Image Processing and Computer Vision_Review:A survey of recent advances in visual feature detection—2014.08
翻译
一项关于视觉特征检测的最新进展概述——http://tongtianta.site/paper/56761
摘要 -特征检测是计算机视觉和图像处理中的基础和重要问题。这是一个低级处理步骤,它是基于计算机视觉的应用程序的基本部分。本文的目的是介绍一项关于视觉特征检测的最新进展和进展的调查。首先,我们从心理学角度描述边缘,角点和斑点之间的关系。其次,我们将检测边缘,角点和斑点的算法分类为不同的类别,并提供每个类别中代表性近期算法的详细描述。考虑到机器学习更多地涉及视觉特征检测,我们更加强调基于机器学习的特征检测方法。第三,还介绍了评估标准和数据库。通过这项调查,我们想介绍最近在视觉特征检测方面取得的进展,并确定未来趋势和挑战。
关键字:视觉特征检测、机器学习、边缘检测、角点检测、斑点检测
1. 简介
视觉特征指的是兴趣图像结构和基元。它们在计算机视觉和图像处理领域非常重要。为了突出数字图像中的显着视觉提示,特征检测被称为感兴趣图像基元(例如,点,线/曲线和区域)的标识。这是一个低级处理步骤,像素强度作为输入和图像结构,表明不同的特性作为输出。各种视觉特征被广泛研究并应用于基于计算机视觉的应用,例如物体识别,基于内容的图像检索(CBIR),视觉跟踪[1]和宽基线匹配[2,3]。虽然视觉特征的应用范围有很大差异,但最终目标是有效且高效地提取具有高稳定性的特征。
计算机视觉中的主要挑战是高级概念和低级视觉提示之间的语义差异。描述性和判别性特征对于弥合语义鸿沟很重要,因此可以显着影响系统性能。尽管已经进行了许多努力来进行特征检测,但仍然存在挑战。它们主要是由成像条件的差异引起的。通常,特征检测的困难是由尺度,视点,照明,图像质量等的变化引起的。高性能特征检测器应该对变化的成像条件表现出鲁棒性并且满足人类的兴趣。此外,需要在实时应用中考虑计算效率。尽管现有关于特征检测方法的调查,但它们关注于单一类型的视觉特征(例如,边缘检测[4-6],兴趣点检测[3,7])以及缺乏不同视觉特征之间的关系。此外,现有调查中引入的一些方法已经过时。此外,我们还注意到机器学习算法在视觉特征检测中得到更广泛应用的新趋势。在本文中,我们调查了特征检测的最新进展和进展。这项调查的动机包括
(1)我们的目标是展示特征检测技术的新兴发展,特别是基于机器学习的特征检测方法。
(2)我们还介绍了不同特征检测方法的关系。除了具有代表性的现有技术外,我们还介绍了特征检测的趋势,并强调了未来的挑战。
本文的其余部分组织如下。第2节介绍了视觉特征的基本定义。第3节介绍了视觉特征检测方法的最新进展。第4节介绍了特征检测的评估和典型数据库。摘要和讨论见第5节。
2. 特征检测方法的分类
视觉特征与人类感知组织密切相关。 Gesalt定律的心理学研究表明,人类视觉系统容易出现低级图像成分。人类视觉系统根据Gesalt因素(如接近度,相似性,连续性和闭合性)对视觉刺激进行分组和组织。由于计算机视觉是用相机和计算机模拟人类视觉感知,因此视觉特征检测从人类视觉感知中获得灵感。计算机视觉任务中应用的几个视觉特征具有生物学启发[8,9]。视觉特征从图像像素桥接到计算机视觉任务。边缘,轮廓,角点和区域等原始特征与人类视觉感知密切相关。为了更好地描述特征检测方法的最新进展,我们首先阐明了相关概念(图1)。

图1.计算机视觉中视觉特征的定义。
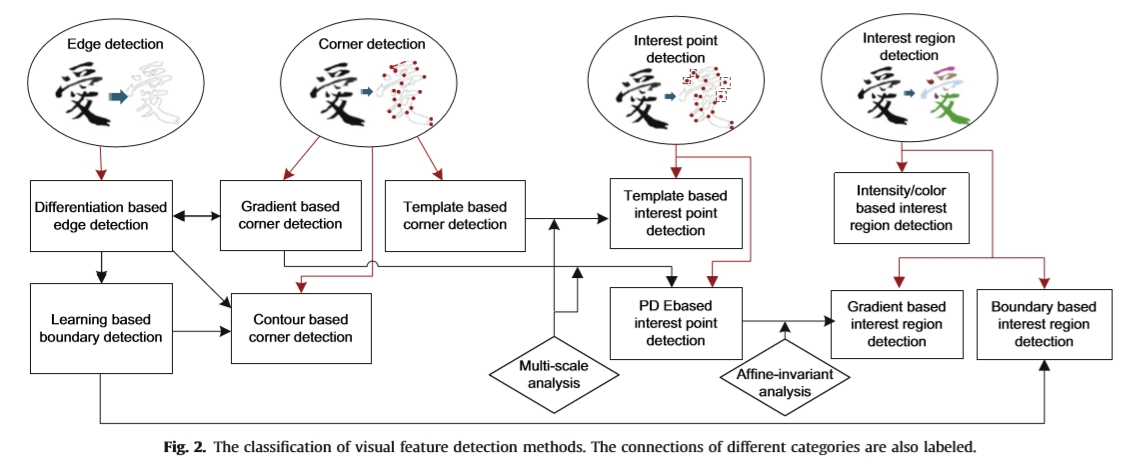
图2.视觉特征检测方法的分类。还标记了不同类别的连接。
基于区分的边缘检测 基于梯度的角点检测 基于模板的角点检测 基于模板的兴趣点检测 基于强度/颜色的感兴趣区域检测
基于学习的边界检测 基于轮廓的角点检测 PD基于兴趣点检测 基于梯度的兴趣区域检测 基于边界的兴趣区域检测
多尺度分析 仿射不变分析
1.边缘是指图像强度突然变化的像素。图像像素在边缘的不同侧是不连续的。
2.轮廓/边界具有模糊的定义。由于我们专注于低级特征,我们将它们称为不同分段区域的交叉线/曲线。
3.角指的是在当地社区中出现两个不同边缘方向的点。它是两条连接轮廓线的交点。
4.区域是指一组封闭的连接点。附近和类似的像素被组合在一起以构成感兴趣区域。
值得注意的是,上述定义之间存在着自然而紧密的联系。也就是说,可以通过跟踪和连接相邻边缘来获得轮廓/边界。角是直边线的交叉点。不同区域之间的交叉曲线构成边界。我们遵循传统的分类,并将边缘,角点,区域作为重要的视觉特征。视觉特征检测方法被分类为边缘检测,角点检测和斑点检测(即,兴趣点/区域检测)。这里blob指的是当地感兴趣的区域。视觉特征检测方法的分类在图2中进一步说明。并且代表性方法在表1中列出。边缘检测简单地分为基于分化和基于学习的方法。边缘梯度的输出通常用作基于学习的方法的输入。对于角点检测,可以将方法划分为基于梯度,基于模板和基于轮廓的方法。基于轮廓的角点检测基于轮廓/边界检测。斑点检测分为兴趣点和区域检测。基于角点检测的多尺度分析,构造了几种兴趣点检测方法。兴趣区域检测与分割技术密切相关。基于边界的兴趣区域检测基于轮廓/边界检测。我们主要关注视觉特征检测的最新进展。近年来出现了一个视觉特征的编年史表,如图3所示。2005年之前的传统特征检测方法首先列出。新出现的代表性特征按年份信息进行排序和标记。我们将在本文的以下部分详细介绍典型的特征检测方法。
表1涵盖的代表性特征检测方法的分类。

类别 分类 方法
边缘检测 基于差异化
基于学习的
角点检测 基于梯度 基于模板 基于轮廓
兴趣点 基于PDE 基于模板
Blob检测
兴趣区域 基于分段
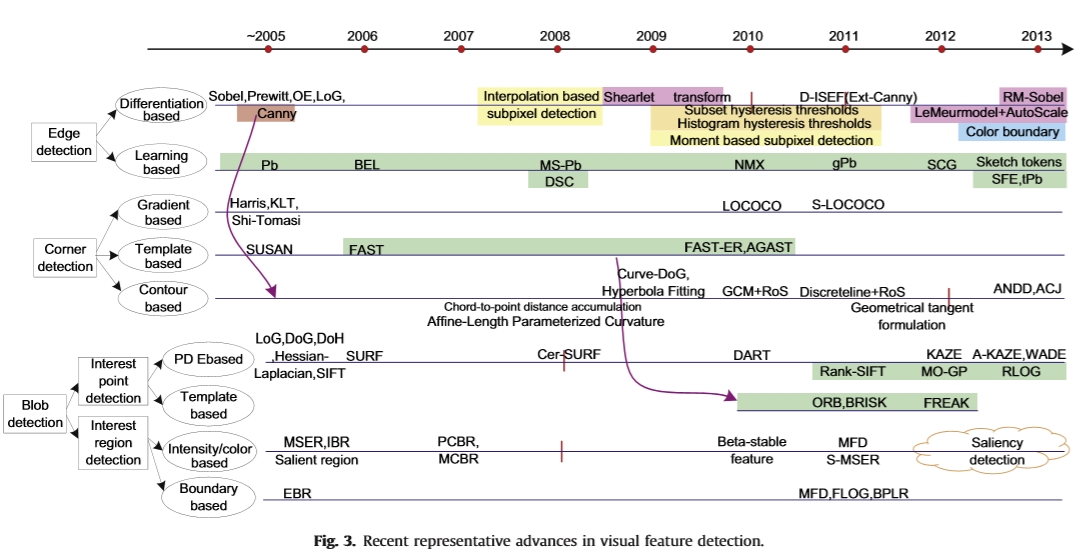
图3.最近在视觉特征检测方面的代表性进展。
3. 特征检测方法
在本节中,我们将详细介绍边,角和斑点的检测方法。我们主要关注最近的进展和进展。还介绍了不同视觉特征检测方法之间的关系。
3.1. 边缘检测
边缘指的是图像亮度的急剧变化。差分操作用于捕获图像亮度中的不连续性的强度和位置。轮廓/边界可以被视为边缘的广义定义,其指示不同区域的交叉。轮廓/边界在图像解释中起着重要作用。最近,人们致力于多分辨率边缘分析,子像素边缘检测和滞后阈值处理。此外,随着多个低级信息的提取,统计机器学习被引入到轮廓和边界检测中。
3.1.1. 基于差异化的边缘检测和进展
经典边缘检测旨在捕获图像亮度的不连续性。基于差异化的过滤器被卷积以识别边缘点。基于一阶微分的梯度算子成对出现(例如,Prewitt,Sobel,如图4(a和b)所示)。通过这些操作员,计算不同方向的梯度。梯度幅度的局部最大值被记录为边缘。二阶微分滤波器,如高斯拉普拉斯(LoG)(图4(c)),将零交叉作为边缘位置。高斯平滑是必要的,因为差分操作对噪声敏感。方向性差异如定向能量(OE)[10]采用一批不同方向的滤波器来获得亮度变化。在[4]中给出了基于区分边缘检测的早期调查。基于区分的边缘检测非常简单但对噪声敏感。目前,它们很少独立地用于识别边缘。然而,差分滤波器的滤波响应仍被广泛用作低级图像线索,以构建更可靠和信息丰富的特征[102]。
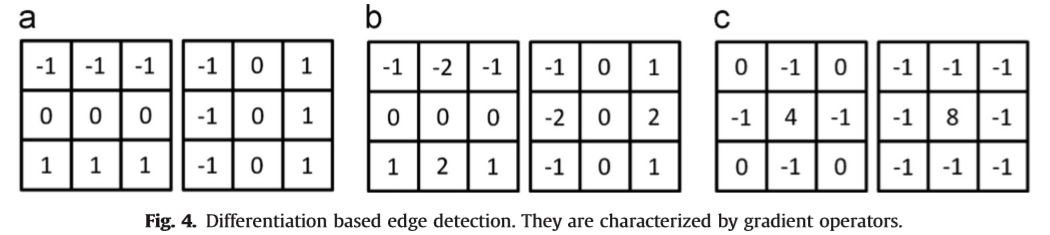
图4.基于区分的边缘检测。它们以梯度算子为特征。
Canny边缘检测器[11]基于边缘检测的计算理论。边缘检测被建模为具有三个标准的优化问题,例如良好的检测,良好的定位和单像素响应。 Canny边缘检测的步骤是滤波,滞后阈值处理,边缘跟踪和非最大抑制。边缘响应首先通过使用梯度算子进行滤波来获得。然后跟踪边缘并由滞后阈值确定。只有梯度方向上具有最大幅度的像素才能被记录为边缘点。 Canny边缘探测器仍然优于几种新探测器,至今仍在广泛应用。最近在[13]中提出了扩展的Canny边缘检测理论,其目的是修改Canny的计算理论,以便生成理论上有限的边缘曲线。此外,[12]中提出了一种用于FPGA实现的分布式Canny边缘检测器。
基于区分的边缘检测的目的是提高检测性能,尤其是在自然图像中。最近的进展主要集中在多分辨率分析,滞后阈值处理和亚像素边缘检测上。多分辨率边缘检测的灵感来自边缘响应与尺度相关,人类视觉是多分辨率的。它旨在整合不同规模的边缘响应。高斯平滑和粗到边缘跟踪结合起来检测多尺度边缘。名为Shearlet变换的小波分析[60]创建了多尺度方向图像表示,用于定位不同尺度的不连续性。 Sobel算子以不同的高斯平滑图像执行。边缘像素以降序比例匹配,以集成到多尺度边缘[61]。人类视觉注意力模型是自动选择最合适的边缘检测尺度[62]。
阈值选择对于边缘响应的二值化至关重要。 Canny边缘检测中使用的滞后阈值处理有助于生成连接的边缘曲线。在所选区域内使用梯度幅度的直方图来确定高阈值和低阈值[63]。构造边缘点候选的子集以确定滞后阈值[64]。子像素边缘检测用于提高定位精度。插值被证明在亚像素边缘定位中是有效的[65]。在感兴趣的区域中计算矩,以构建用于子像素精度的模型[66,67]。此外,色彩边缘检测也引起了人们的注意。颜色模型与边缘确定技术相结合,颜色 - 对手机制源于人类视觉系统应用于颜色边界检测[14]。
3.1.2. 基于学习的边界检测
基于差异化的边缘检测侧重于图像亮度的突然变化。它在纹理区域产生野性边缘响应。需要抑制由纹理引起的内部边缘以获得不同区域之间的边界。伯克利分段数据集和基准(BSDS)大大促进了最近的进展.1自然图像和附加的人体标记边界包含在数据集中。边界被手动标记并在训练和验证集中提供。边缘检测被建模为基于机器学习的框架,以将边缘点与平滑区域区分开。典型的框架如图5所示。提取多个低级图像提示并将其组合到模型中以进行边缘响应预测。我们列出了典型的基于统计学习的边缘检测方法以及表2中的低级线索和应用的统计学习算法。
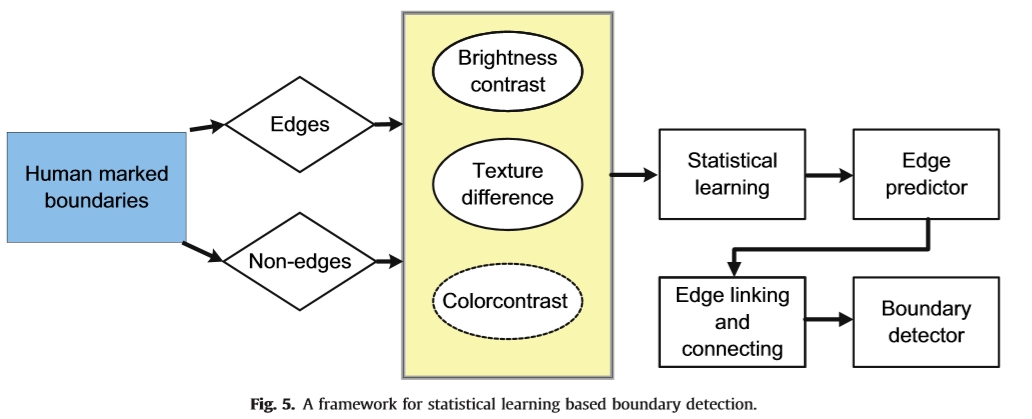
图5.基于边界检测的统计学习框架。
边缘 亮度对比 统计学习 边缘预测器
人类明显的界限 纹理差异
非边缘 颜色对比 边缘链接和连接 边界检测器
表2基于典型统计学习的边缘检测和相应的统计学习算法。
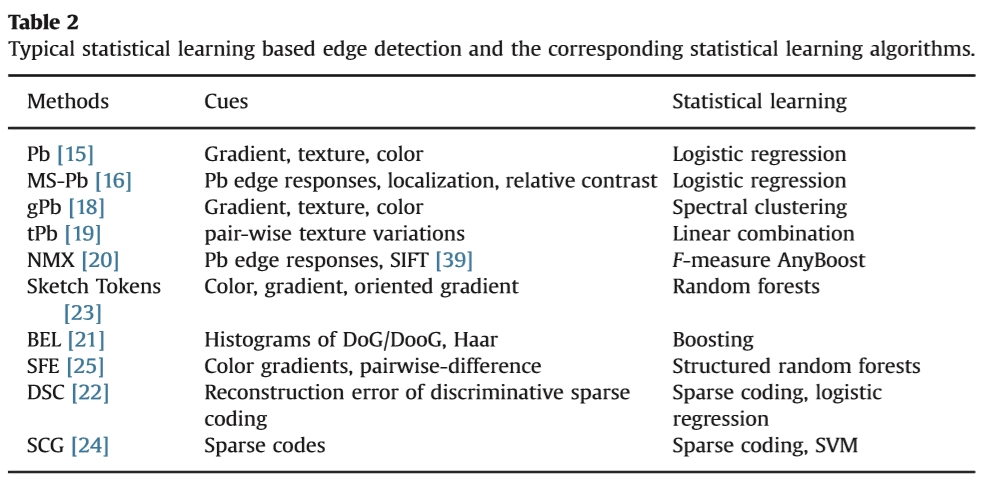
Pb(边界概率)[15]边缘检测基于多个局部线索的提取,包括亮度梯度,纹理梯度和颜色梯度。应用Logistic回归来组合这些多个线索的χ距离,并学习边缘响应预测的判别模型。由于边缘响应与尺度相关,因此提出了基于Pb的多尺度边缘检测器[16,17]。类似于基于微分的边缘检测,不同尺度的边缘的组合和定位是要解决的两个重要问题。 MS-Pb [16]集成了Pb [15]的多尺度边缘响应,附加定位和相对对比度信息,以确定多尺度边缘。定位线索表示在各个尺度上从像素到最接近的峰值Pb响应的距离。相对对比线索表明局部区域的归一化边缘响应。 gPb(全局Pb)[17,18]将三个尺度的Pb边缘响应和全局信息线性组合成轮廓检测。多尺度图像提示被组合成一个能够确定像素之间相似性的亲和矩阵。谱聚类用于全局计算与轮廓信息对应的亲和矩阵的特征向量。 tPb(基于纹理的Pb)[19]使用随机放置的窗口对中的纹理变化的平均值来估计显着边缘响应。 Pb边缘特征被馈入AnyBoost分类器,其优化标准基于F-测量的近似(即,F-测量Boosting)[20]用于边界检测。
除了先前定义的通道中的对比之外,其他方法将现有的特征描述符(例如,Haar小波[68],SIFT [39])应用为字典单词并将它们馈送到用于边缘响应预测的分类器中。 BEL(Boosted edge learning)[21]基于决策树提升概率。诸如DoG响应和Haar小波的直方图之类的通用特征在不同的位置和尺度处生成。通过Boosting决策树顺序选择这些通用特征,以构建用于边缘确定的判别模型。此外,基于结构化森林的边缘检测(SFE)[25]基于随机决策树的学习。输入是颜色和梯度通道以及成对差异。每个结构林标记补丁内的边缘像素。最终边缘响应是随机森林的聚合。基于BEL [21]和SFE [25]的边缘检测都具有相对低的计算成本的优点。此外,自动生成字典单词作为边缘概率确定的分类器的输入。例如,稀疏编码表示被应用于生成候选边缘响应的字典单词。在[22]中,使用判别稀疏编码算法来学习图像的稀疏表示。训练额外的线性分类器以组合稀疏编码的多尺度重建误差并获得边缘响应。 SCG(稀疏码梯度)检测[24]使用稀疏编码自动生成通用特征。稀疏代码用作输入局部提示,并且支持向量机(SVM)分类用于学习模型以区分边缘和非边缘。
边缘点是低级功能。边缘跟踪旨在链接孤立和识别的边缘点。此外,引入轮廓分组以获得连续的语义曲线和封闭形式的区域边界。轮廓分组还可以被视为通过全局信息改善边界检测性能。在轮廓分组中需要考虑分散边缘片段的空间关系。在轮廓分组模型中使用诸如邻近度和连续性的Gesalt因子。图模型已广泛应用于分组因子的制定。解开周期[69]利用轮廓碎片的拓扑关系。在[20]中探索了归一化的轮廓显着性,并将轮廓分组表述为离散优化问题。马尔可夫随机场和条件随机场(CRF)模型[70,71]是广泛应用的分割技术,用于捕获相邻轮廓之间的相互作用并建立轮廓连接。顺序贝叶斯框架应用于分组边缘片段。在[72]中,原始边缘片段被形状信息分类为边缘。在fl fl步骤中学习先前和多种类型的小边缘的过渡。为轮廓元素分组构造粒子滤波框架。此外,[19]中给出了边界检测边缘的顺序标记。
3.1.3. 讨论
边缘检测在图像处理和计算机视觉中一直很重要。基于经典差分的边缘检测通过梯度算子识别具有亮度变化的像素位置。这些梯度算子现在仍然被广泛使用,作为进一步的中级图像表示的低级预处理。 Canny边缘检测是生成连接单响应边的应用的流行选择。最近基于区分的边缘检测涉及三个重要问题。它们是亚像素边缘检测,多尺度边缘分析和滞后阈值处理。第一个目标是提高定位精度,最后两个目标是提高检测精度。基于微分的边缘检测方法仅关注强度的对比度,因此它们普遍具有噪声敏感性的缺点。边缘响应在纹理区域中是狂野的。仅使用梯度信息也可能导致内部边缘,这可能是图像解释的噪声。
另一个值得注意的进展是基于学习的边界检测。 Berkeley Segmentation Dataset和Benchmark的出现推动了它的发展。边缘检测被建模为分类边界点的分类问题。使用统计学习算法和多个图像提示来构建用于边缘响应确定的模型。基于学习的方法可以通过多个提示的表示进一步划分。接下来是Pb边缘检测器[15],距离函数被公式化以测量颜色,纹理,亮度通道中的成对区域差异。分类算法用于组合多个距离测量。由于距离测量与边界点非常直接相关,因此简单的线性分类也可以产生良好的性能。现有实验表明,通过平均成对子窗口中的纹理距离,也可以实现相当的性能[19]。其他基于学习的方法将自动生成的字典单词(即,稀疏代码,密集定义的Haar特征,成对比较特征)馈送到分类器中。在某些情况下,需要使用分类算法(例如Boosting和随机森林)来选择有效的字典单词。通过选择简单的计算字典单词可以减少计算负担。
与基于差异的方法相比,基于学习的方法可以抑制由纹理引起的内部边缘。通过学习检测到的边缘更接近人类视觉感知,并且与诸如对象边界的语义含义更相关。但是,计算成本非常高。多尺度分析是差异化和基于学习的边缘检测的共同问题。然而,仅在基于区分的方法中研究了子像素定位。在基于学习的方法中,子区域不是像素,而是用于差异计算和分析的基本元素。相邻子区域中信息的整合限制了定位精度。基于区分的边缘检测有利于从图像子区域构建中级特征表示。它现在已集成到图像视觉属性的分析中。同时,基于学习的多个线索边缘检测可以获得边界片段,这与图像分割密切相关。
边缘跟踪和轮廓分组是生成连接边缘线/曲线的以下步骤。边缘跟踪旨在将孤立的边缘点连接到边缘线/曲线。轮廓分组旨在获得不同对象之间的语义边界。后者利用全局信息提高边缘检测性能。基于图模型的学习算法用于学习边缘片段的空间和共现关系。连接和分组边缘对于对象识别和图像理解非常有用。可以从连接边缘的分析中直接获取形状信息。因此,Canny和Pb边缘检测器的响应被广泛用作具有形状的对象类识别的基础,其中检测到的响应被视为对象边界的片段。精度和精度是评估边缘检测性能的重要指标。
3.2. 角点检测
角被定义为两条连接的直边线的交叉点。在图像理解中,它在数学上指的是存在两个主要和不同梯度方向的点。可以在角点附近获得丰富的信息。与边缘相比,角点在局部区域是独特的,这有利于宽基线匹配。角点的定义与尺度相关。角点检测和多尺度分析是识别兴趣点的直接而重要的方法。相反,角也可以被视为固定比例的兴趣点。通常,角点检测方法可以进一步划分为三个类。基于经典梯度的角点检测基于梯度计算。基于模板的角点检测基于像素的比较。近年来,模板与机器学习技术(即决策树)相结合,用于快速角点检测。基于轮廓的检测基于轮廓和边界检测的结果。它依赖于边缘响应的预测来识别角点。
3.2.1. 基于梯度的角点检测
早期文献中的大多数角点检测方法都是基于梯度计算。这里我们以代表性的Harris角点探测器[26]为例来说明基于梯度的角点探测的想法。假设在(u,v)处有一个图像补丁作为I(u,v)。将图像块移动(x,y),获得另一个图像块,因为 I(u + x,v + y)。移位窗口和原始窗口之间的加权平方差(SSD)可以计算为
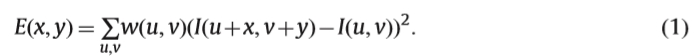
其中w(u,v)是窗口函数。它可以设置为平均或高斯函数。 I(u + x,v + y)可以通过泰勒展开来近似,如公式1所示。 (2):
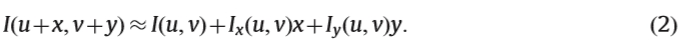
其中Ix和Iy是x和y方向的渐变。此外,E(x,y)可以重写为
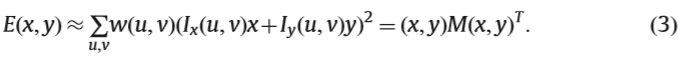
其中M是2 * 2矩阵。它可以从一阶梯度计算得出
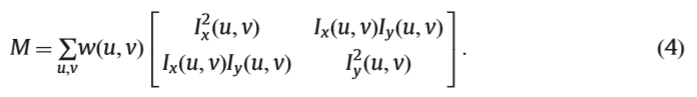
作为λ1和λ2的M的特征值用于区分角。如果λ1和λ2都很大,则E(x,y)在所有方向上都显着增加。这表明 I(u,v)就在拐角处。此外,如果λ1>>λ2,则I(u,v)接近边缘。哈里斯角度测量由M的行列式和轨迹构成。它还用于区分角点,边缘和平滑区域(图6)。
计算Ix和Iy以获得角测量
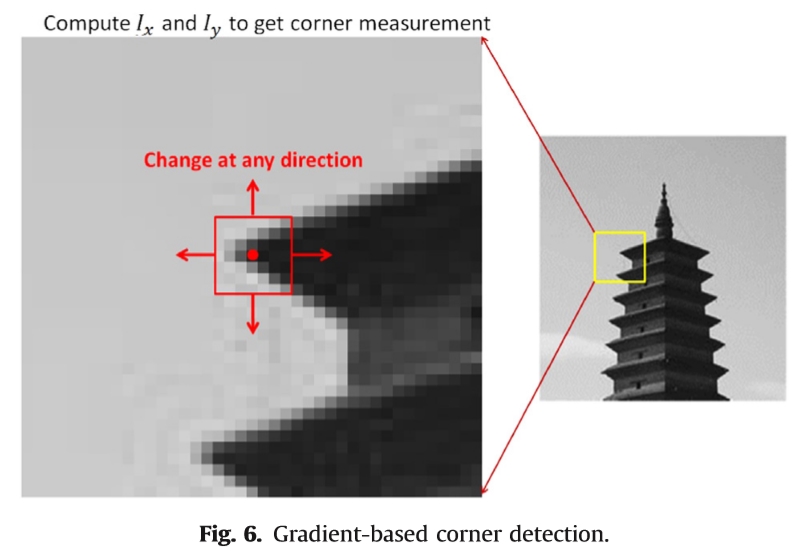
图6.基于梯度的角点检测。
从上面可以看出,Harris角点检测是基于移位窗口上的梯度的自相关。早期论文中提出了其他基于梯度的角点检测方法,如KLT [27]和Shi-Tomasi角点检测器[28]。主要区别在于角度测量功能。由于梯度的计算对噪声敏感,因此基于梯度的角点检测具有噪声敏感性的缺点。此外,需要在窗口内计算测量函数矩阵,这使得计算复杂度非常高。这是传统的基于梯度的角点检测的另一个缺点。为了解决高复杂性,最近已经致力于基于梯度的角度测量的近似。基于经典的角点检测器,如LOCOCO [29],提出了低复杂度角点检测器。它基于Harris和KLT角度测量。首先,盒内核用于近似一阶高斯导数内核。其次,借用基于梯度的积分图像以快速方式计算重叠窗口中的角度响应。最后,基于Quick-sort算法提出了一种有效的非最大抑制,以进一步节省时间。最近在[30]中提出了基于插值的作为S-LOCOCO的LOCOCO的子像素版本。
3.2.2.基于模板的角点检测
基于模板的角点检测通过将周围像素的强度与中心像素的强度进行比较来找到角点。模板首先被定义并放置在中心像素周围,如图7所示。角度测量功能是根据周围/居中像素强度的关系设计的。在传统的SUSAN(最小的单一段同化核)[31]中,将圆形掩模内的每个像素与中心像素进行比较,并记录强度差。
USAN测量被定义为绝对强度差小于阈值的像素数。具有最小USAN值的点被记录为角。基于模板的角点检测的计算成本主要是由多次比较引起的,其相对低于基于梯度的方法。
比较周围像素与中心像素 模板
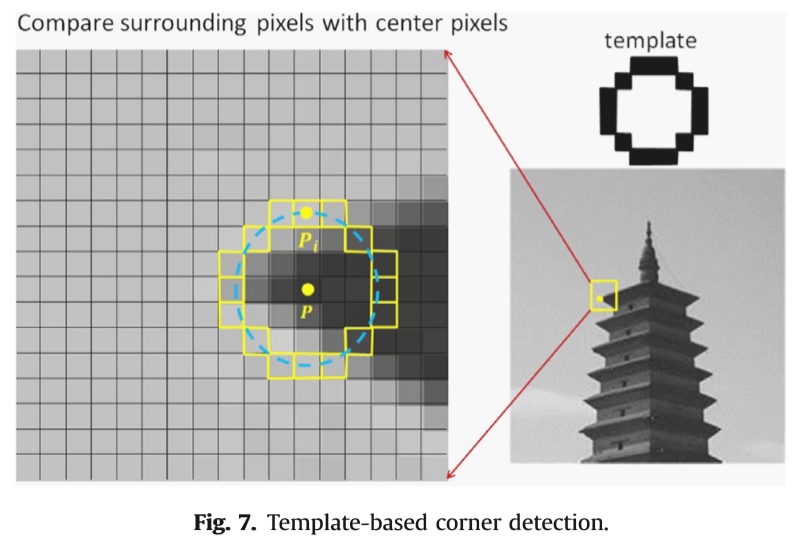
图7.基于模板的角点检测。
近年来,机器学习算法尤其是决策树涉及加速基于模板的角点检测。 FAST(加速段测试的特征)[32]基于直径为3.4像素的圆形模板,包含16个像素。只有当圆中至少有S个连续像素比由中心像素强度和阈值t确定的值更亮或更暗时,才将点视为角。假设中心是p0,像素强度是I(p0)。当p0被视为拐角时,必须至少S个连接的像素比I(p0)+ t更亮或者比I(p0)-t更暗。学习决策树以确定用于比较的像素的顺序,以节省时间。 FAST-ER [33]增加了圆形模板的厚度,以增加检测到的角点的稳定性。 AGAST(自适应和通用加速段测试)[34]是另一种FAST派生。它应用反向归纳法来构建最佳决策树以提高速度。此外,使用不同的特定列车图像训练不同决策树的集合。决策树的集合使得AGAST对于不同的环境更加通用。模板在确定角点时非常重要。选择圆形模板,因为它们是各向同性的。需要插值来计算子像素级的像素强度以获得高精度。通常,较厚的模板增加了鲁棒性和计算成本。此外,虽然机器学习的应用有助于降低角点检测的计算成本,但它也可能导致数据库相关的问题。
3.2.3. 基于轮廓的角点检测
角被定义为两个相邻直边线的交叉点。有一些方法可以根据轮廓/边界检测找到角点。这些方法旨在找到构成边缘的平面曲线中具有最大曲率的点。传统类型的基于轮廓的角点在二进制边缘图中指定,这是边缘检测和跟踪的实现结果(如3.1节所述)。曲线平滑和曲率估计是两个必要步骤。平滑曲线有助于降低量化点位置引起的噪声,高斯滤波器是最广泛使用的平滑功能。高斯(DoG)滤波器的差异与曲线点卷曲,找到曲率角点[73]。基于高斯核[36]的各向异性方向导数(ANDD)滤波器用于保持曲线,同时减少曲线表示噪声。支持区域(RoS)是区域平滑方式(如图8所示)。 RoS是曲线的有界区域,在[35,74]中使用。最近的曲率估计是通过Af fi neLength参数化曲率[75],弦距离积累[75],几何切线公式[76],梯度相关矩阵的行列式[35]获得的。最近一项关于基于轮廓的角点检测与二元边缘图的调查在[77]中提出。基于轮廓的角更多地应用于形状分析和基于形状的图像压缩,而不是宽基线匹配。
原始图像 二进制边缘 角点检测
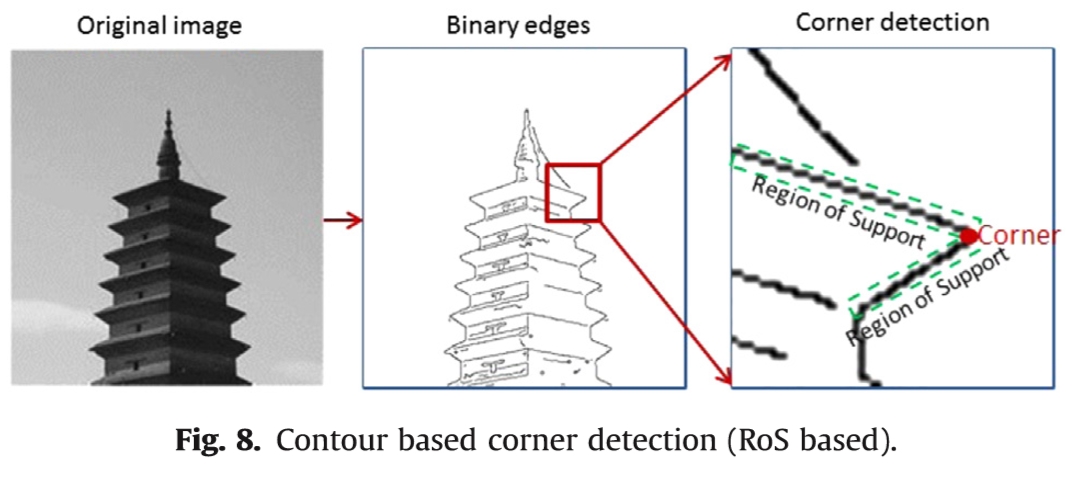
图8.基于轮廓的角点检测(基于RoS)。
角点和连接点的定义之间存在模糊界限,特别是在基于轮廓的检测中。后者通常被赋予更多交叉轮廓的特定信息。交叉轮廓可以与T形,L形,X形连接相连。基于轮廓的角点和结点检测的经典研究集中在二值边缘的处理上。然而,由于二值化导致信息丢失,因此对于自然图像中的应用可能是不充分的。在最近提出的方法中应用边缘响应而不是二值化边缘图。模板首先在边缘图像的中心点周围定义。与FAST [32],AGAST [34]中定义的模板不同,结点检测中的模板更类似于RoS。它们用楔形定义,作为曲线的分支。需要拟合步骤来确定分支中的强度变化信息。结的形状以及拐角度测量是通过分支中边缘响应的强度来实现的。在[37]中,计算边缘响应并用于计算双曲多项式曲线。快速角点检测是通过从基于曲线的曲线形状模型中对代数特征进行阈值处理来完成的。在[38]中,应用了扇形分支。归一化梯度和离散方向用于计算分支中的边缘强度。建立概率原理用于鲁棒结点检测。角定位的准确性依赖于边缘检测。随着多线索集成和机器学习引起的边缘检测性能的提高,基于轮廓的角点检测得到了提升。在[17]中提出了一种基于多线索组合和统计学习的轮廓和结点检测的统一框架。与基于学习的边界检测类似,多个提示的集成有助于抑制纹理区域中的角点。
3.2.4. 讨论
与边缘相比,角点在局部图像区域中是稳定且独特的。角被定义为存在两个不同梯度方向的点。直觉上,出现了基于经典梯度的角点检测方法。但是,它非常耗时且对噪声敏感。相反,基于模板的角点检测要快得多,因为不采用派生运算。它基于圆形模板中像素强度的比较。最近的进展的特点是决策树分类的应用,它显着加快了角点检测速度。除了节省时间之外,通过基于模板的方法(例如FAST [32],FASTER [33],AGAST [34])检测到的角点数大于基于梯度的方法。由于更多的点导致更可靠的匹配,因此在广泛的基线匹配中优选较大数量的检测到的角。像素上的比较还可以容忍照明变化。然而,在不同的成像条件下,检测到的FASTcorner的数量并不是那么稳定[3]。基于模板的方法的另一个缺点是缺乏有效和精确的角度测量。离散拐角度量难以满足非最大抑制的要求。此外,学习过程可能会导致数据库相关的问题,因此需要改进基于机器学习的方法的泛化性能。基于轮廓的角点检测的灵感来自边缘碎片和角点之间的自然连接。它与检测框架和应用领域中基于梯度和模板的方法有很大不同。基于轮廓的检测方法取决于边缘检测和链接获得的轮廓。检测到的角和交叉点更多地应用于基于形状的区域近似和表示。最近的梯度幅度和方向更多地涉及基于轮廓的角点检测,而不是二元识别的轮廓点。角度测量在楔形模板中计算。模板中的分类可以进一步区分不同种类的结。
角点与边缘和斑点密切相关。首先,拐角是存在至少两个主要边缘取向的点。传统的角度测量,如Harris测量[26],UASN [31]也可用于识别边缘。基于轮廓的角点检测基于边缘响应确定。它需要边缘检测和跟踪作为预处理步骤。最近的方法[17]将轮廓和角点检测的任务组合成一个整体框架。其次,角点可以被视为固定尺度的兴趣点。它们可以被视为一种重要的斑点。结合金字塔结构和多尺度分析,可以定位分散在不同尺度的兴趣点。基于经典梯度的角点检测导致基于梯度的特征,例如SIFT [39],SURF [40]。它们具有很高的时间和存储负担。相比之下,基于模板的角点检测导致二进制特征。随着诸如BRIEF [78,79]之类的二进制描述符的出现,基于二元决策树的角点检测被集成到二元特征的构造中,例如ORB [49],BRISK [50]。 ORB借用哈里斯角度测量来对检测到的多尺度角进行排名。二元特征的评估论文在[80]中给出。附加的二进制描述有助于减少匹配的存储负担和时间成本。因此二进制功能节省了时间和存储。较低的计算和存储负担使得决策树检测到的角点在诸如图像检索的大规模基于视觉的应用中更优选。基于梯度和模板的角都被广泛研究并应用于宽基线匹配和立体重建。此外,角点和兴趣点通常与特征描述相结合,用于高级图像解释。
3.3. Blob检测
Blob被定义为像素被认为彼此相似的区域,同时与周围的邻域不同。 blob的定义基于兴趣属性的恒定性,因此blob检测进一步被称为感兴趣点(关键点)/兴趣区域(keyregion)的标识。斑点由规则/不规则形状的区域表示。我们将兴趣点称为比例位置空间中的局部极值,其进一步表示规则的圆形或正方形区域。兴趣区域被称为分段区域(在大多数情况下是不规则的),具有定义的恒定性。兴趣点检测旨在发现金字塔空间中的局部极值,并且兴趣区域检测旨在通过分割技术识别具有恒定性的区域。稳定性始终是blob检测的首选属性。
3.3.1. 兴趣点检测
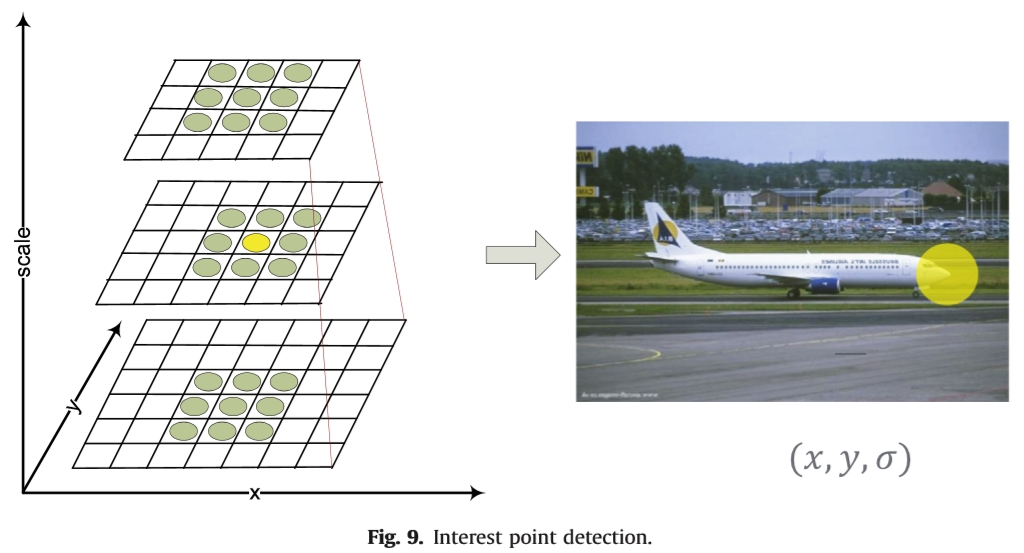
图9.兴趣点检测。
兴趣点可以为数字图像提供信息表示。它指的是具有位置和比例作为轴的三维尺度空间中的局部极值,如图9所示。因此,兴趣点可以在数学上表示为(x,y,σ)。这里(x,y)表示位置,σ表示比例。角可以被视为固定比例的兴趣点。此外,特征描述符可以在以(x,y)为中心的正方形或圆形区域内获得,其大小由σ[81]确定。提出了各种兴趣点检测方法,现有的评价文献在[7,3]中给出。经典方法包括高斯拉普拉斯(LoG),高斯(DoG)和Hessian-Laplacian [7]的差异基于高斯金字塔结构。高斯尺度空间内核定义为
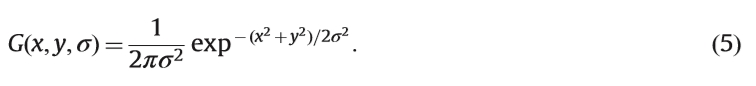
通过增加σ构造高斯金字塔。假设
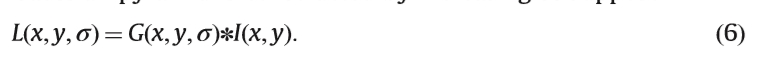
其中*表示卷积运算。 LoG基于高斯滤波尺度空间的拉普拉斯算子。每层LoG金字塔定义为∇2L¼LxxþLyy,其中Lxx,Lyy是第二偏导数。与LoG不同,DoG层是通过两个附近的高斯平滑层的差异获得的,而不计算第二偏导数。可以将DoG视为低计算成本的LoG的近似值。 DoG功能定义为
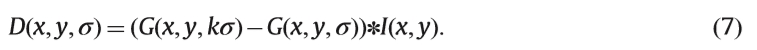
其中k是乘法因子。 LoG和DoG金字塔的局部极值分别记录为LoG和DoG兴趣点。另一种经典兴趣点检测基于Hessian矩阵(DoH)的行列式。高斯平滑图像的Hessian矩阵是
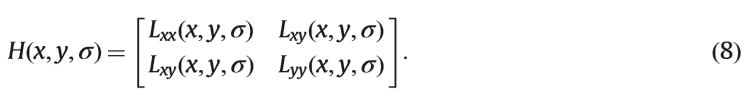
其中Lxx,Lxy,Lyy是第二个偏导数。 Hessian矩阵σ4det(H)的尺度标准化行列式是兴趣点检测的测量函数。 Hessian-Laplacian [7]将LoG和DoH结合起来用于兴趣点检测。
利用DoG,DoH,Hessian-Laplacian进行兴趣点检测仍然在最近的计算机视觉算法中得到广泛应用。 SIFT(尺度不变特征变换)[39]利用DoG金字塔和Hessian矩阵定位兴趣点。 DoG金字塔中的局部极值被记录为潜在关键点,3D二次函数是近似定位候选关键点的插值位置。利用Hessian矩阵的轨迹和行列式计算的测量函数用于消除具有强边缘响应和子像素定位的关键点。梯度方向的直方图是特征描述。 SIFT已被广泛用于宽基线匹配,运动结构,视觉跟踪和物体识别。 SURF(加速鲁棒特征)[40]使用框滤波器来逼近Hessian矩阵的行列式并构造快速Hessian兴趣点检测器。具有SURF(CerSURE)的中心 - 环绕感兴趣点检测器在[41]中给出。通过近似Hessian矩阵的行列式检测另一个兴趣点是DART [42]。它使用加权三角形响应来逼近高斯函数的二阶导数,它对应于Hessian矩阵的元素。除了近似,整合排名,投票和其他基于学习的操作以提高兴趣点的稳定性。 ROLG(高斯的等级拉普拉斯算子)[44]基于加权等级顺序滤波器和LOG。 LoG滤波器可以表示为加权平均值之间的减法。在ROLG中,加权中值响应用于替换加权平均值并生成兴趣点检测方法。在[82]中,投票策略用于对感兴趣点检测的较暗或较亮图像像素进行分组。 Rank-SIFT [43]将监督学习应用为RankSVM来选择稳定的兴趣SIFT点。测量稳定性的得分被建模,并且RankSVM用于解决兴趣点检测的排名函数。在[45]中,构建了兴趣点的稳定性,离差和信息内容三个目标函数。遗传编程用于解决多目标兴趣点检测问题。
诸如LoG,DoG,DoH之类的经典兴趣点基于高斯尺度空间的部分微分。近年来,基于非线性偏微分方程(PDE)的新定义的兴趣点问世。 KAZE的特征[46]通过非线性扩散滤波找到局部极值。基于高斯平滑导致图像模糊的考虑,引入扩散滤波以提供多尺度图像空间,同时保持自然图像边界。加性算子分裂(AOS)方案用于求解扩散函数的非线性偏微分方程。基于推导,Scharr滤波器用于近似扩散函数的一阶和二阶导数。 KAZE功能的主要缺点是计算成本高。在[47]中进一步提出了加速版的KAZE。 WADE [48]兴趣点检测框架基于波传播。波动方程先于突出显示并隔离显着对称,因此WADE先验地检测具有对称性的兴趣点。由于上述兴趣点方法的理论基础是偏微分方程(PDEs),我们将它们称为基于PDE的兴趣点检测。此外,边缘焦点兴趣点[83]被定义为与具有垂直于其自身的梯度方向的边缘点近似等距的点。 Edge foci兴趣点的检测基于批量定向滤波的聚合。对称性的其他兴趣点[84]量化了兴趣点检测的区域的自相似性。
受基于决策树的角点检测器(例如,FAST [32],FAST-ER [33],AGAST [34])的计算速度的启发,出现了基于二元比较和决策树分类的兴趣点检测。 ORB(定向FAST和旋转Brief)[49]在图像金字塔的每个尺度上使用FAST角点检测器。借用哈里斯角度测量来抑制非最大潜在兴趣点。 ORB的特征描述是BRIEF [78,79]的轮换版本。 BRISK(二元鲁棒不变可伸缩关键点)[50]在比例空间中应用AGAST角点检测器[34]来定位潜在的兴趣点。 FAST分数用作非最大抑制和兴趣点定位的显着性测量。 FREAK(快速视网膜关键点)[51]使用与BRISK相同的兴趣点检测器,其中二进制描述符来自人类视网膜。从工程的角度来看,二进制功能非常受欢迎,因为它们耗时少,节省存储空间。
3.3.2. 兴趣区域检测
原始图像 找到具有恒定性的区域 适合具有规则形状的区域
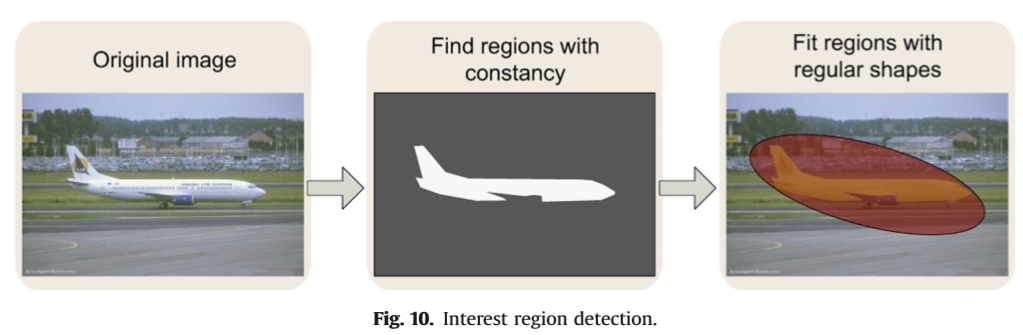
图10.兴趣区域检测。
兴趣区域是指通过利用图像属性的恒定性从邻近区域分割的区域。感兴趣区域检测的典型过程在图10中示出。像素恒定性的定义可以是像素强度,零梯度等。选择沿大阈值范围保持稳定的区域作为感兴趣区域。椭圆或平行四边形用于分割感兴趣的区域。感兴趣区域的数学表示取决于嵌入的椭圆或平行四边形的参数。与兴趣点检测不同,兴趣区域检测通常不需要额外的多尺度金字塔构造。
MSER(最大稳定极值区域)[52]基于对像素强度进行阈值处理来获得感兴趣区域。极值区域被定义为所有像素值比边界上的像素值更亮或更暗的区域。假设i = 1 ... n-1,n,n + 1 ...是测试的阈值,嵌套的极值区域为Q1 ... Qn-1,Qn,Qn + 1 ....区域的稳定性定义为阈值n的函数。
其中Δ是确定边界厚度和|。|的参数获得基数。 MSER定义为Qn,局部最大值为ψn。它旨在找到在大范围的阈值变化范围内保持稳定的区域。其他传统兴趣区域包括IBR(基于强度极值的区域)[2],EBR(基于边缘的区域)[2],基于像素强度的概率分布的显着区域[53]。
近年来,诸如形状凸起和曲率计算的结构因素与经典MSER相结合,以在自然图像中分割可靠区域。 MSER [85]的扩展考虑了形状因子。修改经典稳定性标准并组合形状凸测量以使检测器偏好具有不规则边界的区域。 PCBR(基于主曲率的区域)[54]基于在主曲率图像的分水岭区域中操作的MSER。从Hessian矩阵的特征值中提取主曲率图像。借用增强的分水岭分割并在清洁的二元主曲率图像中使用。 MSER进一步应用于检测和分配流域地图中的兴趣区域。在[86]中,提出了一种基于高斯曲率分析的不变兴趣斑点检测器。尺度不变的兴趣点检测器用于在第一阶段中定位稀疏候选点。在第二阶段,高斯函数用于确定每个兴趣点的形状和位置参数,并生成高斯曲率。基于估计的高斯曲率进一步定义感兴趣区域。此外,还涉及颜色信息。 MSCR(最大稳定颜色区域)[57]是具有颜色信息的MSER的扩展。通过图像像素的泊松统计得到彩色距离。应用凝聚聚类来连续地对具有相似颜色的相邻像素进行分组。
兴趣区域和边界之间存在自然联系。后者代表不同地区的交叉区域。最近,边界信息变得更加集成到兴趣区域检测中,而不是MSER [52]中使用的强度信息。内侧特征检测器[56]是基于边界的框架。首先,利用图像梯度生成加权距离图。之后,在加权距离图中计算全局加权中轴。区域通过中轴分解来分段。最后,定义形状碎片因子以选择感兴趣区域。比例和不定风扇特征[58]基于提取的边缘片段。它首先应用Harris测量[26]来选择显着边缘点作为沿边界的候选兴趣点。边缘片段与候选兴趣点相关联以确定子区域的形状。高斯扇形拉普拉斯(FLOG)用于自动尺度选择和最终感兴趣区域定位。 BPLR(边界保留局部区域)[59]基于基于学习的Pb边缘检测器[87]。针对每个边界段计算距离变换(DT)。通过用最大DT值密集采样来生成候选圆形区域。最小生成树算法用于对相邻的圆形区域进行分组并生成密集放置的边界保留局部区域。与兴趣点检测相比,通过兴趣区域检测获得更多参数,如旋转角度,纵横比。用分割区域提取的特征描述符可以用更多几何参数进行归一化,因此主要是不变的。
显着性检测旨在定位模拟人类对图像的关注的感兴趣区域。如今,它是计算机视觉领域一个热门而快速发展的话题。最近的关于显着性检测的调查和比较研究可以在[88-90]中找到。基于显着性检测目前独立于视觉特征检测的考虑,并且关于该主题存在若干现有调查,这里我们仅简要介绍。早期显着性检测主要基于图像对比度和差异计算。基于局部对比度的特征被组合以找到显着区域[91]。后来,全局分析将类似图像区域的空间分布考虑在内。显着性检测与分割技术密切相关。外观相似性和空间分布是当前显着区域检测方法的两个重要元素。诸如条件随机场(CRF)之类的图模型用于将两个元素组合成显着性赋值[92]。典型的近期方法是多个低级线索组合[93],分级显着性检测[94]和聚合[95]。
3.3.3. 讨论
Blob检测方法与定义的兴趣属性有很大不同。它们可以通过检测框架和输出表达式进行分类。兴趣点检测与规模空间的构建密切相关。他们将3D尺度空间中的局部极值作为兴趣点。经典方法基于高斯尺度空间的二阶导数,其对噪声敏感并且计算复杂度高。最近的进展可以粗略地分为三种方式。首先是经典的基于高斯的方法的推广。偏导数的近似用于提高检测速度,并且插值用于提升定位精度。排名和投票被集成到现有的基于高斯尺度空间的检测框架中,以提高稳定性。 RankSVM和遗传编程等机器学习技术也用于提高稳定性。第二种方式侧重于从非线性尺度空间构造新的偏微分方程,并解决局部外显子以定位兴趣点。 KAZE [46]特征中提出的非线性尺度空间可以生成平滑的尺度空间,同时保留区域的自然边界。其他兴趣点检测方法,如WADE [48]旨在提取自然存在的对称性,并且是重要的Gesalt因子。基于PDE的兴趣点检测的推导是复杂的,并且衍生物计算的计算成本始终是关注的问题。随着基于学习二叉树的角点检测的发展(例如,FAST [32],AGAST [34]),另一种方法将基于模板的角点检测与金字塔构造相结合以提取兴趣点[49,50]。时间成本急剧下降,但量表中的极值测量很难确定。与基于PDE的检测器相比,需要改进新出现的基于FAST和AGAST的检测器的稳定性。
兴趣区域检测旨在对区域进行分割并提取形状参数以进行归一化,以使检测到的特征具有不变性。一种经典的直接方法是利用不变技术扩展兴趣点检测器,例如Hessian-af fi ne,Harris-af fi ne [96]。但是大多数最近的方法都受到细分的启发。形状因子更多地涉及最近的兴趣区域检测方法。形状因子的整合增加了优化的形状限制并提高了稳定性。
此外,边缘和轮廓检测器更多地应用于兴趣区域分割框架中。 Canny边缘检测器仍然是流行的选择,基于学习的gPb [87]检测器也被集成到感兴趣区域分割中。在最近的进展中已经研究了轮廓/边界和感兴趣区域之间的自然拓扑连接。还集成了诸如分水岭算法和距离变换的图像处理技术。利用边缘片段和轮廓检测到的感兴趣区域可以容忍照明变化,但是检测框架也变得更加复杂。与兴趣点检测相比,分割区域可以为立体匹配提供更多几何参数。感兴趣区域检测还显示出平滑区域的提取和表示的优点。斑点检测的灵感来自宽基线匹配,并在三维重建和物体识别方面得到广泛研究。如何选择在不同视点和光照条件下保持稳定的视点和区域仍然非常重要。此外,目标是在自然图像中分割注意区域的显着性检测最近成为热门话题。
4. 评估和数据库
视觉特征检测的评估非常重要。一个令人信服的评估框架可以显着促进研究。虽然可以通过人类观察直观地评估视觉特征检测,但它对于大规模数据库来说是不充分的。作为检测精度,定位误差和计算效率,需要考虑三个标准进行经验评估。计算效率可以通过检测时间成本来衡量。可以从二维空间中的误差距离计算定位误差。检测精度的测量是多种多样的,关键思想是找到对应关系。不同之处在于对应的定义。第一种对应是基于将检测到的响应与人类标记的基础事实相匹配。第二种是匹配相关图像中检测到的响应。我们主要关注最近文献中使用的测量。用于评估边缘检测,角点检测和斑点检测的典型数据库如表3所示。
表3用于评估特征检测的代表性数据集。
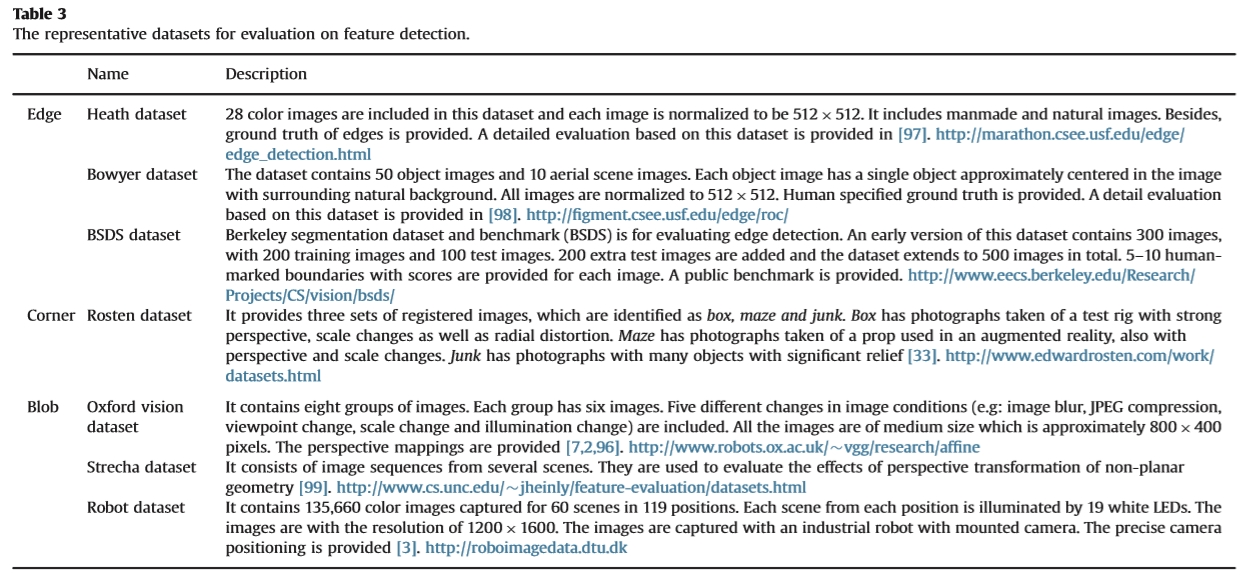
名称 描述
Heath 数据集:此数据集中包含28个彩色图像,每个图像标准化为512 * 512。它包括人造和自然图像。此外,还提供了边缘的基本事实。 [97]中提供了基于该数据集的详细评估。 http://marathon.csee.usf.edu/edge/ edge_detection.html
Bowyer数据集:该数据集包含50个对象图像和10个空中场景图像。每个对象图像具有大约在图像中心的单个对象,具有周围的自然背景。所有图像均标准化为512 * 512。提供了人类特定的基本事实。 [98]中提供了基于该数据集的详细评估。 http://figment.csee.usf.edu/edge/roc/
BSDS数据集:伯克利分段数据集和基准(BSDS)用于评估边缘检测。该数据集的早期版本包含300个图像,具有200个训练图像和100个测试图像。添加了200个额外的测试图像,数据集总共扩展到500个图像。为每个图像提供5-10个带有分数的带人标记的边界。提供公共基准。 http://www.eecs.berkeley.edu/Research/ Projects/CS/vision/bsds/
Rosten数据集:它提供了三组注册图像,分别标识为盒子,迷宫和垃圾。 Box有一张试验台拍摄的照片,它具有很强的视角,尺度变化以及径向畸变。迷宫拍摄了在增强现实中使用的道具的照片,也包括透视和比例变化。垃圾照片中有很多物体都有明显的浮雕效果[33]。http://www.edwardrosten.com/work/ datasets.html
Oxford vision数据集: 它包含八组图像。每组有六张图片。包括图像条件的五种不同变化(例如:图像模糊,JPEG压缩,视点变化,比例变化和光照变化)。所有图像都是中等大小,大约为800×400像素。提供了透视映射[7,2,96]。http://www.robots.ox.ac.uk/vgg/research/affine
Strecha数据集:它由来自几个场景的图像序列组成。它们用于评估非平面几何体的透视变换的影响[99]。 http://www.cs.unc.edu/jheinly/feature-evaluation/datasets.html
Robot数据集:它包含135,660个彩色图像,在119个位置拍摄60个场景。每个位置的每个场景都由19个白色LED照亮。图像的分辨率为1200 * 1600。使用安装有摄像头的工业机器人捕获图像。提供精确的摄像机定位[3]。http://roboimagedata.dtu.dk
通过发现检测到的响应与人类标记的地面实况之间的对应关系来实现边缘检测的评估。典型的BSDS数据库为每个图像提供了几个人类标记的边界图。称为精确调用和附加实值测量(即平均精度,F测量)的参数曲线用于评估。利用固定阈值,可以通过边缘检测方法获得二进制检测响应。检测到的响应与人类标记的边界匹配。真阳性Ntp被定义为匹配响应的数量。假阳性Nfp定义为检测到的响应的数量,其不能与地面实况相匹配。假设有Np标记的边缘点。精度定义为真阳性与所有检测到的响应数之间的比率。回想一下,确定真阳性和人类标记的基本事实之间的比例。那是,
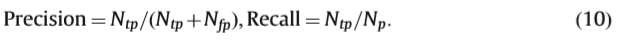
当存在多个地面实况图时,二进制检测到的响应与每个人类标记的边界图匹配。 Recall进一步定义为通过匹配每个地图获得的召回率的平均值。假阳性被定义为检测到的响应的数量,其不能与任何人类标记的边缘匹配,并且精度通过等式1进一步计算。 (10)。能够实现更高精度和召回的检测方法排名更高。平均精度(AP)是实值测量,表示PR曲线的覆盖区域。常用的F-measure定义为

0 <α<1是平衡精度和召回重要性的权重。通常α= 0.5。即,F = 2P * R /(R + P)。最大F度量用作算法排名的实际值。此外,还有新提出的边缘检测测量[100,101]。
表4典型的边缘/边界检测方法及其在BSDS数据集上实现的最大F测量。
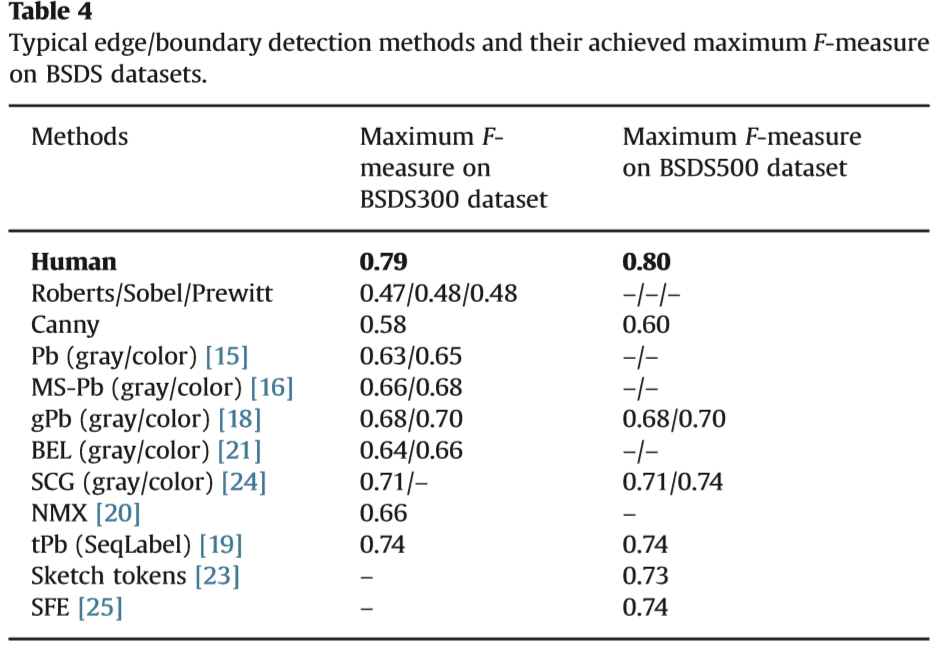
通过广泛认可的BSDS基准,评估边缘和轮廓检测算法。我们列出了表4中代表性方法的最大F-度量,结果来自公共评估2或现有文献。从表中我们可以发现,与基于差异的方法相比,基于学习的边缘检测通常可以实现更高的F-测量。这主要是因为基于区分的边缘检测不区分纹理边缘。通过基于经典差分的边缘检测,例如Roberts,Sobel,Prewitt,在BSDS300数据集上实现的F-测量值约为0.48。此外,Canny边缘检测的F度量为0.58。通过基于学习的方法,F-度量从0.63变化到0.74。基于学习的边缘检测可以由积分提示(即,亮度,纹理和颜色)来划分。从Pb [15]的单独评估中,通过亮度梯度实现的F-测量值为0.60,其高于纹理梯度(即0.58)和颜色梯度(即0.57)。通过gPb [18]和SCG [24]获得具有灰度信息的最高F-测量值,为0.68。根据BEL [21],gPb [18]和SCG [24]提供的经验评估,颜色信息的整合将使F测量值提高约0:02-0:03。 BSDS300数据集上报告的最高F值是0.74 [19],它基于tPb边缘响应预测和基于顺序标记的边缘链接。此外,SFE报告的BSDS500数据集的最高F测量值为0.74 [25]。值得注意的是,通过人体注释获得的理想F-测量值为0.79 / 0.80,这是基于学习的边界检测的最终目标。此外,计算效率也是现有经验评估的一个关注问题。通常,基于学习的边界检测比基于区分的边缘检测更加计算。在所有基于学习的方法中,只有SFE [25]声称它是实时的。 BEL [21]和SFE [25]基于通用描述符和特征选择分类算法(即,用于BEL的Boosting和用于SFE的随机森林)具有相对低的计算成本。但该声明不适用于基于稀疏码计算的SCG [24]。这是计算成本最高的方法[25]。全球信息和边缘链接的整合增加了F-度量,但额外的时间成本也增加了。
角点和斑点检测的评估是在成对图像中找到对应关系。在不同条件下(例如,比例,视点,照明,噪声,JPEG压缩和图像模糊)针对相同场景捕获图像组。用于评估的数据库由这些图像组和标记的成像条件组成。一个简单的测量是检测到的拐角/斑点的数量。它用于衡量方法的适应性。更多功能意味着更多的匹配和图像解释信息。角点/斑点检测的经验评估最常用的测量是可重复性。它旨在测量在改变成像条件下正确对应的比率。假设Ia和Ib表示成对图像,H是从Ia到Ib的估计单应性。 Pa和Pb是检测到的关键点/角点。 Ra和Rb是检测到的感兴趣区域。正确的对应关系测量为
点对点通信:
区域对应:
其中K是像素位置误差阈值,ε是区域重叠阈值。重复性测量值被定义为相应对的比率与检测到的特征的最小总数量之比。它还可以被定义为相应对的比率和不同图像中检测到的特征的总和数量。具有较高可重复性的方法被认为是更好的,因为它表明该方法可以在变化的条件下稳定地检测特征。参数曲线可以通过连续改变尺度,视点,照明以及计算的可重复性作为因变量来获得。重复性被广泛用于基准评估角点和斑点检测方法[3,7,103]。还有其他测量。例如,基于扩散分布有助于减少特征混淆的考虑,使用熵来测量图像中感兴趣点的空间分布中的扩散。
尽管重复性是经验评估的公认测量,但实验设置(例如,像素/重叠阈值,数据集和计算机配置)对于现有文献和比较研究而言是不同的[7,3]。然而,尽管实验环境存在差异,但从现有的实证评估中得出了一些有趣的结果。牛津数据集最广泛用于评估。根据现有的实验结果,最近基于模板的角点检测与决策树分类如FAST [32],FASTER [33]和AGAST [34]已经带来了显着的计算效率。与基于经典梯度的角点检测方法(如Harris [26])相比,角点检测可以显着加速。由于应用了较厚的模板,FAST-ER [33]略慢于FAST [32]。但是较厚的模板也增加了FAST-ER角点检测的稳定性。 AGAST [34]比FAST更有效,计算效率更高[32]。由于基于模板的兴趣点检测(如ORB [49]和BRISK [50])基于基于决策树分类的角点检测,因此它们具有计算成本低的优点。然而,基于决策树分类的角点检测存在若干缺点。一个是它们在模糊图像中表现不佳[49]。重复性在大的视点变化中下降。另一个是根据[3]中提供的经验评估,检测到的角点数量不稳定。此外,角点与规模相关。因此,角点检测的重复性测量得分,如经典Harris和最近的FAST [32],AGAST [34]在规模变化下是不具有竞争力的,这是预期的。
除了基于决策树的角点检测的参与之外,兴趣点检测的另一个进展是近似技术的集成,例如SURF [40],CerSURE [41]和DART [42]。根据实验,提高了计算效率,同时SURF [40],CerSURE [41],DART [42]的可重复性与经典SIFT [39]在视点,尺度,光照变化方面相当。但是面内旋转变化的可重复性降低了,因为基于盒子和三角形滤波的近似或多或少破坏了高斯平滑的各向同性特性。相比之下,非线性偏微分方程的引入和KAZE [46]和WADE [48]等新特征的计算成本很高。
但高斯模糊条件下的重复性更稳定。兴趣区域检测与分割技术集成在一起。经典的MSER [52]显示出优势[7],特别是对于结构化场景。相反,基于PDE的兴趣点检测在纹理场景中更好地执行。由于感兴趣的视觉特性不同,预计会有所不同。一般来说,MSER [52]在视点和光照变化下实现了更高的重复性分数和更好的性能,但对图像模糊变化敏感[7]。诸如MSCR [57]之类的颜色信息的集成增加了纹理场景的视点改变下的可重复性,但是计算负担也增加了。另一方面,结构因素(即PCBR [54])和边界信息(即BPLR [59])与兴趣区域检测的整合显示了视觉任务的性能提升,如对象识别[59]和图像检索[ 56]。
5. 总结和讨论
视觉特征检测的目的是识别兴趣图像结构(例如,点,曲线和区域)。特征检测是计算机视觉系统中的重要部分。在蓬勃发展的计算机视觉应用中需要有效和高效的功能,例如宽基线匹配,运动结构,物体识别和图像检索。特征检测的研究可以追溯到计算机视觉的开端,提出了许多经典的方法。在本文中,我们主要关注视觉特征检测的最新进展。我们介绍和分类检测边缘,轮廓,角点和斑点的最新进展。总的来说,最近提案的一部分继承了经典方法的关键思想。例如,兴趣点检测的LoG测量已经集成到几个最近的特征中。除了传统方法的扩展之外,最近的进展还需要注意两个趋势。首先是机器学习技术在视觉特征检测中的应用。特征检测被建模为学习和推理问题。人类标记的特征用作特征存在确定的训练样本。第二个趋势是利用存在于不同类型特征中的连接。边界检测更集成到角点和感兴趣区域检测中。在分类的基础上,我们还讨论了不同特征检测方法的优缺点。我们希望为感兴趣的研究人员提供参考,并确定特征检测的趋势。
早期边缘检测通过微分算子发现像素突然发生变化。最近基于差异的边缘检测的努力主要在于多分辨率分析,子像素定位和滞后阈值确定。边缘检测的重要进展在于新兴的基于学习的方法。边缘检测被建模为学习和推理问题,以区分边界和背景。将多个低级视觉提示(例如,颜色,纹理,梯度和稀疏代码)融合到用于边缘响应预测的学习和推理模型中。人类标记的边界不是用作评估的基础事实,而是还提供用于学习边缘预测模型的训练样本。基于学习的方法可以抑制在纹理区域中广泛出现的内部边缘。角点检测与梯度方向密切相关。经典角点检测基于二阶导数的计算,这非常耗时。虽然有最近的近似检测器,但计算成本仍然很高。最近机器学习已经与基于模板的角度测量相结合。通过模板内的加速像素比较实现快速角点检测。轮廓和角点之间的自然连接促进了基于轮廓的角点/交叉点检测。最近的尝试包括整合基于有效学习的边界检测。雇用学习主要有两种动机。一种是提高检测精度,另一种是提高检测速度。基于学习的边界检测的动机是提高检测精度。相反,角点检测中使用的学习算法旨在提高检测速度。引入学习的共同问题是,用于检测的学习模型可能与数据库有关。
Blob检测一直是一个活跃的主题,特别是在广泛的基线匹配中。兴趣点检测基于尺度空间的构建。传统方法旨在找出高斯尺度空间上的局部极值。已经提出了LoG函数的近似以提高检测速度。此外,还探索了机器学习技术,如排名,遗传编程,以提高检测到的响应的稳定性。其他新的兴趣点定义出来了,基于理论分析的偏导数方程可以用来识别它们。基于学习的角点检测与多尺度分析相结合,以检测兴趣点并产生二元特征。二进制特征的一个优点是它们节省了大量时间和存储,这在大规模Web检索和移动应用程序中是有利的。兴趣区域检测基于分割技术。经典的MSER基于像素强度恒定性。 MSER最近有几个扩展,它们结合了结构因子和颜色信息,在自然图像中生成更可靠的分割区域。受边界和利益区域之间的联系的启发,近年来边界信息更加一体化。模拟人类关注的显着区域检测近年来取得了很大进展,现在已成为一个热门话题。局部对比以及其他空间信息在学习和推理模型中结合用于显着性计算。
视觉特征检测涉及很多计算机视觉应用并受其启发。边缘和轮廓与对象边界密切相关。它们是图像解释所必需和应用的,例如物体识别,图像分割,视觉跟踪,动作分析。与边缘相比,角点和斑点在局部图像区域中是独特的,因此在宽基线匹配,立体声,SLAM中是有利的。 Blob还可以广泛用于识别用于压缩图像表示的稀疏图像区域,因此广泛应用于对象识别和图像检索。视觉特征检测的评估是独特的并且取决于应用。直接的人类观察在评估众多测试图像方面是困难和主观的。考虑到这一点,研究和提出了量化指标。检测精度是最关注的属性,它依赖于发现对应关系。边缘和轮廓检测的评估基于测量检测到的响应与人类标记的地面实况之间的对应关系。精确回忆曲线和附加的F-measure是广泛认可的评估测量。通过发现在变化条件下捕获的图像中的对应关系来测量角点和斑点检测的检测精度。它受到立体声匹配应用的启发。针对不同场景,在不同图像条件下捕获图像组。针对在不同条件下从相同场景捕获的分组图像记录透视映射函数。可重复性是角点和斑点检测的常用测量。实时应用程序需要考虑计算复杂性。此外,需要在大规模图像检索和移动应用中考虑和估计存储需求。
特征检测的未来挑战在于四个方面。首先,我们需要为蓬勃发展的计算机视觉应用设计更有效和更有效的特征检测方法。特征是从图像像素到语义意义的桥接的低级表示,它是高级图像解释的基础。如何设计和检测特定的任务相关功能是一个重要问题。此外,由于人类动作识别[104]等更广泛的视频应用,需要开发视觉特征的时间分析。其次,需要进一步开发不同类型特征之间的关系。视觉特征的定义是拓扑相关的。拓扑关系很重要,但远不是现有方法的充分利用。虽然有人试图同时检测不同类型的视觉特征,但我们需要利用通用框架来识别不同类型的视觉特征,以进行全面的图像分析。第三,机器学习比以往更多地涉及视觉特征检测。然而,有两个问题需要解决。一个是在检测精度和计算效率之间取得平衡。另一种是使学习模型的特征检测与数据库无关。在利用模型和构建通用数据库方面仍有许多工作要做。最后,需要改进视觉特征检测的评估。一个令人信服和全面的评估框架可以显着促进研究。视觉特征检测不是最后的处理步骤,并且不同的特征对于不同的任务是有价值的。人类标记的基本事实特征可能含糊不清且不可靠。视觉特征检测的评估需要包括两部分。一个是衡量检测到的反应与基本事实之间的对应关系的普遍评估。另一种是针对各种计算机视觉任务的特定评估。
参考文献
Image Processing and Computer Vision_Review:A survey of recent advances in visual feature detection—2014.08的更多相关文章
- Image Processing and Computer Vision_Review:A survey of recent advances in visual feature detection(Author's Accepted Manuscript)——2014.08
翻译 一项关于视觉特征检测的最新进展概述(作者已被接受的手稿) 和A survey of recent advances in visual feature detection——2014.08内容相 ...
- Image Processing and Computer Vision_Review:Local Invariant Feature Detectors: A Survey——2007.11
翻译 局部不变特征探测器:一项调查 摘要 -在本次调查中,我们概述了不变兴趣点探测器,它们如何随着时间的推移而发展,它们如何工作,以及它们各自的优点和缺点.我们首先定义理想局部特征检测器的属性.接下来 ...
- Image Processing and Computer Vision_Review:Recent Advances in Features Extraction and Description Algorithms: A Comprehensive Survey——2017.03
翻译 特征提取和描述算法的最新进展:全面的调查 摘要 - 计算机视觉是当今信息技术中最活跃的研究领域之一.让机器和机器人能够以视线的速度看到和理解周围的世界,创造出无穷无尽的潜在应用和机会.特征检测和 ...
- Image Processing and Computer Vision_Review:A Performance Evaluation of Local Descriptors——2005.08
翻译 本地描述符的性能评估——http://tongtianta.site/paper/56756 摘要 - 在本文中,我们比较了为局部感兴趣区域计算的描述符的性能,例如,由Harris-Affine ...
- Image Processing and Computer Vision_Review:HPatches A benchmark and evaluation of handcrafted and learned local descriptors——2017.04
翻译 HPatches:手工和学习本地描述符的基准和评估——http://tongtianta.site/paper/8979 摘要:在本文中,我们提出了一个评估本地图像描述符的新基准.我们证明现有数 ...
- Image Processing and Analysis_15_Image Registration:a survey of image registration techniques——1992
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- Image Processing and Analysis_15_Image Registration:A survey of medical image registration——1998
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- Image Processing and Analysis_15_Image Registration:Image registration methods a survey——2003
此主要讨论图像处理与分析.虽然计算机视觉部分的有些内容比如特 征提取等也可以归结到图像分析中来,但鉴于它们与计算机视觉的紧密联系,以 及它们的出处,没有把它们纳入到图像处理与分析中来.同样,这里面也有 ...
- Deep learning_CNN_Review:A Survey of the Recent Architectures of Deep Convolutional Neural Networks——2019
CNN综述文章 的翻译 [2019 CVPR] A Survey of the Recent Architectures of Deep Convolutional Neural Networks 翻 ...
随机推荐
- MATLAB常用快捷键总结
MATLAB 命令栏显示处理的常用命令 清屏:clc 紧凑显示格式:format compact 宽松显示格式:format loose 数据高精度显示:format longG 数据低精度显示:fo ...
- Ubuntu安装teamview客户端
1,下载teamviem客户端的Ubuntu版本 下载地址 https://www.teamviewer.com/en/download/linux/ 2,安装 apt install ./teamv ...
- Spring Aop(十二)——编程式的创建Aop代理之AspectjProxyFactory
转发地址:https://www.iteye.com/blog/elim-2397922 编程式的创建Aop代理之AspectjProxyFactory 之前已经介绍了一款编程式的创建Aop代理的工厂 ...
- <marquee>滚动文字</marquee>
<marquee>滚动文字</marquee> 水平滚动: <marquee direction=">水平滚动字幕内容</marquee> 垂 ...
- 最新 竞技世界java校招面经 (含整理过的面试题大全)
从6月到10月,经过4个月努力和坚持,自己有幸拿到了网易雷火.京东.去哪儿.竞技世界等10家互联网公司的校招Offer,因为某些自身原因最终选择了竞技世界.6.7月主要是做系统复习.项目复盘.Leet ...
- c# dateTime格式转换为Unix时间戳工具类
using System; using System.Collections.Generic; using System.Text; namespace TJCFinanceWriteOff.BizL ...
- 剑指offer46:圆圈中最后剩下的数字(链表,递归)
1 题目描述 每年六一儿童节,牛客都会准备一些小礼物去看望孤儿院的小朋友,今年亦是如此.HF作为牛客的资深元老,自然也准备了一些小游戏.其中,有个游戏是这样的:首先,让小朋友们围成一个大圈.然后,他随 ...
- 【AC自动机】Censoring
[题目链接] https://loj.ac/problem/10059 [题意] 有一个长度不超过 1e5 的字符串 .Farmer John 希望在 T 中删掉 n 个屏蔽词(一个屏蔽词可能出现多 ...
- 一个MySQL JDBC驱动bug引起的血案
1.1 问题背景 公司是做电商系统的,整个系统搭建在华为云上.系统设计的时候,考虑到后续的用户和订单数量比较大,需要使用一些大数据库的组件.关系型数据库这块,考虑到后续数据量的快速增长,不是 ...
- skywalking-agent 与docker组合使用
docker部署 公司有使用docker部署的微服务 可以直接使用 仓库/java:8-jdk-alpine-asla-shanghai-1-skyagent-2作为基础镜像 这个镜像包是java8 ...