https://docs.microsoft.com/zh-cn/windows/release-information/ 所有的日期都按照 ISO ...
- [转帖]从零开始入门 K8s:应用编排与管理:Job & DaemonSet
从零开始入门 K8s:应用编排与管理:Job & DaemonSet https://www.infoq.cn/article/KceOuuS7somCYbfuykRG 陈显鹭 阅读数:193 ...